Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
| Mayana Pereira | Scott Christiansen |
|---|---|
| Science des données CELA | Sécurité et confiance des clients |
| Microsoft | Microsoft |
Résumé — L’identification des rapports de bogues de sécurité (SBR) est une étape essentielle du cycle de vie du développement logiciel. Dans les approches basées sur le Machine Learning supervisée, il est habituel de supposer que l’ensemble des rapports de bogues sont disponibles pour l’apprentissage et que leurs étiquettes sont sans bruit. À notre connaissance, c'est la première étude à montrer que la prédiction précise des étiquettes est possible pour les SBR même lorsque seul le titre est disponible et en présence de bruit dans les étiquettes.
Termes de l'index - Apprentissage automatique, erreur d'étiquetage, bruit, rapport de bogue de sécurité, référentiels de bogues.
I. INTRODUCTION
L’identification des problèmes liés à la sécurité parmi les bogues signalés est un besoin pressant parmi les équipes de développement de logiciels, car ces problèmes demandent des correctifs plus accélérés afin de répondre aux exigences de conformité et de garantir l’intégrité des données logicielles et client.
Le Machine Learning et les outils d’intelligence artificielle promettent de rendre le développement logiciel plus rapide, agile et correct. Plusieurs chercheurs ont appliqué le Machine Learning au problème d’identification des bogues de sécurité [2], [7], [8], [18]. Les études publiées précédentes ont supposé que l’ensemble du rapport de bogues est disponible pour l’entraînement et le scoring d’un modèle Machine Learning. Ce n’est pas nécessairement le cas. Il existe des situations où l’ensemble du rapport de bogues ne peut pas être mis à disposition. Par exemple, le rapport de bogue peut contenir des mots de passe, des informations d’identification personnelle (PII) ou d’autres types de données sensibles , un cas auquel nous sommes actuellement confrontés chez Microsoft. Il est donc important d’établir la façon dont l’identification des bogues de sécurité peut être effectuée à l’aide de moins d’informations, par exemple lorsque seul le titre du rapport de bogues est disponible.
En outre, les référentiels de bogues contiennent souvent des entrées mal étiquetées [7] : les rapports de bogues non sécurisés classés comme liés à la sécurité et inversement. Il y a plusieurs raisons pour lesquelles il y a des erreurs d’étiquetage, allant de l’absence d’expertise de l’équipe de développement en matière de sécurité, au manque d’expertise de certains problèmes, par exemple, il est possible que les bogues non-sécurité soient exploités de manière indirecte afin de provoquer une implication en matière de sécurité. Il s’agit d’un problème grave, car l’étiquetage incorrect des SBR entraîne l’examen manuel de la base de données des bogues dans un effort coûteux et fastidieux. Comprendre comment le bruit affecte différents classifieurs et à quel point les techniques d’apprentissage automatique sont robustes (ou fragiles) en présence de jeux de données contaminés par différents types de bruit est un problème qui doit être résolu pour intégrer la classification automatique dans la pratique de l’ingénierie logicielle.
Les travaux préliminaires font valoir que les référentiels de bogues sont intrinsèquement bruyants et que le bruit peut avoir un effet négatif sur les classifieurs de Machine Learning de performances [7]. Toutefois, il manque toute étude systématique et quantitative de la façon dont différents niveaux et types de bruit affectent les performances des différents algorithmes de Machine Learning supervisés pour le problème d’identification des rapports de bogues de sécurité (SRB).
Cette étude montre que la classification des rapports de bogues peut être effectuée même lorsque seul le titre est disponible pour la formation et la notation. À notre connaissance, c'est la toute première étude à le faire. En outre, nous fournissons la première étude systématique de l’effet du bruit dans la classification des rapports de bogues. Nous faisons une étude comparative de la robustesse de trois techniques d’apprentissage automatique (régression logistique, naïve Bayes et AdaBoost) contre le bruit indépendant de la classe.
Bien qu’il existe certains modèles analytiques qui capturent l’influence générale du bruit pour quelques classifieurs simples [5], [6], ces résultats ne fournissent pas de limites serrées sur l’effet du bruit sur la précision et sont valides uniquement pour une technique d’apprentissage automatique particulière. Une analyse précise de l’effet du bruit dans les modèles Machine Learning est généralement effectuée en exécutant des expériences de calcul. Ces analyses ont été effectuées pour plusieurs scénarios allant des données de mesure logicielle [4], à la classification des images satellites [13] et aux données médicales [12]. Toutefois, ces résultats ne peuvent pas être traduits en notre problème spécifique, en raison de sa forte dépendance à la nature des jeux de données et du problème de classification sous-jacent. Au mieux de nos connaissances, il n’existe aucun résultat publié sur le problème de l’effet des jeux de données bruyants sur la classification des rapports de bogues de sécurité en particulier.
