Note
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier les répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de changer de répertoire.
Cet article présente la nouvelle API Speech et montre comment l’implémenter dans une application Xamarin.iOS pour prendre en charge la reconnaissance vocale continue et transcrire la voix (à partir de flux audio en direct ou enregistrés) en texte.
Nouveautés d’iOS 10, Apple a publié l’API Reconnaissance vocale qui permet à une application iOS de prendre en charge la reconnaissance vocale continue et de transcrire la voix (à partir de flux audio en direct ou enregistrés) en texte.
Selon Apple, l’API Reconnaissance vocale présente les fonctionnalités et avantages suivants :
- Très précis
- État de l’art
- Facile à utiliser
- Rapide
- Prend en charge plusieurs langues
- Respecte la confidentialité des utilisateurs
Fonctionnement de la reconnaissance vocale
La reconnaissance vocale est implémentée dans une application iOS en acquérant l’audio en direct ou préenregistré (dans l’une des langues parlées prises en charge par l’API) et en le transmettant à un module Speech Recognizer qui retourne une transcription en texte brut des mots prononcés.

Dictée au clavier
Lorsque la plupart des utilisateurs pensent à reconnaissance vocale sur un appareil iOS, ils pensent à l’assistant vocal Siri intégré, qui a été publié avec la dictée clavier dans iOS 5 avec l’iPhone 4S.
La Dictée du clavier est prise en charge par n’importe quel élément d’interface qui prend en charge TextKit (par UITextField exemple) UITextAreaet est activé par l’utilisateur en cliquant sur le bouton Dictée (directement à gauche de la barre d’espace) dans le clavier virtuel iOS.
Apple a publié les statistiques de dictée clavier suivantes (collectées depuis 2011) :
- La dictée de clavier a été largement utilisée depuis sa publication dans iOS 5.
- Environ 65 000 applications l’utilisent par jour.
- Environ un tiers de la Dictée iOS est effectuée dans une application tierce.
La dictée de clavier est extrêmement facile à utiliser, car elle ne nécessite aucun effort sur la partie du développeur, autre que l’utilisation d’un élément d’interface TextKit dans la conception de l’interface utilisateur de l’application. La dictée de clavier présente également l’avantage de ne pas nécessiter de demandes de privilèges spéciaux à partir de l’application avant de pouvoir être utilisée.
Les applications qui utilisent les nouvelles API reconnaissance vocale nécessitent des autorisations spéciales pour être accordées par l’utilisateur, car la reconnaissance vocale nécessite la transmission et le stockage temporaire des données sur les serveurs d’Apple. Pour plus d’informations, consultez notre documentation sur les améliorations de la sécurité et de la confidentialité.
Bien que la dictée clavier soit facile à implémenter, elle présente plusieurs limitations et inconvénients :
- Il nécessite l’utilisation d’un champ d’entrée de texte et l’affichage d’un clavier.
- Il fonctionne uniquement avec l’entrée audio en direct et l’application n’a aucun contrôle sur le processus d’enregistrement audio.
- Il n’offre aucun contrôle sur la langue utilisée pour interpréter la parole de l’utilisateur.
- Il n’existe aucun moyen pour l’application de savoir si le bouton Dictée est même disponible pour l’utilisateur.
- L’application ne peut pas personnaliser le processus d’enregistrement audio.
- Il fournit un ensemble très peu profond de résultats qui manquent d’informations telles que le minutage et la confiance.
API Reconnaissance vocale
Nouveautés d’iOS 10, Apple a publié l’API Reconnaissance vocale qui offre un moyen plus puissant pour une application iOS d’implémenter la reconnaissance vocale. Cette API est la même qu’Apple utilise pour alimenter Siri et la Dictée clavier et elle est capable de fournir une transcription rapide avec une précision de pointe.
Les résultats fournis par l’API Reconnaissance vocale sont personnalisés de manière transparente pour les utilisateurs individuels, sans que l’application n’ait à collecter ou à accéder à des données utilisateur privées.
