Concepts de sécurité pour les Clusters Big Data SQL Server
S’applique à : ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
Le module complémentaire Clusters Big Data Microsoft SQL Server 2019 sera mis hors service. La prise en charge de la plateforme Clusters Big Data Microsoft SQL Server 2019 se terminera le 28 février 2025. Tous les utilisateurs existants de SQL Server 2019 avec Software Assurance seront entièrement pris en charge sur la plateforme, et le logiciel continuera à être maintenu par les mises à jour cumulatives SQL Server jusqu’à ce moment-là. Pour plus d’informations, consultez le billet de blog d’annonce et les Options Big Data sur la plateforme Microsoft SQL Server.
Cet article aborde les principaux concepts liés à la sécurité de clés.
Les Clusters Big Data SQL Server assurent des fonctionnalités d’autorisation et d’authentification uniformes et cohérentes. Un cluster Big Data peut être intégré à Active Directory (AD) par le biais d’un déploiement entièrement automatisé qui configure l’intégration AD sur un domaine existant. Une fois qu’un cluster Big Data est configuré avec l’intégration AD, vous pouvez tirer parti des identités et des groupes d’utilisateurs existants pour un accès unifié sur tous les points de terminaison. En outre, une fois que vous avez créé des tables externes dans SQL Server, vous pouvez contrôler l’accès aux sources de données en accordant l’accès à des tables externes aux utilisateurs et groupes AD, en centralisant ainsi les stratégies d’accès aux données à un emplacement unique.
Dans cette vidéo de 14 minutes, vous obtiendrez une vue d’ensemble de la sécurité des clusters Big Data :
Authentification
Les points de terminaison de cluster externes prennent en charge l’authentification AD. Utilisez votre identité AD pour vous authentifier auprès du cluster Big Data.
Points de terminaison de cluster
Il existe cinq points d’entrée pour le cluster Big Data
Instance maître : point de terminaison TDS permettant d’accéder à l’instance maître SQL Server dans le cluster, en utilisant des outils de base de données et des applications comme SSMS ou Azure Data Studio. Lorsque vous utilisez des commandes HDFS ou SQL Server à partir de Azure Data CLI (
azdata), l’outil se connecte aux autres points de terminaison, en fonction de l’opération.Passerelle pour accéder aux fichiers HDFS, Spark (Knox) ; point de terminaison HTTPS pour accéder à des services tels que webHDFS et Spark.