NOS CONTRIBUTIONS DE RECHERCHE :
Nous formons des classificateurs pour l’identification des rapports de bogues de sécurité (SBR) uniquement en fonction du titre des rapports. À notre connaissance, c’est la première étude à le faire. Les travaux précédents ont utilisé le rapport de bogue complet ou amélioré le rapport de bogues avec d’autres fonctionnalités complémentaires. La classification des bogues basés uniquement sur la vignette est particulièrement pertinente lorsque les rapports de bogues complets ne peuvent pas être mis à disposition en raison de problèmes de confidentialité. Par exemple, il est connu le cas de rapports de bogues qui contiennent des mots de passe et d’autres données sensibles.
Nous fournissons également la première étude systématique de la tolérance au bruit des différents modèles et techniques d’apprentissage automatique utilisés pour la classification automatique des SBR. Nous effectuons une étude comparative de la robustesse de trois techniques d’apprentissage automatique distinctes (régression logistique, naïve Bayes et AdaBoost) contre le bruit dépendant de la classe et indépendant de la classe.
Le reste du document est présenté comme suit : Dans la section II, nous présentons quelques-unes des œuvres précédentes dans la littérature. Dans la section III, nous décrivons le jeu de données et la façon dont les données sont prétraitées. La méthodologie est décrite dans la section IV et les résultats de nos expériences analysées dans la section V. Enfin, nos conclusions et nos travaux futurs sont présentés dans VI.
II. TRAVAUX PRÉCÉDENTS
DES APPLICATIONS D’APPRENTISSAGE AUTOMATIQUE AUX RÉFÉRENTIELS DE BOGUES.
Il existe une documentation étendue sur l’application de l’exploration de texte, du traitement du langage naturel et du Machine Learning sur les référentiels de bogues dans une tentative d’automatiser des tâches laborieuses telles que la détection des bogues de sécurité [2], [7], [8], [18], identification du doublon de bogue [3], triage des bogues [11], pour nommer quelques applications. Idéalement, le mariage du Machine Learning (ML) et du traitement du langage naturel réduit potentiellement le travail manuel requis pour organiser les bases de données de bogues, raccourcir le temps nécessaire pour accomplir ces tâches et peut augmenter la fiabilité des résultats.
Dans [7], les auteurs proposent un modèle de langage naturel pour automatiser la classification des SBR en fonction de la description du bogue. Les auteurs extraient un vocabulaire de toute description de bogue dans le jeu de données d’entraînement et l’organisent manuellement en trois listes de mots : mots pertinents, mots vides (mots communs qui semblent inutiles pour la classification) et synonymes. Ils comparent les performances du classifieur de bogue de sécurité formé sur les données évaluées par les ingénieurs de sécurité et un classifieur formé sur les données étiquetées par les reporters de bogues en général. Bien que leur modèle soit clairement plus efficace lorsqu’il est formé aux données examinées par les ingénieurs de sécurité, le modèle proposé est basé sur un vocabulaire dérivé manuellement, ce qui le rend dépendant de la curation humaine. De plus, il n’existe aucune analyse de la façon dont différents niveaux de bruit affectent leur modèle, la façon dont différents classifieurs répondent au bruit et si le bruit dans l’une ou l’autre classe affecte les performances différemment.
Zou et. al [18] utilisent plusieurs types d’informations contenues dans un rapport de bogues qui impliquent les champs non textuels d’un rapport de bogues (métadonnées, par exemple, temps, gravité et priorité) et le contenu textuel d’un rapport de bogue (fonctionnalités textuelles, c’est-à-dire le texte dans les champs de synthèse). En fonction de ces fonctionnalités, ils créent un modèle pour identifier automatiquement les SBR via le traitement du langage naturel et les techniques d’apprentissage automatique. Dans [8] les auteurs effectuent une analyse similaire, mais ils comparent en outre les performances des techniques de Machine Learning supervisées et non supervisées, et étudient la quantité de données nécessaires pour entraîner leurs modèles.
Dans [2] les auteurs explorent également différentes techniques d’apprentissage automatique pour classifier les bogues en tant que SBR ou NSBR (Rapport de bogues non liés à la sécurité) en fonction de leurs descriptions. Ils proposent un pipeline pour le traitement des données et l’apprentissage des modèles en fonction de TFIDF. Ils comparent le pipeline proposé à un modèle basé sur un sac de mots (bag-of-words) ou Naive Bayes. Wijayasekara et al. [16] ont également utilisé des techniques d’exploration de texte pour générer le vecteur de fonctionnalité de chaque rapport de bogues en fonction de mots fréquents pour identifier les bogues d’impact masqué (HIBs). Yang et al[17] ont déclaré avoir identifié des rapports de bogues à fort impact (par exemple, des SBR) en utilisant la fréquence de terme (TF, Term Frequency) et Naive Bayes. Dans [9], les auteurs proposent un modèle pour prédire la gravité d’un bogue.
