Mécanismes et recommandations liés aux délais d’attente concernant les baux, les clusters et le contrôle d’intégrité pour les groupes de disponibilité Always On
En raison des différences de configuration au niveau du matériel, des logiciels et des clusters, ainsi que des différents besoins de disponibilité et de performances des applications, il est nécessaire de définir des valeurs de délai spécifiques pour les baux, les clusters et le contrôle d’intégrité. Certaines applications et charges de travail nécessitent une surveillance plus importante dans le but de limiter les temps d’arrêt conséquents à une défaillance. D’autres nécessitent une plus grande tolérance aux pannes réseau temporaires. Elles attendent avant d’utiliser une grande quantité de ressources et tolèrent les basculements lents.
Les services présents sur chaque nœud sont chargés de détecter les défaillances. Le service de cluster peut détecter la perte de quorum, la DLL de ressource peut détecter un problème exposé par la détection de l’état d’intégrité Always-on, et un basculement manuel peut être effectué directement sur l’instance principale. Le service de cluster, l’hôte des ressources et l’instance SQL Server sont synchronisés via RPC, la mémoire partagée et T-SQL. Dans la plupart des cas, ces services communiquent sans problème. Cependant, cette communication n’est pas totalement fiable, même entre les services d’un même ordinateur. De plus, le groupe de disponibilité doit pouvoir supporter les événements qui affectent l’intégralité du système, tels que les pannes réseau et les défaillances de disque, qui peuvent empêcher toute communication et utilisation. En cas de nombreuses défaillances et sans une communication entièrement fiable entre les services, le groupe de disponibilité dépend de différents mécanismes de détection de basculement pour détecter et résoudre les défaillances indépendamment les unes des autres, pour que l’état du cluster reste le même sur tous les nœuds.
Nœuds de cluster et détection des ressources
Chaque nœud du cluster exécute un service de cluster, qui fait fonctionner le cluster de basculement et surveille toutes les ressources du cluster. L’hôte des ressources est un processus séparé qui constitue l’interface entre le service de cluster et les ressources du cluster. L’hôte des ressources effectue des opérations sur les ressources du cluster lorsque celles-ci sont appelées par le service de cluster. Les applications qui prennent en charge les clusters, comme SQL Server, fournissent des interfaces personnalisées au moniteur de ressource via des DLL de ressource. La DLL de ressource implémente des opérations en ligne et hors connexion, ainsi que la surveillance de l’état d’intégrité pour les ressources personnalisées. L’hôte des ressources est un processus enfant du service de cluster. Par conséquent, si le service de cluster est « tué », il le sera également.
Pour SQL Server, la DLL de ressource du groupe de disponibilité détermine l’état d’intégrité du groupe de disponibilité à l’aide du mécanisme de bail et de la détection de l’état d’intégrité AlwaysOn. La DLL de ressource du groupe de disponibilité expose l’état d’intégrité des ressources via l’opération IsAlive. Le moniteur de ressource interroge IsAlive en se basant sur l’intervalle d’interrogation du cluster (pulsations), qui est défini par les valeurs de cluster CrossSubnetDelay et SameSubnetDelay. Sur un nœud principal, le service de cluster lance un basculement chaque fois que l’appel de IsAlive à la DLL de ressource indique que le groupe de disponibilité n’est pas sain.
Le service de cluster interroge les autres nœuds du cluster en envoyant des pulsations, puis accuse réception des pulsations reçues. Quand un nœud détecte une défaillance de communication à partir d’une série de pulsations dont la réception n’a pas été confirmée, il diffuse un message qui provoque la réconciliation des vues d’état d’intégrité de tous les nœuds accessibles du cluster. Cet événement, appelé événement de regroupement, maintient la cohérence de l’état du cluster sur tous les nœuds. Après un événement de regroupement, si le quorum est perdu, toutes les ressources du cluster, y compris les groupes de disponibilité de cette partition, sont mises hors connexion. Tous les nœuds de cette partition sont transitionnés vers un état de résolution. S’il existe une partition contenant un quorum, le groupe de disponibilité est affecté à un nœud de la partition et devient le réplica principal, tandis que tous les autres nœuds deviennent des réplicas secondaires.
