Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S’applique à :![]() SQL Server sur Linux
SQL Server sur Linux
Ce tutoriel montre comment créer et configurer un groupe de disponibilité (AG) pour SQL Server sur Linux. Contrairement à SQL Server 2016 (13.x) et les versions antérieures de Windows, vous pouvez activer un groupe de disponibilité avec ou sans créer d’abord le cluster Pacemaker sous-jacent. L’intégration au cluster, si nécessaire, se produit ultérieurement.
Le tutoriel inclut les tâches suivantes :
- Activer des groupes de disponibilité.
- Créer des points de terminaison de groupe de disponibilité et des certificats.
- Utiliser SQL Server Management Studio (SSMS) ou Transact-SQL pour créer un groupe de disponibilité.
- Créer la connexion SQL Server et les autorisations pour Pacemaker.
- Créer des ressources de groupe de disponibilité dans un cluster Pacemaker (type externe uniquement).
Prérequis
Déployez le cluster de haute disponibilité de Pacemaker comme décrit dans Déployer un cluster Pacemaker pour SQL Server sur Linux.
Activez la fonctionnalité Groupes de disponibilité
Vous ne pouvez pas utiliser PowerShell ou le Gestionnaire de configuration SQL Server pour activer la fonctionnalité Groupes de disponibilité comme sur Windows. Sur Linux, vous pouvez activer la fonctionnalité des groupes de disponibilité de deux façons : utiliser l’utilitaire mssql-conf ou modifier le mssql.conf fichier manuellement.
Important
Vous devez activer la fonctionnalité AG pour les réplicas à des fins de configuration seulement, même sur SQL Server Express.
Utilisez l’utilitaire mssql-conf
À une invite, exécutez la commande suivante :
sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
Modifiez le fichier mssql-conf
Vous pouvez également modifier le mssql.conf fichier, situé sous le /var/opt/mssql dossier. Ajoutez les lignes suivantes :
[hadr]
hadr.hadrenabled = 1
Redémarrez SQL Server
Après avoir activé des groupes de disponibilité, vous devez redémarrer SQL Server. Utilisez la commande suivante :
sudo systemctl restart mssql-server
Créez les points de terminaison du groupe de disponibilité et les certificats
Un groupe de disponibilité utilise des points de terminaison TCP pour la communication. Sous Linux, SQL Server prend en charge les points de terminaison réseau d’un groupe de disponibilité uniquement si vous utilisez des certificats pour l’authentification. Vous devez restaurer le certificat à partir d’une instance sur toutes les autres instances qui participent en tant que réplicas au sein du même groupe de disponibilité. Vous avez besoin du processus de certificat même pour une réplique uniquement de configuration.
Vous pouvez uniquement créer des points de terminaison et restaurer des certificats à l’aide de Transact-SQL. Vous pouvez également utiliser des certificats non générés par SQL Server. Vous avez également besoin d’un processus de gestion et de remplacement des certificats qui arrivent à expiration.
Important
Si vous envisagez d'utiliser l'assistant de SQL Server Management Studio pour créer le groupe de disponibilité, vous devez toujours utiliser Transact-SQL sur Linux pour créer et restaurer les certificats.
Pour obtenir une syntaxe complète sur les options disponibles pour les différentes commandes (y compris la sécurité), consultez :
Remarque
Bien que vous soyez en train de créer un groupe de disponibilité, le type de point de terminaison utilise FOR DATABASE_MIRRORING, car certains aspects sous-jacents ont préalablement été partagés avec cette fonctionnalité maintenant abandonnée.
Cet exemple crée des certificats pour une configuration à trois nœuds. Les noms d’instance sont LinAGN1, LinAGN2 et LinAGN3.
Exécutez le script suivant sur
LinAGN1pour créer la clé principale, le certificat et le point de terminaison, ainsi que pour sauvegarder le certificat. Pour cet exemple, le port TCP standard 5022 est utilisé pour le point de terminaison.CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; GO CREATE CERTIFICATE LinAGN1_Cert WITH SUBJECT = 'LinAGN1 AG Certificate'; GO BACKUP CERTIFICATE LinAGN1_Cert TO FILE = '/var/opt/mssql/data/LinAGN1_Cert.cer'; GO CREATE ENDPOINT AGEP STATE = STARTED AS TCP ( LISTENER_PORT = 5022, LISTENER_IP = ALL ) FOR DATABASE_MIRRORING ( AUTHENTICATION = CERTIFICATE LinAGN1_Cert, ROLE = ALL ); GOProcédez de la même façon sur
LinAGN2:CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; GO CREATE CERTIFICATE LinAGN2_Cert WITH SUBJECT = 'LinAGN2 AG Certificate'; GO BACKUP CERTIFICATE LinAGN2_Cert TO FILE = '/var/opt/mssql/data/LinAGN2_Cert.cer'; GO CREATE ENDPOINT AGEP STATE = STARTED AS TCP ( LISTENER_PORT = 5022, LISTENER_IP = ALL ) FOR DATABASE_MIRRORING ( AUTHENTICATION = CERTIFICATE LinAGN2_Cert, ROLE = ALL ); GOEnfin, exécutez la même séquence sur
LinAGN3:CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; GO CREATE CERTIFICATE LinAGN3_Cert WITH SUBJECT = 'LinAGN3 AG Certificate'; GO BACKUP CERTIFICATE LinAGN3_Cert TO FILE = '/var/opt/mssql/data/LinAGN3_Cert.cer'; GO CREATE ENDPOINT AGEP STATE = STARTED AS TCP ( LISTENER_PORT = 5022, LISTENER_IP = ALL ) FOR DATABASE_MIRRORING ( AUTHENTICATION = CERTIFICATE LinAGN3_Cert, ROLE = ALL ); GOÀ l’aide d’
scpou d’un autre utilitaire, copiez les sauvegardes du certificat sur chaque nœud pour qu'il fasse partie du groupe de disponibilité.Pour cet exemple :
- Copiez
LinAGN1_Cert.cerversLinAGN2etLinAGN3. - Copiez
LinAGN2_Cert.cerversLinAGN1etLinAGN3. - Copiez
LinAGN3_Cert.cerversLinAGN1etLinAGN2.