BRUIT D’ÉTIQUETTE
Le problème du traitement des jeux de données avec bruit dans les étiquettes a été largement étudié. Frenay et Verleysen proposent une taxonomie de bruit d’étiquette dans [6], afin de distinguer différents types d’étiquettes bruyantes. Les auteurs proposent trois types de bruit différents : bruit d’étiquette qui se produit indépendamment de la vraie classe et des valeurs des caractéristiques de l’instance ; bruit d’étiquette qui dépend uniquement de la véritable étiquette ; et bruit d’étiquette où la probabilité de mal étiquetage dépend également des valeurs des caractéristiques. Dans notre travail, nous étudions les deux premiers types de bruit. Du point de vue théorique, le bruit de l’étiquette diminue généralement les performances d’un modèle [10], sauf dans certains cas spécifiques [14]. En général, les méthodes robustes dépendent de l’évitement de tout surajustement pour gérer le bruit des étiquettes[15]. L’étude des effets sonores dans la classification a été effectuée avant dans de nombreux domaines tels que la classification d’images satellites [13], la classification de la qualité des logiciels [4] et la classification du domaine médical [12]. Pour le meilleur de nos connaissances, il n’y a pas de travaux publiés qui étudient la quantifiée précise des effets des étiquettes bruyantes dans le problème de la classification des SBR. Dans ce scénario, la relation précise entre les niveaux de bruit, les types de bruit et la dégradation des performances n’a pas été établie. De plus, il est utile de comprendre comment les classifieurs se comportent en présence de bruit. Plus généralement, nous ne sommes pas au courant de tout travail qui étudie systématiquement l’effet des jeux de données bruyants sur les performances des différents algorithmes de Machine Learning dans le contexte des rapports de bogues logiciels.
III. DESCRIPTION DU JEU DE DONNÉES
Notre jeu de données se compose de 1 073 149 titres de bogues, dont 552 073 correspondent aux SBR et 521 076 aux NSBR. Les données ont été collectées auprès de différentes équipes de Microsoft au cours des années 2015, 2016, 2017 et 2018. Toutes les étiquettes ont été obtenues par des systèmes de vérification de bogues basés sur des signatures ou par des étiquettes humaines. Les titres de bogues dans notre jeu de données sont des textes très courts, contenant environ 10 mots, avec une vue d’ensemble du problème.
A. Prétraitement des données. Nous analysons chaque titre de bogue sur la base de ses espaces pour produire une liste de jetons. Nous traitons chaque liste de jetons comme suit :
Supprimer tous les jetons qui sont des chemins d’accès aux fichiers
Jetons fractionnés où les symboles suivants sont présents : { , (, ), -, }, {, [, ], }
Supprimez les mots vides, les jetons composés uniquement de caractères numériques, et les jetons qui apparaissent moins de 5 fois dans l’ensemble du corpus.
IV. MÉTHODOLOGIE
Le processus d’entraînement de nos modèles Machine Learning se compose de deux étapes principales : l’encodage des données dans des vecteurs de caractéristiques et l’apprentissage de classifieurs de Machine Learning supervisés.
A. Vecteurs de caractéristiques et techniques de Machine Learning
La première partie implique l’encodage de données dans des vecteurs de caractéristiques à l’aide de l’algorithme TF-IDF (Term Frequency-Inverse Document Frequency), tel qu’utilisé ailleurs[2]. TF-IDF est une technique de recherche d'informations qui pèse la fréquence des termes (TF) et la fréquence inverse des documents (IDF). Chaque mot ou terme a son score TF et IDF respectifs. L’algorithme TF-IDF attribue l’importance à ce mot en fonction du nombre de fois qu’il apparaît dans le document, et plus important encore, il vérifie la pertinence du mot clé dans toute la collection de titres dans le jeu de données. Nous avons formé et comparé trois techniques de classification : naïve Bayes (NB), arbre de décision optimisé (AdaBoost) et régression logistique (LR). Nous avons choisi ces techniques parce qu'elles ont montré qu'elles performaient bien pour la tâche associée d'identifier les rapports de bogues de sécurité en fonction de l'ensemble du rapport dans la littérature. Ces résultats ont été confirmés dans une analyse préliminaire où ces trois classifieurs ont dépassé les machines vectorielles de prise en charge et les forêts aléatoires. Dans nos expériences, nous utilisons la bibliothèque scikit-learn pour l’encodage et l’entraînement des modèles.
B. Types de bruit
Le bruit étudié dans ce travail est celui de l’étiquette de la classe dans les données d’apprentissage. En présence de ce bruit, par conséquent, le processus d’apprentissage et le modèle résultant sont altérés par des exemples mal étiquetés. Nous analysons l’impact des différents niveaux de bruit appliqués aux informations de classe. Des types de bruit d’étiquette ont été abordés précédemment dans la littérature à l’aide de diverses terminologies. Dans notre travail, nous analysons les effets de deux bruits d’étiquette différents dans nos classifieurs : le bruit d’étiquette indépendant de la classe, qui est introduit par la sélection d’instances au hasard et le glissement de leur étiquette ; et le bruit dépendant de la classe, où les classes ont une probabilité différente d’être bruyantes.
