Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Ce document explique les étapes nécessaires pour connecter un compte Azure Data Factory avec un compte Microsoft Purview afin de suivre la traçabilité des données et d’ingérer des sources de données. Le document aborde également les détails de l’étendue de couverture de l’activité et des modèles de traçabilité pris en charge.
Lorsque vous connectez un Azure Data Factory à Microsoft Purview, chaque fois qu’une activité Azure Data Factory prise en charge est exécutée, les métadonnées relatives aux données sources de l’activité, aux données de sortie et à l’activité sont automatiquement ingérées dans le Mappage de données Microsoft Purview.
Si une source de données a déjà été analysée et existe dans le mappage de données, le processus d’ingestion ajoute les informations de traçabilité de Azure Data Factory à cette source existante. Si la source ou la sortie n’existe pas dans le mappage de données et qu’elle est prise en charge par Azure Data Factory traçabilité, Microsoft Purview ajoute automatiquement leurs métadonnées de Azure Data Factory dans le mappage de données sous la collection racine.
Cela peut être un excellent moyen de surveiller votre patrimoine de données à mesure que les utilisateurs déplacent et transforment des informations à l’aide de Azure Data Factory.
Afficher les connexions Data Factory existantes
Plusieurs fabriques de données Azure peuvent se connecter à un seul Microsoft Purview pour envoyer (push) des informations de traçabilité. La limite actuelle vous permet de connecter jusqu’à 10 comptes Data Factory à la fois à partir du centre de gestion Microsoft Purview. Pour afficher la liste des comptes Data Factory connectés à votre compte Microsoft Purview, procédez comme suit :
Sélectionnez Gestion dans le volet de navigation gauche.
Sous Connexions de traçabilité, sélectionnez Data Factory.
La liste des connexions Data Factory s’affiche.

Notez les différentes valeurs de l’état de la connexion :
- Connecté : La fabrique de données est connectée au compte Microsoft Purview.
- Déconnecté : Data Factory a accès au catalogue, mais il est connecté à un autre catalogue. Par conséquent, la traçabilité des données n’est pas automatiquement signalée au catalogue.
- Inconnu : l’utilisateur actuel n’ayant pas accès à Data Factory, la connexion status est inconnue.

Remarque
Pour afficher les connexions Data Factory, vous devez disposer du rôle suivant. L’héritage de rôle à partir du groupe d’administration n’est pas pris en charge. Rôle d’administrateur de collection sur la collection racine.
Créer une connexion Data Factory
Remarque
Pour ajouter ou supprimer les connexions Data Factory, vous devez disposer du rôle suivant. L’héritage de rôle à partir du groupe d’administration n’est pas pris en charge. Rôle d’administrateur de collection sur la collection racine.
En outre, les utilisateurs doivent être le « propriétaire » ou le « contributeur » de la fabrique de données.
L’identité managée affectée par le système doit être activée dans votre fabrique de données.
Suivez les étapes ci-dessous pour connecter une fabrique de données existante à votre compte Microsoft Purview. Vous pouvez également connecter Data Factory à un compte Microsoft Purview à partir d’ADF.
Sélectionnez Gestion dans le volet de navigation gauche.
Sous Connexions de traçabilité, sélectionnez Data Factory.
Dans la page de connexion Data Factory , sélectionnez Nouveau.
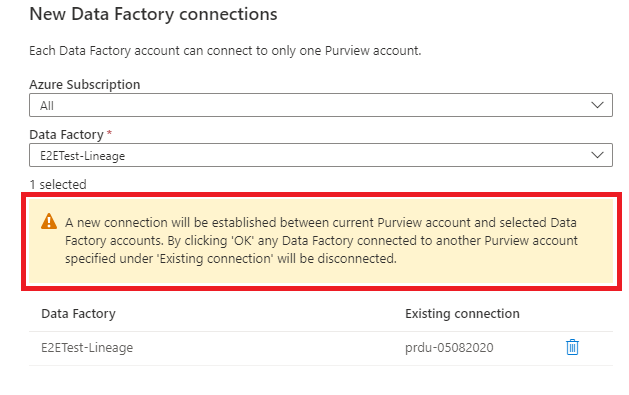
Sélectionnez votre compte Data Factory dans la liste, puis sélectionnez OK. Vous pouvez également filtrer par nom d’abonnement pour limiter votre liste.
Certaines instances Data Factory peuvent être désactivées si la fabrique de données est déjà connectée au compte Microsoft Purview actuel ou si la fabrique de données n’a pas d’identité managée.