Point de terminaison du service de gestion de cluster (contrôleur) : service de gestion de cluster Big Data qui expose les API REST pour gérer le cluster. L’outil azdata nécessite une connexion à ce point de terminaison.
Proxy de gestion : pour accéder au tableau de bord de recherche des journaux et au tableau de bord des métriques.
Proxy d’application : point de terminaison pour la gestion des applications déployées dans le cluster Big Data.
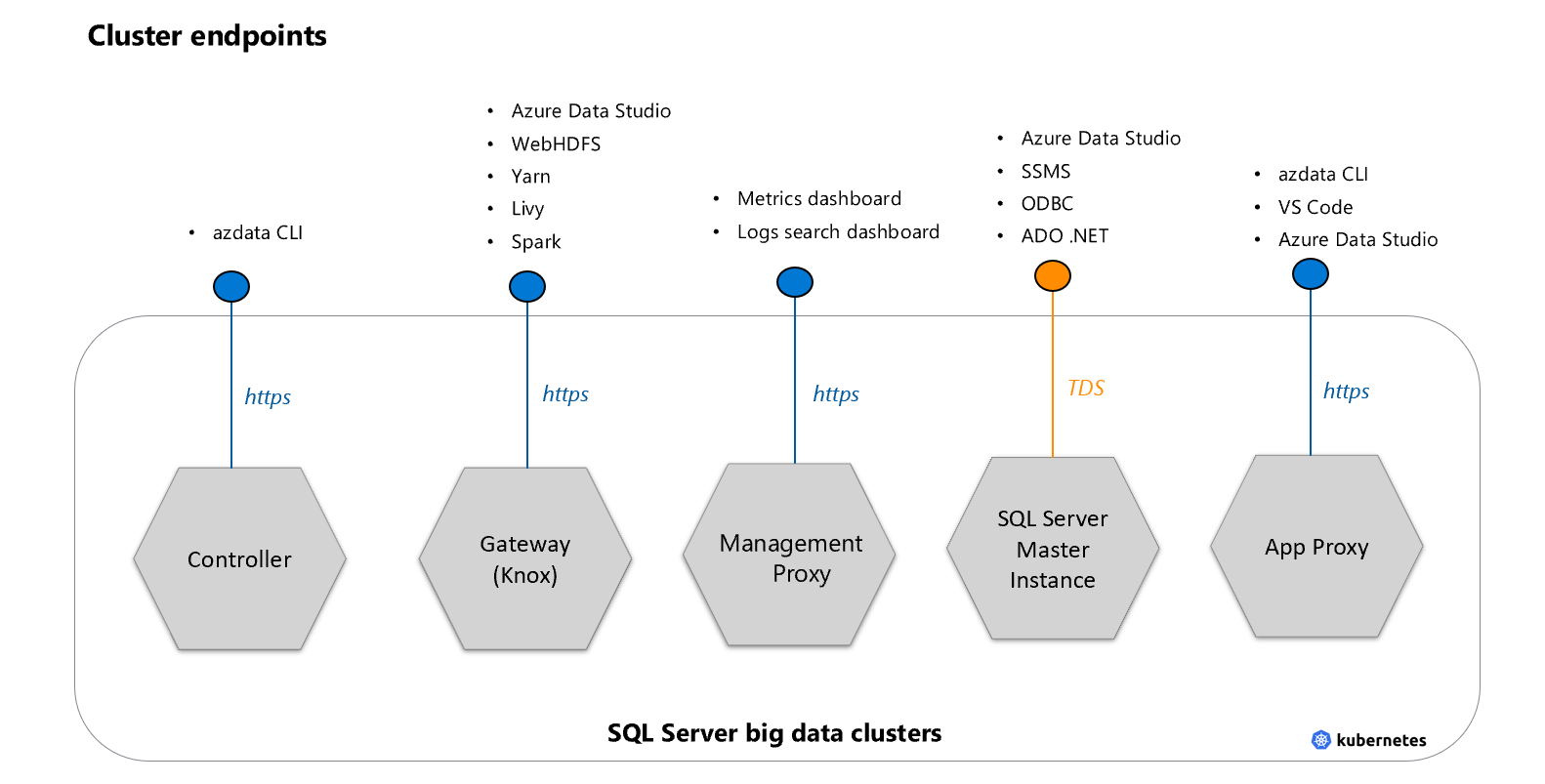
Actuellement, il n’est pas possible d’ouvrir des ports supplémentaires pour accéder au cluster de l’extérieur.
Autorisation
Dans l’ensemble du cluster, la sécurité intégrée entre les différents composants permet de transmettre l’identité de l’utilisateur d’origine lors de l’émission de requêtes à partir de Spark et SQL Server jusqu’à HDFS. Comme indiqué ci-dessus, les différents points de terminaison de cluster externes prennent en charge l’authentification Active Directory.
Il existe deux niveaux de contrôles d’autorisation dans le cluster pour la gestion de l’accès aux données. L’autorisation dans le contexte de Big Data s’effectue dans SQL Server, à l’aide des autorisations SQL Server traditionnelles sur les objets et dans HDFS avec des listes de contrôle (ACL), qui associent les identités des utilisateurs à des autorisations spécifiques.
Un cluster Big Data sécurisé implique une prise en charge uniforme et cohérente des scénarios d’authentification et d’autorisation, à la fois sur SQL Server et HDFS/Spark. L’authentification est le processus qui consiste à vérifier l’identité d’un utilisateur ou d’un service et à confirmer qu’il correspond bien à ce qu’il prétend être. L’autorisation fait référence à l’octroi ou au refus de l’accès à des ressources spécifiques en fonction de l’identité de l’utilisateur à l’origine de la demande. Cette étape est effectuée après l’identification d’un utilisateur au moyens du processus d’authentification.
L’autorisation dans le contexte du Big Data est généralement effectuée par le biais de listes de contrôle d’accès (ACL) qui associent des identités d’utilisateur à des autorisations spécifiques. HDFS prend en charge l’autorisation en limitant l’accès aux API de service, aux fichiers HDFS et à l’exécution de travaux.
