Comment utiliser Visual Studio Code pour déployer des applications sur Clusters Big Data SQL Server
S’applique à : ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Cet article explique comment déployer des applications sur un cluster Big Data SQL Server. Nous allons utiliser Microsoft Visual Studio Code et l’extension App Deploy.
Important
Le module complémentaire Clusters Big Data Microsoft SQL Server 2019 sera mis hors service. La prise en charge de la plateforme Clusters Big Data Microsoft SQL Server 2019 se terminera le 28 février 2025. Tous les utilisateurs existants de SQL Server 2019 avec Software Assurance seront entièrement pris en charge sur la plateforme, et le logiciel continuera à être maintenu par les mises à jour cumulatives SQL Server jusqu’à ce moment-là. Pour plus d’informations, consultez le billet de blog d’annonce et les Options Big Data sur la plateforme Microsoft SQL Server.
Prérequis
Fonctionnalités
L’extension App Deploy prend en charge les tâches suivantes dans Visual Studio Code :
- Fournit l’authentification auprès du cluster Big Data SQL Server.
- Récupère un modèle d’application à partir du dépôt GitHub pour le déploiement de runtimes pris en charge.
- Gère les modèles d’application actuellement ouverts dans l’espace de travail de l’utilisateur.
- Déploie une application via une spécification au format YAML.
- Gère les applications déployées dans un cluster Big Data SQL Server.
- Affiche toutes les applications que vous avez déployées, ainsi que d’autres informations, dans la barre latérale.
- Génère une spécification d’exécution pour consommer ou supprimer l’application dans le cluster.
- Consomme les applications déployées via une spécification d’exécution YAML.
Les sections suivantes décrivent les étapes d’installation d’App Deploy. Elles présentent également une vue d’ensemble du fonctionnement de l’extension.
Comment installer l’extension App Deploy dans Visual Studio Code
Dans Visual Studio Code, installez l’extension App Deploy :
Pour installer App Deploy avec Visual Studio Code, téléchargez l’extension à partir de GitHub.
Lancez Visual Studio Code et accédez à la barre latérale Extensions.
Cliquez sur le
…menu contextuel en haut de la barre latérale et sélectionnezInstall from vsix.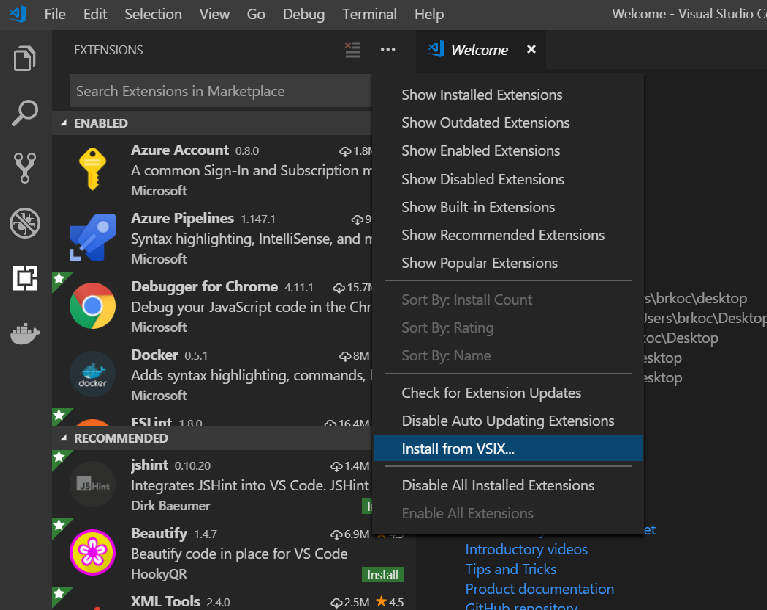
Recherchez le fichier
sqlservbdc-app-deploy.vsixque vous avez téléchargé et sélectionnez-le pour l’installer.
Une fois App Deploy correctement installé, un message vous invite à recharger Visual Studio Code. Vous devez maintenant voir l’Explorateur d’applications du cluster Big Data SQL Server dans la barre latérale de Visual Studio Code.