L’API Reconnaissance vocale fournit des résultats à l’application appelante en quasi temps réel, car l’utilisateur parle et fournit plus d’informations sur les résultats de la traduction que du texte. Il s’agit notamment des paramètres suivants :
- Interprétations multiples de ce que l’utilisateur a dit.
- Niveaux de confiance pour les traductions individuelles.
- Informations de minutage.
Comme indiqué ci-dessus, l’audio pour la traduction peut être fourni par un flux en direct ou à partir d’une source préenregistré et dans l’une des plus de 50 langues et dialectes pris en charge par iOS 10.
L’API Reconnaissance vocale peut être utilisée sur n’importe quel appareil iOS exécutant iOS 10 et, dans la plupart des cas, nécessite une connexion Internet active, car la majeure partie des traductions a lieu sur les serveurs d’Apple. Cela dit, certains appareils iOS plus récents prennent en charge toujours la traduction sur appareil de langues spécifiques.
Apple a inclus une API de disponibilité pour déterminer si une langue donnée est disponible pour la traduction à l’heure actuelle. L’application doit utiliser cette API au lieu de tester directement la connectivité Internet.
Comme indiqué ci-dessus dans la section Dictée clavier, la reconnaissance vocale nécessite la transmission et le stockage temporaire des données sur les serveurs Apple sur Internet, et, par conséquent, l’application doit demander l’autorisation de l’utilisateur d’effectuer la reconnaissance en incluant la NSSpeechRecognitionUsageDescription clé dans son Info.plist fichier et en appelant la SFSpeechRecognizer.RequestAuthorization méthode.
En fonction de la source de l’audio utilisée pour la reconnaissance vocale, d’autres modifications apportées au fichier de Info.plist l’application peuvent être requises. Pour plus d’informations, consultez notre documentation sur les améliorations de la sécurité et de la confidentialité.
Adoption de la reconnaissance vocale dans une application
Il existe quatre étapes majeures que le développeur doit effectuer pour adopter la reconnaissance vocale dans une application iOS :
- Fournissez une description d’utilisation dans le fichier de l’application à l’aide de
Info.plistlaNSSpeechRecognitionUsageDescriptionclé. Par exemple, une application de caméra peut inclure la description suivante : « Cela vous permet de prendre une photo simplement en disant le mot « fromage ». - Demandez l’autorisation en appelant la
SFSpeechRecognizer.RequestAuthorizationméthode pour présenter une explication (fournie dans laNSSpeechRecognitionUsageDescriptionclé ci-dessus) de la raison pour laquelle l’application souhaite accéder à la reconnaissance vocale à l’utilisateur dans une boîte de dialogue et lui permettre d’accepter ou de refuser. - Créez une demande de reconnaissance vocale :
- Pour l’audio préenregistré sur le disque, utilisez la
SFSpeechURLRecognitionRequestclasse. - Pour l’audio en direct (ou audio à partir de la mémoire), utilisez la
SFSPeechAudioBufferRecognitionRequestclasse.
- Pour l’audio préenregistré sur le disque, utilisez la
- Transmettez la demande de reconnaissance vocale à un module Speech Recognizer (
SFSpeechRecognizer) pour commencer la reconnaissance. L’application peut éventuellement conserver le retourSFSpeechRecognitionTaskpour surveiller et suivre les résultats de la reconnaissance.
Ces étapes seront décrites en détail ci-dessous.