Un message d’avertissement s’affiche si l’une des fabriques de données sélectionnées est déjà connectée à un autre compte Microsoft Purview. Lorsque vous sélectionnez OK, la connexion Data Factory avec l’autre compte Microsoft Purview est déconnectée. Aucune autre confirmation n’est requise.
Remarque
Nous prenons en charge l’ajout de 10 comptes Azure Data Factory à la fois. Si vous souhaitez ajouter plus de 10 comptes data factory, faites-le par lots.
Fonctionnement de l’authentification
L’identité managée de Data Factory est utilisée pour authentifier les opérations push de traçabilité de data factory vers Microsoft Purview. Lorsque vous connectez votre fabrique de données à Microsoft Purview sur l’interface utilisateur, elle ajoute automatiquement l’attribution de rôle.
Accordez le rôle Conservateur de données à l’identité managée de la fabrique de données sur la collection racine Microsoft Purview. En savoir plus sur le contrôle d’accès dans Microsoft Purview et Ajouter des rôles et restreindre l’accès via des collections.
Supprimer les connexions Data Factory
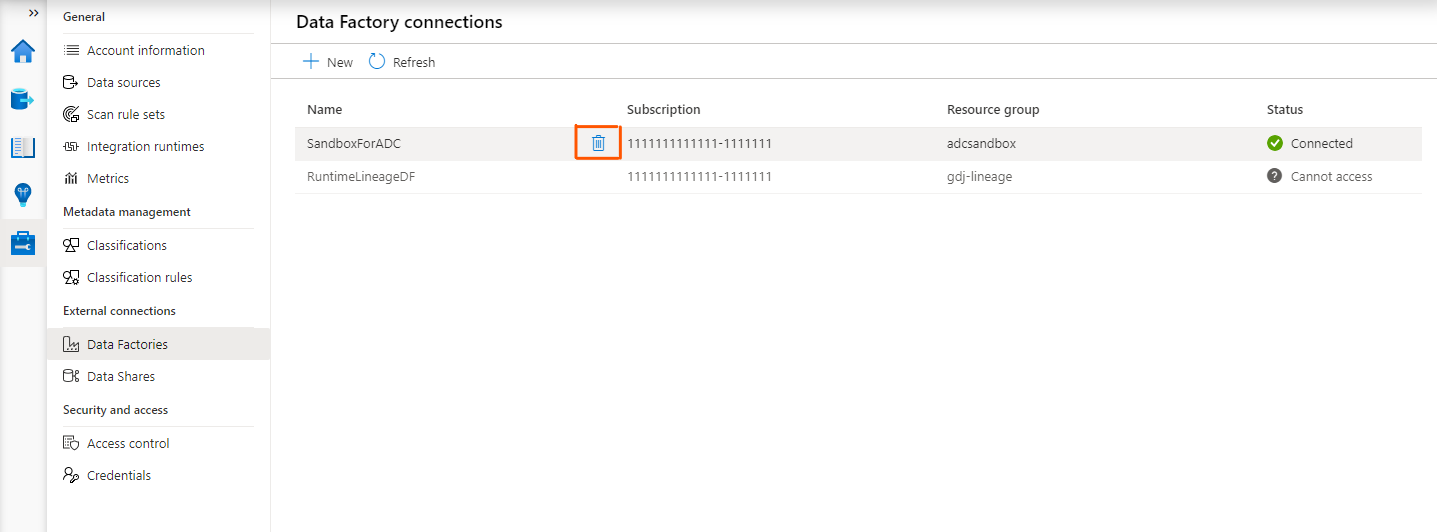
Pour supprimer une connexion de fabrique de données, procédez comme suit :
Dans la page de connexion Data Factory , sélectionnez le bouton Supprimer en regard d’une ou de plusieurs connexions data factory.
Sélectionnez Confirmer dans la fenêtre contextuelle pour supprimer les connexions de fabrique de données sélectionnées.

Surveiller les liens Data Factory
Dans le portail de gouvernance Microsoft Purview, vous pouvez surveiller les liens Data Factory.
Activités Azure Data Factory prises en charge
Microsoft Purview capture la traçabilité du runtime à partir des activités Azure Data Factory suivantes :
Importante
Microsoft Purview supprime la traçabilité si la source ou la destination utilise un système de stockage de données non pris en charge.