- Copiez
Modifiez la propriété et le groupe associé aux fichiers de certificat copiés sur
mssql.sudo chown mssql:mssql <CertFileName>Créez les connexions au niveau de l’instance et les utilisateurs associés à
LinAGN2etLinAGN3surLinAGN1.CREATE LOGIN LinAGN2_Login WITH PASSWORD = '<password>'; CREATE USER LinAGN2_User FOR LOGIN LinAGN2_Login; GO CREATE LOGIN LinAGN3_Login WITH PASSWORD = '<password>'; CREATE USER LinAGN3_User FOR LOGIN LinAGN3_Login; GOAttention
Votre mot de passe doit suivre la politique de mot de passe par défaut de SQL Server. Par défaut, le mot de passe doit avoir au moins huit caractères appartenant à trois des quatre groupes suivants : lettres majuscules, lettres minuscules, chiffres de base 10 et symboles. Les mots de passe peuvent comporter jusqu'à 128 caractères. Utilisez des mots de passe aussi longs et complexes que possible.
Restaurez
LinAGN2_CertetLinAGN3_CertsurLinAGN1. Le fait d'avoir les certificats des autres réplicats est un aspect important de la communication et de la sécurité de l'ensemble de disponibilité.CREATE CERTIFICATE LinAGN2_Cert AUTHORIZATION LinAGN2_User FROM FILE = '/var/opt/mssql/data/LinAGN2_Cert.cer'; GO CREATE CERTIFICATE LinAGN3_Cert AUTHORIZATION LinAGN3_User FROM FILE = '/var/opt/mssql/data/LinAGN3_Cert.cer'; GOAccordez aux connexions associées à
LinAGN2et àLinAGN3l’autorisation de se connecter au point de terminaison surLinAGN1.GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN2_Login; GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN3_Login;Créez les connexions au niveau de l’instance et les utilisateurs associés à
LinAGN1etLinAGN3surLinAGN2.CREATE LOGIN LinAGN1_Login WITH PASSWORD = '<password>'; CREATE USER LinAGN1_User FOR LOGIN LinAGN1_Login; GO CREATE LOGIN LinAGN3_Login WITH PASSWORD = '<password>'; CREATE USER LinAGN3_User FOR LOGIN LinAGN3_Login; GORestaurez
LinAGN1_CertetLinAGN3_CertsurLinAGN2.CREATE CERTIFICATE LinAGN1_Cert AUTHORIZATION LinAGN1_User FROM FILE = '/var/opt/mssql/data/LinAGN1_Cert.cer'; GO CREATE CERTIFICATE LinAGN3_Cert AUTHORIZATION LinAGN3_User FROM FILE = '/var/opt/mssql/data/LinAGN3_Cert.cer'; GOAccordez aux connexions associées à
LinAGN1et àLinAGN3l’autorisation de se connecter au point de terminaison surLinAGN2.GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN1_Login; GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN3_Login; GOCréez les connexions au niveau de l’instance et les utilisateurs associés à
LinAGN1etLinAGN2surLinAGN3.CREATE LOGIN LinAGN1_Login WITH PASSWORD = '<password>'; CREATE USER LinAGN1_User FOR LOGIN LinAGN1_Login; GO CREATE LOGIN LinAGN2_Login WITH PASSWORD = '<password>'; CREATE USER LinAGN2_User FOR LOGIN LinAGN2_Login; GORestaurez
LinAGN1_CertetLinAGN2_CertsurLinAGN3.CREATE CERTIFICATE LinAGN1_Cert AUTHORIZATION LinAGN1_User FROM FILE = '/var/opt/mssql/data/LinAGN1_Cert.cer'; GO CREATE CERTIFICATE LinAGN2_Cert AUTHORIZATION LinAGN2_User FROM FILE = '/var/opt/mssql/data/LinAGN2_Cert.cer'; GOAccordez aux connexions associées à
LinAG1et àLinAGN2l’autorisation de se connecter au point de terminaison surLinAGN3.GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN1_Login; GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN2_Login; GO
Créez le groupe de disponibilité
Cette section montre comment utiliser SQL Server Management Studio (SSMS) ou Transact-SQL pour créer le groupe de disponibilité pour SQL Server.
Utilisez SQL Server Management Studio.
Cette section montre comment créer un groupe de disponibilité avec un type de cluster "Externe" en utilisant SSMS grâce à l’Assistant Nouveau groupe de disponibilité.
Dans SSMS, étendez Always On High Availability, cliquez avec le bouton droit sur Groupes de disponibilité et sélectionnez Assistant Nouveau groupe de disponibilité.