Description de l’utilisation
Pour fournir la clé requise NSSpeechRecognitionUsageDescription dans le Info.plist fichier, procédez comme suit :
Double-cliquez sur le
Info.plistfichier pour l’ouvrir pour modification.Basculez vers la vue Source :

Cliquez sur Ajouter une nouvelle entrée, entrez
NSSpeechRecognitionUsageDescriptionla propriété,Stringpour le type et une description d’utilisation comme valeur. Par exemple :
Si l’application gère la transcription audio en direct, elle nécessite également une description de l’utilisation du microphone. Cliquez sur Ajouter une nouvelle entrée, entrez
NSMicrophoneUsageDescriptionla propriété,Stringpour le type et une description d’utilisation comme valeur. Par exemple :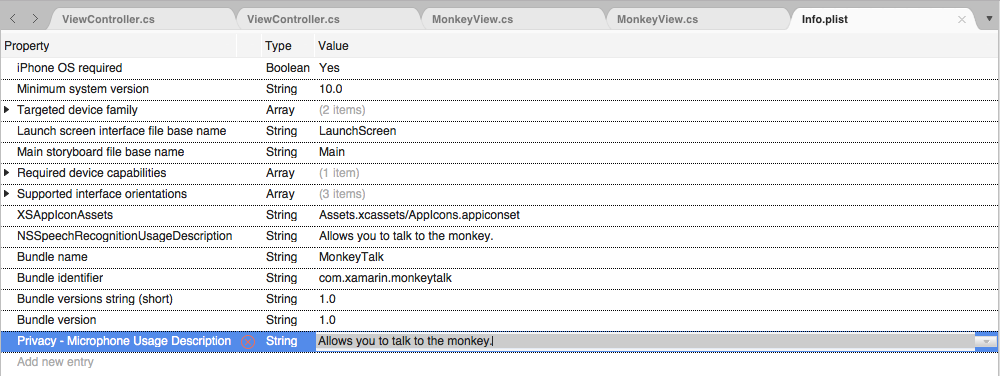
Enregistrez les modifications du fichier.





Important
L’échec de la fourniture de l’une des touches ci-dessus Info.plist (NSSpeechRecognitionUsageDescription ou NSMicrophoneUsageDescription) peut entraîner l’échec de l’application sans avertissement lors de la tentative d’accès à la reconnaissance vocale ou au microphone pour l’audio en direct.
Demande d’autorisation
Pour demander l’autorisation utilisateur requise qui permet à l’application d’accéder à la reconnaissance vocale, modifiez la classe de contrôleur de vue principale et ajoutez le code suivant :
using System;
using UIKit;
using Speech;
namespace MonkeyTalk
{
public partial class ViewController : UIViewController
{
protected ViewController (IntPtr handle) : base (handle)
{
// Note: this .ctor should not contain any initialization logic.
}
public override void ViewDidLoad ()
{
base.ViewDidLoad ();
// Request user authorization
SFSpeechRecognizer.RequestAuthorization ((SFSpeechRecognizerAuthorizationStatus status) => {
// Take action based on status
switch (status) {
case SFSpeechRecognizerAuthorizationStatus.Authorized:
// User has approved speech recognition
...
break;
case SFSpeechRecognizerAuthorizationStatus.Denied:
// User has declined speech recognition
...
break;
case SFSpeechRecognizerAuthorizationStatus.NotDetermined:
// Waiting on approval
...
break;
case SFSpeechRecognizerAuthorizationStatus.Restricted:
// The device is not permitted
...
break;
}
});
}
}
}
La RequestAuthorization méthode de la SFSpeechRecognizer classe demande à l’utilisateur l’autorisation d’accéder à la reconnaissance vocale à l’aide de la raison pour laquelle le développeur a fourni dans la NSSpeechRecognitionUsageDescription clé du Info.plist fichier.
Un SFSpeechRecognizerAuthorizationStatus résultat est retourné à la routine de rappel de la RequestAuthorization méthode qui peut être utilisée pour effectuer des actions en fonction de l’autorisation de l’utilisateur.
Important
Apple suggère d’attendre que l’utilisateur ait démarré une action dans l’application qui nécessite la reconnaissance vocale avant de demander cette autorisation.
Reconnaissance de la reconnaissance vocale préenregistré
Si l’application souhaite reconnaître la voix à partir d’un fichier WAV ou MP3 préenregistré, elle peut utiliser le code suivant :
using System;
using UIKit;
using Speech;
using Foundation;
...
public void RecognizeFile (NSUrl url)
{
// Access new recognizer
var recognizer = new SFSpeechRecognizer ();
// Is the default language supported?
if (recognizer == null) {
// No, return to caller
return;
}
// Is recognition available?
if (!recognizer.Available) {
// No, return to caller
return;
}
// Create recognition task and start recognition
var request = new SFSpeechUrlRecognitionRequest (url);
recognizer.GetRecognitionTask (request, (SFSpeechRecognitionResult result, NSError err) => {
// Was there an error?
if (err != null) {
// Handle error
...
