Superviser les performances des groupes de disponibilité Always On
S'applique à : ![]() SQL Server
SQL Server
La partie performance des groupes de disponibilité Always On est essentielle au respect du SLA (contrat de niveau de service) pour vos bases de données critiques. Le fait de comprendre comment les groupes de disponibilité envoient les journaux aux réplicas secondaires peut vous aider à estimer le RTO (objectif de temps de récupération) et le RPO (objectif de point de récupération) de votre implémentation de disponibilité et à identifier les goulots d’étranglement dans les groupes ou réplicas de disponibilité peu performants. Cet article décrit le processus de synchronisation, montre comment calculer certaines métriques clés et fournit des liens vers des scénarios courants de résolution de problèmes de performances.
Processus de synchronisation des données
Pour estimer le temps nécessaire à la synchronisation complète et identifier le goulot d’étranglement, vous devez comprendre le processus de synchronisation. Un goulot d’étranglement des performances peut se trouver n’importe où dans le processus, et sa localisation peut vous aider à explorer plus en détail les problèmes sous-jacents. La figure et le tableau suivants illustrent le processus de synchronisation de données :

| Séquence | Description de l’étape | Commentaires | Mesures utiles |
|---|---|---|---|
| 1 | Génération du journal | Les données de journal sont vidées sur le disque. Ce journal doit être répliqué sur les réplicas secondaires. Les enregistrements de journal entrent dans la file d’attente d’envoi. | SQL Server:Base de données > Octets de journal vidés/s |
| 2 | Capture | Les journaux de chaque base de données sont capturés et envoyés à la file d’attente du partenaire correspondant (un par paire base de données-réplica). Ce processus de capture s’exécute en continu tant que le réplica de disponibilité est connecté et que le déplacement des données n’est pas suspendu pour une raison quelconque. La paire base de données-réplica indique Synchronisation ou Synchronisé. Si le processus de capture ne peut pas analyser et empiler les messages suffisamment vite, la file d’attente d’envoi du journal augmente. | SQL Server:Réplica de disponibilité > Octets envoyés au réplica\s, qui est une agrégation de la somme de tous les messages de base de données en file d’attente pour ce réplica de disponibilité. log_send_queue_size (Ko) et log_bytes_send_rate (Ko/s) sur le réplica principal. |
| 3 | Envoyer | Les messages dans la file d’attente de chaque base de données-réplica sont dépilés et envoyés sur le réseau au réplica secondaire respectif. | SQL Server:Réplica de disponibilité > Octets envoyés au transport/s |
| 4 | Réception et mise en cache | Chaque réplica secondaire reçoit et met en cache le message. | Compteur de performances SQL Server:Réplica de disponibilité > Octets de journal reçus/s |
| 5 | Renforcer | Le journal est vidé sur le réplica secondaire pour renforcement. Après le vidage du journal, un accusé de réception est renvoyé au réplica principal. Une fois le journal renforcé, la perte de données est évitée. |
Compteur de performances SQL Server:Base de données > Octets de journal vidés/s Type d’attente HADR_LOGCAPTURE_SYNC |
| 6 | Rétablir | Les pages vidées sont restaurées par progression sur le réplica secondaire. Les pages sont conservées dans la file d’attente de restauration par progression jusqu’au démarrage de la restauration par progression. | SQL Server:Réplica de base de données > Octets restaurés/s redo_queue_size (Ko) et redo_rate. Type d’attente REDO_SYNC |
Portes de contrôle de flux
Les groupes de disponibilité sont conçus avec des portes de contrôle de flux sur le réplica principal pour éviter toute consommation excessive des ressources, notamment les ressources réseau et mémoire, sur tous les réplicas de disponibilité. Ces portes de contrôle de flux n’affectent pas l’état d’intégrité de la synchronisation des réplicas de disponibilité, mais elles peuvent affecter les performances globales de vos bases de données de disponibilité, notamment le RPO.
Une fois capturés sur le réplica principal, les journaux sont soumis à deux niveaux de contrôles de flux. Une fois le seuil de messages atteint sur l’une des portes, les messages de journal ne sont plus envoyés à un réplica spécifique ou pour une base de données spécifique. Les messages peuvent être envoyés après l’obtention des accusés de réception des messages envoyés afin de faire passer le nombre de messages envoyés sous le seuil.