Détection de l’état d’intégrité AlwaysOn
La DLL de ressource AlwaysOn surveille l’état des composants internes de SQL Server. sp_server_diagnostics rapporte l’état d’intégrité de ces composants SQL Server selon un intervalle contrôlé par HealthCheckTimeout. sp_server_diagnostics rapporte l’état d’intégrité de cinq composants de niveau instance : le système, les ressources, le traitement des requêtes, le sous-système d’E/S et les événements. Il rapporte également l’état d’intégrité de chaque groupe de disponibilité. Lors de chaque mise à jour, la DLL de ressource met à jour l’état d’intégrité de la ressource Groupe de disponibilité, en fonction du niveau de défaillance du groupe de disponibilité. Lorsque des données sont retournées par sp_server_diagnostics, elle affiche, pour chacun des composants, l’état Sain, Avertissement, Erreur ou Inconnu, ainsi que des données XML décrivant l’état de chaque composant. Pour la détection de l’état d’intégrité, la DLL de ressource n’intervient que si un composant est à l’état Erreur.
Si la détection de l’état d’intégrité ne parvient pas à signaler une mise à jour à la DLL de ressource pendant plusieurs intervalles, le groupe de disponibilité est considéré comme n’étant pas sain, et signale un échec à chaque appel de IsAlive.
Mécanisme de bail
Contrairement à d’autres mécanismes de basculement, l’instance SQL Server joue un rôle actif dans le mécanisme de bail. Le mécanisme de bail est utilisé comme une validation de type « Semble actif » entre l’hôte des ressources du cluster et le processus SQL Server. Le mécanisme est utilisé pour garantir que les deux côtés (le service de cluster et le service SQL Server) sont fréquemment en contact dans le but de vérifier l’état de l’autre et empêcher un scénario de type Split-Brain. Lors de la mise en ligne d’un groupe de disponibilité en tant que réplica principal, l’instance SQL Server génère un thread de travail de bail dédié pour le groupe de disponibilité. Le travail de bail partage une petite zone de mémoire avec l’hôte des ressources qui contient les événements de renouvellement et d’arrêt de bail. Le travail de bail et l’hôte des ressources fonctionnent de façon circulaire, en signalant leurs événements de renouvellement de bail respectifs, puis en se mettant en veille et en attendant que l’autre signale son propre événement de renouvellement ou d’arrêt de bail. L’hôte des ressources et le thread de bail SQL Server ont une valeur de durée de vie, qui est mise à jour chaque fois que le thread sort de veille, après avoir été signalé par l’autre thread. Si la durée de vie est atteinte lors de l’attente du signal, le bail expire et le réplica passe à l’état de résolution pour le groupe de disponibilité en question. Si l’événement d’arrêt de bail est signalé, le réplica prend un rôle de résolution.