Dans la boîte de dialogue Introduction, sélectionnez Suivant.
Dans la boîte de dialogue Spécifier les options du groupe de disponibilité, entrez un nom pour le groupe de disponibilité, puis sélectionnez un type de cluster parmi
EXTERNALouNONEdans la liste déroulante. UtilisezEXTERNALlorsque vous déployez Pacemaker. UtiliserNONEpour des scénarios spécialisés, tels que le scale-out en lecture. La sélection de l’option pour la détection d’intégrité au niveau de la base de données est facultative. Pour plus d’informations sur cette option, consultez l’option de basculement de détection de l’intégrité de la base de données au niveau du groupe de disponibilité. Cliquez sur Suivant.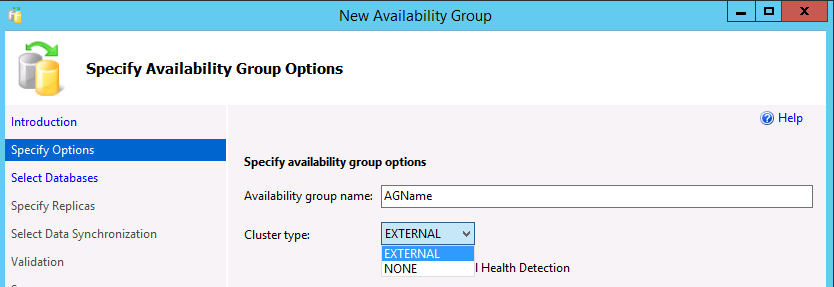
Dans la boîte de dialogue Sélectionner des bases de données, sélectionnez les bases de données que vous souhaitez inclure dans le groupe de disponibilité. Chaque base de données doit avoir une sauvegarde complète avant de pouvoir l’ajouter à un groupe de disponibilité (AG). Cliquez sur Suivant.
Dans la boîte de dialogue Spécifier les répliques, sélectionnez l’option Ajouter une réplique.
Dans la boîte de dialogue Se connecter au serveur, entrez le nom de l'instance Linux de SQL Server qui sera le réplica secondaire ainsi que les informations d’identification pour se connecter. Sélectionnez Connecter.
Répétez les deux étapes précédentes pour l'instance qui contiendra une réplique uniquement de configuration ou une autre réplique secondaire.
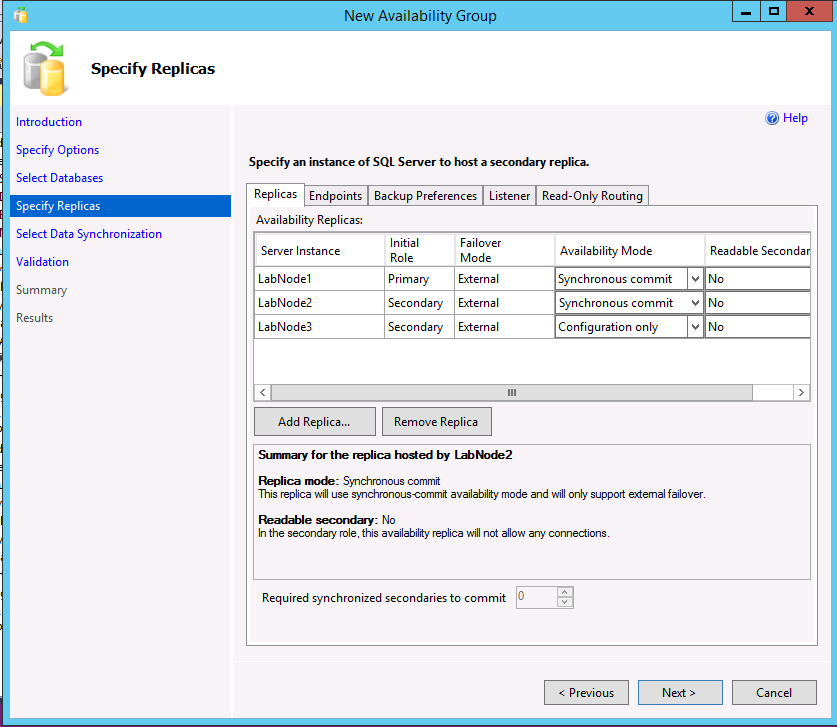
Les trois instances apparaissent dans la boîte de dialogue Définir les répliques. Si vous utilisez un type de cluster externe, pour le réplica secondaire véritable, vérifiez que le mode de disponibilité correspond à celui du réplica principal et que le mode de basculement est défini sur Externe. Pour le réplica de configuration uniquement, sélectionnez un mode de disponibilité de configuration uniquement.
L’exemple suivant montre un AG avec deux réplicas, un cluster de type externe et un réplica uniquement de configuration.