Outre les portes de contrôle de flux, un autre facteur peut empêcher l’envoi des messages de journal. La synchronisation des réplicas garantit que les messages sont envoyés et appliqués dans l’ordre des LSN (numéros séquentiels dans le journal). Avant l’envoi d’un message de journal, son LSN fait également l’objet d’un contrôle par rapport au LSN avec l’accusé de réception le plus bas pour vérifier qu’il est inférieur à l’un des seuils (selon le type de message). Si l’intervalle entre les deux LSN est supérieur au seuil, les messages ne sont pas envoyés. Quand l’intervalle est à nouveau sous le seuil, les messages sont envoyés.
SQL Server 2022 augmente le nombre maximal de messages autorisés par chaque porte. Avec l’indicateur de trace 12310, la limite augmentée est également disponible pour les versions suivantes de SQL Server, à compter de SQL Server 2019 CU9, 2017 CU18 et 2016 SP1 CU16.
Le tableau suivant compare les nombres limites de messages :
SQL Server 2022 et les versions prises en charge de SQL Server (à compter de SQL Server 2019 CU9, 2017 CU18 et 2016 SP1 CU16) avec l’indicateur de trace 12310 activé prévoient les limites suivantes :
| Level | Nombre de portes | Nombre de messages | Mesures utiles |
|---|---|---|---|
| Transport | 1 par réplica de disponibilité | 16384 | Événement étendu database_transport_flow_control_action |
| Base de données | 1 par base de données de disponibilité | 7168 | DBMIRROR_SEND Événement étendu hadron_database_flow_control_action |
Deux compteurs de performances utiles, SQL Server:Réplica de disponibilité > Contrôle de flux/s et SQL Server:Réplica de disponibilité > Durée du contrôle de flux (ms/s), vous montrent dans la dernière seconde écoulée le nombre de fois que le contrôle de flux a été activé et le temps passé à attendre le contrôle de flux. Plus le temps d’attente est élevé sur le contrôle de flux, plus le RPO est élevé. Pour plus d’informations sur les types de problèmes pouvant provoquer un temps d’attente élevé sur le contrôle de flux, consultez Dépanner : Dépassement de RPO du groupe de disponibilité.
Estimation du temps de basculement (RTO)
Le RTO dans votre SLA dépend du temps de basculement de votre implémentation Always On à un moment donné. Il peut être calculé à l’aide de la formule suivante :

Important
Si un groupe de disponibilité contient plusieurs bases de données de disponibilité, celle avec la valeur Tfailover la plus élevée devient la valeur de limitation pour la conformité au RTO.
Le temps de détection d’échec (Tdetection) est le temps qu’il faut au système pour détecter la défaillance. Ce temps dépend des paramètres au niveau du cluster et non des réplicas de disponibilité individuels. En fonction de la condition de basculement automatique configurée, un basculement peut être déclenché comme réponse instantanée à une erreur interne SQL Server critique (par exemple, des verrouillages spinlock orphelins). Dans ce cas, la détection peut être aussi rapide que l’envoi du rapport d’erreurs sp_server_diagnostics (Transact-SQL) au cluster WSFC (l’intervalle par défaut est égal à un tiers du délai d’expiration du contrôle d’intégrité). Un basculement peut également être déclenché en raison du dépassement d’un délai d’expiration, notamment celui associé au contrôle d’intégrité (30 secondes par défaut) ou celui associé au bail entre la DLL de ressource et l’instance SQL Server (20 secondes par défaut). Dans ce cas, le temps de détection est égal à l’intervalle du délai d’expiration. Pour plus d’informations, consultez Stratégie de basculement flexible pour le basculement automatique d’un groupe de disponibilité (SQL Server).
Pour que le réplica secondaire soit prêt pour le basculement, il suffit que la restauration par progression rattrape son retard et arrive à la fin du journal. Le temps de restauration par progression, Tredo, est calculé à l’aide de la formule suivante :

où redo_queue est la valeur dans redo_queue_size et redo_rate la valeur dans redo_rate.
La surcharge de temps de basculement, Toverhead, comprend le temps nécessaire pour basculer le cluster WSFC et placer les bases de données en ligne. Ce temps est généralement court et constant.