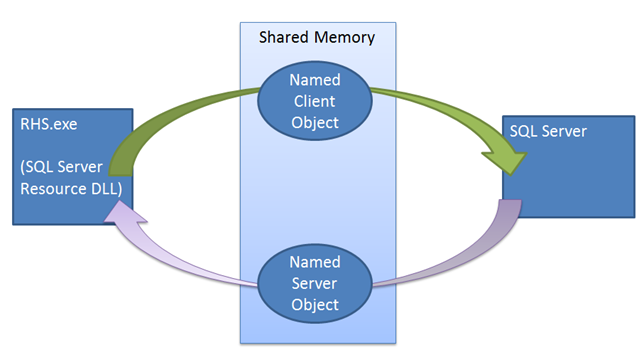
Le mécanisme de bail applique la synchronisation entre SQL Server et le cluster de basculement Windows Server. Lorsqu’une commande de basculement est émise, le service de cluster effectue un appel Offline à la DLL de ressource du réplica principal actuel. La DLL de ressource essaie d’abord de mettre le groupe de disponibilité hors connexion à l’aide d’une procédure stockée. Si cette procédure stockée échoue ou expire, l’échec est signalé au service de cluster, qui, à son tour, émet une commande de fin d’exécution. La commande de fin d’exécution tente à nouveau d’exécuter la même procédure stockée. Toutefois, cette fois-ci, le cluster n’attend pas que la DLL de ressource signale une réussite ou un échec avant de mettre en ligne le groupe de disponibilité sur un nouveau réplica. Si ce deuxième appel de procédure échoue, l’hôte des ressources doit compter sur le mécanisme de bail pour mettre l’instance hors connexion. Lorsque la DLL de ressource est appelée pour mettre le groupe de disponibilité hors connexion, la DLL de ressource signale l’événement d’arrêt de bail, et sort de veille le thread de travail de bail SQL Server pour mettre le groupe de disponibilité hors connexion. Même si cet événement d’arrêt n’est pas signalé, le bail expire, et le réplica passe à l’état de résolution.
Le bail est principalement un mécanisme de synchronisation entre l’instance principale et le cluster, mais il peut également créer des conditions d’échec là où un basculement n’était pas nécessaire. Par exemple, les situations d’utilisation élevée du processeur, de mémoire insuffisante (mémoire virtuelle faible, pagination du processus), d’absence de réponse du processus SQL lors de la génération d’une sauvegarde de mémoire, d’absence de réponse du système, de déconnexion du cluster (WSFC) (par exemple, en raison d’une perte de quorum) peuvent empêcher le renouvellement du bail de l’instance SQL et provoquer un redémarrage ou un basculement.
Recommandations concernant les valeurs de délai d’expiration des clusters
Il est conseillé de bien évaluer les inconvénients et les conséquences d’une surveillance moins importante pour votre cluster SQL Server. Le fait d’augmenter les valeurs de délai d’expiration des clusters a pour effet d’accroître la tolérance aux pannes réseau temporaires, mais également d’allonger le temps de réponse aux défaillances. Le fait d’augmenter les valeurs de délai d’expiration, en vue de gérer une sollicitation des ressources trop importante ou une latence géographique trop élevée, a pour effet d’augmenter le temps de récupération nécessaire après une défaillance, récupérable ou non. Bien que cela reste acceptable pour de nombreuses applications, ce n’est pas idéal dans tous les cas.
Les paramètres par défaut sont optimisés pour réagir rapidement aux symptômes de défaillance et pour réduire au maximum le temps d’arrêt. Ils peuvent toutefois être trop agressifs pour certaines charges de travail et configurations. Il est déconseillé de rétablir la valeur par défaut de LeaseTimeout, CrossSubnetDelay, CrossSubnetThreshold, SameSubnetDelay, SameSubnetThreshold ou HealthCheckTimeout (voire d’utiliser une valeur inférieure à celle-ci). Les paramètres qui conviennent à chaque déploiement varient et peuvent nécessiter un certain nombre de tests avant d’être déterminés. Lorsque vous changez l’une de ces valeurs, faites-le progressivement et en tenant compte des relations et des dépendances qui existent entre elles.