Chiffrement en vol et autres mécanismes de sécurité
Le chiffrement de la communication entre les clients et les points de terminaison externes, ainsi qu’entre les composants à l’intérieur du cluster, est sécurisé avec TLS/SSL, à l’aide de certificats.
Toutes les communications de SQL Server à SQL Server, telles que l’instance maître SQL communiquant avec un pool de données, sont sécurisées à l’aide de connexions SQL.
Important
Les Clusters Big Data utilisent etcd pour stocker les informations d’identification. En guise de bonne pratique, assurez-vous que votre cluster Kubernetes est configuré pour utiliser le chiffrement etcd au repos. Par défaut, les secrets stockés dans etcd ne sont pas chiffrés. La documentation Kubernetes fournit des détails sur cette tâche administrative : https://kubernetes.io/docs/tasks/administer-cluster/kms-provider/ et https://kubernetes.io/docs/tasks/administer-cluster/encrypt-data/.
Chiffrement des données au repos
La fonctionnalité de chiffrement au repos sur des Clusters Big Data SQL Server prend en charge le scénario de base du chiffrement au niveau de l’application pour les composants SQL Server et HDFS. Pour obtenir des instructions complètes sur l’utilisation des fonctionnalités, suivez l’article Guide de configuration et des concepts du chiffrement au repos.
Important
Le chiffrement de volume est recommandé pour tous les déploiements de cluster Big Data SQL Server. Les volumes de stockage fournis par le client configurés dans les clusters Kubernetes doivent également être chiffrés, en tant qu’approche complète du chiffrement des données au repos. La fonctionnalité de chiffrement au repos sur le cluster Big Data SQL Server est une couche de sécurité supplémentaire, qui fournit le chiffrement au niveau de l’application des fichiers de données et journaux de SQL Server et du support des zones de chiffrement HDFS.
Connexion administrateur de base
Vous pouvez choisir de déployer le cluster en mode AD ou à l’aide d’une connexion administrateur de base uniquement. L’utilisation de la connexion administrateur de base seule n’est pas un mode de sécurité pris en charge par la production et est destinée à l’évaluation du produit.
Même si vous choisissez le mode Active Directory, les connexions de base seront créées pour l’administrateur de cluster. Cette fonctionnalité offre un accès alternatif, en cas de défaillance de la connectivité AD.
Lors du déploiement, cette connexion de base se verra accorder des autorisations d’administrateur dans le cluster. L’utilisateur de la connexion sera administrateur système dans l’instance maître SQL Server et un administrateur dans le contrôleur de cluster. Les composants Hadoop ne prennent pas en charge l’authentification en mode mixte, ce qui signifie qu’il n’est pas possible d’utiliser une connexion administrateur de base pour l’authentification auprès de la passerelle (Knox).
Les informations d’identification de connexion que vous devez définir lors du déploiement.
Nom d’utilisateur d’administrateur de cluster :
AZDATA_USERNAME=<username>
Mot de passe d’administrateur de cluster :
AZDATA_PASSWORD=<password>
Notes
Notez que, en mode non-AD, le nom d’utilisateur doit être utilisé conjointement avec le mot de passe ci-dessus, pour l’authentification auprès de la Passerelle (Knox) pour l’accès à HDFS/Spark. Avant SQL Server 2019 CU5, le nom d’utilisateur était root.
À partir de SQL Server 2019 (15.x) CU 5, lorsque vous déployez un nouveau cluster avec l’authentification de base, tous les points de terminaison, dont la passerelle, utilisent AZDATA_USERNAME et AZDATA_PASSWORD. Les points de terminaison sur les clusters mis à niveau vers la CU 5 continuent à utiliser root comme nom d’utilisateur pour se connecter au point de terminaison de la passerelle. Cette modification ne s’applique pas aux déploiements utilisant l’authentification Active Directory. Voir Informations d’identification pour l’accès aux services via le point de terminaison de passerelle dans les notes de publication.
Gérer les versions des clés
Clusters de Big Data SQL Server 2019 permet la gestion des versions des clés pour SQL Server et HDFS en utilisant des zones de chiffrement. Pour plus d’informations, consultez Versions des clés dans Cluster Big Data.
Étapes suivantes
Présentation des Clusters de Big Data SQL Server 2019
Atelier : Architecture des Clusters Big Data SQL Server Microsoft