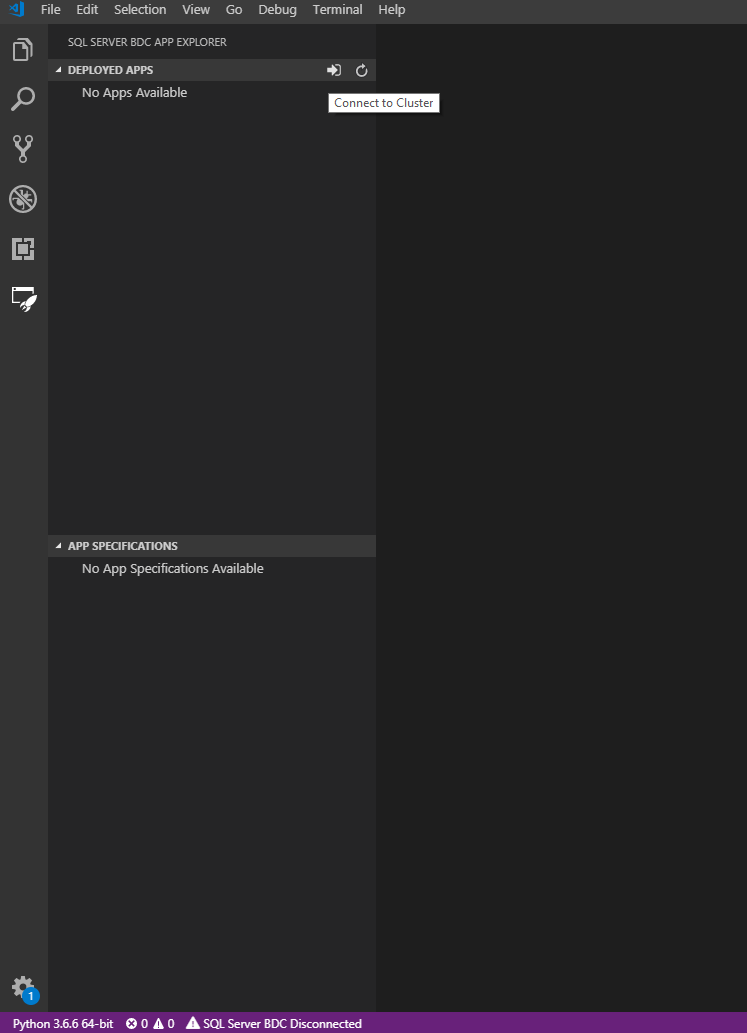
Charger l’Explorateur d’applications
Sélectionnez l’icône Extensions dans la barre latérale. Un panneau latéral charge et affiche l’Explorateur d’applications.
Établir une connexion au point de terminaison du cluster
Vous pouvez utiliser les méthodes suivantes pour vous connecter au point de terminaison du cluster :
- Cliquez sur la barre d’état dans le bas, indiquant
SQL Server BDC Disconnected. - Vous pouvez aussi cliquer sur le bouton
Connect to Clusteren haut avec la flèche pointant vers une entrée de porte.
Visual Studio Code vous demande le point de terminaison, le nom d’utilisateur et le mot de passe appropriés.
Connectez-vous au point de terminaison Cluster Management Service sur le port 30080.
Vous pouvez également trouver ce point de terminaison à partir de la ligne de commande en utilisant cette commande :
azdata bdc endpoint list
Une autre façon de récupérer ces informations consiste à accéder au serveur dans Azure Data Studio et à cliquer avec le bouton droit sur Gérer. Les points de terminaison des services sont listés.
Recherchez le point de terminaison que vous souhaitez utiliser, puis connectez-vous au cluster.
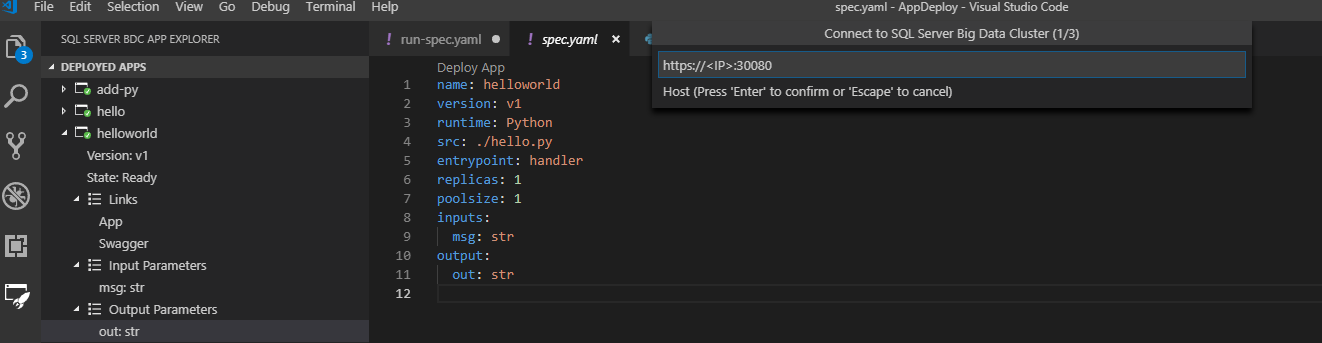
Une fois la connexion établie, Visual Studio Code vous informe que vous êtes connecté au cluster. Les applications déployées sont affichées dans la barre latérale, et votre point de terminaison et votre nom d’utilisateur sont enregistrés sous ./sqldbc dans votre profil utilisateur. Les mots de passe ou jetons ne sont jamais enregistrés. Lors des connexions suivantes, l’invite préremplit l’hôte et votre nom d’utilisateur enregistrés, mais vous demande toujours d’entrer un mot de passe. Si vous voulez vous connecter à un autre point de terminaison du cluster, sélectionnez New Connection. La connexion est automatiquement fermée lorsque vous quittez Visual Studio Code et quand vous ouvrez un autre espace de travail. Vous devrez alors vous reconnecter.