L’intégration entre Data Factory et Microsoft Purview prend uniquement en charge un sous-ensemble des systèmes de données pris en charge par Data Factory, comme décrit dans les sections suivantes.
activité Copy prise en charge
| Magasin de données | Pris en charge |
|---|---|
| Stockage Blob Azure | Oui |
| Recherche cognitive Azure | Oui |
| Azure Cosmos DB for NoSQL * | Oui |
| Azure Cosmos DB for MongoDB * | Oui |
| Azure Data Explorer * | Oui |
| Azure Data Lake Storage Gen1 | Oui |
| Azure Data Lake Storage Gen2 | Oui |
| Azure Database for MariaDB * | Oui |
| Azure Database pour MySQL * | Oui |
| Azure Database pour PostgreSQL * | Oui |
| Azure Files | Oui |
| base de données Azure SQL * | Oui |
| Azure SQL Managed Instance * | Oui |
| Azure Synapse Analytics * | Oui |
| Pool SQL dédié Azure (anciennement SQL DW) * | Oui |
| Stockage Table Azure | Oui |
| Amazon S3 | Oui |
| Ruche* | Oui |
| Oracle* | Oui |
| Table SAP (lors de la connexion à SAP ECC ou SAP S/4HANA) | Oui |
| SQL Server * | Oui |
| Teradata * | Oui |
* Actuellement, Microsoft Purview ne prend pas en charge la requête ou la procédure stockée pour la traçabilité ou l’analyse. La traçabilité est limitée aux sources de table et de vue uniquement.
Si vous utilisez des Integration Runtime auto-hébergés, notez la version minimale avec prise en charge de la traçabilité pour :
- Tout cas d’usage : version 5.9.7885.3 ou ultérieure
- Copie de données à partir d’Oracle : version 5.10 ou ultérieure
- Copie de données dans Azure Synapse Analytics via la commande COPY ou PolyBase : version 5.10 ou ultérieure
Limitations relatives à la traçabilité de l’activité de copie
Actuellement, si vous utilisez les fonctionnalités d’activité de copie suivantes, la traçabilité n’est pas encore prise en charge :
- Copiez des données dans Azure Data Lake Storage Gen1 à l’aide du format binaire.
- Paramètre de compression pour les fichiers Binaire, texte délimité, Excel, JSON et XML.
- Options de partition source pour Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, SQL Server et SAP Table.
- Copiez des données dans un récepteur basé sur un fichier avec la définition du nombre maximal de lignes par fichier.
- La traçabilité au niveau de la colonne n’est actuellement pas prise en charge par l’activité de copie lorsque la source/récepteur est un jeu de ressources.
En plus de la traçabilité, le schéma de ressource de données (affiché dans l’onglet Ressource -> Schéma) est signalé pour les connecteurs suivants :
- Fichiers CSV et Parquet sur Azure Blob, Azure Files, ADLS Gen1, ADLS Gen2 et Amazon S3
- Azure Data Explorer, Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, SQL Server, Teradata
Data Flow prise en charge
| Magasin de données | Pris en charge |
|---|---|
| Stockage Blob Azure | Oui |
| Azure Cosmos DB for NoSQL * | Oui |
| Azure Data Lake Storage Gen1 | Oui |
| Azure Data Lake Storage Gen2 | Oui |
| Azure Database pour MySQL * | Oui |
| Azure Database pour PostgreSQL * | Oui |
| base de données Azure SQL * | Oui |
| Azure SQL Managed Instance * | Oui |
| Azure Synapse Analytics * | Oui |
| Pool SQL dédié Azure (anciennement SQL DW) * | Oui |
* Actuellement, Microsoft Purview ne prend pas en charge la requête ou la procédure stockée pour la traçabilité ou l’analyse. La traçabilité est limitée aux sources de table et de vue uniquement.
Limitations de la traçabilité des flux de données
- La traçabilité du flux de données peut générer un jeu de ressources au niveau du dossier sans visibilité sur les fichiers impliqués.
- La traçabilité au niveau de la colonne n’est actuellement pas prise en charge lorsque la source/le récepteur est un jeu de ressources.
- Pour la traçabilité de l’activité de flux de données, Microsoft Purview prend uniquement en charge l’affichage de la source et du récepteur impliqués. La traçabilité détaillée pour la transformation de flux de données n’est pas encore prise en charge.
- La traçabilité n’est pas prise en charge lorsque les flowlets font partie du flux de données.
- Actuellement, Purview ne prend pas en charge les rapports de traçabilité pour les tables Synapse (base de données LakeHouse DB/Workspace)
Prise en charge de l’exécution du package SSIS
Reportez-vous aux magasins de données pris en charge.
Accéder au compte Microsoft Purview sécurisé
Si votre compte Microsoft Purview est protégé par un pare-feu, découvrez comment permettre à Data Factory d’accéder à un compte Microsoft Purview sécurisé via des points de terminaison privés Microsoft Purview.