Estimation du risque de perte de données (RPO)
Le RPO dans votre SLA dépend du risque de perte de données de votre implémentation Always On à un moment donné. Ce risque de perte de données peut être calculé à l’aide de la formule suivante :

où log_send_queue est la valeur de log_send_queue_size et log generation rate la valeur de SQL Server:Base de données > Octets de journal vidés/s.
Avertissement
Si un groupe de disponibilité contient plusieurs bases de données de disponibilité, celle avec la valeur Tdata_loss la plus élevée devient la valeur de limitation pour la conformité au RPO.
La file d’attente d’envoi du journal représente toutes les données pouvant être perdues en raison d’une défaillance catastrophique. À première vue, il est curieux de constater que le taux de génération de journaux est utilisé à la place du taux d’envoi de journaux (consultez log_send_rate). Toutefois, n’oubliez pas que le taux d’envoi de journaux vous donne uniquement le temps nécessaire à la synchronisation, tandis que le RPO mesure la perte de données en fonction de la vitesse à laquelle il est généré, et non en fonction de la vitesse à laquelle il est synchronisé.
Un moyen plus simple d’estimer Tdata_loss consiste à utiliser last_commit_time. La DMV sur le réplica principal fournit cette valeur pour tous les réplicas. Vous pouvez calculer la différence entre la valeur du réplica principal et celle du réplica secondaire pour estimer la vitesse à laquelle le journal sur le réplica secondaire rattrape son retard par rapport au réplica principal. Comme indiqué précédemment, ce calcul n’indique pas le risque de perte de données en fonction de la vitesse à laquelle le journal est généré, mais il doit s’agir d’une bonne approximation.
Estimer le RTO et le RPO avec le tableau de bord SSMS
Dans les groupes de disponibilité AlwaysOn, le RTO et le RPO sont calculés et affichés pour les bases de données hébergées sur les réplicas secondaires. Dans le tableau de bord du réplica principal, le RTO et le RPO sont regroupés par le réplica secondaire.
Pour voir le RTO et le RPO dans le tableau de bord, procédez comme suit :
Dans SQL Server Management Studio, développez le nœud Haute disponibilité Always On, cliquez avec le bouton droit sur le nom de votre groupe de disponibilité et sélectionnez Afficher le tableau de bord.
Sélectionnez Ajouter/Supprimer des colonnes sous l’onglet Regrouper par. Cochez à la fois Temps de récupération estimé (en secondes) [RTO] et Perte de données estimée (temps) [RPO].

Calcul du RTO de base de données secondaire
Le calcul du temps de récupération détermine la durée nécessaire pour récupérer la base de données secondaire après un basculement. Ce temps de basculement est généralement court et constant. Le temps de détection dépend des paramètres au niveau du cluster et non des réplicas de disponibilité individuels.
Pour une base de données secondaire (DB_sec), le calcul et l’affichage de son RTO sont basés sur son redo_queue_size et son redo_rate :

À l’exception des cas extrêmes, la formule pour calculer le RTO d’une base de données secondaire est :

Calcul du RPO d’une base de données secondaire
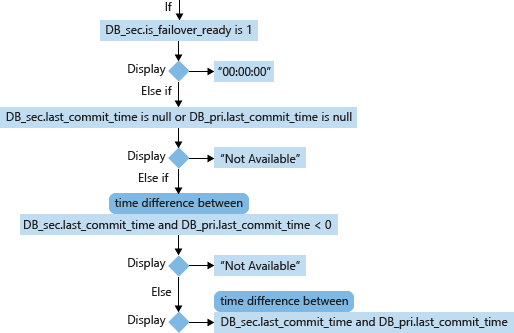
Pour une base de données secondaire (DB_sec), le calcul et l’affichage de son RPO sont basés sur son is_failover_ready, son last_commit_time et le last_commit_time de sa base de données primaire (DB_pri). Quand secondary database.is_failover_ready = 1, daa est synchronisé et aucune perte de données ne se produit pendant le basculement. Toutefois, si cette valeur est 0, un écart se crée entre le last_commit_time de la base de données primaire et le last_commit_time de la base de données secondaire.