Créer un modèle d’application
Dans Visual Studio Code, ouvrez un espace de travail à l’emplacement où vous souhaitez enregistrer vos artefacts d’application.
Pour déployer une nouvelle application à partir d’un modèle, sélectionnez le bouton Nouveau modèle d’application dans le volet Spécifications de l’application. Une invite vous demande où vous souhaitez enregistrer le nom, le runtime et la nouvelle application sur votre machine locale. Le nom et la version que vous indiquez doivent être une étiquette DNS-1035 et contenir des caractères alphanumériques minuscules ou le tiret « - ». De plus, ils doivent commencer par un caractère alphabétique et se terminer par un caractère alphanumérique.
Placez de préférence l’extension dans votre espace de travail Visual Studio Code actif. Vous bénéficierez ainsi des fonctionnalités complètes de l’extension.
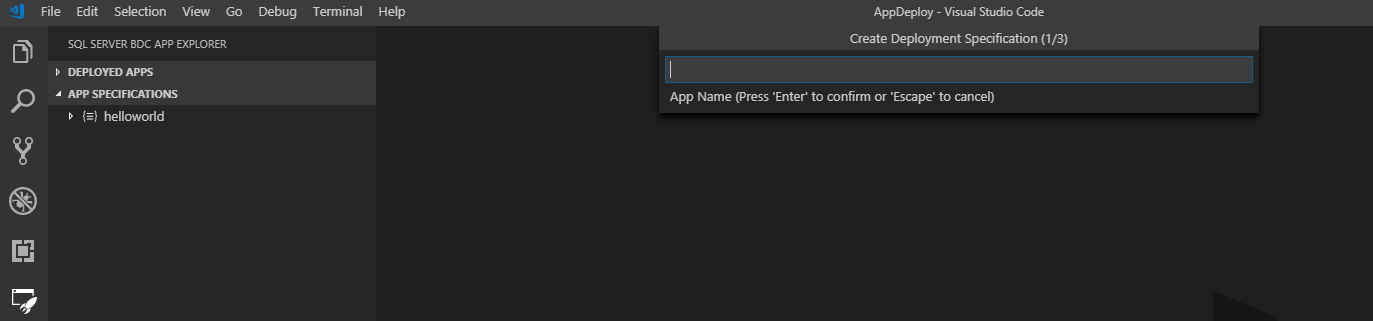
Une fois l’opération terminée, un modèle de nouvelle application est automatiquement généré à l’emplacement que vous avez spécifié, et le fichier spec.yaml de déploiement s’ouvre dans votre espace de travail. Si le répertoire sélectionné se trouve dans votre espace de travail, il est listé dans le volet Spécifications de l’application :
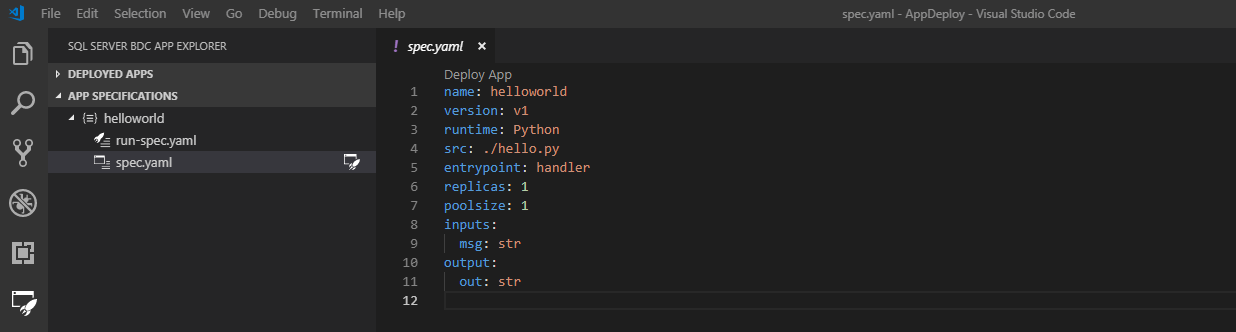
Le nouveau modèle est une application helloworld simple qui se présente dans le volet Spécifications de l’application de la façon suivante :
- spec.yaml
- Indique au cluster comment déployer votre application
- run-spec.yaml
- Indique au cluster comment vous voulez appeler votre application
Le code source de l’application se trouve dans le dossier Espace de travail.