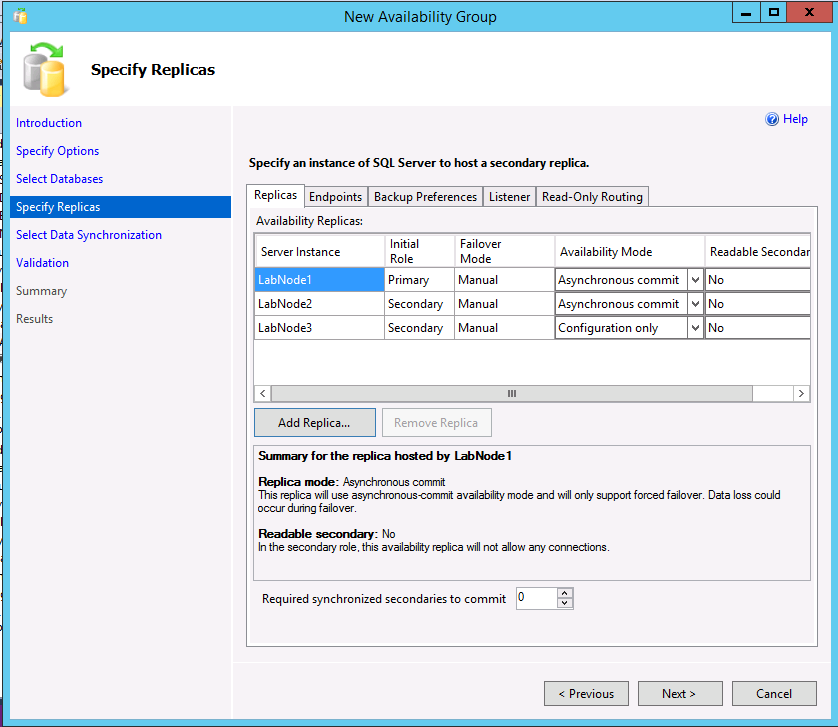
L’exemple suivant montre un groupe de disponibilité (AG) avec deux réplicas, aucun type de cluster, et un réplica réservé à la configuration uniquement.
Si vous souhaitez modifier les préférences de sauvegarde, sélectionnez l’onglet Préférences de sauvegarde. Pour plus d’informations sur les préférences de sauvegarde avec des groupes de disponibilité, consultez Configurer des sauvegardes sur des réplicas secondaires d’un groupe de disponibilité Always On.
Si vous utilisez des fichiers secondaires lisibles ou créez un groupe de disponibilité avec un type de cluster None pour la mise à l’échelle de lecture, vous pouvez créer un écouteur en sélectionnant l’onglet Écouteur . Vous pouvez également ajouter un écouteur ultérieurement. Pour créer un écouteur, choisissez l’option Créer un écouteur de groupe de disponibilité et entrez un nom, un port TCP/IP et indiquez s’il faut utiliser une adresse IP DHCP statique ou automatiquement affectée. Pour un groupe de disponibilité avec un type de cluster None, l’adresse IP doit être statique et définie sur l’adresse IP du serveur principal.
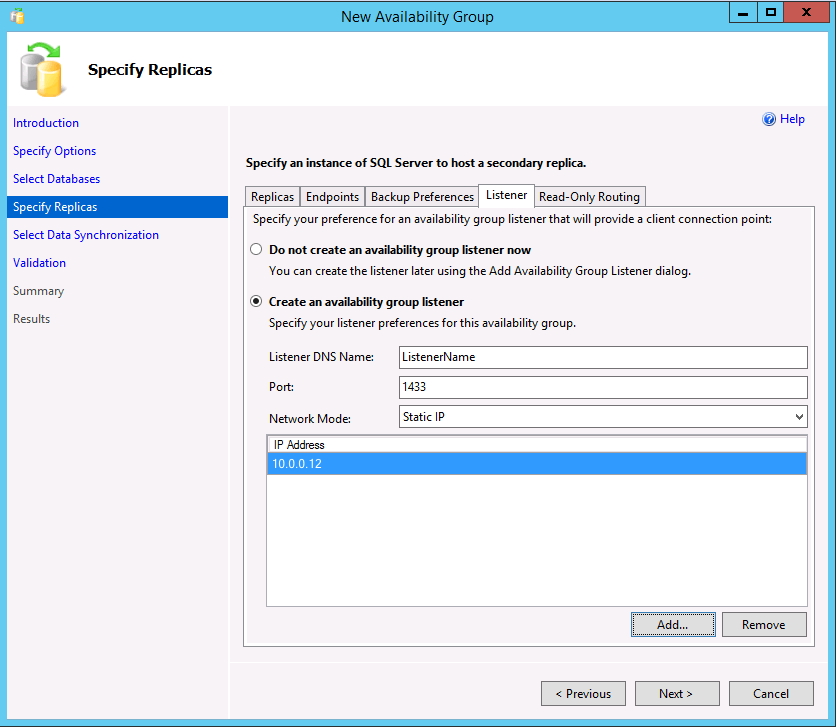
Si vous créez un listener pour des scénarios de lecture, SSMS permet de créer le routage en lecture seule dans l'assistant. Vous pouvez également l’ajouter ultérieurement via SSMS ou Transact-SQL. Pour activer le routage en lecture seule maintenant :
Sélectionnez l’onglet Routage en lecture seule.
Entrez les URLs des réplicas en lecture seule. Ces URL sont similaires aux points de terminaison, sauf qu’elles utilisent le port de l’instance et non le point de terminaison.
- Sélectionnez chaque URL et, au bas, choisissez les versions lisibles. Pour sélectionner plusieurs éléments, maintenez la touche Maj enfoncée ou faites glisser pour sélectionner.
Cliquez sur Suivant.