Pour la base de données primaire, le last_commit_time est l’heure à laquelle la dernière transaction a été validée. Pour la base de données secondaire, le last_commit_time est l’heure de la dernière validation de la transaction sur la base de données primaire qui a également été confirmée sur la base de données secondaire. Ce nombre doit être le même pour les bases de données primaire et secondaire. Un écart entre ces deux valeurs représente la durée pendant laquelle les transactions en attente n’ont pas été confirmées sur la base de données secondaire et seront perdues en cas de basculement.
Compteurs de performances utilisés dans les formules RTO/RPO
- redo_queue_size (Ko) [utilisé dans le RTO] : la taille de la file d’attente de restauration par progression est la taille des journaux de transactions entre ses last_received_lsn et last_redone_lsn. last_received_lsn est l’ID de bloc du journal qui identifie le point jusqu’auquel tous les blocs du journal ont été reçus par le réplica secondaire qui héberge cette base de données secondaire. Last_redone_lsn est le numéro séquentiel dans le journal du dernier enregistrement du journal qui a été restauré par progression sur la base de données secondaire. En fonction de ces deux valeurs, nous pouvons trouver les ID du bloc de journal de début (last_received_lsn) et du bloc de journal de fin (last_redone_lsn). L’espace entre ces deux blocs de journal peut alors représenter combien de blocs de journal de transactions n’ont pas encore été restaurés par progression. C’est mesuré en kilo-octets (Ko).
- redo_rate (Ko/s) [utilisé dans le RTO] : valeur cumulative qui représente, à un moment du temps écoulé, la part du journal des transactions (Ko) qui a été restaurée par progression dans la base de données secondaire en kilo-octets par seconde (Ko/s).
- last_commit_time (Datetime) [utilisé dans le RPO] : pour la base de données primaire, last_commit_time est l’heure à laquelle la dernière transaction a été validée. Pour la base de données secondaire, le last_commit_time est l’heure de la dernière validation de la transaction sur la base de données primaire qui a également été confirmée sur la base de données secondaire. Étant donné que cette valeur sur la base de données secondaire doit être synchronisée avec la même valeur que celle sur la base de données primaire, tout écart entre ces deux valeurs est l’estimation de la perte de données (RPO).
Estimer le RTO et le RPO à l’aide de vues DMV
Il est possible d’interroger les vues DMV sys.dm_hadr_database_replica_states et sys.dm_hadr_database_replica_cluster_states pour estimer le RPO et le RTO d’une base de données. Les requêtes ci-dessous créent les procédures stockées qui accomplissent les deux choses.
Notes
Veillez à créer et à exécuter la procédure stockée pour estimer d’abord le RTO, car les valeurs qu’il génère sont nécessaires à l’exécution de la procédure stockée pour estimer le RPO.
Créer une procédure stockée pour estimer le RTO
- Sur le réplica secondaire cible, créez une procédure stockée proc_calculate_RTO. Si cette procédure stockée existe déjà, commencez par la supprimer, puis recréez-la.
if object_id(N'proc_calculate_RTO', 'p') is not null
drop procedure proc_calculate_RTO
go
raiserror('creating procedure proc_calculate_RTO', 0,1) with nowait
go
--
-- name: proc_calculate_RTO
--
-- description: Calculate RTO of a secondary database.
--
-- parameters: @secondary_database_name nvarchar(max): name of the secondary database.
--
-- security: this is a public interface object.