- Nom du fichier source
- Il s’agit de votre fichier de code source tel que spécifié par
srcdansspec.yaml - Il a une seule fonction appelée
handler, qui est considérée commeentrypointde l’application, comme montré dansspec.yaml. Elle prend une entrée de chaîne appeléemsget retourne une sortie de chaîne appeléeout. Celles-ci sont spécifiées dansinputsetoutputsdu fichierspec.yaml.
- Il s’agit de votre fichier de code source tel que spécifié par
Si vous préférez utiliser le fichier spec.yaml au lieu d’un modèle généré automatiquement pour déployer une application, sélectionnez le bouton New Deploy Spec situé à côté du bouton New App Template. Répétez le même processus. Vous obtenez uniquement le fichier spec.yaml, que vous êtes libre de modifier.
Déployer votre application
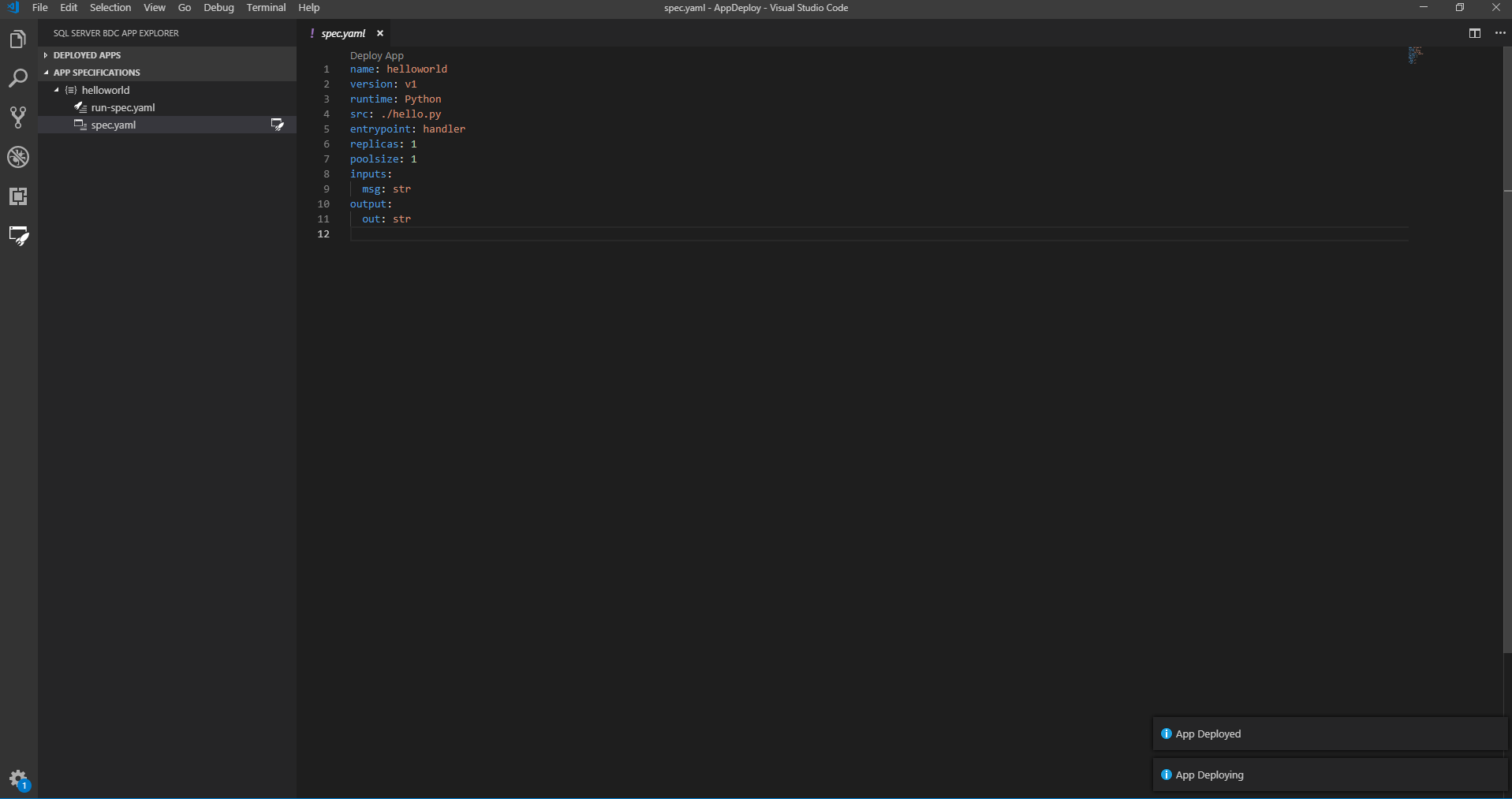
Vous pouvez déployer votre application instantanément via le CodeLens Deploy App dans le fichier spec.yaml, ou en sélectionnant le bouton du dossier avec un éclair en regard du fichier spec.yaml dans le menu Spécifications de l’application. L’extension compresse tous les fichiers dans le répertoire contenant votre fichier spec.yaml. Elle déploie ensuite votre application sur le cluster.