} else {
// Is this the final translation?
if (result.Final) {
Console.WriteLine ("You said, \"{0}\".", result.BestTranscription.FormattedString);
}
}
});
}
En examinant ce code en détail, tout d’abord, il tente de créer un module Speech Recognizer (SFSpeechRecognizer). Si la langue par défaut n’est pas prise en charge pour la reconnaissance vocale, null est retournée et les fonctions se terminent.
Si speech Recognizer est disponible pour la langue par défaut, l’application vérifie si elle est actuellement disponible pour la reconnaissance à l’aide de la Available propriété. Par exemple, la reconnaissance peut ne pas être disponible si l’appareil n’a pas de connexion Internet active.
A SFSpeechUrlRecognitionRequest est créé à partir de l’emplacement NSUrl du fichier préenregistré sur l’appareil iOS et il est remis à Speech Recognizer pour traiter avec une routine de rappel.
Lorsque le rappel est appelé, s’il NSError n’y a pas null eu d’erreur qui doit être gérée. Étant donné que la reconnaissance vocale est effectuée de manière incrémentielle, la routine de rappel peut être appelée plusieurs fois afin que la SFSpeechRecognitionResult.Final propriété soit testée pour voir si la traduction est terminée et la meilleure version de la traduction est écrite (BestTranscription).
Reconnaissance vocale en direct
Si l’application souhaite reconnaître la reconnaissance vocale en direct, le processus est très similaire à la reconnaissance vocale préenregistré. Par exemple :
using System;
using UIKit;
using Speech;
using Foundation;
using AVFoundation;
...
#region Private Variables
private AVAudioEngine AudioEngine = new AVAudioEngine ();
private SFSpeechRecognizer SpeechRecognizer = new SFSpeechRecognizer ();
private SFSpeechAudioBufferRecognitionRequest LiveSpeechRequest = new SFSpeechAudioBufferRecognitionRequest ();
private SFSpeechRecognitionTask RecognitionTask;
#endregion
...
public void StartRecording ()
{
// Setup audio session
var node = AudioEngine.InputNode;
var recordingFormat = node.GetBusOutputFormat (0);
node.InstallTapOnBus (0, 1024, recordingFormat, (AVAudioPcmBuffer buffer, AVAudioTime when) => {
// Append buffer to recognition request
LiveSpeechRequest.Append (buffer);
});
// Start recording
AudioEngine.Prepare ();
NSError error;
AudioEngine.StartAndReturnError (out error);
// Did recording start?
if (error != null) {
// Handle error and return
...
return;
}
// Start recognition
RecognitionTask = SpeechRecognizer.GetRecognitionTask (LiveSpeechRequest, (SFSpeechRecognitionResult result, NSError err) => {
// Was there an error?
if (err != null) {
// Handle error
...
} else {
// Is this the final translation?
if (result.Final) {
Console.WriteLine ("You said \"{0}\".", result.BestTranscription.FormattedString);
}
}
});
}
public void StopRecording ()
{
AudioEngine.Stop ();
LiveSpeechRequest.EndAudio ();
}
public void CancelRecording ()
{
AudioEngine.Stop ();
RecognitionTask.Cancel ();
}
En examinant ce code en détail, il crée plusieurs variables privées pour gérer le processus de reconnaissance :
private AVAudioEngine AudioEngine = new AVAudioEngine ();
private SFSpeechRecognizer SpeechRecognizer = new SFSpeechRecognizer ();
private SFSpeechAudioBufferRecognitionRequest LiveSpeechRequest = new SFSpeechAudioBufferRecognitionRequest ();
private SFSpeechRecognitionTask RecognitionTask;
Il utilise AV Foundation pour enregistrer l’audio qui sera transmis à un SFSpeechAudioBufferRecognitionRequest pour gérer la demande de reconnaissance :
var node = AudioEngine.InputNode;
var recordingFormat = node.GetBusOutputFormat (0);
node.InstallTapOnBus (0, 1024, recordingFormat, (AVAudioPcmBuffer buffer, AVAudioTime when) => {
// Append buffer to recognition request
LiveSpeechRequest.Append (buffer);
});
L’application tente de démarrer l’enregistrement et toutes les erreurs sont gérées si l’enregistrement ne peut pas être démarré :
AudioEngine.Prepare ();
NSError error;
AudioEngine.StartAndReturnError (out error);
// Did recording start?