--
create procedure proc_calculate_RTO
(
@secondary_database_name nvarchar(max)
)
as
begin
declare @db sysname
declare @is_primary_replica bit
declare @is_failover_ready bit
declare @redo_queue_size bigint
declare @redo_rate bigint
declare @replica_id uniqueidentifier
declare @group_database_id uniqueidentifier
declare @group_id uniqueidentifier
declare @RTO float
select
@is_primary_replica = dbr.is_primary_replica,
@is_failover_ready = dbcs.is_failover_ready,
@redo_queue_size = dbr.redo_queue_size,
@redo_rate = dbr.redo_rate,
@replica_id = dbr.replica_id,
@group_database_id = dbr.group_database_id,
@group_id = dbr.group_id
from sys.dm_hadr_database_replica_states dbr join sys.dm_hadr_database_replica_cluster_states dbcs on dbr.replica_id = dbcs.replica_id and
dbr.group_database_id = dbcs.group_database_id where dbcs.database_name = @secondary_database_name
if @is_primary_replica is null or @is_failover_ready is null or @redo_queue_size is null or @replica_id is null or @group_database_id is null or @group_id is null
begin
print 'RTO of Database '+ @secondary_database_name +' is not available'
return
end
else if @is_primary_replica = 1
begin
print 'You are visiting wrong replica';
return
end
if @redo_queue_size = 0
set @RTO = 0
else if @redo_rate is null or @redo_rate = 0
begin
print 'RTO of Database '+ @secondary_database_name +' is not available'
return
end
else
set @RTO = CAST(@redo_queue_size AS float) / @redo_rate
print 'RTO of Database '+ @secondary_database_name +' is ' + convert(varchar, ceiling(@RTO))
print 'group_id of Database '+ @secondary_database_name +' is ' + convert(nvarchar(50), @group_id)
print 'replica_id of Database '+ @secondary_database_name +' is ' + convert(nvarchar(50), @replica_id)
print 'group_database_id of Database '+ @secondary_database_name +' is ' + convert(nvarchar(50), @group_database_id)
end
- Exécutez proc_calculate_RTO avec le nom de la base de données secondaire cible :
exec proc_calculate_RTO @secondary_database_name = N'DB_sec'
La sortie affiche la valeur RTO de la base de données du réplica secondaire cible. Enregistrez les group_id, replica_id et group_database_id pour les utiliser avec la procédure stockée d’estimation de RPO.
Exemple de sortie :
Le RTO de la base de données DB_sec' est 0
group_id de la base de données DB4 est F176DD65-C3EE-4240-BA23-EA615F965C9B
replica_id de la base de données DB4 est 405554F6-3FDC-4593-A650-2067F5FABFFD
group_database_id de la base de données DB4 est 39F7942F-7B5E-42C5-977D-02E7FFA6C392
Créer une procédure stockée pour estimer le RPO
- Sur le réplica principal, créez une procédure stockée proc_calculate_RPO. Si elle existe déjà, commencez par la supprimer, puis recréez-la.
if object_id(N'proc_calculate_RPO', 'p') is not null
drop procedure proc_calculate_RPO
go
raiserror('creating procedure proc_calculate_RPO', 0,1) with nowait
go
--
-- name: proc_calculate_RPO
--
-- description: Calculate RPO of a secondary database.
--
-- parameters: @group_id uniqueidentifier: group_id of the secondary database.
-- @replica_id uniqueidentifier: replica_id of the secondary database.
-- @group_database_id uniqueidentifier: group_database_id of the secondary database.
--
-- security: this is a public interface object.
--
create procedure proc_calculate_RPO
(
@group_id uniqueidentifier,
@replica_id uniqueidentifier,
@group_database_id uniqueidentifier
)
as
begin
declare @db_name sysname
declare @is_primary_replica bit
declare @is_failover_ready bit
declare @is_local bit
declare @last_commit_time_sec datetime
declare @last_commit_time_pri datetime
declare @RPO nvarchar(max)
-- secondary database's last_commit_time
select
@db_name = dbcs.database_name,
@is_failover_ready = dbcs.is_failover_ready,
@last_commit_time_sec = dbr.last_commit_time
from sys.dm_hadr_database_replica_states dbr join sys.dm_hadr_database_replica_cluster_states dbcs on dbr.replica_id = dbcs.replica_id and
dbr.group_database_id = dbcs.group_database_id where dbr.group_id = @group_id and dbr.replica_id = @replica_id and dbr.group_database_id = @group_database_id
-- correlated primary database's last_commit_time
select
@last_commit_time_pri = dbr.last_commit_time,
@is_local = dbr.is_local
from sys.dm_hadr_database_replica_states dbr join sys.dm_hadr_database_replica_cluster_states dbcs on dbr.replica_id = dbcs.replica_id and
dbr.group_database_id = dbcs.group_database_id where dbr.group_id = @group_id and dbr.is_primary_replica = 1 and dbr.group_database_id = @group_database_id
if @is_local is null or @is_failover_ready is null
begin
print 'RPO of database '+ @db_name +' is not available'
return
end
if @is_local = 0
begin
print 'You are visiting wrong replica'
return
end
if @is_failover_ready = 1
set @RPO = '00:00:00'
else if @last_commit_time_sec is null or @last_commit_time_pri is null
begin
print 'RPO of database '+ @db_name +' is not available'
return
end
else
begin
if DATEDIFF(ss, @last_commit_time_sec, @last_commit_time_pri) < 0
begin
print 'RPO of database '+ @db_name +' is not available'
return
end
else
set @RPO = CONVERT(varchar, DATEADD(ms, datediff(ss ,@last_commit_time_sec, @last_commit_time_pri) * 1000, 0), 114)
end
print 'RPO of database '+ @db_name +' is ' + @RPO
end
- Exécutez proc_calculate_RPO avec les group_id, replica_id et group_database_id de la base de données secondaire cible.
exec proc_calculate_RPO @group_id= 'F176DD65-C3EE-4240-BA23-EA615F965C9B',
@replica_id = '405554F6-3FDC-4593-A650-2067F5FABFFD',
@group_database_id = '39F7942F-7B5E-42C5-977D-02E7FFA6C392'
- La sortie affiche la valeur RPO de la base de données du réplica secondaire cible.
Supervision du RTO et du RPO
Cette section montre comment monitorer les métriques RTO et RPO des groupes de disponibilité. Cette démonstration est similaire au tutoriel de l’interface graphique utilisateur présenté dans The Always On health model, part 2: Extending the health model (Modèle d’intégrité Always On Partie 2 : Extension du modèle d’intégrité).
Les éléments de calcul du temps de basculement et du risque de perte de données dans Estimation du temps de basculement (RTO) et Estimation du risque de perte de données (RPO) sont proposés sous forme de métriques dans la facette de gestion de stratégie État du réplica de base de données (consultez Afficher les facettes de gestion basée sur des stratégies sur un objet SQL Server). Vous pouvez monitorer ces deux métriques selon une planification et recevoir une alerte quand elles dépassent le RTO et le RPO, respectivement.
Les scripts présentés créent deux stratégies système qui sont exécutées selon leur planification respective, avec les caractéristiques suivantes :
Une stratégie RTO échoue quand le temps de basculement estimé est supérieur à 10 minutes (évaluation toutes les 5 minutes)
Une stratégie RPO échoue quand la perte de données estimée est supérieure à 1 heure (évaluation toutes les 30 minutes)
Les deux stratégies ont la même configuration sur tous les réplicas de disponibilité
Les stratégies sont évaluées sur tous les serveurs, mais uniquement sur les groupes de disponibilité pour lesquels le réplica de disponibilité local est le réplica principal. Si le réplica de disponibilité local n’est pas le réplica principal, les stratégies ne sont pas évaluées.
Les échecs de stratégies sont clairement présentés dans le tableau de bord Always On affiché sur le réplica principal.
Pour créer les stratégies, suivez les instructions ci-dessous sur toutes les instances de serveur qui participent au groupe de disponibilité :
Démarrez le service SQL Server Agent si cela n’est pas déjà fait.
Dans SQL Server Management Studio, dans le menu Outils, cliquez sur Options.
Sous l’onglet SQL Server Always On, sélectionnez Activer la stratégie Always On définie par l’utilisateur, puis cliquez sur OK.
Ce paramètre vous permet d’afficher les stratégies personnalisées correctement configurées dans le tableau de bord Always On.
Créez une condition de gestion basée sur la stratégie à l’aide des spécifications suivantes :
Nom :
RTOFacette : État du réplica de base de données
Champ :
Add(@EstimatedRecoveryTime, 60)Opérateur : <=
Valeur :
600
Cette condition échoue quand le temps de basculement potentiel est supérieur à 10 minutes (dont une surcharge de 60 secondes pour la détection des échecs et le basculement).
Créez une deuxième condition de gestion basée sur la stratégie à l’aide des spécifications suivantes :
Nom :
RPOFacette : État du réplica de base de données
Champ :
@EstimatedDataLossOpérateur : <=
Valeur :
3600
Cette condition échoue quand la perte de données potentielle est supérieure à 1 heure.
Créez une troisième condition de gestion basée sur la stratégie à l’aide des spécifications suivantes :
Nom :
IsPrimaryReplicaFacette : Groupe de disponibilité
Champ :
@LocalReplicaRoleOpérateur : =
Valeur :
Primary
Cette condition vérifie si le réplica de disponibilité local pour un groupe de disponibilité donné est le réplica principal.
Créez une stratégie de gestion basée sur la stratégie à l’aide des spécifications suivantes :
Page Général :
Nom :
CustomSecondaryDatabaseRTOVérifier la condition :
RTOPar rapport aux cibles : Chaque DatabaseReplicaState dans IsPrimaryReplica AvailabilityGroup
Ce paramètre garantit que la stratégie est évaluée uniquement sur les groupes de disponibilité pour lesquels le réplica de disponibilité local est le réplica principal.
Mode d’évaluation : Selon planification
Planification : CollectorSchedule_Every_5min
Activé : Sélectionné
Page Description :
Catégorie : Avertissements de base de données de disponibilité
Ce paramètre permet d’afficher les résultats de l’évaluation de la stratégie dans le tableau de bord Always On.
Description : Le réplica actuel a un RTO supérieur à 10 minutes, avec pour hypothèse une surcharge de 1 minute pour la détection et le basculement. Vous devez examiner immédiatement les problèmes de performances sur l’instance de serveur respective.
Texte à afficher : RTO dépassé !
Créez une deuxième stratégie de gestion basée sur la stratégie à l’aide des spécifications suivantes :
Page Général :
Nom :
CustomAvailabilityDatabaseRPOVérifier la condition :
RPOPar rapport aux cibles : Chaque DatabaseReplicaState dans IsPrimaryReplica AvailabilityGroup
Mode d’évaluation : Selon planification
Planification : CollectorSchedule_Every_30min
Activé : Sélectionné
Page Description :
Catégorie : Avertissements de base de données de disponibilité
Description : La base de données de disponibilité a dépassé votre RPO de 1 heure. Vous devez immédiatement examiner les problèmes de performances sur les réplicas de disponibilité.
Texte à afficher : RPO dépassé !
Quand vous avez terminé, deux travaux SQL Server Agent sont créés, un pour chaque planification d’évaluation de stratégie. Le nom de ces travaux doit commencer par syspolicy_check_schedule.
Vous pouvez afficher l’historique des travaux pour examiner les résultats de l’évaluation. Les échecs d’évaluation sont également enregistrés dans le journal des applications Windows (dans l’observateur d’événements) avec l’ID d’événement 34052. Vous pouvez également configurer SQL Server Agent de manière à ce qu’il envoie des alertes en cas d’échec de stratégie. Pour plus d’informations, consultez Configurer des alertes pour informer les administrateurs de stratégie en cas d’échec de stratégie.
Scénarios de résolution des problèmes de performances
Le tableau suivant répertorie les scénarios courants de résolution des problèmes liés aux performances.
| Scénario | Description |
|---|---|
| Résolution du problème : Dépassement de RTO du groupe de disponibilité | Après un basculement automatique ou un basculement manuel planifié sans perte de données, le temps de basculement dépasse votre RTO. Vous pouvez aussi constater que votre estimation du temps de basculement d’un réplica secondaire avec validation synchrone (par exemple, un partenaire de basculement automatique) dépasse votre RTO. |
| Résolution du problème : Dépassement de RPO du groupe de disponibilité | À l’issue d’un basculement manuel forcé, la perte de données est supérieure à votre RPO. Vous pouvez aussi constater que votre calcul de la perte de données potentielle d’un réplica secondaire avec validation asynchrone dépasse votre RPO. |
| Résolution du problème : Les changements sur le réplica principal ne sont pas répercutés sur le réplica secondaire | L’application cliente mène à bien une mise à jour sur le réplica principal, mais l’exécution d’une requête sur le réplica secondaire montre que le changement n’a pas été répercuté. |
Événements étendus utiles
Les événements étendus suivants sont utiles dans le cadre de la résolution des problèmes liés aux réplicas dans l’état Synchronisation.
| Nom de l'événement | Category | Channel | Réplica de disponibilité |
|---|---|---|---|
| redo_caught_up | transactions | Débogage | Secondary |
| redo_worker_entry | transactions | Débogage | Secondary |
| hadr_transport_dump_message | alwayson |
Débogage | Principal |
| hadr_worker_pool_task | alwayson |
Débogage | Principal |
| hadr_dump_primary_progress | alwayson |
Débogage | Principal |
| hadr_dump_log_progress | alwayson |
Débogage | Principal |
| hadr_undo_of_redo_log_scan | alwayson |
Analytiques | Secondary |