Notes
Le fichier spec.yaml doit se trouver au niveau racine du répertoire du code source de votre application. Vérifiez aussi que tous les fichiers de l’application se trouvent dans le même répertoire que le fichier spec.yaml.
L’état de l’application dans la barre latérale vous avertit quand l’application est prête à être utilisée :
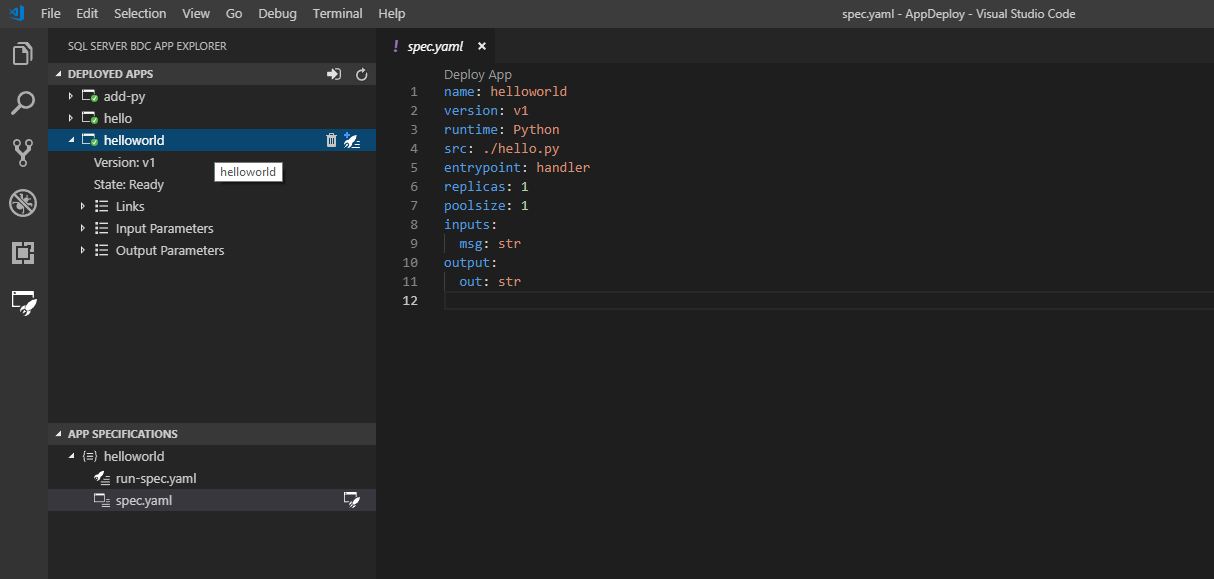

Le volet latéral affiche les informations suivantes :