a) Bruit indépendant de la classe : Le bruit indépendant de la classe fait référence au bruit qui se produit indépendamment de la classe réelle des instances. Dans ce type de bruit, la probabilité d’étiquetage incorrect pbr est la même pour toutes les instances du jeu de données. Nous introduisons un bruit indépendant de la classe dans nos jeux de données en inversant chaque étiquette dans notre jeu de données de façon aléatoire avec la probabilité pbr.
b) bruit dépendant de la classe: le bruit dépendant de la classe fait référence au bruit qui dépend de la classe réelle des instances. Dans ce type de bruit, la probabilité d’étiquetage incorrect dans la classe SBR est psbr et la probabilité d’étiquetage incorrect dans la classe NSBR est pnsbr. Nous introduisons un bruit dépendant de la classe dans notre jeu de données en inversant chaque entrée dans le jeu de données pour laquelle la véritable étiquette est SBR avec la probabilité psbr. Similairement, nous inversons l’étiquette de classe des instances NSBR avec la probabilité pnsbr.
c) bruit de classe unique: le bruit de classe unique est un cas spécial de bruit dépendant de la classe, où pnsbr = 0 et psbr> 0. Notez que, pour le bruit indépendant de la classe, nous avons psbr = pnsbr = pbr.
C. Génération de bruit
Nos expériences examinent l’impact des différents types et niveaux de bruit dans l’entraînement des classifieurs SBR. Dans nos expériences, nous définissons 25% du jeu de données comme données de test, 10% comme validation et 65% en tant que données d’apprentissage.
Nous ajoutons du bruit aux jeux de données d’entraînement et de validation pour différents niveaux de pbr, psbr et pnsbr . Nous n’apportez aucune modification au jeu de données de test. Les différents niveaux de bruit utilisés sont P = {0,05 × i|0 < i < 10}.
Dans les expériences de bruit indépendantes de la classe, pour pbr ∈ P, nous procédons comme suit :
Générer du bruit pour les jeux de données d’entraînement et de validation ;
Entraîner la régression logistique, les modèles Naïve Bayes et AdaBoost à l’aide d’un jeu de données d’entraînement (avec bruit) ; * Paramétrez les modèles à l’aide d’un jeu de données de validation (avec bruit) ;
Tester des modèles à l’aide d’un jeu de données de test (sans bruit).
Dans les expériences de bruit dépendant de la classe, pour psbr ∈ P et pnsbr ∈ P, nous procédons comme suit pour toutes les combinaisons de psbr et pnsbr:
Générer du bruit pour les jeux de données d’entraînement et de validation ;
Entraîner la régression logistique, les modèles Naïve Bayes et AdaBoost à l’aide d’un jeu de données d’entraînement (avec bruit) ;
Paramétrez les modèles à l’aide d’un jeu de données de validation (avec bruit) ;
Tester des modèles à l’aide d’un jeu de données de test (sans bruit).
V. RÉSULTATS EXPÉRIMENTAUX
Dans cette section, analysez les résultats des expériences effectuées en fonction de la méthodologie décrite dans la section IV.
a) Performances du modèle sans bruit dans le jeu de données d’entraînement: l’une des contributions de ce document est la proposition d’un modèle Machine Learning pour identifier les bogues de sécurité en utilisant uniquement le titre du bogue comme données pour la prise de décision. Cela permet l’apprentissage des modèles Machine Learning même lorsque les équipes de développement ne souhaitent pas partager des rapports de bogues en totalité en raison de la présence de données sensibles. Nous comparons les performances de trois modèles Machine Learning lorsqu’ils sont entraînés à l’aide uniquement de titres de bogues.
Le modèle de régression logistique est le classifieur le plus performant. Il s’agit du classifieur avec la valeur AUC la plus élevée, de 0,9826, rappel de 0,9353 pour une valeur FPR de 0,0735. Le classifieur Bayes naïve présente des performances légèrement inférieures à celles du classifieur de régression logistique, avec une AUC de 0,9779 et un rappel de 0,9189 pour un FPR de 0,0769. Le classifieur AdaBoost présente des performances inférieures par rapport aux deux classifieurs mentionnés précédemment. Son AUC est de 0,9143, avec un rappel de 0,7018 pour un FPR de 0,0774. La zone sous la courbe ROC (AUC) est une bonne métrique pour comparer les performances de plusieurs modèles, car elle résume en une seule valeur la relation TPR et FPR. Dans l’analyse suivante, nous allons limiter notre analyse comparative aux valeurs AUC.
Tableau 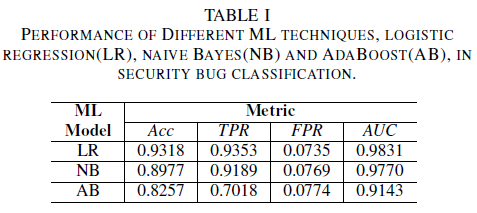
A. Bruit de la classe : classe unique
Il est possible d’imaginer un scénario où tous les bogues sont attribués à la classe NSBR par défaut, et un bogue n’est attribué qu’à la classe SBR s’il existe un expert en sécurité qui examine le référentiel de bogues. Ce scénario est représenté dans le contexte expérimental monoclasse, où nous supposons que pnsbr = 0 et 0 < psbr< 0,5.
