Se connecter à un cluster Big Data SQL Server avec Azure Data Studio
S’applique à : ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Cet article explique comment se connecter à un Clusters de Big Data SQL Server 2019 à partir d’Azure Data Studio.
Important
Le module complémentaire Clusters Big Data Microsoft SQL Server 2019 sera mis hors service. La prise en charge de la plateforme Clusters Big Data Microsoft SQL Server 2019 se terminera le 28 février 2025. Tous les utilisateurs existants de SQL Server 2019 avec Software Assurance seront entièrement pris en charge sur la plateforme, et le logiciel continuera à être maintenu par les mises à jour cumulatives SQL Server jusqu’à ce moment-là. Pour plus d’informations, consultez le billet de blog d’annonce et les Options Big Data sur la plateforme Microsoft SQL Server.
Prérequis
- Un cluster Big Data SQL Server 2019 déployé.
- Outils de Big Data SQL Server 2019 :
- Azure Data Studio
- Extension SQL Server 2019
- kubectl
- azdata
Se connecter au cluster
Pour vous connecter à un cluster Big Data avec Azure Data Studio, établissez une nouvelle connexion à l’instance principale SQL Server dans le cluster. Voici comment faire.
Recherchez le point de terminaison de l’instance principale SQL Server :
azdata bdc endpoint list -e sql-server-masterConseil
Pour plus d’informations sur la façon de récupérer des points de terminaison, consultez Récupérer des points de terminaison.
Dans Azure Data Studio, appuyez sur F1>Nouvelle connexion.
Dans Type de connexion, sélectionnez Microsoft SQL Server.
Tapez le nom du point de terminaison que vous avez trouvé pour l’instance principale SQL Server dans la zone de texte Nom du serveur (par exemple : <IP_Address>,31433).
Choisissez votre type d’authentification. Pour une instance principale SQL Server s’exécutant dans un cluster Big Data, seules l’authentification Windows et la connexion SQL sont prises en charge.
Si vous utilisez une connexion SQL, entrez le nom d’utilisateur et le mot de passe de votre connexion SQL .
Conseil
Par défaut, le nom d’utilisateur SA est désactivé durant le déploiement de clusters Big Data. Un nouvel utilisateur sysadmin est provisionné lors du déploiement avec le nom et le mot de passe correspondant aux variables d’environnement AZDATA_USERNAME et AZDATA_PASSWORD, qui ont été définies avant ou après le déploiement.
Remplacez le Nom de la base de données cible par une de vos bases de données relationnelles.
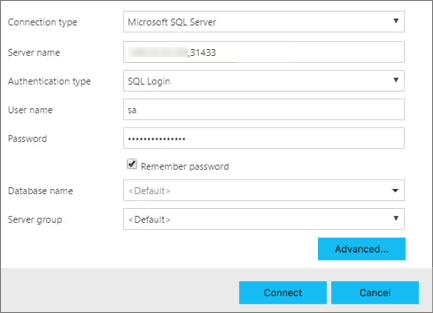
Appuyez sur Se connecter : le Tableau de bord du serveur doit apparaître.
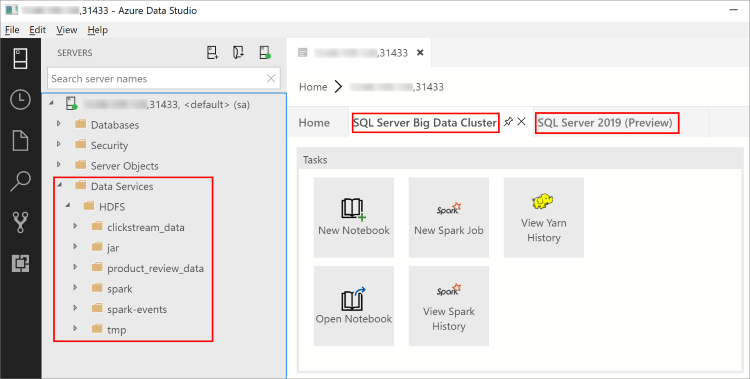
Avec la version de février 2019 d’Azure Data Studio, la connexion à l’instance principale SQL Server vous permet également d’interagir avec la passerelle HDFS/Spark. Cela signifie que vous n’avez pas besoin d’utiliser une connexion distincte pour HDFS et Spark décrite dans la section suivante.
L’Explorateur d’objets contient maintenant un nouveau nœud Services de données avec prise en charge du clic droit pour les tâches de cluster Big Data, comme la création de notebooks ou l’envoi de travaux Spark.
Le nœud Data Services contient également un dossier HDFS pour vous permettre d’explorer le contenu du HDFS et d’effectuer des tâches courantes impliquant le HDFS (par exemple la création d’une table externe ou l’ouverture d’un notebook pour analyser le contenu du HDFS).
Le Tableau de bord du serveur pour la connexion contient également des onglets pour Cluster Big Data SQL Server et SQL Server 2019 quand l’extension est installée.
Étapes suivantes
Pour plus d’informations sur les Clusters de Big Data SQL Server 2019, consultez Que sont les Clusters de Big Data SQL Server 2019 ?.