Vous voyez toutes les applications que vous avez déployées, ainsi que ces liens :
- state
- version
- paramètres d'entrée
- paramètres de sortie
- liens
- fichier Swagger
- details
Notez que, si vous cliquez sur links, vous accédez au fichier swagger.json de l’application déployée. Vous pouvez ici écrire des clients pour appeler votre application :
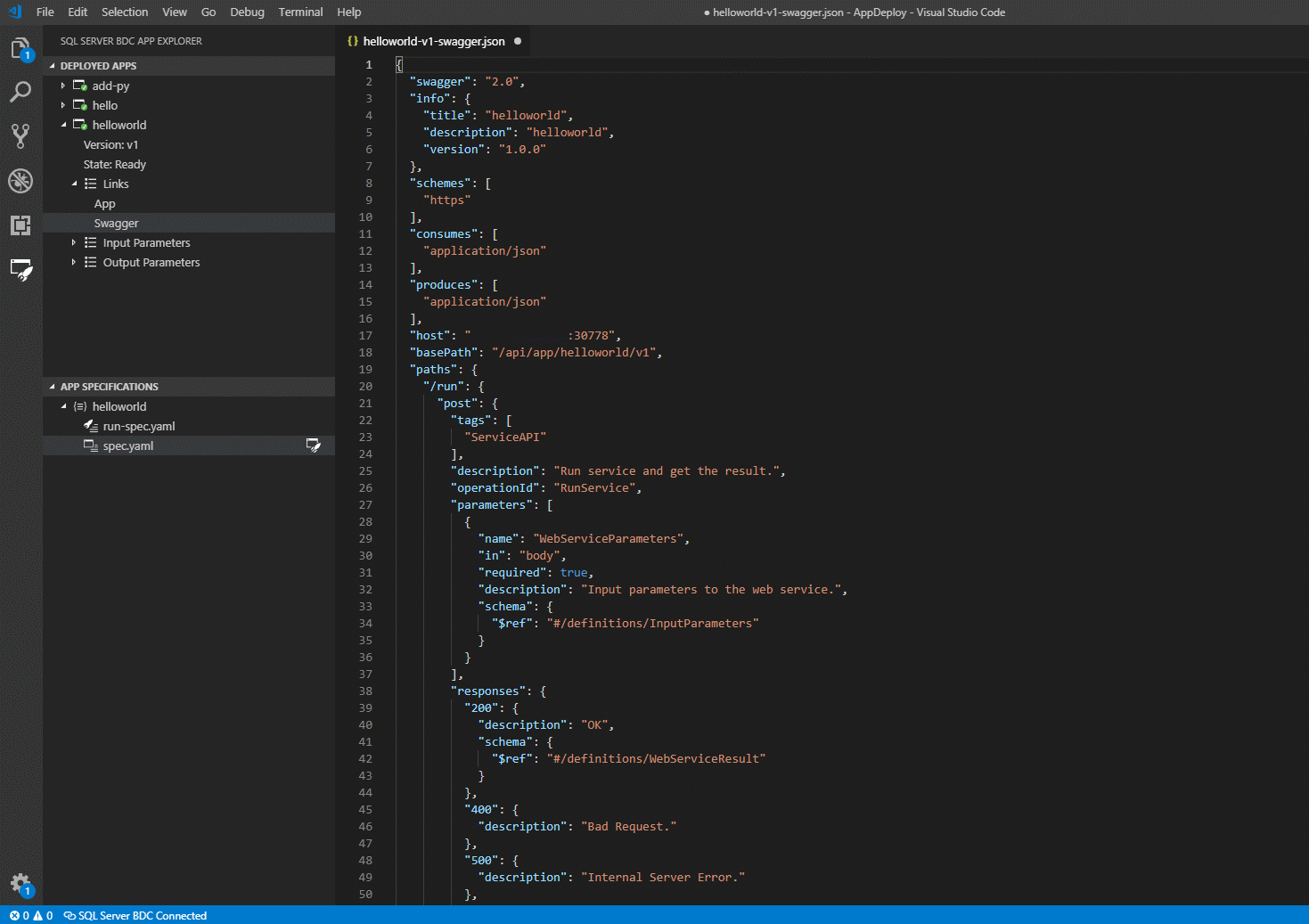
Pour plus d’informations, consultez Utiliser des applications sur des clusters Big Data.