if (error != null) {
// Handle error and return
...
return;
}
La tâche de reconnaissance est démarrée et un handle est conservé dans la tâche de reconnaissance (SFSpeechRecognitionTask) :
RecognitionTask = SpeechRecognizer.GetRecognitionTask (LiveSpeechRequest, (SFSpeechRecognitionResult result, NSError err) => {
...
});
Le rappel est utilisé de la même manière que celui utilisé ci-dessus lors de la reconnaissance vocale préenregistré.
Si l’enregistrement est arrêté par l’utilisateur, le moteur audio et la demande de reconnaissance vocale sont informés :
AudioEngine.Stop ();
LiveSpeechRequest.EndAudio ();
Si l’utilisateur annule la reconnaissance, la tâche de reconnaissance et du moteur audio sont informées :
AudioEngine.Stop ();
RecognitionTask.Cancel ();
Il est important d’appeler RecognitionTask.Cancel si l’utilisateur annule la traduction pour libérer de la mémoire et du processeur de l’appareil.
Important
L’échec de la fourniture des NSSpeechRecognitionUsageDescription NSMicrophoneUsageDescription Info.plist clés peut entraîner l’échec de l’application sans avertissement lors de la tentative d’accès à la reconnaissance vocale ou au microphone pour l’audio en direct ().var node = AudioEngine.InputNode; Pour plus d’informations, consultez la section Fournir une description de l’utilisation ci-dessus.
Limites de reconnaissance vocale
Apple impose les limitations suivantes lors de l’utilisation de la reconnaissance vocale dans une application iOS :
- La reconnaissance vocale est gratuite pour toutes les applications, mais son utilisation n’est pas illimitée :
- Les appareils iOS individuels ont un nombre limité de reconnaissances qui peuvent être effectuées par jour.
- Les applications seront limitées globalement sur une base de demande par jour.
- L’application doit être prête à gérer les échecs de connexion réseau et de débit d’utilisation de reconnaissance vocale.
- La reconnaissance vocale peut avoir un coût élevé à la fois dans le drainage de la batterie et le trafic réseau élevé sur l’appareil iOS de l’utilisateur, en raison de cela, Apple impose une limite de durée audio stricte d’environ une minute de voix max.
Si une application atteint régulièrement ses limites de limitation de débit, Apple demande au développeur de les contacter.
Considérations relatives à la confidentialité et à la facilité d’utilisation
Apple a la suggestion suivante pour être transparent et respectant la confidentialité de l’utilisateur lors de l’inclusion de la reconnaissance vocale dans une application iOS :
- Lors de l’enregistrement de la parole de l’utilisateur, veillez à indiquer clairement que l’enregistrement a lieu dans l’interface utilisateur de l’application. Par exemple, l’application peut lire un son « enregistrement » et afficher un indicateur d’enregistrement.
- N’utilisez pas la reconnaissance vocale pour les informations utilisateur sensibles telles que les mots de passe, les données d’intégrité ou les informations financières.
- Affichez les résultats de la reconnaissance avant d’agir dessus. Cela fournit non seulement des commentaires sur ce que fait l’application, mais permet à l’utilisateur de gérer les erreurs de reconnaissance à mesure qu’elles sont effectuées.
Résumé
Cet article a présenté la nouvelle API Speech et a montré comment l’implémenter dans une application Xamarin.iOS pour prendre en charge la reconnaissance vocale continue et transcrire la parole (à partir de flux audio en direct ou enregistrés) en texte.