Sélectionnez la méthode pour initialiser les réplicas secondaires. La valeur par défaut est d'utiliser l'amorçage automatique, qui requiert le même chemin sur tous les serveurs participant au groupe de disponibilité. Vous pouvez également avoir l’Assistant effectuer une sauvegarde, une copie et une restauration (deuxième option); effectuer une jonction en cas de sauvegarde, copie et restauration manuelle de la base de données sur les réplicas (troisième option); ou ajouter la base de données ultérieurement (dernière option). Comme pour les certificats, si vous effectuez manuellement des sauvegardes et les copiez, définissez des autorisations sur les fichiers de sauvegarde sur les autres copies de sauvegarde. Cliquez sur Suivant.
Dans la boîte de dialogue Validation, si l’assistant d'installation ne retourne pas Réussite pour toutes les vérifications, procédez à une analyse plus approfondie. Certains avertissements sont acceptables et ne sont pas éliminatoires, par exemple si vous ne créez pas d’écouteur. Cliquez sur Suivant.
Sur la boîte de dialogue Résumé, sélectionnez Terminer. Le processus de création de l'AG commence.
Lorsque la création du groupe de disponibilité est terminée, sélectionnez Fermer dans les résultats. Vous pouvez maintenant voir le groupe de disponibilité (AG) sur les réplicas dans les vues de gestion dynamique, et dans le dossier Haute disponibilité Always On dans SSMS.




Utiliser Transact-SQL
Cette section présente des exemples de création d’un AG à l’aide de Transact-SQL. Vous pouvez configurer le listener et le routage en lecture seule après avoir créé le groupe de disponibilité. Vous pouvez modifier le groupe de disponibilité AG en utilisant ALTER AVAILABILITY GROUP, mais vous ne pouvez pas changer le type de cluster dans SQL Server 2017 (14.x). Si vous ne vouliez pas créer de groupe de disponibilité avec un type de cluster externe, vous devez le supprimer et le recréer avec un type de cluster « Aucun ». Pour plus d’informations et d’autres options, consultez les liens suivants :
- CRÉER UN GROUPE DE DISPONIBILITÉ (Transact-SQL)
- MODIFIER GROUPE DE DISPONIBILITÉ (Transact-SQL)
- Configurer le routage en lecture seule pour un groupe de disponibilité Always On
- Configurer un écouteur Always On pour un groupe de disponibilité
Exemple A : deux réplicas avec un réplica à configuration uniquement (type de cluster externe)
Cet exemple montre comment créer un AG à deux répliques qui utilise une réplique de configuration uniquement.
Exécutez l’instruction suivante sur le nœud qui joue le rôle de réplica principal et contient la copie complète en lecture/écriture des bases de données. Cet exemple utilise l’amorçage automatique.
CREATE AVAILABILITY GROUP [<AGName>] WITH (CLUSTER_TYPE = EXTERNAL) FOR DATABASE <DBName> REPLICA ON N'LinAGN1' WITH ( ENDPOINT_URL = N' TCP://LinAGN1.FullyQualified.Name:5022', FAILOVER_MODE = EXTERNAL, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT ), N'LinAGN2' WITH ( ENDPOINT_URL = N'TCP://LinAGN2.FullyQualified.Name:5022', FAILOVER_MODE = EXTERNAL, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC ), N'LinAGN3' WITH ( ENDPOINT_URL = N'TCP://LinAGN3.FullyQualified.Name:5022', AVAILABILITY_MODE = CONFIGURATION_ONLY ); GODans une fenêtre de requête connectée à l’autre réplica, exécutez l’instruction suivante pour joindre le réplica au groupe de disponibilité et lancer le processus d’amorçage du réplica principal vers le réplica secondaire.
ALTER AVAILABILITY GROUP [<AGName>] JOIN WITH (CLUSTER_TYPE = EXTERNAL); GO ALTER AVAILABILITY GROUP [<AGName>] GRANT CREATE ANY DATABASE; GODans une fenêtre de requête connectée uniquement au réplica de configuration, exécutez l’instruction suivante pour l'ajouter au groupe de disponibilité (AG).
ALTER AVAILABILITY GROUP [<AGName>] JOIN WITH (CLUSTER_TYPE = EXTERNAL); GO
Exemple B : trois répliques avec routage en lecture seule (type de cluster externe)
Cet exemple montre trois réplicas complets et comment configurer le routage en lecture seule dans le cadre de la création initiale du groupe de disponibilité (AG).
Exécutez l’instruction suivante sur le nœud qui joue le rôle de réplica principal et contient la copie complète en lecture/écriture des bases de données. Cet exemple utilise l’amorçage automatique.