Exécuter l’application
Une fois votre application prête, appelez-la avec run-spec.yaml. Ce fichier est fourni avec le modèle d’application :
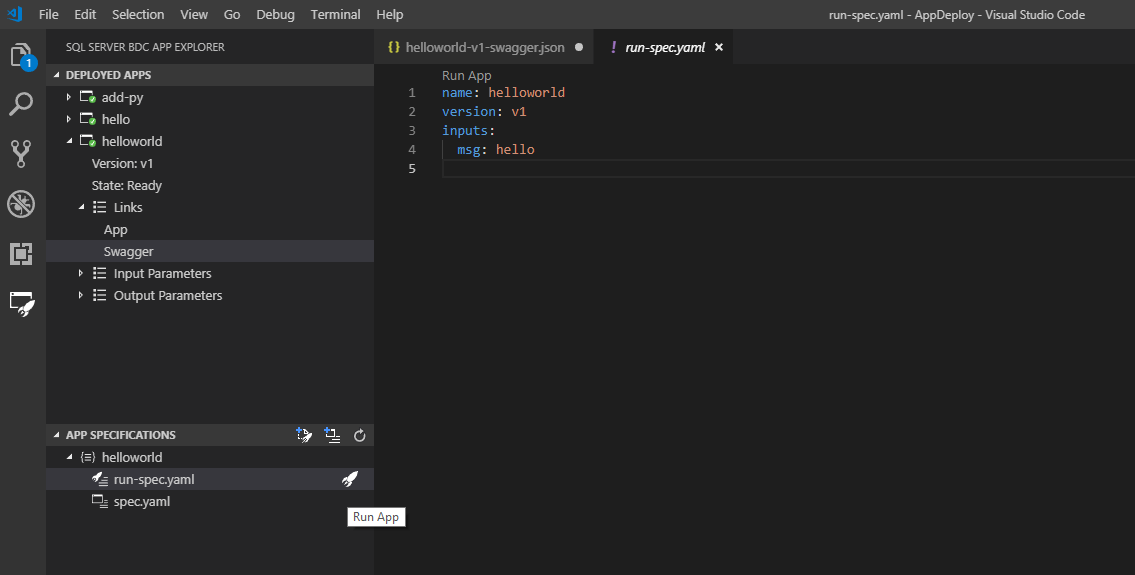
Spécifiez une chaîne à la place de hello. Ensuite, réexécutez votre application en utilisant le lien CodeLens ou le bouton Éclair dans la barre latérale. Si vous ne voyez pas l’option run-spec, générez-en une à partir de l’application déployée dans le cluster :
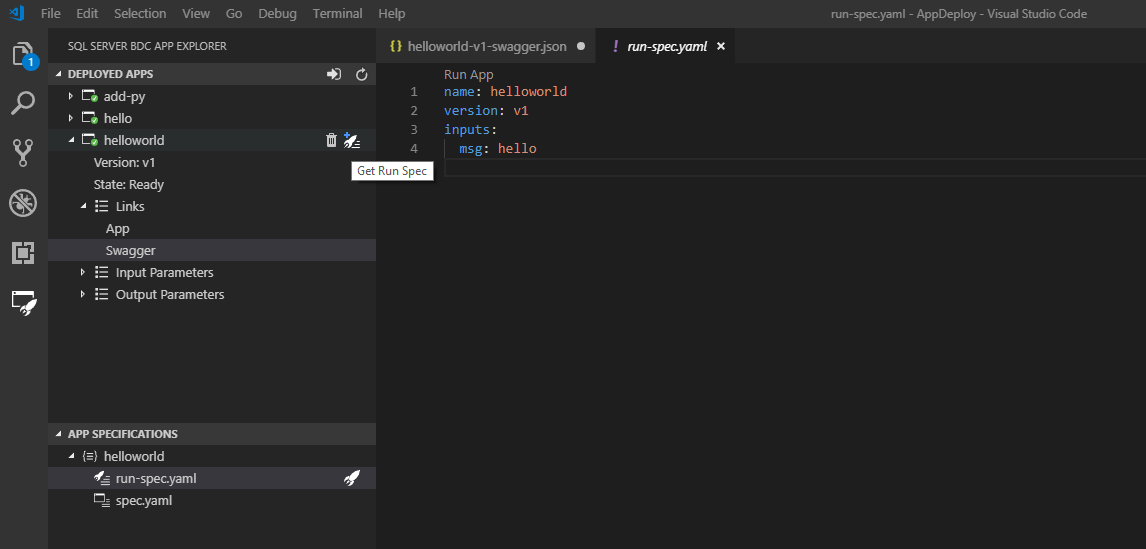
Après avoir modifié votre spécification d’exécution, exécutez-la. Visual Studio Code retourne un commentaire à la fin de l’exécution de l’application :
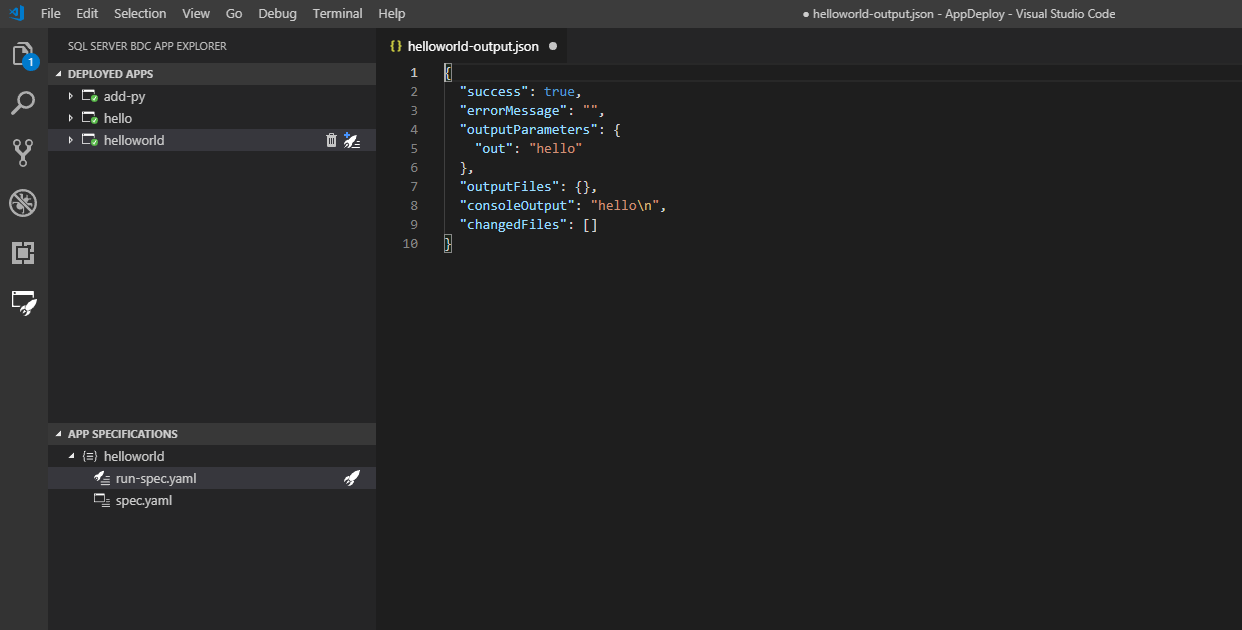
Dans la capture d’écran précédente, vous voyez que la sortie est retournée dans un fichier .json temporaire dans votre espace de travail. Si vous souhaitez conserver cette sortie, vous pouvez l’enregistrer. Sinon, elle sera supprimée à la fermeture. Si votre application n’a pas de sortie à écrire dans un fichier, vous recevez seulement la notification d’état Successful App Run. Si l’exécution a échoué, vous recevez un message d’erreur qui vous aide à déterminer la cause du problème.
Lors de l’exécution d’une application, vous disposez de plusieurs façons de passer des paramètres :
Vous pouvez spécifier toutes les entrées nécessaires dans un fichier .json, comme ceci :
inputs: ./example.json
Spécifiez le type de paramètre inline quand une application déployée est appelée et que les paramètres d’entrée ne sont pas des paramètres primitifs. C’est le cas avec les tableaux, les vecteurs, les dataframes, les JSON complexes, etc. :