Relation entre le délai d’expiration du cluster et le délai d’expiration du bail
La principale fonction du mécanisme de bail est d’accepter la ressource SQL Server hors connexion si le service de cluster ne peut pas communiquer avec l’instance lors de l’exécution d’un basculement vers un autre nœud. Lorsque le cluster effectue une opération hors connexion sur la ressource de cluster du groupe de disponibilité, le service de cluster effectue un appel RPC à rhs.exe afin de mettre la ressource hors connexion. La DLL de ressource utilise des procédures stockées pour indiquer à SQL Server de mettre le groupe de disponibilité hors connexion. Toutefois, les procédures stockées peuvent échouer ou expirer. L’hôte des ressources arrête également son propre thread de renouvellement de bail lors de l’appel hors connexion. Dans le cas le plus défavorable, SQL Server provoque l’expiration du bail à la moitié du délai défini (LeaseTimeout) et fait passer l’instance à l’état de résolution. Les basculements peuvent être effectués par plusieurs parties. Toutefois, il est crucial que la vue de l’état du cluster soit la même sur l’ensemble du cluster et entre les instances SQL Server. Prenons, par exemple, un scénario dans lequel l’instance principale perd la connexion avec le reste du cluster. Tous les nœuds du cluster vont détecter une défaillance au même moment en raison des valeurs de délai d’expiration du cluster, mais seul le nœud principal pourra interagir avec l’instance principale de SQL Server afin de la forcer à abandonner le rôle principal.
Pour le nœud principal, le service de cluster a perdu le quorum et met fin à sa propre exécution. Le service de cluster émet un appel RPC vers l’hôte des ressources pour mettre fin au processus. Cet appel de fin d’exécution est chargé de mettre hors connexion le groupe de disponibilité de l’instance SQL Server. Cet appel hors connexion est effectué via T-SQL, mais ne peut pas garantir la connexion entre SQL et la DLL de ressource.
Pour le reste du cluster, il n’existe aucun réplica principal pour le moment. Il va donc voter et établir un nouveau réplica principal pour les autres nœuds du cluster. Si la procédure stockée qui a été appelée par la DLL de ressource échoue ou expire, le cluster peut être vulnérable au syndrome Split-Brain.
Le délai d’expiration du bail empêche le syndrome Split-Brain en cas d’erreurs de communication. Même si toutes les communications échouent, le processus de la DLL de ressource s’arrête et ne peut plus mettre à jour le bail. Une fois que le bail expire, il se charge de mettre hors connexion le groupe de disponibilité. L’instance SQL Server doit être informée qu’elle n’héberge plus le réplica principal avant que le cluster n’en établisse un nouveau. Étant donné que le reste du cluster, qui est chargé de choisir un nouveau réplica principal, n’a aucun moyen de se coordonner avec l’actuel réplica principal, les valeurs de délai d’expiration empêchent qu’un nouveau réplica principal ne soit établi avant que l’actuel réplica ne se mette hors connexion.
Lorsque le cluster bascule, l’instance SQL Server qui héberge l’ancien réplica principal doit passer à l’état de résolution avant que le nouveau réplica principal ne soit en ligne. Le thread de bail SQL Server a toujours une durée de vie égale à la moitié du délai d’expiration du bail (LeaseTimeout), car chaque fois que le bail est renouvelé, la nouvelle durée de vie est remplacée par LeaseInterval ou par la moitié * du délai d’expiration du bail (LeaseTimeout). Si le service de cluster ou de l’hôte des ressources s’interrompt ou cesse de s’exécuter sans signaler l’événement d’arrêt de bail, le cluster déclare le nœud principal comme mort au bout de SameSubnetThreshold\ SameSubnetDelay millisecondes. Pendant ce délai, le bail doit expirer pour garantir la mise hors connexion du réplica principal. La durée maximale de vie du délai d’expiration du bail étant ½ * LeaseTimeout, ½ * LeaseTimeout doit être inférieur à SameSubnetThreshold * SameSubnetDelay.
SameSubnetThreshold \<= CrossSubnetThreshold et SameSubnetDelay \<= CrossSubnetDelay doit avoir la valeur True sur tous les clusters SQL Server.