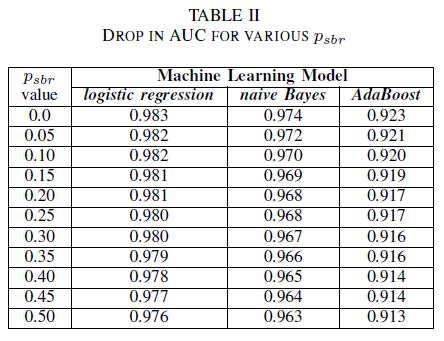
À partir du tableau II, nous observons un impact très faible dans l’AUC pour les trois classifieurs. Le AUC-ROC d’un modèle entraîné sur psbr = 0 par rapport à un AUC-ROC de modèle où psbr = 0,25 diffère de 0,003 pour la régression logistique, 0,006 pour naïve Bayes et 0,006 pour AdaBoost. Dans le cas de psbr = 0,50, l’AUC mesuré pour chacun des modèles diffère du modèle entraîné avec psbr = 0 par 0,007 pour la régression logistique, 0,011 pour naïve Bayes et 0,010 pour AdaBoost. classifieur de régression logistique formé en présence de bruit à classe unique présente la plus petite variation de sa métrique AUC, c’est-à-dire un comportement plus robuste, par rapport à nos classifieurs Naïve Bayes et AdaBoost.
B. Bruit de classe : indépendant de la classe
Nous comparons les performances de nos trois classifieurs lorsque le jeu d’apprentissage est altéré par un bruit indépendant de la classe. Nous mesurons l’AUC pour chaque modèle entraîné avec différents niveaux de pbr dans les données d’entraînement.
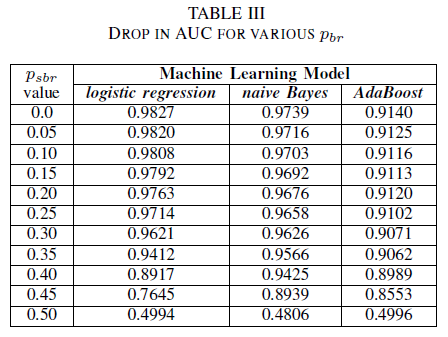
Dans le tableau III, nous observons une diminution de la AUC-ROC pour chaque incrément de bruit dans l’expérience. Le AUC-ROC mesuré à partir d’un modèle entraîné sur des données sans bruit, comparé à un AUC-ROC d’un modèle entraîné avec un bruit indépendant de la classe avec pbr = 0,25, diffère de 0,011 pour la régression logistique, de 0,008 pour Naïve Bayes et de 0,0038 pour AdaBoost. Nous constatons que le bruit de l’étiquette n’a pas d’impact sur l’AUC des classifieurs Naïve Bayes et AdaBoost de manière significative lorsque les niveaux de bruit sont inférieurs à 40%. En revanche, le classifieur par régression logistique accuse un impact dans la mesure de l’AUC pour les niveaux de bruit d’étiquette supérieurs à 30 %.
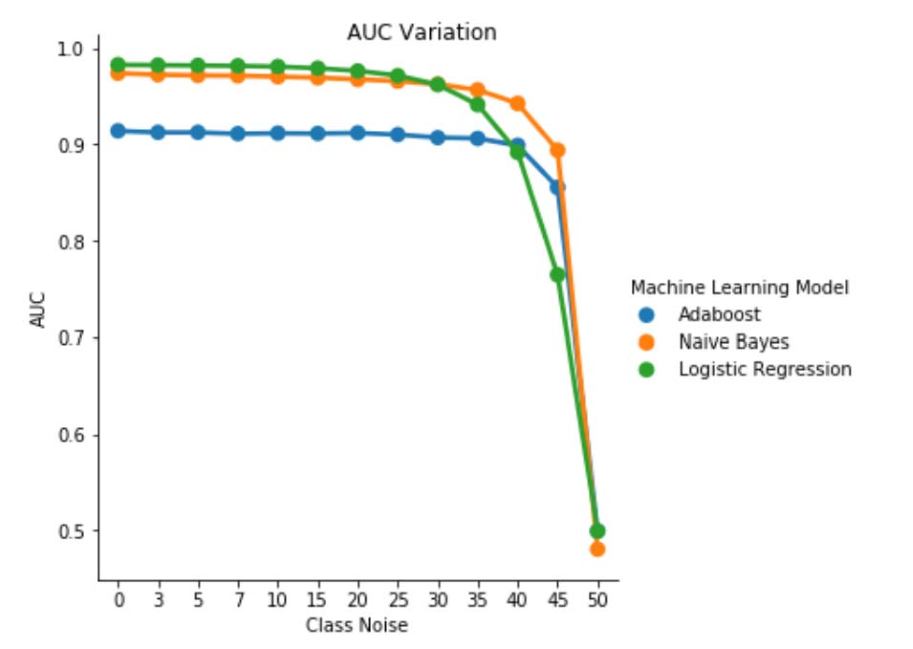
Fig. 1. Variation d’AUC-ROC dans le bruit indépendant de la classe. Pour un niveau de bruit pbr =0,5, le classifieur agit comme un classifieur aléatoire, c.-à-d. AUC≈0,5. Mais nous pouvons observer que pour des niveaux de bruit inférieurs (pbr ≤0.30), l’apprenant de régression logistique présente une meilleure performance par rapport aux deux autres modèles. Cependant, pour 0,35 ≤ pbr ≤ 0,45, le classifieur Naive Bayes présente de meilleures métriques d’AUC-ROC.