- Vecteur
inputs:x: [1, 2, 3]
- Matrice
inputs:x: [[A,B,C],[1,2,3]]
- Object
inputs:x: {A: 1, B: 2, C: 3}
Ou passez une chaîne à un fichier .txt, .json ou .csv au format requis par votre application. Dans cet exemple, l’analyse du fichier est basée sur Node.js Path library, où un chemin de fichier est défini en tant que string that contains a / or \ character.
Si aucun paramètre d’entrée requis n’est fourni, un message d’erreur s’affiche. Le message indique soit le chemin de fichier incorrect si un chemin de fichier de type chaîne a été donné, soit le paramètre qui n’est pas valide. Le créateur de l’application doit s’assurer qu’il définit les paramètres de manière appropriée.
Pour supprimer une application, accédez à l’application dans le volet latéral Deployed Apps et sélectionnez l’icône Corbeille.
Étapes suivantes
Pour plus d’informations, découvrez comment intégrer des applications déployées sur des Clusters Big Data SQL Server dans vos propres applications en consultant Consommer des applications sur des clusters Big Data. Vous pouvez également vous reporter aux exemples supplémentaires de Exemples de déploiement d’applications pour essayer l’extension.
Pour plus d’informations sur Clusters Big Data SQL Server, consultez Présentation des Clusters de Big Data SQL Server 2019.
Notre objectif est de rendre cette extension pratique à utiliser : nous apprécions donc votre feedback. Envoyez-le à l’SQL Serveréquipe.