Intégrer la traçabilité Data Factory dans Microsoft Purview
Pour obtenir une procédure pas à pas de bout en bout, suivez le Tutoriel : Envoyer des données de traçabilité Data Factory à Microsoft Purview.
Modèles de traçabilité pris en charge
Microsoft Purview prend en charge plusieurs modèles de traçabilité. Les données de traçabilité générées sont basées sur le type de source et de récepteur utilisé dans les activités Data Factory. Bien que Data Factory prenne en charge plus de 80 sources et récepteurs, Microsoft Purview ne prend en charge qu’un sous-ensemble, comme indiqué dans Activités Azure Data Factory prises en charge.
Pour configurer Data Factory pour envoyer des informations de traçabilité, consultez Prise en main de la traçabilité.
Voici d’autres façons de trouver des informations dans la vue de traçabilité :
- Sous l’onglet Traçabilité , pointez sur les formes pour afficher un aperçu des informations supplémentaires sur la ressource dans l’info-bulle.
- Sélectionnez le nœud ou l’arête pour voir le type de ressource qu’il appartient ou pour changer de ressource.
- Les colonnes d’un jeu de données sont affichées sur le côté gauche de l’onglet Traçabilité . Pour plus d’informations sur la traçabilité au niveau des colonnes, consultez Traçabilité des colonnes du jeu de données.
Traçabilité des données pour les opérations 1:1
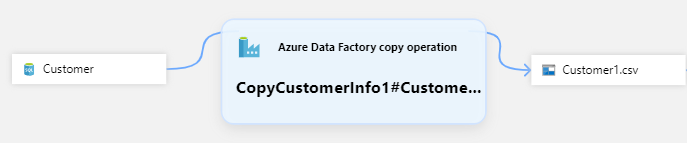
Le modèle le plus courant pour capturer la traçabilité des données consiste à déplacer des données d’un jeu de données d’entrée unique vers un jeu de données de sortie unique, avec un processus entre les deux.
Voici un exemple de ce modèle :
- 1 source/entrée : Client (table SQL)
- 1 récepteur/sortie : Customer1.csv (Objet blob Azure)
- 1 processus : CopyCustomerInfo1#Customer1.csv (Data Factory activité Copy)
Déplacement des données avec prise en charge de la traçabilité 1:1 et des caractères génériques
Un autre scénario courant de capture de traçabilité consiste à utiliser un caractère générique pour copier des fichiers d’un jeu de données d’entrée unique vers un jeu de données de sortie unique. Le caractère générique permet à l’activité de copie de faire correspondre plusieurs fichiers à copier à l’aide d’une partie commune du nom de fichier. Microsoft Purview capture la traçabilité au niveau du fichier pour chaque fichier copié par l’activité de copie correspondante.
Voici un exemple de ce modèle :
- Source/entrée : CustomerCall*.csv (chemin ADLS Gen2)
- Récepteur/sortie : CustomerCall*.csv (fichier blob Azure)
- 1 processus : CopyGen2ToBlob#CustomerCall.csv (Data Factory activité Copy)

Déplacement des données avec traçabilité n :1
Vous pouvez utiliser Data Flow activités pour effectuer des opérations de données telles que la fusion, la jointure, etc. Plusieurs jeux de données sources peuvent être utilisés pour produire un jeu de données cible. Dans cet exemple, Microsoft Purview capture la traçabilité au niveau du fichier pour les fichiers d’entrée individuels dans une table SQL qui fait partie d’une activité Data Flow.
Voici un exemple de ce modèle :
- 2 sources/entrées : Customer.csv, Sales.parquet (chemin ADLS Gen2)
- 1 récepteur/sortie : données de l’entreprise (table Azure SQL)
- 1 processus : DataFlowBlobsToSQL (activité Data Flow Data Factory)

Traçabilité des jeux de ressources
Un jeu de ressources est un objet logique dans le catalogue qui représente de nombreux fichiers de partition dans le stockage sous-jacent. Pour plus d’informations, consultez Présentation des jeux de ressources. Lorsque Microsoft Purview capture la traçabilité à partir du Azure Data Factory, il applique les règles pour normaliser les fichiers de partition individuels et créer un seul objet logique.
Dans l’exemple suivant, un jeu de ressources Azure Data Lake Gen2 est généré à partir d’un objet blob Azure :
- 1 source/entrée : Employee_management.csv (Objet blob Azure)
- 1 récepteur/sortie : Employee_management.csv (Azure Data Lake Gen 2)
- 1 processus : CopyBlobToAdlsGen2_RS (Data Factory activité Copy)

Étapes suivantes
Tutoriel : Envoyer (push) des données de traçabilité Data Factory à Microsoft Purview