C. Bruit de classe : dépendant de la classe
Dans le dernier ensemble d’expériences, nous considérons un scénario où différentes classes contiennent différents niveaux de bruit, c’est-à-dire psbr ≠ pnsbr. Nous incrémentons systématiquement de 0,05, indépendamment, psbr et pnsbr dans les données d’apprentissage et observons le changement de comportement des trois classifieurs.
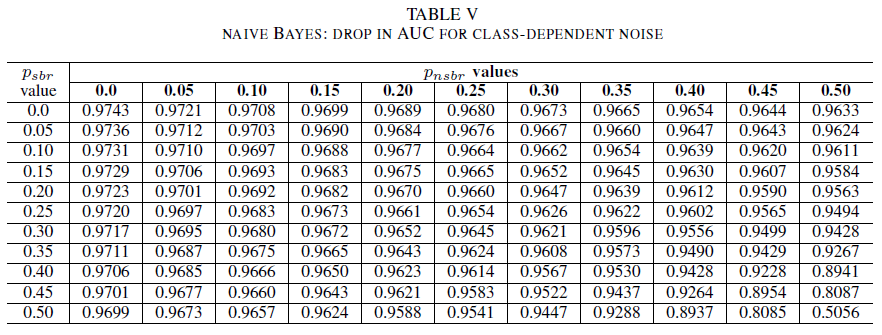
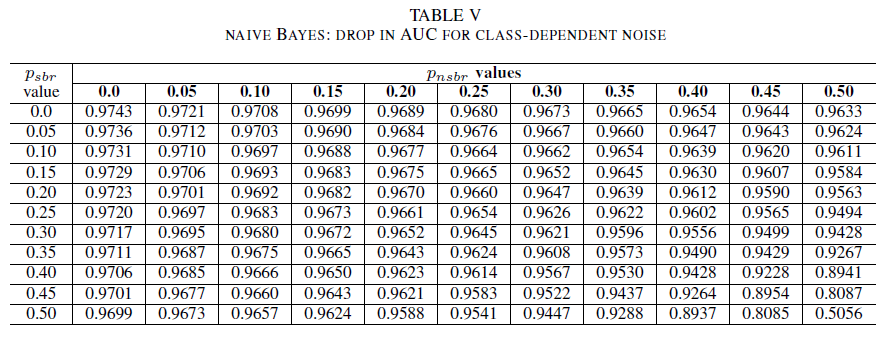
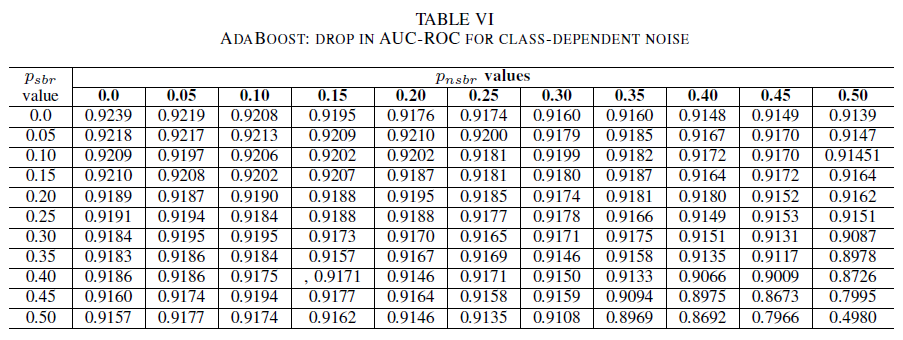
Les tableaux IV, V, VI montrent la variation de l’AUC à mesure que le bruit augmente dans différents niveaux pour chaque classe : pour la régression logistique dans le tableau IV, pour le naïf Bayes dans le tableau V et pour AdaBoost dans le tableau VI. Pour tous les classifieurs, nous constatons un impact sur la métrique de l’AUC lorsque les deux classes contiennent un niveau de bruit supérieur à 30 %. Le comportement du classifieur Naive Bayes est le plus robuste. L’impact sur l’AUC est très faible, même lorsque 50 % des étiquettes dans la classe positive sont inversées, pour autant que la classe négative contienne au maximum 30 % d’étiquettes bruyantes. Dans ce cas, la baisse de l’AUC est de 0,03. AdaBoost a présenté le comportement le plus robuste des trois classifieurs. Une modification significative de l’AUC ne se produit que pour les niveaux de bruit supérieurs à 45% dans les deux classes. Dans ce cas, nous commençons à observer une dégradation de l’AUC supérieure à 0,02.