CREATE AVAILABILITY GROUP [<AGName>] WITH (CLUSTER_TYPE = EXTERNAL) FOR DATABASE < DBName > REPLICA ON N'LinAGN1' WITH ( ENDPOINT_URL = N'TCP://LinAGN1.FullyQualified.Name:5022', FAILOVER_MODE = EXTERNAL, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, PRIMARY_ROLE(ALLOW_CONNECTIONS = READ_WRITE, READ_ONLY_ROUTING_LIST = ( ( 'LinAGN2.FullyQualified.Name', 'LinAGN3.FullyQualified.Name' ) )), SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL, READ_ONLY_ROUTING_URL = N'TCP://LinAGN1.FullyQualified.Name:1433') ), N'LinAGN2' WITH ( ENDPOINT_URL = N'TCP://LinAGN2.FullyQualified.Name:5022', FAILOVER_MODE = EXTERNAL, SEEDING_MODE = AUTOMATIC, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, PRIMARY_ROLE(ALLOW_CONNECTIONS = READ_WRITE, READ_ONLY_ROUTING_LIST = ( ( 'LinAGN1.FullyQualified.Name', 'LinAGN3.FullyQualified.Name' ) )), SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL, READ_ONLY_ROUTING_URL = N'TCP://LinAGN2.FullyQualified.Name:1433') ), N'LinAGN3' WITH ( ENDPOINT_URL = N'TCP://LinAGN3.FullyQualified.Name:5022', FAILOVER_MODE = EXTERNAL, SEEDING_MODE = AUTOMATIC, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, PRIMARY_ROLE(ALLOW_CONNECTIONS = READ_WRITE, READ_ONLY_ROUTING_LIST = ( ( 'LinAGN1.FullyQualified.Name', 'LinAGN2.FullyQualified.Name' ) )), SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL, READ_ONLY_ROUTING_URL = N'TCP://LinAGN3.FullyQualified.Name:1433') ) LISTENER '<ListenerName>' ( WITH IP = ('<IPAddress>', '<SubnetMask>'), Port = 1433 ); GOVoici quelques points à noter concernant cette configuration :
-
AGNameest le nom de l'AG. -
DBNameest le nom de la base de données que vous utilisez avec le groupe de disponibilité. Il peut également s’agir d’une liste de noms séparés par des virgules. -
ListenerNameest un nom différent de l’un des serveurs ou nœuds sous-jacents. Il est inscrit dans DNS avecIPAddress. -
IPAddressest une adresse IP associée àListenerName. Il est également unique et non identique à l’un des serveurs ou nœuds. Les applications et les utilisateurs finaux utilisent soitListenerName, soitIPAddresspour se connecter au AG.-
SubnetMaskest le masque de sous-réseau deIPAddress. Dans SQL Server 2019 (15.x) et les versions précédentes, cette valeur est255.255.255.255. Dans SQL Server 2022 (16.x) et versions ultérieures, cette valeur est0.0.0.0.
-
-
Dans une fenêtre de requête connectée à l’autre réplica, exécutez l’instruction suivante pour joindre le réplica au groupe de disponibilité et lancer le processus d’amorçage du réplica principal vers le réplica secondaire.
ALTER AVAILABILITY GROUP [<AGName>] JOIN WITH (CLUSTER_TYPE = EXTERNAL); GO ALTER AVAILABILITY GROUP [<AGName>] GRANT CREATE ANY DATABASE; GORépétez l’étape 2 pour le troisième réplica.
Exemple C : deux réplicas avec routage en lecture seule (type de cluster « None »)
Cet exemple illustre la création d’une configuration à deux réplicas à l’aide d’un type de cluster None. Utilisez cette configuration pour le scénario à l’échelle en lecture où aucun basculement n’est attendu. Cette étape crée l'écouteur qui est effectivement la réplique principale et met en œuvre le routage en lecture seule, en utilisant la fonctionnalité round robin.
Exécutez l’instruction suivante sur le nœud qui joue le rôle de réplica principal et contient la copie complète en lecture/écriture des bases de données. Cet exemple utilise l’amorçage automatique.
CREATE AVAILABILITY GROUP [<AGName>] WITH (CLUSTER_TYPE = NONE) FOR DATABASE <DBName> REPLICA ON N'LinAGN1' WITH ( ENDPOINT_URL = N'TCP://LinAGN1.FullyQualified.Name: <PortOfEndpoint>', FAILOVER_MODE = MANUAL, AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, PRIMARY_ROLE( ALLOW_CONNECTIONS = READ_WRITE, READ_ONLY_ROUTING_LIST = (('LinAGN1.FullyQualified.Name'.'LinAGN2.FullyQualified.Name')) ), SECONDARY_ROLE( ALLOW_CONNECTIONS = ALL, READ_ONLY_ROUTING_URL = N'TCP://LinAGN1.FullyQualified.Name:<PortOfInstance>' ) ), N'LinAGN2' WITH ( ENDPOINT_URL = N'TCP://LinAGN2.FullyQualified.Name:<PortOfEndpoint>', FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC, AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, PRIMARY_ROLE(ALLOW_CONNECTIONS = READ_WRITE, READ_ONLY_ROUTING_LIST = ( ('LinAGN1.FullyQualified.Name', 'LinAGN2.FullyQualified.Name') )), SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL, READ_ONLY_ROUTING_URL = N'TCP://LinAGN2.FullyQualified.Name:<PortOfInstance>') ), LISTENER '<ListenerName>' (WITH IP = ( '<PrimaryReplicaIPAddress>', '<SubnetMask>'), Port = <PortOfListener> ); GODans cet exemple :
-
AGNameest le nom de l'AG. -
DBNameest le nom de la base de données que vous utilisez avec le groupe de disponibilité. Il peut également s’agir d’une liste de noms séparés par des virgules. -
PortOfEndpointest le numéro de port utilisé par le point de terminaison que vous créez.-
PortOfInstanceest le numéro de port utilisé par l’instance de SQL Server.