Délai d’attente du contrôle d’intégrité
Le délai d’attente du contrôle d’intégrité est plus souple, car aucun autre mécanisme de basculement ne dépend directement de lui. La valeur par défaut de 30 secondes comprend un intervalle sp_server_diagnostics égal à 10 secondes, une valeur minimale de 15 secondes pour le délai d’attente et un intervalle de 5 secondes. En règle générale, l’intervalle de mise à jour sp_server_diagnostics est toujours égal à 1/3 * HealthCheckTimeout. Lorsque la DLL de ressource ne reçoit pas de nouveau jeu de données d’intégrité à un certain intervalle, elle continue d’utiliser les données d’intégrité de l’intervalle précédent pour déterminer l’état d’intégrité du groupe de disponibilité et de l’instance actuels. Le fait d’augmenter la valeur du délai d’attente du contrôle d’intégrité permet au réplica principal d’être plus tolérant à la sursollicitation de l’UC, ce qui peut empêcher sp_server_diagnostics de fournir de nouvelles données à chaque intervalle. Cela signifie, toutefois, qu’il va s’appuyer plus longtemps sur des contrôles d’intégrité obsolètes. Quelle que soit la valeur du délai d’attente, lorsque vous recevez des données indiquant que le réplica n’est pas sain, le prochain appel à IsAlive retourne que l’instance n’est pas saine et que le service de cluster s’apprête à démarrer un basculement.
Le niveau de condition d’échec du groupe de disponibilité modifie les conditions d’échec pour le contrôle d’intégrité. Pour tous les niveaux d’échec, si l’élément Groupe de disponibilité est déclaré comme non sain par sp_server_diagnostics, le contrôle d’intégrité échoue. Chaque niveau hérite de toutes les conditions d’échec des niveaux inférieurs à lui.
| Level | Condition sous laquelle l’instance est considérée comme morte |
|---|---|
| 1 : OnServerDown | Le contrôle d’intégrité n’entreprend aucune action si l’une des ressources échoue, en dehors du groupe de disponibilité. Si les données du groupe de disponibilité ne sont pas reçues au bout de cinq intervalles ou 5/3 * HealthCheckTimeout |
| 2 : OnServerUnresponsive | Si aucune donnée n’est reçue de sp_server_diagnostics pour HealthCheckTimeout |
| 3 : OnCriticalServerError | (Par défaut) Si le composant Système signale une erreur |
| 4 : OnModerateServerError | Si le composant Ressource signale une erreur |
| 5 : OnAnyQualifiedFailureConitions | Si le composant Traitement des requêtes signale une erreur |
Mise à jour des valeurs d’expiration des clusters et d’Always-on
Valeurs de cluster
Dans la configuration WSFC, il existe quatre valeurs qui sont chargées de déterminer les valeurs de délai d’expiration des clusters :
- SameSubnetDelay
- SameSubnetThreshold
- CrossSubnetDelay
- CrossSubnetThreshold
Les valeurs de délai déterminent le temps d’attente entre chaque pulsation du service de cluster, et les valeurs de seuil définissent le nombre de pulsations dont la réception peut ne pas être confirmée par le nœud ou la ressource cible avant que l’objet ne soit déclaré comme mort par le cluster. Si aucune pulsation n’est détectée entre les nœuds d’un même sous-réseau pendant plus de SameSubnetDelay \* SameSubnetThreshold millisecondes, le nœud est considéré comme mort. Il en va de même pour les communications entre plusieurs sous-réseaux qui utilisent les mêmes valeurs.
Pour répertorier toutes les valeurs de cluster actuelles, sur l’un des nœuds du cluster cible, ouvrez un terminal PowerShell avec élévation de privilèges. Exécutez la commande suivante :
Get-Cluster | fl *
Pour mettre à jour ces valeurs, exécutez la commande suivante dans un terminal PowerShell avec élévation de privilèges :
(Get-Cluster).<ValueName> = <NewValue>
Lorsque vous augmentez le produit Délai * Seuil pour rendre plus tolérant le délai d’expiration des clusters, il est plus efficace de commencer par augmenter la valeur du délai avant d’augmenter celle du seuil. En augmentant le délai d’attente, vous augmentez le temps entre chaque pulsation. Plus le temps entre chaque pulsation est important, plus les pannes réseau temporaires disposent de temps pour se résoudre et réduire l’encombrement réseau lié à l’envoi d’un trop grand nombre de pulsations au cours d’une même période.