D. Sur la présence de bruit résiduel dans le jeu de données d’origine
Notre jeu de données a été étiqueté par des systèmes automatisés basés sur des signatures et par des experts humains. De plus, tous les rapports de bogues ont été examinés et fermés par des experts humains. Bien que nous nous attendons à ce que la quantité de bruit dans notre jeu de données soit minimale et non statistiquement significative, la présence de bruit résiduel n’invalide pas nos conclusions. En effet, à titre d'illustration, supposons que l'ensemble de données original soit corrompu par un bruit indépendant de la classe égal à 0 < p < 1/2 indépendant et identiquement distribué (i.i.d) pour chaque entrée.
Si nous ajoutons, au-dessus du bruit d'origine, un bruit indépendant de la classe avec la probabilité pbr i.i.d, le bruit résultant par entrée sera p∗ = p(1 − pbr ) + (1 − p)pbr. Pour 0 < p,pbr< 1/2, nous avons que le bruit réel par étiquette p∗ est strictement plus grand que le bruit que nous ajoutons artificiellement au jeu de données pbr . Ainsi, les performances de nos classifieurs seraient encore mieux si elles étaient entraînées avec un jeu de données totalement sans bruit (p = 0) en premier lieu. En résumé, l’existence d’un bruit résiduel dans le jeu de données réel signifie que la résilience contre le bruit de nos classifieurs est meilleure que les résultats présentés ici. De plus, si le bruit résiduel dans notre jeu de données était statistiquement pertinent, l’AUC de nos classifieurs deviendrait 0,5 (une estimation aléatoire) pour un niveau de bruit strictement inférieur à 0,5. Nous n’observons pas ce comportement dans nos résultats.
VI. CONCLUSIONS ET TRAVAUX FUTURS
Notre contribution dans ce document est double.
Tout d’abord, nous avons montré la faisabilité de la classification des rapports de bogues de sécurité basée uniquement sur le titre du rapport de bogues. Cela est particulièrement pertinent dans les scénarios où l’ensemble du rapport de bogues n’est pas disponible en raison de contraintes de confidentialité. Par exemple, dans notre cas, les rapports de bogues contenaient des informations privées telles que des mots de passe et des clés de chiffrement et n’étaient pas disponibles pour l’apprentissage des classifieurs. Notre résultat montre que l’identification SBR peut être effectuée à haute précision même si seuls les titres de rapport sont disponibles. Notre modèle de classification qui utilise une combinaison de TF-IDF et de régression logistique s’effectue à une AUC de 0,9831.
Ensuite, nous avons analysé l’effet des données d’apprentissage et de validation mal étiquetées. Nous avons comparé trois techniques de classification du Machine Learning connues (naïve Bayes, régression logistique et AdaBoost) en termes de robustesse contre différents types de bruit et niveaux de bruit. Les trois classifieurs sont robustes pour un bruit d’une seule classe. Le bruit dans les données d’apprentissage n’a aucun effet significatif dans le classifieur résultant. La diminution de l’AUC est très petite (0,01) pour un niveau de bruit de 50%. Pour le bruit présent dans les deux classes et indépendant de la classe, les modèles Naive Bayes et AdaBoost présentent des variations significatives d’AUC uniquement quand ils sont formés avec un jeu de données dans lequel les niveaux de bruit sont supérieurs à 40 %.
Enfin, un bruit dépendant de la classe a un impact significatif sur l’AUC uniquement quand il y a plus de 35 % de bruit dans les deux classes. AdaBoost a montré la plus robustesse. L’impact sur l’AUC est très faible même lorsque la classe positive a 50% de ses étiquettes bruyantes, à partir du moment où la classe négative contient 45% d’étiquettes bruyantes ou moins. Dans ce cas, la baisse de l’AUC est inférieure à 0,03. Au mieux de nos connaissances, il s’agit de la première étude systématique sur l’effet des jeux de données bruyants pour l’identification des rapports de bogues de sécurité.
FUTURS TRAVAUX
Dans ce document, nous avons commencé l’étude systématique des effets du bruit dans les performances des classifieurs machine learning pour l’identification des bogues de sécurité. Il existe plusieurs suites intéressantes à ce travail, notamment : examen de l’effet des jeux de données bruyants pour déterminer le niveau de gravité d’un bogue de sécurité ; comprendre l’effet du déséquilibre de classe sur la résilience des modèles entraînés contre le bruit ; comprendre l’effet du bruit introduit de manière contradictoire dans le jeu de données.
RÉFÉRENCES
John Anvik, Lyndon Hiew et Gail C Murphy[1]. Qui doit résoudre ce bogue ? Dans les actes de la 28e conférence internationale sur l'ingénierie logicielle, pages 361–370. ACM, 2006.