-
-
ListenerNameest un nom différent de l’un des réplicas sous-jacents, mais qui n'est en réalité pas utilisé. -
PrimaryReplicaIPAddressest l’adresse IP du réplica principal.-
SubnetMaskest le masque de sous-réseau deIPAddress. Dans SQL Server 2019 (15.x) et les versions précédentes, cette valeur est255.255.255.255. Dans SQL Server 2022 (16.x) et versions ultérieures, cette valeur est0.0.0.0.
-
-
Ajoutez la réplique secondaire au groupe de disponibilité et démarrez l’amorçage automatique.
ALTER AVAILABILITY GROUP [<AGName>] JOIN WITH (CLUSTER_TYPE = NONE); GO ALTER AVAILABILITY GROUP [<AGName>] GRANT CREATE ANY DATABASE; GO
Créer la connexion SQL Server et les autorisations pour Pacemaker
Un cluster Pacemaker à haute disponibilité qui utilise SQL Server sur Linux a besoin d’accéder à l’instance SQL Server ainsi que des autorisations sur le groupe de disponibilité en lui-même. Ces étapes créent la connexion et les autorisations associées, ainsi qu’un fichier qui indique à Pacemaker comment s’authentifier auprès de SQL Server.
Dans une fenêtre de requête connectée à la première réplique, exécutez le script suivant :
CREATE LOGIN PMLogin WITH PASSWORD = '<password>'; GO GRANT VIEW SERVER STATE TO PMLogin; GO GRANT ALTER, CONTROL, VIEW DEFINITION ON AVAILABILITY GROUP::<AGThatWasCreated> TO PMLogin; GOSur le nœud 1, entrez la commande :
sudo emacs /var/opt/mssql/secrets/passwdCette commande ouvre l’éditeur Emacs.
Dans l’éditeur, entrez les deux lignes suivantes :
PMLogin <password>Maintenez la touche
Ctrlenfoncée et appuyez surX, puis surC, pour quitter et enregistrer le fichier.Exécutez :
sudo chmod 400 /var/opt/mssql/secrets/passwdpour verrouiller le fichier.
Répétez les étapes 1 à 5 sur les autres serveurs qui servent de réplicas.
Créer les ressources de groupe de disponibilité dans le cluster Pacemaker (externe uniquement)
Après avoir créé un AG (groupe de disponibilité) dans SQL Server, vous devez créer les ressources correspondantes dans Pacemaker lorsque vous spécifiez un type de cluster Externe. Un groupe de disponibilité a besoin de deux ressources : la ressource du groupe de disponibilité et une ressource d’adresse IP. La configuration de la ressource d’adresse IP est facultative si vous n’utilisez pas d’écouteur. Toutefois, il est recommandé lorsque vous avez besoin de fonctionnalités d’écouteur.
La ressource AG que vous créez est un type de ressource appelé clone. La ressource AG a des copies sur chaque nœud et une ressource de contrôle appelée maître. Le serveur maître est associé au serveur hébergeant le réplica principal. Les autres ressources hébergent des réplicas secondaires (standard ou configuration uniquement) et peuvent être promus en principal lors d'un basculement.
Remarque
Dans SQL Server 2025 (17.x) avec mise à jour cumulative (CU) 3 et versions ultérieures, l’agent de haute disponibilité Pacemaker v2 (préversion) est disponible pour Red Hat Enterprise Linux (RHEL) et Ubuntu via le mssql-server-ha package. Les déploiements hors production peuvent évaluer l’agent de haute disponibilité Pacemaker v2. L’agent de haute disponibilité Pacemaker existant (v1) reste entièrement pris en charge pour les déploiements en production. Pour plus d’informations, consultez Pacemaker HA Agent v2 (préversion).
Agent de haute disponibilité Pacemaker v1
Créez la ressource AG dans le Pacemaker à l’aide de l’agent Haute Disponibilité Pacemaker (v1) : (
ocf:mssql:ag)sudo pcs resource create <NameForAGResource> ocf:mssql:ag ag_name=<AGName> meta failure-timeout=30s promotable notify=trueDans cet exemple,
NameForAGResourceest le nom unique que vous attribuez à cette ressource de cluster pour le groupe de disponibilité etAGNameest le nom du groupe de disponibilité que vous avez créé.Créez la ressource d'adresse IP pour la passerelle d'application que vous associez à la fonctionnalité d'écoute.
sudo pcs resource create <NameForIPResource> ocf:heartbeat:IPaddr2 ip=<IPAddress> cidr_netmask=<Netmask>Dans cet exemple,
NameForIPResourceil s’agit du nom unique de la ressource IP etIPAddressde l’adresse IP statique que vous affectez à la ressource.Pour vous assurer que l’adresse IP et la ressource AG s’exécutent sur le même nœud, configurez une contrainte de colocalisation.
sudo pcs constraint colocation add <NameForIPResource> with promoted <NameForAGResource>-clone INFINITYDans cet exemple,
NameForIPResourceil s’agit du nom de la ressource IP etNameForAGResourcedu nom de la ressource de groupe de disponibilité.Créez une contrainte d'ordre pour vous assurer que la ressource de groupe de disponibilité est opérationnelle avant l'adresse IP. Bien que la contrainte de colocation implique une contrainte d'ordonnancement, cette étape la renforce.
sudo pcs constraint order promote <NameForAGResource>-clone then start <NameForIPResource>Dans cet exemple,
NameForIPResourceil s’agit du nom de la ressource IP etNameForAGResourcedu nom de la ressource de groupe de disponibilité.