Délai d’expiration du bail
Le mécanisme de bail est contrôlé par une seule valeur qui est spécifique à chaque groupe de disponibilité d’un cluster WSFC. Un délai d’expiration du bail peut entraîner les erreurs suivantes :
Error 35201:
A connection timeout has occurred while attempting to establish a connection to availability replica 'replicaname'
Error 35206:
A connection timeout has occurred on a previously established connection to availability replica 'replicaname'
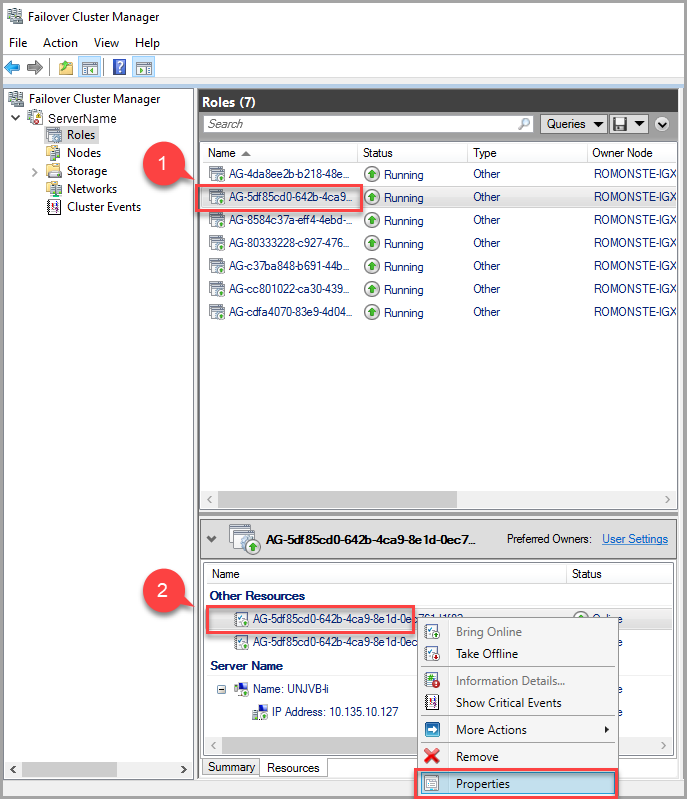
Pour modifier la valeur du délai d’expiration du bail, utilisez le Gestionnaire du cluster de basculement et procédez comme suit :
Dans l’onglet Rôles, recherchez le rôle de groupe de disponibilité cible. Sélectionnez le rôle de groupe de disponibilité cible.
Cliquez avec le bouton droit sur la ressource Groupe de disponibilité au bas de la fenêtre, puis sélectionnez Propriétés.
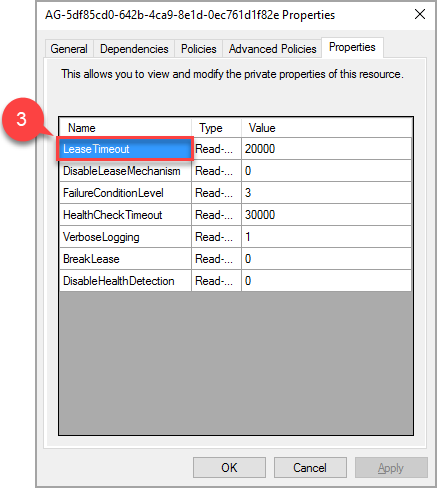
Dans la fenêtre contextuelle, accédez à l’onglet Propriétés pour voir une liste des valeurs spécifiques au groupe de disponibilité. Sélectionnez la valeur LeaseTimeout pour la modifier.
Selon la configuration du groupe de disponibilité, il peut y avoir d’autres ressources pour les écouteurs, les disques partagés, les partages de fichiers, etc. Ces ressources ne nécessitent pas de configuration supplémentaire.
Remarque
La nouvelle valeur de la propriété « LeaseTimeout » prend effet une fois que la ressource est mise hors connexion puis remise en ligne.
Valeurs du contrôle d’intégrité
Deux valeurs définissent le contrôle d’intégrité Always On : FailureConditionLevel et HealthCheckTimeout. FailureConditionLevel indique le niveau de tolérance pour les conditions d’échec signalées par sp_server_diagnostics, et HealthCheckTimeout définit le délai pendant lequel la DLL de ressource peut fonctionner sans recevoir de mise à jour de sp_server_diagnostics. L’intervalle de mise à jour pour sp_server_diagnostics est toujours égal à un tiers de HealthCheckTimeout.
Pour configurer le niveau de condition de basculement, utilisez l’option FAILURE_CONDITION_LEVEL = <n> de l’instruction CREATE ou ALTERAVAILABILITY GROUP, où <n> est un entier compris entre 1 et 5. La commande suivante définit le niveau de condition d’échec sur 1 pour le groupe de disponibilité « AG1 » :
ALTER AVAILABILITY GROUP AG1 SET (FAILURE_CONDITION_LEVEL = 1);
Pour configurer le délai d’attente du contrôle d’intégrité, utilisez l’option HEALTH_CHECK_TIMEOUT des instructions CREATE ou ALTERAVAILABILITY GROUP. La commande suivante définit le délai d’attente du contrôle d’intégrité sur 60 000 millisecondes pour le groupe de disponibilité AG1 :
ALTER AVAILABILITY GROUP AG1 SET (HEALTH_CHECK_TIMEOUT =60000);
Récapitulatif des recommandations relatives aux délais d’expiration
Il est déconseillé de définir la valeur d’un délai d’expiration en dessous de sa valeur par défaut.
L’intervalle du bail (½ * LeaseTimeout) doit être inférieur à SameSubnetThreshold * SameSubnetDelay
SameSubnetThreshold <= CrossSubnetThreshold
SameSubnetDelay <= CrossSubnetDelay
| Paramètre de délai d’attente | Objectif | Entre | Utilisations | IsAlive et LooksAlive | Causes | Résultat |
|---|---|---|---|---|---|---|
| Délai d’expiration du bail Valeur par défaut : 20 000 |
Empêcher le Split-Brain | Principal et cluster (HADR) |
Objets d’événement Windows | Utilisé dans les deux | Absence de réponse du système d’exploitation, mémoire virtuelle faible, pagination de la plage de travail, génération d’un vidage sur incident, UC invariable, WSFC hors service (perte de quorum) | Ressource de groupe de disponibilité hors connexion-en ligne, basculement |
| Délai d’expiration de session Valeur par défaut : 10 000 |
Informer de l’existence d’un problème de communication entre le principal et le secondaire | Secondaire et principal (HADR) |
Sockets TCP (messages envoyés via le point de terminaison DBM) | Utilisé dans aucun des deux | Problèmes de communication réseau sur le secondaire - hors service, absence de réponse du système d’exploitation, contention de ressources |
Secondaire - DÉCONNECTÉ |
| Délai d’attente HealthCheck Valeur par défaut : 30 000 |
Indiquer le délai d’expiration lors d’une tentative de détermination de l’état du réplica principal | Cluster et principal (ICF et HADR) |
sp_server_diagnostics T-SQL | Utilisé dans les deux | Conditions d’échec réunies, absence de réponse du système d’exploitation, mémoire virtuelle faible, plage de travail tronquée, génération d’un vidage sur incident, WSFC (perte de quorum), problèmes de planificateur (planificateurs bloqués) | Ressource de groupe de disponibilité hors connexion/en ligne ou basculement, redémarrage/basculement de FCI |
Contenu connexe
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour