Réglage automatique
S’applique à :![]() SQL Server 2017 (14.x) et versions ultérieures
SQL Server 2017 (14.x) et versions ultérieures ![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance
L’optimisation automatique est une fonctionnalité de base de données qui fournit des insights sur les éventuels problèmes de performances des requêtes, recommande des solutions et corrige automatiquement les problèmes identifiés.
Le réglage automatique, introduit dans SQL Server 2017 (14.x), vous avertit chaque fois qu’un problème potentiel de niveau de performance est détecté et vous permet d’appliquer des actions correctives ou de laisser le Moteur de base de données résoudre automatiquement les problèmes de niveau de performance. Le réglage automatique de SQL Server identifie et résout les problèmes de performances causés par les régressions de choix de plan d’exécution de requête. Le réglage automatique dans Azure SQL Database crée également des index nécessaires et annule des index inutilisés. Pour plus d’informations sur les plans d’exécution de requête, consultez Plans d’exécution.
Le Moteur de base de données SQL Server analyse les requêtes exécutées sur la base de données et améliore automatiquement le niveau de performance de la charge de travail. Le Moteur de base de données dispose d’un mécanisme d’intelligence intégré qui peut automatiquement régler et améliorer le niveau de performance de vos requêtes en adaptant de manière dynamique la base de données à votre charge de travail. Deux fonctionnalités de réglage automatique sont disponibles :
La correction automatique du plan identifie les plans d’exécution de requête problématiques, tels qu’une sensibilité des paramètres ou des problèmes de détection de paramètre et corrige les problèmes de niveau de performance liés au plan d’exécution de requête en forçant le dernier bon plan connu avant la régression. S’applique à : SQL Server (à partir de SQL Server 2017 (14.x)) et Azure SQL Database et Azure SQL Managed Instance]
La gestion automatique des index identifie les index qui doivent être ajoutés à votre base de données et ceux qui doivent être supprimés. S’applique à : Azure SQL Database
À quoi sert le réglage automatique ?
Trois des principales tâches de l’administration des bases de données classiques analysent la charge de travail, identifient les requêtes Transact-SQL critiques et identifient les index qui doivent être ajoutés ou les index rarement utilisés et qui peuvent être supprimés pour améliorer le niveau de performance. Le Moteur de base de données SQL Server fournit des insights détaillés sur les requêtes et les index que vous devez analyser. Toutefois, la surveillance permanente d’une base de données est une tâche difficile et fastidieuse, en particulier lors du traitement de plusieurs bases de données. La gestion d’un nombre important de bases de données est impossible efficacement. Au lieu d’analyser et de régler votre base de données manuellement, vous pouvez envisager de déléguer certaines actions d’analyse et de réglage au Moteur de base de données grâce à la fonctionnalité de réglage automatique.
Comment fonctionne le réglage automatique ?
Le réglage automatique est un processus d’analyse en continu, qui en apprend sans cesse davantage sur les caractéristiques de votre charge de travail et identifie des problèmes et améliorations potentiels.
Ce processus permet à la base de données de s’adapter de manière dynamique à votre charge de travail en recherchant les plans et les index qui peuvent améliorer le niveau de performance de vos charges de travail et les index qui affectent vos charges de travail. En fonction de ces résultats, le réglage automatique effectue des actions de réglage qui améliorent le niveau de performance de votre charge de travail. En outre, le réglage automatique analyse en permanence le niveau de performance de la base de données après avoir implémenté toutes les modifications pour s’assurer qu’elle améliore le niveau de performance de votre charge de travail. Toute action qui n’a pas amélioré le niveau de performance est automatiquement annulée. Ce processus de vérification est une fonctionnalité clé qui permet de s’assurer que les modifications apportées par le réglage automatique ne diminuent pas le niveau de performance de votre charge de travail.
Correction de plan automatique
La correction automatique du plan est une fonctionnalité de réglage automatique qui identifie la régression du choix du plan d’exécution et corrige automatiquement le problème en appliquant le dernier bon plan connu. Pour plus d’informations sur l’interrogation des plans d’exécution de requête et l’Optimiseur de requête, consultez le Guide d’architecture de traitement des requêtes.
Important
La correction automatique du plan dépend du Magasin des requêtes activé dans la base de données pour le suivi des charges de travail.
Qu’est-ce que la régression de choix du plan d’exécution ?
Le Moteur de base de données SQL Server peut utiliser des plans d’exécution différents pour exécuter les requêtes Transact-SQL. Les plans de requête dépendent des statistiques, des index et d’autres facteurs. Le plan optimal qui doit être utilisé pour exécuter une requête Transact-SQL peut changer au fil du temps en fonction des modifications apportées à ces facteurs. Dans certains cas, le nouveau plan peut ne pas être meilleur que le précédent et il peut entraîner une régression du niveau de performance, telle qu’une sensibilité de paramètre ou un problème lié de détection de paramètre.
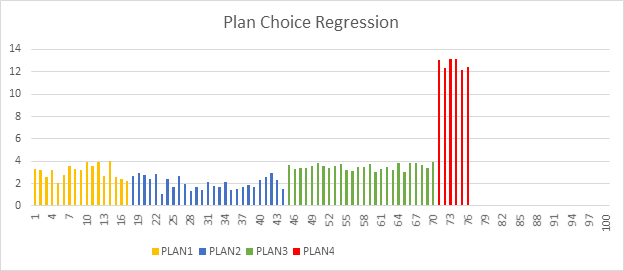
Chaque fois que vous remarquez qu’une régression de choix de plan s’est produite, vous devez trouver un bon plan précédent et appliquer son utilisation au lieu du plan actuel. Cela est possible à l’aide de la procédure sp_query_store_force_plan. Le Moteur de base de données dans SQL Server 2017 (14.x) fournit des informations sur les plans régressés et les actions correctives recommandées. En outre, le Moteur de base de données vous permet d’automatiser entièrement ce processus et permet au Moteur de base de données de résoudre tout problème lié au changement de plan.
Important
La correction automatique du plan doit être utilisée dans l’étendue d’une mise à niveau de compatibilité de la base de données, une fois qu’une ligne de base a été capturée, pour atténuer automatiquement les risques de mise à niveau de la charge de travail. Pour plus d’informations à ce sujet, consultez Maintenir la stabilité du niveau de performance lors de la mise à niveau vers une version plus récente de SQL Server.
Correction automatique du choix de plan
Le Moteur de base de données peut automatiquement basculer vers le dernier bon plan connu dès qu’il détecte une régression de choix de plan.
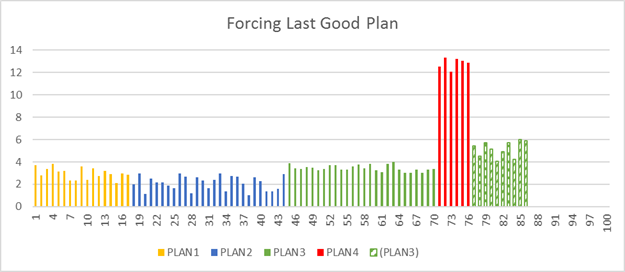
Le Moteur de base de données détecte automatiquement une régression de choix de plan potentielle, notamment le plan à utiliser à la place du plan inapproprié. Le plan d’exécution résultant forcé par la correction automatique du plan sera identique ou similaire au dernier bon plan connu. Étant donné que le plan obtenu ne peut pas être identique au dernier bon plan connu, le niveau de performance du plan forcé peut varier. Dans de rares cas, la différence de niveau de performance peut être significative et négative ; dans ce cas, la correction automatique du plan arrête automatiquement de tenter de forcer le plan de remplacement.
Quand le Moteur de base de données applique le dernier bon plan connu, il analyse automatiquement le niveau de performance du plan forcé. Si le plan forcé n’est pas meilleur que le plan régressé, l’obligation d’utiliser le nouveau plan est annulée et le Moteur de base de données compile un nouveau plan. Si le Moteur de base de données vérifie que le plan forcé est meilleur que le plan régressé, le plan forcé sera conservé. Il sera conservé jusqu’à ce qu’une recompilation se produise (par exemple, lors de la prochaine mise à jour des statistiques ou du changement de schéma). Pour plus d’informations sur le forçage de plan et les types de plans qui peuvent être forcés, consultez Limitations de contrainte de plan.
Note
Si l’instance SQL est redémarrée avant qu’une action forcée de plan soit vérifiée, ce plan sera automatiquement non appliqué. Dans le cas contraire, le forçage du plan est conservé sur les redémarrages de SQL Server.
Activer la correction automatique du choix de plan
Vous pouvez activer le réglage automatique pour chaque base de données et spécifier que le dernier bon plan connu doit être forcé quand une régression de changement de plan est détectée. Pour cela, utilisez la commande suivante :
ALTER DATABASE <yourDatabase>
SET AUTOMATIC_TUNING ( FORCE_LAST_GOOD_PLAN = ON );
Une fois que vous avez activé cette option, le Moteur de base de données force automatiquement les recommandations applicables si le gain d’UC estimé est supérieur à 10 secondes ou si le nombre d’erreurs dans le nouveau plan est supérieur au nombre d’erreurs dans le plan recommandé et vérifie que le plan forcé est préférable au plan actuel.
Pour activer le réglage automatique dans Azure SQL Database et Azure SQL Managed Instance, consultez Activer le réglage automatique dans Azure SQL Database à l’aide du portail Azure.
Autre possibilité : la correction manuelle du choix de plan
Quand le réglage automatique n’est pas activé, les utilisateurs doivent régulièrement analyser le système et rechercher les requêtes régressées. Si un plan a régressé, l’utilisateur doit trouver un bon plan précédent et l’appliquer au lieu de celui en cours à l’aide de la procédure sp_query_store_force_plan. La meilleure pratique consisterait à appliquer le dernier bon plan connu, car les plans plus anciens peuvent ne pas être valides en raison des statistiques ou des changements d’index. L’utilisateur qui applique le dernier bon plan connu doit analyser le niveau de performance de la requête exécutée à l’aide du plan forcé et vérifier que le plan forcé fonctionne comme prévu. Selon les résultats de l’analyse, le plan doit être forcé ou l’utilisateur doit trouver un autre moyen d’optimiser la requête, comme la réécriture. Les plans forcés manuellement ne doivent pas être forcés pour toujours, car le Moteur de base de données doit être en mesure d’appliquer des plans optimaux. L’utilisateur ou l’administrateur de base de données doit éventuellement annuler le plan à l’aide de la procédure sp_query_store_unforce_plan et laisser le Moteur de base de données trouver le plan optimal.
Astuce
Vous pouvez également utiliser l’affichage du Magasin des requêtes Requêtes avec plans forcés pour localiser et annuler l’application des plans.
SQL Server fournit tous les affichages et procédures nécessaires pour analyser le niveau de performance et résoudre les problèmes dans le Magasin des requêtes.
Dans SQL Server 2016 (13.x), vous pouvez trouver des régressions de choix de plan à l’aide d’affichages système Magasin des requêtes. À compter de SQL Server 2017 (14.x), le Moteur de base de données détecte et affiche les régressions de choix de plan potentielles et les actions recommandées qui doivent être appliquées dans le DMV sys.dm_db_tuning_recommendations (Transact-SQL). La DMV affiche des informations sur le problème, l’importance du problème et les détails tels que la requête identifiée, l’ID du plan régressé, l’ID du plan utilisé comme ligne de base pour la comparaison et l’instruction Transact-SQL qui peut être exécutée pour résoudre le problème.
| type | description | DateHeure | score | details | ... |
|---|---|---|---|---|---|
FORCE_LAST_GOOD_PLAN |
Temps processeur passé de 4 m à 14 m | 17/03/2017 | 83 | queryId recommendedPlanId regressedPlanId T-SQL |
|
FORCE_LAST_GOOD_PLAN |
Temps processeur passé de 37 m à 84 m | 3/16/2017 | 26 | queryId recommendedPlanId regressedPlanId T-SQL |
Certaines colonnes de cet affichage sont décrites dans la liste suivante :
- Type d'action recommandée
FORCE_LAST_GOOD_PLAN. - Description qui contient des informations sur la raison pour laquelle le Moteur de base de données pense que ce changement de plan est une régression potentielle du niveau de performance.
- DateHeure lorsque la régression potentielle est détectée.
- Score de cette recommandation.
- Détails sur les problèmes tels que l’ID du plan détecté, l’ID du plan régressé, l’ID du plan qui doit être forcé de résoudre le problème, le script Transact-SQL qui peut être appliqué pour résoudre le problème, etc. Les détails sont stockés au format JSON.
Utilisez la requête suivante pour obtenir un script qui résout le problème et des informations supplémentaires sur le gain estimé :
SELECT reason, score,
script = JSON_VALUE(details, '$.implementationDetails.script'),
planForceDetails.*,
estimated_gain = (regressedPlanExecutionCount + recommendedPlanExecutionCount)
* (regressedPlanCpuTimeAverage - recommendedPlanCpuTimeAverage)/1000000,
error_prone = IIF(regressedPlanErrorCount > recommendedPlanErrorCount, 'YES','NO')
FROM sys.dm_db_tuning_recommendations
CROSS APPLY OPENJSON (Details, '$.planForceDetails')
WITH ( [query_id] int '$.queryId',
regressedPlanId int '$.regressedPlanId',
recommendedPlanId int '$.recommendedPlanId',
regressedPlanErrorCount int,
recommendedPlanErrorCount int,
regressedPlanExecutionCount int,
regressedPlanCpuTimeAverage float,
recommendedPlanExecutionCount int,
recommendedPlanCpuTimeAverage float
) AS planForceDetails;
Voici le jeu de résultats obtenu.
| reason | score | script | query_id | current plan_id | recommended plan_id | estimated_gain | error_prone |
|---|---|---|---|---|---|---|---|
| Temps processeur passé de 3 m à 46 m | 36 | EXEC sp_query_store_force_plan 12, 17; | 12 | 28 | 17 | 11,59 | 0 |
La colonne estimated_gain représente le nombre estimé de secondes enregistrées si le plan recommandé était utilisé pour l’exécution de requêtes au lieu du plan actuel. Le plan recommandé doit être appliqué au lieu du plan actuel si le gain est supérieur à 10 secondes. S’il existe plus d’erreurs (par exemple, des délais d’attente ou des exécutions abandonnées) dans le plan actuel que dans le plan recommandé, la colonne error_prone est définie sur la valeur YES. Un plan sujet aux erreurs est une autre raison pour laquelle le plan recommandé doit être appliqué au lieu du plan actuel.
Bien que le Moteur de base de données fournisse toutes les informations nécessaires pour identifier les régressions de choix de plan, l’analyse continue et la résolution des problèmes de niveau de performance peuvent devenir un processus fastidieux. Le réglage automatique facilite beaucoup ce processus.
Note
Les données de la DMV sys.dm_db_tuning_recommendations ne sont pas conservées après un redémarrage du moteur de base de données. Utilisez la colonne sqlserver_start_time dans sys.dm_os_sys_info pour rechercher la dernière heure de démarrage du moteur de base de données.
Gestion automatique des index
Dans Azure SQL Database, la gestion des index est facile, car Azure SQL Database s’informe sur votre charge de travail et s’assure que vos données sont toujours indexées de manière optimale. Pour assurer des performances optimales de votre charge de travail, l’index doit être correctement conçu. La gestion automatique des index peut vous aider à les optimiser. La gestion automatique des index permet de résoudre les problèmes de performances dans les bases de données indexées de manière incorrecte, ou de conserver et d’améliorer les index dans la structure de base de données existante. Le réglage automatique dans Azure SQL Database effectue les actions suivantes :
- Identifie les index qui peuvent améliorer le niveau de performance de vos requêtes Transact-SQL qui lisent les données des tables.
- Identifie les index redondants ou les index qui n’ont pas été utilisés pendant plus de temps et qui peuvent être supprimés. La suppression d’index inutiles améliore le niveau de performance des requêtes qui mettent à jour les données dans les tables.
Pourquoi utiliser la gestion des index ?
Les index accélèrent certaines de vos requêtes qui lisent les données à partir des tables ; cependant, ils peuvent ralentir les requêtes qui mettent à jour les données. Vous devez analyser soigneusement quand créer un index et les colonnes que vous devez inclure dans l’index. Certains index peuvent ne plus être nécessaires après un certain temps. Par conséquent, vous devez régulièrement identifier et annuler les index qui n’apportent aucun avantage. Si vous ignorez les index non utilisés, le niveau de performance des requêtes qui mettent à jour les données diminue sans aucun avantage pour les requêtes qui lisent les données. Les index inutilisés affectent également les performances globales du système, car les mises à jour supplémentaires impliquent une journalisation inutile.
Pour trouver l’ensemble optimal d’index qui améliore les performances des requêtes qui lisent les données de vos tables et ont un impact minimal sur les mises à jour, vous aurez peut-être besoin d’une analyse continue complexe.
Azure SQL Database utilise l’intelligence intégrée et des règles avancées pour analyser vos requêtes, identifier les index qui seraient optimaux pour vos charges de travail actuelles et les index qui peuvent être supprimés. Azure SQL Database permet de s’assurer que vous disposez de l’ensemble d’index minimal nécessaire à l’optimisation des requêtes qui lisent les données, avec un impact réduit sur les autres requêtes.
Gestion automatique des index
En plus de la détection, Azure SQL Database peut appliquer automatiquement des suggestions identifiées. Si vous constatez que les règles intégrées améliorent le niveau de performance de votre base de données, vous pouvez laisser Azure SQL Database gérer automatiquement vos index.
Lorsque Azure SQL Database applique une recommandation CREATE INDEX ou DROP INDEX, il analyse automatiquement le niveau de performance des requêtes affectées par l’index. Un nouvel index sera conservé uniquement si le niveau de performance des requêtes affectées est amélioré. L’index annulé est automatiquement recréé s’il existe des requêtes qui s’exécutent plus lentement en raison de l’absence de l’index.
Considérations sur la gestion automatique des index
Les actions requises pour créer les index nécessaires dans Azure SQL Database peuvent consommer des ressources et affecter temporairement le niveau de performance en termes de charge de travail. Pour minimiser l’impact de la création d’index sur le niveau de performance des charges de travail, Azure SQL Database recherche la période appropriée pour chaque opération de gestion des index. Le réglage est reporté à plus tard si la base de données a besoin de ressources pour exécuter votre charge de travail. Il redémarre lorsque la base de données dispose de suffisamment de ressources inutilisées qui peuvent être exploitées pour la tâche de maintenance. Une fonctionnalité importante dans la gestion automatique des index est la vérification des actions. Lorsqu’Azure SQL Database crée ou annule des index, un processus analyse le niveau de performance de votre charge de travail pour vérifier que l’action les a globalement améliorées. Si l’amélioration n’est pas significative, l’action est immédiatement restaurée. De cette manière, Azure SQL Database s’assure que les actions automatiques ne nuisent pas au niveau de performance de votre charge de travail. Les index créés par le réglage automatique sont transparents pour l’opération de maintenance sur le schéma sous-jacent. Les modifications du schéma, par exemple le fait de supprimer ou de renommer des colonnes, ne sont pas bloquées par la présence d’index créés automatiquement. Les index créés automatiquement par Azure SQL Database sont immédiatement annulés lorsque la table ou les colonnes liées sont annulées.
Alternative - gestion manuelle des index
Sans gestion automatique des index, un utilisateur ou un administrateur de base de données doit interroger manuellement l’affichage sys.dm_db_missing_index_details (Transact-SQL) ou utiliser le rapport Tableau de bord du niveau de performance dans Management Studio pour rechercher des index susceptibles d’améliorer le niveau de performance, créer des index à l’aide des détails fournis dans cet affichage et analyser manuellement le niveau de performance de la requête. Pour trouver les index qui doivent être annulés, les utilisateurs doivent analyser les statistiques d’utilisation opérationnelle des index pour trouver des index rarement utilisés.
Azure SQL Database simplifie ce processus. Azure SQL Database analyse votre charge de travail, identifie les requêtes qui pourraient s’exécuter plus rapidement avec un nouvel index et identifie les index non utilisés ou en double. Pour plus d’informations sur l’identification des index à modifier, voir Rechercher des recommandations d’index dans le portail Azure.
Étapes suivantes
- Réglage automatique dans Azure SQL Database et Azure SQL Managed Instance
- ALTER DATABASE SET AUTOMATIC_TUNING (Transact-SQL)
- sys.database_automatic_tuning_options (Transact-SQL)
- sys.dm_db_tuning_recommendations (Transact-SQL)
- sys.dm_db_missing_index_details (Transact-SQL)
- sp_query_store_force_plan (Transact-SQL)
- sys.query_store_plan_forcing_locations (Transact-SQL)
- sp_query_store_unforce_plan (Transact-SQL)
- sys.database_query_store_options (Transact-SQL)
- sys.dm_os_sys_info (Transact-SQL)
- Fonctions JSON
- Plans d’exécution
- Surveillance et réglage des performances
- Outils de surveillance et de réglage des performances
- Analyse des performances à l’aide du magasin de requêtes
- Assistant Paramétrage des requêtes
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour