Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S’applique à :![]() SQL Server 2016 (13.x) et ultérieur
SQL Server 2016 (13.x) et ultérieur
Cet article fournit une vue d’ensemble des solutions de continuité d’activité dans le cadre de la haute disponibilité et de la récupération d’urgence dans SQL Server, sous Windows et Linux.
Tout le monde qui déploie SQL Server doit s’assurer que toutes les instances SQL Server critiques et les bases de données qu’elles contiennent sont disponibles lorsque les utilisateurs professionnels et finaux en ont besoin, que cette disponibilité soit pendant les heures d’ouverture normales ou autour de l’horloge. L’objectif est de maintenir l’activité avec un minimum d’interruption voire sans interruption. Ce concept est également connu sous le nom de continuité d’activité.
SQL Server 2017 (14.x) et versions ultérieures ont introduit des fonctionnalités et des améliorations pour la disponibilité. L’ajout le plus important est la prise en charge de SQL Server sur les distributions Linux. Pour obtenir la liste complète des nouvelles fonctionnalités de SQL Server, consultez les articles suivants :
| Version | Système d’exploitation |
|---|---|
| Nouveautés de SQL Server 2025 (17.x) | Windows | Linux |
| Nouveautés de SQL Server 2022 (16.x) | Windows | Linux |
| Nouveautés de SQL Server 2019 (15.x) | Windows | Linux |
| Nouveautés de SQL Server 2017 (14.x) | Windows | Linux |
Cet article se concentre sur les scénarios de disponibilité dans SQL Server 2017 (14.x) et versions ultérieures, ainsi que sur les nouvelles fonctionnalités de disponibilité améliorées. Les scénarios incluent des scénarios hybrides qui peuvent s’étendre sur des déploiements SQL Server sur Windows Server et Linux, et ceux qui peuvent augmenter le nombre de copies lisibles d’une base de données.
Bien que cet article ne couvre pas les options de disponibilité externes à SQL Server (telles que la virtualisation), tout ce qui est abordé ici s’applique aux installations de SQL Server à l’intérieur d’une machine virtuelle invitée, que ce soit dans le cloud public ou hébergé par un serveur d’hyperviseur local.
Scénarios SQL Server qui utilisent des fonctionnalités de disponibilité
Vous pouvez utiliser des groupes de disponibilité Always On, des instances de cluster de basculement et la copie des journaux de transaction de différentes manières, et pas seulement pour la disponibilité. Il existe quatre façons principales d’utiliser les fonctionnalités de disponibilité :
- Haute disponibilité
- Récupération d'urgence
- Les migrations et les mises à niveau
- La mise à plus haute échelle des copies accessibles en lecture d’une ou plusieurs bases de données
Les sections suivantes décrivent les fonctionnalités pertinentes pour chaque scénario. Une fonctionnalité non couverte est la réplication SQL Server. Bien que la réplication SQL Server ne soit pas officiellement désignée comme fonctionnalité de disponibilité sous le parapluie Always On, elle est souvent utilisée pour rendre les données redondantes dans certains scénarios. La réplication de fusion n’est pas prise en charge pour SQL Server sur Linux. Pour plus d’informations, consultez réplication SQL Server sur Linux.
Importante
Les fonctionnalités de disponibilité de SQL Server ne remplacent pas la nécessité d’avoir une stratégie de sauvegarde et de restauration robuste et bien testée. Une stratégie de sauvegarde et de restauration est le bloc de construction le plus fondamental de toute solution de disponibilité.
Haute disponibilité
Il est important de s’assurer que les instances ou bases de données SQL Server sont disponibles si un problème se produit localement dans un centre de données ou une seule région dans le cloud. Cette section explique comment les fonctionnalités de disponibilité DE SQL Server peuvent vous aider. Toutes les fonctionnalités décrites sont disponibles aussi bien sur Windows Server que sur Linux.
Groupes de disponibilité
Les groupes de disponibilité fournissent une protection au niveau de la base de données en envoyant chaque transaction d’une base de données à une autre instance ou réplica, qui contient une copie de cette base de données dans un état spécial. Vous pouvez déployer un groupe de disponibilité sur les éditions Standard ou Enterprise. Les instances qui font partie d’un groupe de disponibilité peuvent être autonomes ou des instances de cluster de basculement (FCI, décrites dans la section suivante). Les transactions étant envoyées à un réplica à mesure qu’elles se produisent, les groupes de disponibilité sont recommandés quand il est nécessaire de baisser les objectifs de point de récupération et de délai de récupération. Le déplacement de données entre réplicas peut être synchrone ou asynchrone. L’édition Entreprise autorise jusqu'à trois réplicas synchrones (y compris le réplica principal). Un groupe de disponibilité contient une copie complète de la base de données accessible en écriture et en lecture qui se trouve sur le réplica principal. Les réplicas secondaires ne peuvent pas recevoir de transactions directement des utilisateurs finaux ou des applications.
Note
Always On est un terme général qui désigne les fonctionnalités de disponibilité dans SQL Server et inclut les groupes de disponibilité et les instances FCI. "Always On" n’est pas le nom de la fonctionnalité de "groupe de disponibilité" (AG).
Avant SQL Server 2022 (16.x), les groupes de disponibilité fournissent uniquement une protection au niveau de la base de données et non une protection au niveau de l’instance. Tout ce qui n’est pas capturé dans le journal des transactions ou configuré dans la base de données doit être synchronisé manuellement pour chaque réplica secondaire. Exemples d’objets devant être synchronisés manuellement : connexions au niveau de l’instance, serveurs liés et travaux de SQL Server Agent.
Dans SQL Server 2022 (16.x) et versions ultérieures, vous pouvez gérer les objets de métadonnées, notamment les utilisateurs, les connexions, les autorisations et les tâches de l'Agent SQL Server au niveau du groupe de disponibilité en plus du niveau de l’instance. Pour plus d’informations, consultez Qu’est-ce qu’un groupe de disponibilité autonome ?
Un groupe de disponibilité a également un autre composant qui est l’écouteur. Il permet aux applications et aux utilisateurs finaux de se connecter sans avoir besoin de connaître l’instance de SQL Server qui héberge le réplica principal. Chaque groupe de disponibilité possède son propre écouteur. Bien que les implémentations de l’écouteur soient légèrement différentes sur Windows Server et Linux, elles fournissent toutes deux les mêmes fonctionnalités et facilité d’utilisation. Le diagramme suivant montre un AG basé sur Windows Server qui utilise un cluster de basculement de Windows Server (WSFC). Un cluster sous-jacent au niveau de la couche système d’exploitation est requis pour la disponibilité, qu’il soit sur Linux ou Windows Server. L’exemple montre une configuration simple à deux serveurs, ou nœuds, où le cluster sous-jacent est un cluster WSFC.
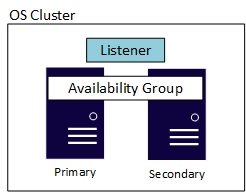
Les éditions Standard et Entreprise prennent chacune en charge un nombre maximal de réplicas différent. Un groupe de disponibilité dans l’édition Standard, appelé groupe de disponibilité de base, prend en charge deux réplicas (un réplica principal et un secondaire) et une seule base de données dans le groupe de disponibilité. L’édition Entreprise permet non seulement de configurer plusieurs bases de données dans un seul AG, mais prend en charge également jusqu'à neuf réplicas au total (un réplica principal et huit secondaires). L’édition Entreprise fournit d’autres avantages comme des réplicas secondaires accessibles en lecture, la possibilité d’effectuer des sauvegardes d’un réplica secondaire, et bien plus encore.
Note
La mise en miroir de bases de données, qui a été déconseillée dans SQL Server 2012 (11.x), n’est pas disponible sur la version Linux de SQL Server, ni elle n’est ajoutée. Les clients qui utilisent encore la mise en miroir de bases de données doivent planifier la migration vers les AG, qui remplacent la mise en miroir de bases de données.
En matière de disponibilité, les groupes de disponibilité peuvent fournir un basculement automatique ou manuel. Un basculement automatique peut se produire si un déplacement de données synchrone est configuré et que la base de données est synchronisée sur les réplicas principal et secondaire. Tant que l’écouteur est utilisé et que l’application utilise une version prise en charge de .NET Framework (3.5 avec Service Pack 1 ou 4.6.2 et versions ultérieures), le basculement doit être géré avec un minimum d’effet sur les utilisateurs finaux si un écouteur est utilisé. Le basculement vers un réplica secondaire pour en faire un réplica principal peut être automatique ou manuel, et est généralement mesuré en secondes.
La liste suivante met en évidence certaines différences avec les Availability Groups sur Windows Server par rapport à Linux :
En raison du fonctionnement du cluster sous-jacent sur Linux et Windows Server, tous les basculements des AG (manuels ou automatiques) sont effectués via le cluster sur Linux. Pour les déploiements de groupes de disponibilité de base Windows Server, les basculements manuels doivent être effectués via SQL Server. Les basculements automatiques sont gérés par le cluster sous-jacent sur Windows Server et Linux.
Pour SQL Server sur Linux, il est recommandé de configurer un groupe de disponibilité avec un minimum de trois réplicas, en raison du mode de fonctionnement du clustering sous-jacent.
Sur Linux, le nom commun utilisé par chaque écouteur est défini dans DNS et non dans le cluster tel qu’il se trouve sur Windows Server.
SQL Server 2017 (14.x) a introduit les fonctionnalités et améliorations suivantes pour les AGs (groupes de disponibilité) :
- Types de cluster
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT- Amélioration de la prise en charge de Microsoft Distributor Transaction Coordinator (DTC) pour les configurations basées sur Windows Server
- Ajout de scénarios de scale-out pour les bases de données en lecture seule (décrits plus loin dans cet article)
Types de cluster des groupes de disponibilité
La forme de disponibilité intégrée de clustering dans Windows Server est activée via une fonctionnalité nommée Clustering de basculement. Cela vous permet de créer un cluster WSFC à utiliser avec un groupe de disponibilité ou une instance FCI. SQL Server fournit des DLL de ressources prenant en charge les clusters qui fournissent une intégration pour les groupes de disponibilité et les instances de cluster.
SQL Server sur Linux prend en charge plusieurs technologies de clustering. Microsoft prend en charge les composants SQL Server, tandis que nos partenaires prennent en charge la technologie de clustering appropriée. Par exemple, avec Pacemaker, SQL Server sur Linux prend en charge HPE Serviceguard et DH2i DxEnterprise en tant que solution de cluster.
Un cluster de basculement Windows et une solution de cluster Linux sont plus similaires que différents. Tous deux permettent de combiner des serveurs individuels dans une configuration pour assurer la disponibilité et utilisent des concepts comme les ressources, les contraintes (même si elles sont implémentées différemment), le basculement, etc.
Par exemple, pour prendre en charge Pacemaker dans les configurations de groupes de disponibilité et d’instances FCI (y compris le basculement automatique), Microsoft fournit le package mssql-server-ha pour Pacemaker, qui est similaire, mais pas exactement identique, aux DLL de ressource dans un cluster WSFC. Un cluster WSFC et Pacemaker se distinguent notamment par le fait qu’aucune ressource de nom de réseau n’est incluse dans Pacemaker, car celui-ci récupère le nom de l’écouteur (ou le nom de l’instance de cluster de basculement) sur un cluster WSFC. Utilisez DNS pour la résolution de noms sur Linux.
En raison de la différence dans la pile de cluster, les groupes de disponibilité dans SQL Server 2017 (14.x) et les versions ultérieures doivent gérer certaines des métadonnées gérées en mode natif par un cluster WSFC. Par exemple, il existe trois types de clusters pour un groupe de disponibilité, qui sont stockés dans sys.availability_groups, cluster_type et cluster_type_desc colonnes :
- WSFC
- Externe
- Aucun
Tous les groupes de disponibilité nécessitant une haute disponibilité doivent utiliser un cluster sous-jacent, ce qui, dans le cas de SQL Server 2017 (14.x) et des versions ultérieures, signifie WSFC ou un agent de clustering Linux. Pour les groupes de disponibilité (AG) basés sur Windows Server qui utilisent un cluster WSFC sous-jacent, le type de cluster par défaut est WSFC et il n'est pas nécessaire de le définir. Pour les groupes de disponibilité basés sur Linux, vous devez définir le type de cluster sur External lors de la création du groupe de disponibilité. L’intégration à une solution de cluster externe sous Linux est configurée après la création du groupe de disponibilité, tandis que sur un cluster WSFC, elle est effectuée au moment de la création.
Le type de cluster Aucun peut être utilisé avec les groupes de disponibilité Windows Server et Linux. Quand vous définissez le type de cluster sur Aucun, le groupe de disponibilité n’a pas besoin de cluster sous-jacent. Cela signifie que SQL Server 2017 (14.x) est la première version de SQL Server qui prend en charge les groupes de disponibilité sans cluster. Toutefois, cette configuration n’est pas prise en charge comme solution de haute disponibilité.
Importante
Dans SQL Server 2017 (14.x) et les versions ultérieures, vous ne pouvez pas changer le type de cluster d'un groupe de disponibilité une fois celui-ci créé. Cette restriction signifie qu’un groupe de disponibilité ne peut pas être modifié de None à External ou WSFC, et d'un type à l'autre.
Si vous souhaitez uniquement ajouter des copies en lecture seule supplémentaires d’une base de données, ou si vous souhaitez ce qu’un groupe de disponibilité fournit pour la migration et les mises à niveau, mais ne souhaitez pas gérer la complexité d’un cluster sous-jacent ou même la réplication, envisagez de configurer un groupe de disponibilité avec un type de cluster None. Pour plus d’informations, consultez les sections Migrations et mises à niveau et mise à l’échelle en lecture.
La capture d’écran suivante montre la prise en charge des différents types de clusters dans SQL Server Management Studio (SSMS). Vous devez exécuter la version 17.1 ou ultérieure. La capture d’écran suivante provient de la version 17.2 :

REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT
Dans SQL Server 2016 (13.x), la prise en charge du nombre de réplicas synchrones est passée de deux à trois dans l’édition Entreprise. Toutefois, si un réplica secondaire est synchronisé, mais que l’autre réplica rencontre un problème, il n’existe aucun moyen de contrôler le comportement pour indiquer au réplica principal d’attendre le réplica comportant un problème ou de lui permettre de continuer. Dans ce scénario, le réplica principal peut toujours recevoir du trafic d’écriture même si le réplica secondaire n’est pas dans un état synchronisé, ce qui entraîne une perte de données sur le réplica secondaire.
Dans SQL Server 2017 (14.x) et versions ultérieures, vous pouvez contrôler le comportement de ce qui se passe lorsqu’il existe des réplicas synchrones avec REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT. Cette option fonctionne de la façon suivante :
- Il existe trois valeurs possibles :
0,1et2. - La valeur correspond au nombre de réplicas secondaires qui doivent être synchronisés, ce qui a des implications pour la perte de données, la disponibilité du groupe AG et le basculement.
- Pour les WSFCs et un type de cluster None, la valeur par défaut est
0, et vous pouvez la définir manuellement sur1ou2. - Pour un type de cluster Externe, le mécanisme de cluster définit cette valeur par défaut et vous pouvez le remplacer manuellement. Pour trois réplicas synchrones, la valeur par défaut est
1.
Sur Linux, vous configurez la valeur de la ressource du groupe de disponibilité AG REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT dans le cluster. Sur Windows, vous le définissez via Transact-SQL.
Une valeur supérieure à 0 assure une meilleure protection des données, parce que si le nombre requis de répliques secondaires n’est pas disponible, la réplique principale n’est pas disponible tant que cette condition n’est pas résolue.
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT affecte également le comportement de basculement, car le basculement automatique ne peut pas se produire si le nombre approprié de répliques secondaires n’est pas dans le bon état. Sur Linux, une valeur de 0 n'autorise pas le basculement automatique. Par conséquent, lors de l'utilisation synchrone avec basculement automatique sur Linux, vous devez définir la valeur à un niveau supérieur à 0 pour obtenir le basculement automatique.
0 sur Windows Server est le comportement dans SQL Server 2016 (13.x) et versions antérieures.
Amélioration de la prise en charge de Microsoft Distributed Transaction Coordinator
Avant SQL Server 2016 (13.x), la seule façon d’obtenir la disponibilité dans SQL Server pour les applications nécessitant des transactions distribuées, qui utilisent DTC sous les couvertures, était de déployer des FCI. Une transaction distribuée peut être effectuée de deux manières :
- Transaction qui s’étend sur plusieurs bases de données dans la même instance SQL Server.
- Une transaction qui s’étend sur plusieurs instances SQL Server ou éventuellement implique une source de données non-SQL Server.
SQL Server 2016 (13.x) a introduit la prise en charge partielle de DTC avec les groupes de disponibilité (2ème scénario). SQL Server 2017 (14.x) complète la prise en charge dans les deux scénarios avec DTC.
Dans SQL Server 2017 (14.x) et versions ultérieures, vous pouvez ajouter la prise en charge du DTC à un groupe de disponibilité après qu'il a été créé. Dans SQL Server 2016 (13.x), vous ne pouvez activer la prise en charge DTC que lors de la création d'un groupe de disponibilité.
Instances de cluster de basculement
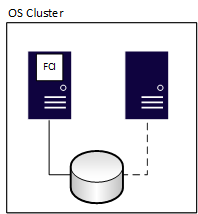
Les instances de cluster de basculement assurent la disponibilité pour toute l’installation de SQL Server, appelée instance. Avec les instances de cluster de basculement, si le serveur sous-jacent rencontre un problème, tout ce qui se trouve à l’intérieur de l’instance est déplacé vers un autre serveur, notamment les bases de données, les tâches du SQL Server Agent, les serveurs liés, et plus encore. Toutes les FCI nécessitent un stockage partagé, même s'il est défini par le réseau. Un nœud peut s’exécuter et posséder les ressources de l’instance de cluster de basculement à tout moment donné. Dans le diagramme suivant, le premier nœud du cluster détient l'instance FCI. Il possède également les ressources de stockage partagées qui lui sont associées, comme l'indique la ligne continue menant au stockage.
Après un basculement, le droit de propriété change, comme illustré dans le diagramme suivant :
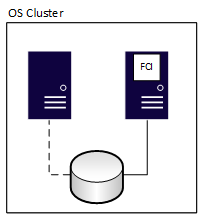
Une instance de cluster de basculement a zéro perte de données, mais le stockage partagé sous-jacent est un point de défaillance unique, car il existe une copie des données. Pour avoir des copies redondantes de bases de données, combinez des FCI avec une autre méthode de haute disponibilité, telle qu'un groupe de disponibilité ou l'expédition des journaux de transactions. L’autre méthode doit utiliser un stockage physiquement distinct du FCI (instance de cluster de basculement). Lorsque l’instance FCI bascule vers un autre nœud, elle s’arrête sur un nœud et démarre sur un autre. Ce processus est similaire à la mise hors tension d’un serveur et à son activation.
Une instance de cluster de basculement passe par le processus de récupération normal. Elle applique toutes les transactions qui doivent être avancées et annule toutes les transactions incomplètes. Par conséquent, la base de données reste cohérente depuis un point de données jusqu'au moment de l'échec ou du basculement manuel, ce qui empêche toute perte de données. Les bases de données ne sont disponibles qu’une fois la récupération terminée. Le temps de récupération dépend de nombreux facteurs et est généralement plus long que le basculement d’un groupe de disponibilité (AG). Le compromis est que lorsque vous basculez un groupe de disponibilité, il peut y avoir des tâches supplémentaires nécessaires pour rendre une base de données utilisable, comme l’activation d’un travail SQL Server Agent.
Note
La récupération de base de données accélérée (ADR) peut atténuer le temps de récupération. Pour plus d’informations, consultez Récupération de base de données accélérée.
Tout comme les AG, les instances FCI récupèrent le nœud du cluster sous-jacent qui les héberge. Une instance FCI conserve toujours le même nom. Les applications et les utilisateurs finaux ne se connectent jamais aux nœuds. Au lieu de cela, ils utilisent le nom unique affecté à la FCI. Une instance FCI peut participer à un groupe de disponibilité sous la forme d’une instance hébergeant un réplica principal ou secondaire.
La liste suivante met en évidence certaines différences avec les FCI sur Windows Server et Linux :
- Sur Windows Server, une instance FCI fait partie du processus d’installation. Vous configurez une FCI (instance de cluster de basculement) sur Linux après avoir installé SQL Server.
- Linux ne prend en charge qu'une seule installation de SQL Server par hôte, donc toutes les instances de cluster de basculement (FCI) sont des instances par défaut. Windows Server prend en charge jusqu'à 25 instances FCI par cluster WSFC.
- Le nom commun utilisé par les instances FCI dans Linux est défini dans le système DNS, et doit être identique à la ressource créée pour l’instance FCI.
Copie des journaux de transaction
Si les objectifs de point de récupération et de temps de récupération sont plus flexibles, ou que les bases de données ne sont pas de la plus haute importance critique, la journalisation des transactions est une autre fonctionnalité de disponibilité éprouvée dans SQL Server. Basé sur les sauvegardes natives de SQL Server, le processus de copie des journaux de transaction génère automatiquement des sauvegardes de fichier journal, les copie dans une ou plusieurs instances appelées secours semi-automatique, et applique automatiquement les sauvegardes du fichier journal à ce secours. La copie des journaux de transaction utilise les travaux de SQL Server Agent pour automatiser le processus de sauvegarde, de copie et d’application des sauvegardes du fichier journal.
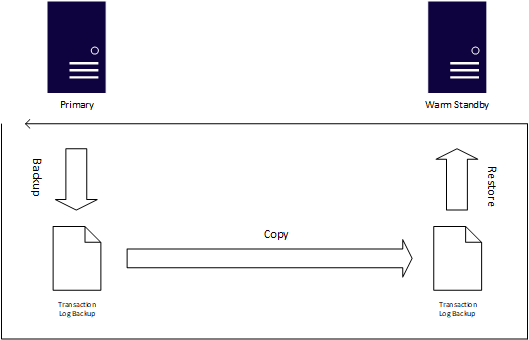
Le plus grand avantage du transfert des journaux est qu'il prend en compte les erreurs humaines, car vous pouvez retarder l'application des journaux de transaction. Par exemple, si quelqu’un émet un UPDATE sans une clause WHERE, le système de secours n’a peut-être pas la modification, vous pouvez donc basculer vers celui-ci pendant que vous réparez le système principal. Bien que l'expédition de journaux soit facile à configurer, le passage du serveur primaire à un serveur de secours préchauffé, appelé changement de rôle, est toujours manuel. Vous lancez une modification de rôle via Transact-SQL et, à l'instar d'un groupe de disponibilité (AG), vous devez synchroniser manuellement tous les objets qui ne sont pas capturés dans le journal des transactions. Vous devez configurer l'expédition des journaux de transaction pour chaque base de données, tandis qu'un seul groupe de disponibilité peut contenir plusieurs bases de données.
Contrairement à un groupe de disponibilité ou à une instance FCI, la copie des journaux de transaction n’a pas d’abstraction pour un changement de rôle, que les applications doivent être en mesure de gérer. Des techniques comme l’alias DNS (CNAME) peuvent être utilisées, mais il existe des avantages et des inconvénients, par exemple, le temps que prend le système DNS pour l’actualisation après le basculement.
Récupération d'urgence
Quand votre emplacement de disponibilité principal subit un événement catastrophique comme un tremblement de terre ou une inondation, l’entreprise doit être préparée à mettre ses systèmes en ligne ailleurs. Cette section explique comment les fonctionnalités de disponibilité DE SQL Server peuvent aider à assurer la continuité de l’activité.
Groupes de disponibilité
L’un des avantages des groupes de disponibilité est que vous configurez à la fois la haute disponibilité et la récupération d’urgence à l’aide d’une seule fonctionnalité. S’il n’est pas nécessaire de garantir la haute disponibilité du stockage partagé, il est bien plus facile d’avoir des réplicas locaux dans un seul centre de données pour la haute disponibilité et des réplicas distants dans d’autres centres de données pour la récupération d’urgence, chacun avec un stockage séparé. La redondance entraîne en contrepartie des copies supplémentaires de la base de données. Un exemple d'AG qui s’étend sur plusieurs centres de données est illustré dans le diagramme suivant. Un seul réplica principal est responsable de la synchronisation de tous les réplicas secondaires.

En dehors d’un groupe de disponibilité avec un type de cluster None, un groupe de disponibilité exige que tous les réplicas fassent partie du même cluster sous-jacent, qu’il s’agisse, par exemple, d’un cluster WSFC ou d’une solution de cluster externe. Dans le diagramme précédent, le cluster WSFC est étendu pour fonctionner dans deux centres de données différents, ce qui ajoute de la complexité, quelle que soit la plateforme (Windows Server ou Linux). Le fait d’étirer les clusters sur la distance ajoute de la complexité.
À compter de SQL Server 2016 (13.x), un groupe de disponibilité distribué permet à un groupe de disponibilité de configurer des groupes de disponibilité sur des clusters différents. Les groupes de disponibilité distribués découplent l’exigence selon laquelle tous les nœuds doivent participer au même cluster et facilite donc la configuration de la récupération d’urgence. Pour plus d’informations sur les groupes de disponibilité distribués, consultez Groupes de disponibilité distribués.
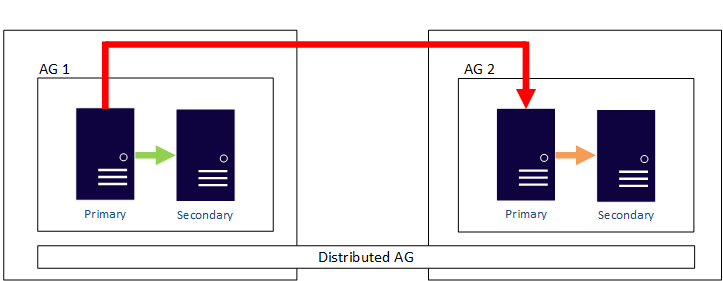
Instances de cluster de basculement
Vous pouvez utiliser les FCI pour la récupération d'urgence. Comme pour un groupe de disponibilité normal, il est nécessaire d'étendre le mécanisme de cluster sous-jacent à tous les sites, ce qui ajoute de la complexité. Pour les instances de cluster de basculement, vous devez également prendre en compte le stockage partagé. Les sites principaux et secondaires doivent accéder aux mêmes disques. Pour vous assurer que le stockage utilisé par l'instance de cluster de basculement (FCI) existe dans les deux sites, utilisez une méthode externe telle que les fonctionnalités fournies par le fournisseur de stockage au niveau de la couche matérielle. La fonctionnalité Storage Replica sous Windows Server peut également être utilisée.
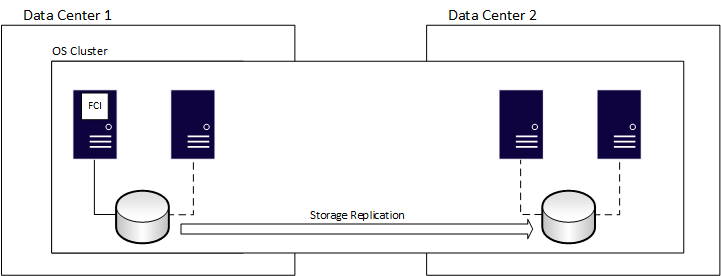
Copie des journaux de transaction
La journalisation est l'une des méthodes les plus anciennes pour fournir une récupération d'urgence pour les bases de données SQL Server. L'expédition des journaux est souvent utilisée avec des groupes de disponibilité et des Instances de Cluster de Basculement (FCI) pour fournir une solution de récupération d'urgence économique et plus simple, lorsque d'autres options peuvent être difficiles à mettre en œuvre en raison des contraintes de l'environnement, des compétences administratives ou du budget. À l'instar du scénario de haute disponibilité pour la transmission des journaux, de nombreux environnements retardent le chargement d'un journal des transactions pour prendre en compte les erreurs humaines.
Les migrations et les mises à niveau
Lorsqu’une organisation déploie de nouvelles instances ou met à niveau des anciennes instances, elle ne peut pas tolérer de longues pannes. Cette section explique comment les fonctionnalités de disponibilité de SQL Server peuvent être utilisées pour réduire le temps d’arrêt dans une modification d’architecture planifiée, le changement de serveur, le changement de plateforme (par exemple, Windows Server sur Linux ou vice versa) ou pendant la mise à jour corrective.
Note
Vous pouvez également utiliser d’autres méthodes, telles que les sauvegardes et les restaurations, pour les migrations et les mises à niveau. Cet article ne traite pas de ces méthodes.
Groupes de disponibilité
Vous pouvez mettre à niveau une instance existante qui contient un ou plusieurs groupes de disponibilité (AGs) en place, vers des versions ultérieures de SQL Server. Bien que cette mise à niveau nécessite un certain temps d’arrêt, elle peut être réduite avec la bonne planification.
Si vous souhaitez migrer vers de nouveaux serveurs sans modifier la configuration (y compris le système d’exploitation ou la version de SQL Server), ajoutez ces serveurs en tant que nœuds au cluster sous-jacent existant, puis ajoutez-les au groupe de disponibilité. Une fois que la réplique ou les répliques sont dans l’état approprié, effectuez un basculement manuel vers un nouveau serveur. Ensuite, supprimez les anciens serveurs du groupe de disponibilité et mettez-les hors service.
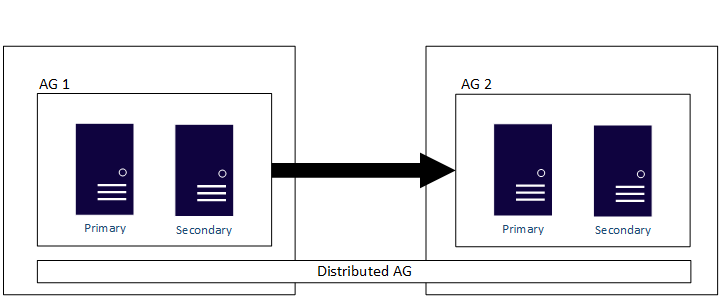
Les groupes de disponibilité distribués permettent eux aussi de migrer vers une nouvelle configuration ou de mettre à niveau SQL Server. Étant donné qu’un groupe de disponibilité distribué prend en charge différents groupes de disponibilité sous-jacents sur différentes architectures, vous pouvez passer de SQL Server 2019 (15.x) s’exécutant sur Windows Server 2019 à SQL Server 2025 (17.x) s’exécutant sur Windows Server 2025.
Enfin, les AGs avec un type de cluster None sont utiles pour la migration ou la mise à niveau. Vous ne pouvez pas combiner et mettre en correspondance les types de cluster dans une configuration de groupe de disponibilité standard. Tous les réplicas doivent donc être un type None. Un groupe de disponibilité distribué peut être utilisé pour étendre les groupes de disponibilité configurés avec différents types de cluster. Cette méthode est également prise en charge sur différentes plateformes de système d’exploitation.
Toutes les variantes des groupes de disponibilité pour les migrations et les mises à niveau permettent la synchronisation des données, la partie la plus longue du travail, qui peut être répartie au fil du temps. Quand il est temps de lancer le basculement vers la nouvelle configuration, le basculement est une panne brève, plutôt qu’une longue période de temps d’arrêt où tous les travaux, y compris la synchronisation des données, doivent être terminés.
Les groupes de disponibilité peuvent fournir un temps d'arrêt minimal pendant la mise à jour corrective du système d'exploitation sous-jacent en procédant à un basculement manuel de la réplique principale vers une réplique secondaire pendant que la mise à jour corrective est en cours. Du point de vue du système d’exploitation, cela est plus courant sur Windows Server, car la maintenance du système d’exploitation sous-jacent peut nécessiter un redémarrage. La mise à jour corrective de Linux nécessite parfois un redémarrage, mais elle est moins courante.
Une autre façon de réduire le temps d’arrêt consiste à corriger les instances SQL Server participant à un groupe de disponibilité, en fonction de la complexité de l’architecture du groupe de disponibilité. Vous corrigez d’abord un réplica secondaire. Une fois le nombre approprié de répliques corrigées, effectuez manuellement une bascule du réplica principal vers un autre nœud pour effectuer la mise à niveau. Mettez à niveau les réplicas secondaires restants à ce stade.
Instances de cluster de basculement
Les FCI ne peuvent pas aider par eux-mêmes à effectuer une migration ou une mise à niveau traditionnelle. Vous devez configurer un groupe de disponibilité (AG) ou un transfert des journaux de transaction pour les bases de données dans l’instance de cluster de basculement (FCI) et prendre en compte tous les autres objets. Toutefois, les instances de cluster de basculement sous Windows Server restent une option populaire lorsque vous devez appliquer des correctifs aux serveurs Windows sous-jacents. Lorsque vous lancez un basculement manuel, la brève interruption remplace le fait que l'instance soit indisponible pendant toute la période où Windows Server est mis à jour.
Vous pouvez mettre à niveau une instance FCI en place vers des versions ultérieures de SQL Server. Pour plus d’informations, consultez Mettre à niveau une instance de cluster de basculement.
Copie des journaux de transaction
La copie des journaux de transaction reste une option courante pour migrer et mettre à niveau des bases de données. Comme pour les AG, mais cette fois en utilisant le journal des transactions comme méthode de synchronisation, la propagation des données peut être démarrée un certain temps avant le basculement de serveur. Au moment du basculement, une fois que tout le trafic est interrompu au niveau de la source, un journal de transactions final doit être capturé, copié et appliqué à la nouvelle configuration. À ce stade, la base de données peut être mise en ligne.
L'expédition de journaux est souvent plus tolérante envers les réseaux plus lents et, bien que le basculement puisse être légèrement plus long que celui effectué à l’aide d’un groupe de disponibilité (AG) ou d’un groupe de disponibilité distribué, il est généralement mesuré en minutes, plutôt qu'en heures, jours ou semaines.
Comme pour les groupes de sécurité réseau, la copie des journaux de transaction peut fournir un moyen de basculer vers un autre serveur pendant une fenêtre de maintenance.
Autres méthodes de déploiement de SQL Server et disponibilité
Il existe deux autres méthodes de déploiement de SQL Server sur Linux : les conteneurs et l’utilisation d’Azure (ou d’un autre fournisseur de cloud public). Le besoin général de disponibilité existe, quel que soit le mode de déploiement de SQL Server. Ces deux méthodes présentent des considérations particulières lors de la mise à disposition de SQL Server à haut niveau de disponibilité.
Conteneurs SQL Server et options HA/DR
Le déploiement de conteneurs SQL Server est un moyen de simplifier l’approvisionnement, la mise à l’échelle et la gestion du cycle de vie SQL Server dans les environnements. Un conteneur est une image prête à l’exécution complète de SQL Server.
Selon votre plateforme de conteneurs, par exemple lors de l’utilisation d’un orchestrateur de conteneurs comme Kubernetes, si le conteneur est perdu, il peut être redéployé et attaché au stockage partagé utilisé. Bien que cela offre une certaine résilience, il y a une période d'interruption associée à la récupération de la base de données, et ce n’est pas réellement très hautement disponible, comme ce serait le cas si vous utilisiez un groupe de disponibilité ou une instance de cluster de disponibilité.
Si vous souhaitez configurer la haute disponibilité pour les conteneurs SQL Server déployés sur des plateformes Kubernetes ou non Kubernetes, vous pouvez utiliser DH2i DxEnterprise comme l’une des solutions de clustering, par-dessus laquelle vous pouvez configurer un groupe de disponibilité en mode haute disponibilité. Cette option vous fournit l’objectif de point de récupération (RPO) et l’objectif de temps de récupération (RTO) attendus d’une solution de haute disponibilité.
Déploiement de machines virtuelles linux
Linux peut être déployé avec SQL Server sur des machines virtuelles Azure Linux. Comme pour les installations locales, une installation prise en charge nécessite l’utilisation d’une configuration de clôture pour un nœud défaillant qui est externe à l’agent de cluster lui-même. La clôture de nœud est fournie via des agents de disponibilité de clôture. Certaines distributions les incluent dans la plateforme, tandis que d’autres font appel à des fournisseurs de matériel et de logiciels externes. Vérifiez avec votre distribution Linux préférée pour voir quelles formes d’clôture de nœud sont fournies afin qu’une solution prise en charge puisse être déployée dans le cloud public.
Les guides d’installation des SQL Server sur Linux sont disponibles pour les distributions suivantes :
- Démarrage rapide : Installer SQL Server et créer une base de données sur Red Hat
- Démarrage rapide : Installer SQL Server et créer une base de données sur Ubuntu
- Démarrage rapide : Installer SQL Server et créer une base de données sur SUSE Linux Enterprise Server
Évolutivité des opérations de lecture
Les réplicas secondaires peuvent être utilisés pour les requêtes en lecture seule. Il existe deux façons d’y parvenir avec un AG :
- Autoriser l’accès direct au serveur secondaire
- Configuration du routage en lecture seule, ce qui nécessite l’utilisation de l’écouteur. SQL Server 2016 (13.x) a introduit la possibilité d’équilibrer la charge des connexions en lecture seule via l’écouteur à l’aide d’un algorithme de type tourniquet (Round Robin), ce qui permet aux demandes en lecture seule d’être réparties sur tous les réplicas accessibles en lecture.
Note
Les répliques secondaires lisibles sont disponibles uniquement dans l’édition Entreprise. Chaque instance qui héberge un réplica lisible a besoin d’une licence SQL Server.
La mise à l’échelle des copies lisibles d’une base de données via des groupes de disponibilité a été introduite initialement avec des groupes de disponibilité distribués dans SQL Server 2016 (13.x). Cette fonctionnalité offre des copies en lecture seule de la base de données non seulement localement, mais également régionalement et globalement, avec une configuration minimale. Cette configuration réduit le trafic réseau et la latence en ayant des requêtes exécutées localement. Chaque réplique principale d’un groupe de disponibilité peut amorcer deux autres groupes de disponibilité, même s’il ne s’agit pas de la copie complète en lecture/écriture, et chaque groupe de disponibilité distribué peut prendre en charge jusqu’à 27 copies accessibles en lecture des données.

Dans SQL Server 2017 (14.x) et versions ultérieures, vous pouvez créer une solution en lecture seule en temps quasi réel avec des groupes de disponibilité configurés avec un type de cluster None. Si votre objectif est d'utiliser des groupes de disponibilité pour des réplicas secondaires lisibles plutôt que pour la haute disponibilité, cette approche supprime la complexité de l'utilisation d'un cluster WSFC (Windows Server Failover Cluster) ou d'une solution de cluster externe sur Linux. Il offre les avantages facilement compréhensibles d’un groupe de disponibilité, dans une méthode de déploiement simplifiée.
La seule mise en garde majeure est qu'en l'absence d'un cluster sous-jacent de type None, la configuration du routage en lecture seule diffère légèrement. En ce qui concerne SQL Server, un écouteur est toujours nécessaire pour router les demandes, même en cas d’absence de cluster. Au lieu de configurer un écouteur traditionnel, utilisez l’adresse IP ou le nom du réplica principal. Le réplica principal achemine ensuite les requêtes en lecture seule.
Une veille à chaud par expédition de journaux peut être techniquement configurée pour une utilisation en lecture en restaurant la base de données WITH STANDBY. Toutefois, parce que les journaux de transaction nécessitent l’utilisation exclusive de la base de données pour la restauration, les utilisateurs ne peuvent pas accéder à la base de données pendant l’opération. De ce fait, la copie des journaux de transaction est une solution moins idéale, en particulier si vous avez besoin des données quasiment en temps réel.
Contrairement à la réplication transactionnelle où toutes les données sont actives, chaque réplica secondaire dans un scénario à l’échelle de lecture est une copie exacte du réplica principal. Le réplica n’est pas dans un état où des index uniques peuvent être appliqués. Si des index sont requis pour la création de rapports ou si des données doivent être manipulées, vous devez créer ces index sur les bases de données sur le réplica principal. Si vous avez besoin de cette flexibilité, la réplication est une meilleure solution pour les données accessibles en lecture.
Scénarios multiplateformes et d’interopérabilité entre distributions Linux
Avec la prise en charge de SQL Server sur Windows Server et Linux, cette section explique comment elles peuvent fonctionner ensemble pour la disponibilité en plus d’autres fins. Il aborde également l’histoire des solutions qui incorporent plusieurs distributions Linux.
Note
Il n’existe aucun scénario dans lequel une instance de cluster de basculement basée sur WSFC (FCI) ou un groupe de disponibilité (AG) peut fonctionner directement avec une instance de cluster de basculement basée sur Linux ou un groupe de disponibilité. Un cluster de basculement Windows Server (WSFC) ne peut pas être étendu par un nœud Pacemaker et inversement.
Groupes de disponibilité distribués
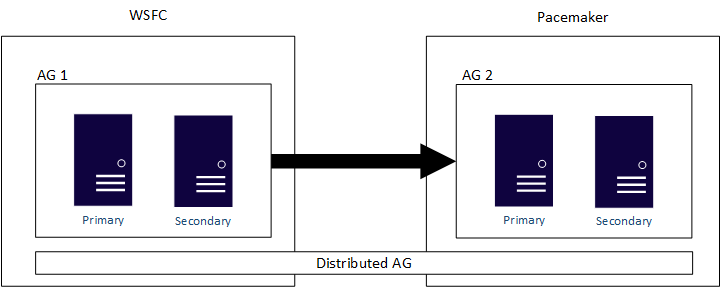
Les groupes de disponibilité distribués sont conçus pour englober les configurations de AG, que les deux clusters sous-jacents des groupes de disponibilité soient deux clusters WSFC distincts, des distributions Linux ou un cluster WSFC et une distribution Linux. Un groupe de disponibilité distribué est la méthode principale pour obtenir une solution multiplateforme. Un groupe de disponibilité distribué constitue également la solution principale pour les migrations comme la conversion d’une infrastructure SQL Server basée sur Windows Server en infrastructure basée sur Linux si tel est le souhait de votre entreprise. Comme indiqué précédemment, les groupes de disponibilité et surtout les groupes de disponibilité distribués réduisent le temps pendant lequel une application n’est pas disponible pour une utilisation. Voici un exemple de groupe de disponibilité distribué qui s’étend sur un cluster WSFC et Pacemaker, comme le montre le diagramme suivant :
Si vous configurez un groupe de disponibilité avec un type de cluster None, il peut s’étendre sur Windows Server et Linux et sur plusieurs distributions Linux. Étant donné que cette configuration n’est pas vraie haute disponibilité, ne l’utilisez pas pour les déploiements stratégiques. Utilisez-le plutôt pour des scénarios de mise à l’échelle en lecture ou de migration et de mise à niveau.
Copie des journaux de transaction
L'expédition des journaux est basée sur la sauvegarde et la restauration. Il n’existe donc aucune différence entre les bases de données, les structures de fichiers et d’autres éléments de SQL Server sur Windows Server et SQL Server sur Linux. Vous pouvez configurer l'expédition des journaux entre une installation de SQL Server basée sur Windows Server et une installation Linux, ainsi qu'entre les distributions Linux. Rien d’autre ne change.
Tout comme avec un groupe de disponibilité, l’expédition des journaux ne fonctionne pas lorsque le serveur source est à une version principale de SQL Server supérieure à celle de la cible, qui est à une version principale inférieure.
Résumé
Vous pouvez rendre des instances et des bases de données de SQL Server 2017 (14.x) et versions ultérieures hautement disponibles à l’aide des mêmes fonctionnalités sur Windows Server et Linux. Outre les scénarios de disponibilité standard de la haute disponibilité locale et de la récupération d’urgence, vous pouvez réduire les temps d’arrêt associés aux mises à niveau et aux migrations à l’aide des fonctionnalités de disponibilité dans SQL Server. Les groupes de disponibilité peuvent fournir des copies supplémentaires d’une base de données au sein de la même architecture pour permettre une mise à l'échelle horizontale des copies lisibles. Qu’il s’agisse de déployer une nouvelle solution ou d’effectuer une mise à niveau, SQL Server offre la disponibilité et la fiabilité dont vous avez besoin.