Pacemaker HA Agent v2 (préversion)
L’agent haute disponibilité Pacemaker v2 utilise une architecture basée sur le service. L’agent s’exécute en tant que service système dédié nommé mssql-pcsag, qui est chargé de gérer les opérations de haute disponibilité spécifiques à SQL Server et la communication avec Pacemaker.
Le mssql-pcsag service est géré à l’aide de contrôles de service système standard. Vous pouvez démarrer, arrêter, redémarrer et vérifier l’état de ce service en fonction des besoins à l’aide des commandes suivantes :
sudo systemctl start mssql-pcsag # Start the Pacemaker HA agent v2 (mssql-pcsag) service
sudo systemctl stop mssql-pcsag # Stop the Pacemaker HA agent v2 (mssql-pcsag) service
sudo systemctl restart mssql-pcsag # Restart the Pacemaker HA agent v2 (mssql-pcsag) service
sudo systemctl status mssql-pcsag # Check the status of the Pacemaker HA agent v2 (mssql-pcsag) service
Pacemaker interagit avec les groupes de disponibilité SQL Server via le mssql-pcsag service. Pour que la surveillance et le basculement des groupes de disponibilité se fassent correctement :
- Le cluster Pacemaker doit être en cours d’exécution.
- Le
mssql-pcsagservice doit être en cours d’exécution.
Alors que Pacemaker et mssql-pcsag sont déployés en tant que composants distincts, ils fonctionnent ensemble au moment de l’exécution. Si Pacemaker ou le service mssql-pcsag est arrêté, les opérations de basculement du groupe de disponibilité ne fonctionnent pas comme prévu.
Remarque
Le redémarrage du mssql-pcsag service ne redémarre pas SQL Server. De même, le redémarrage de SQL Server ne redémarre pas automatiquement l’agent de haute disponibilité Pacemaker. Vérifiez que les deux services s’exécutent pendant la résolution des problèmes.
L’agent haute disponibilité Pacemaker v2 introduit des améliorations de fiabilité et de performances sur l’agent précédent, notamment :
Amélioration des performances de basculement pour réduire les temps de basculement, qu'ils soient prévus ou imprévus.
Prise en charge des stratégies de basculement automatique flexibles, notamment la configuration du niveau de condition d’échec et du délai d’expiration du contrôle de l’intégrité.
Exemple : l’instruction Transact-SQL suivante modifie le niveau de condition d’échec d’un groupe de disponibilité existant nommé AG1 au niveau 2 :
ALTER AVAILABILITY GROUP AG1 SET (FAILURE_CONDITION_LEVEL = 2);Exemple : l’instruction Transact-SQL suivante modifie le seuil de délai d’expiration du contrôle d’intégrité d’un groupe de disponibilité existant nommé AG1 à 60 000 millisecondes (60 secondes).
ALTER AVAILABILITY GROUP AG1 SET (HEALTH_CHECK_TIMEOUT = 60000);Exemple : après avoir appliqué la configuration, utilisez l’instruction Transact-SQL suivante pour vérifier le niveau de condition d’échec configuré et le délai d’expiration du contrôle d’intégrité pour les groupes de disponibilité.
SELECT failure_condition_level, health_check_timeout FROM sys.availability_groups;Prise en charge de TLS 1.3 pour la communication entre le cluster Pacemaker et SQL Server.
Créez la ressource AG dans Pacemaker à l'aide de l'agent Pacemaker HA v2 : (
ocf:mssql:agv2)sudo pcs resource create <NameForAGResource> ocf:mssql:agv2 ag_name=<AGName> meta failure-timeout=30s promotable notify=trueSi vous effectuez une mise à niveau de l’agent HA Pacemaker v1 vers v2, supprimez la ressource AG existante avant de créer la ressource
agv2.sudo pcs resource delete <NameForAGResource>Cette opération interrompt temporairement la synchronisation du groupe de disponibilité pendant que la ressource est recréée. La suppression et la recréation de la ressource Pacemaker AG ne suppriment pas l'AG. Une fois la ressource recréée, Pacemaker reprend automatiquement la gestion et la synchronisation du groupe de disponibilité (AG).
Créez la ressource d'adresse IP pour la passerelle d'application que vous associez à la fonctionnalité d'écoute.
sudo pcs resource create <NameForIPResource> ocf:heartbeat:IPaddr2 ip=<IPAddress> cidr_netmask=<Netmask>Dans cet exemple,
NameForIPResourceil s’agit du nom unique de la ressource IP etIPAddressde l’adresse IP statique que vous affectez à la ressource.Pour vous assurer que l’adresse IP et la ressource AG s’exécutent sur le même nœud, configurez une contrainte de colocalisation.
sudo pcs constraint colocation add <NameForIPResource> with promoted <NameForAGResource>-clone INFINITYDans cet exemple,
NameForIPResourceil s’agit du nom de la ressource IP etNameForAGResourcedu nom de la ressource de groupe de disponibilité.Créez une contrainte d'ordre pour vous assurer que la ressource de groupe de disponibilité est opérationnelle avant l'adresse IP. Bien que la contrainte de colocation implique une contrainte d'ordonnancement, cette étape la renforce.
sudo pcs constraint order promote <NameForAGResource>-clone then start <NameForIPResource>Dans cet exemple,
NameForIPResourceil s’agit du nom de la ressource IP etNameForAGResourcedu nom de la ressource de groupe de disponibilité.