Diksha Behl, Sahil Handa et Anuja Arora[2]. Outil d’exploration de bogues pour identifier et analyser les bogues de sécurité avec Bayes naïf et tf-idf. Dans Optimisation, Fiabilité et Technologie de l’information (ICROIT), conférence internationale de 2014, pages 294-299. IEEE, 2014.
Nicolas Bettenburg, Rahul Premraj, Thomas Zimmermann et Sunghun Kim[3]. Les rapports de bogues en double sont-ils vraiment considérés comme nuisibles ? Dans Software maintenance, 2008. ICSM 2008. Conférence internationale de l'IEEE, pages 337-345. IEEE, 2008.
Andres Folleco, Taghi M Khoshgoftaar, Jason Van Hulse et Lofton Bullard[4]. Identification des apprenants robustes aux données de faible qualité. Dans Réutilisation et intégration des informations, 2008. IRI 2008. IEEE International Conference on, p. 190-195. IEEE, 2008.
[5] Benoît Frenay. L'incertitude et le bruit d'étiquettes dans l'apprentissage automatique. Thèse de doctorat, Université catholique de Louvain, Louvain-la-Neuve, Belgique, 2013.
[6] Benoıt Frenay et Michel Verleysen. Classification en présence de bruit d’étiquette : une étude. transactions IEEE sur les réseaux neuronaux et les systèmes d’apprentissage, 25(5) :845-869, 2014.
Michael Gegick, Pete Rotella et Tao Xie[7]. Identification des rapports de bogues de sécurité via l’exploration de texte : étude de cas industrielle. Dans Mining software repositories (MSR), 2010 7th IEEE working conference, pages 11–20. IEEE, 2010.
Katerina Goseva-Popstojanova et Jacob Tyo[8]. Identification des rapports de bogues liés à la sécurité via l’exploration de texte à l’aide de la classification supervisée et non supervisée. Dans 2018 IEEE International Conference on Software Quality, Reliability and Security (QRS), pages 344 à 355, 2018.
Ahmed Lamkanfi, Serge Demeyer, Emmanuel Giger et Bart Goethals [9] Ahmed Lamkanfi. Prédiction de la gravité d’un bogue signalé. Dans Mining Software Repositories (MSR), 2010 7th IEEE Working Conference, pages 1 à 10. IEEE, 2010.
Naresh Manwani et PS Sastry[10]. Tolérance au bruit sous la réduction des risques. IEEE Transactions on Cybernetics, 43(3) : 1146-1151, 2013.
G Murphy et D Cubranic[11]. Tri automatique des bogues à l’aide de la catégorisation de texte. Dans Actes de la Seizième Conférence internationale sur l’ingénierie logicielle & Ingénierie des connaissances. Citeseer, 2004.
[12] Mykola Pechenizkiy, Alexey Tsymbal, Seppo Puuronen et Oleksandr Pechenizkiy. Bruit de classe et apprentissage supervisé dans les domaines médicaux : effet de l’extraction de caractéristiques. Dans null, pages 708 à 713. IEEE, 2006.
[13] Charlotte Pelletier, Silvia Valero, Jordi Inglada, Nicolas Champion, Claire Marais Sicre, et Gérard Dedieu : « Effect of training class label noise on classification performances for land cover mapping with satellite image time series » (Effet du bruit des étiquettes des classes d'apprentissage sur les performances de classification pour la cartographie de l'occupation du sol avec des séries temporelles d'images satellite). Télédétection, 9(2):173, 2017.
[14] PS Sastry, GD Nagendra, et Naresh Manwani. A team of continuous action learning automata for noise-tolerant learning of half-spaces. Transactions IEEE sur les Systèmes, Homme et Cybernétique, Partie B (Cybernétique), 40(1):19–28, 2010.
[15] Choh-Man Teng. Comparaison des techniques de gestion du bruit. Dans FLAIRS Conference, pages 269 à 273, 2001.
Dumidu Wijayasekara, Milos Manic et Miles McQueen[16]. Identification et classification des vulnérabilités via des bases de données de bogues d’exploration de texte. Dans Société d'Électronique Industrielle, IECON 2014 - 40ème Conférence Annuelle de l'IEEE, pages 3612-3618. IEEE, 2014.
[17] Xinli Yang, David Lo, Qiao Huang, Xin Xia et Jianling Sun. Identification automatisée des rapports de bogues à impact élevé tirant parti de stratégies d’apprentissage déséquilibrées. Dans Computer Software and Applications Conference (COMPSAC), 2016 IEEE 40th Annual, volume 1, pages 227 à 232. IEEE, 2016.
[18] Deqing Zou, Zhijun Deng, Jen Li et Hai Jin. Identification automatique des rapports de bogues de sécurité via l’analyse des fonctionnalités multitypes. Dans Conférence australe sur la sécurité de l’information et la confidentialité, pages 619-633. Springer, 2018.