Groupes de fichiers et fichiers de base de données
S’applique à : ![]() SQL Server
SQL Server ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Chaque base de données SQL Server a au moins deux fichiers de système d'exploitation : un fichier de données et un fichier d'historique. Les fichiers de données contiennent des données et des objets tels que des tables, des index, des procédures stockées et des vues. Les fichiers journaux contiennent les informations nécessaires pour récupérer toutes les transactions de la base de données. Les fichiers de données peuvent être regroupés dans des groupes de fichiers à des fins d'allocation et d'administration.
fichiers de la base de données ;
Les bases de données SQL Server possèdent trois types de fichiers, comme indiqué dans le tableau suivant.
| Fichier | Description |
|---|---|
| Principal | Contient les informations de démarrage de la base de données et pointe vers les autres fichiers de la base de données. Chaque base de données comprend un fichier de données primaire. L'extension de fichier recommandée est .mdf. |
| Secondary | Fichier de données facultatif défini par l'utilisateur. Les données peuvent être réparties sur plusieurs disques en plaçant chaque fichier sur un lecteur de disque distinct. L'extension de fichier recommandée est .ndf. |
| Journal des transactions | Ce journal contient les informations utilisées pour la récupération de la base de données. Chaque base de données doit posséder au moins un fichier journal. L'extension de fichier recommandée pour les journaux des transactions est .ldf. |
Par exemple, il est possible de créer une base de données simple, appelée Sales, incluant un fichier primaire qui contient toutes les données et tous les objets, et un fichier journal qui contient les informations du journal des transactions. Il est possible de créer une base de données plus complexe, appelée Orders, incluant un fichier primaire et cinq fichiers secondaires. Les données et les objets de la base de données sont répartis dans les six fichiers, et les quatre fichiers journaux contiennent les informations du journal des transactions.
Par défaut, les données et les journaux de transactions sont placés sur le même lecteur et le même chemin pour traiter les systèmes à disque unique. Cette configuration n'est pas forcément optimale pour les environnements de production. Nous vous recommandons de placer les fichiers de données et les fichiers journaux sur des disques distincts.
Noms de fichiers logiques et physiques
Les fichiers SQL Server ont deux types de nom de fichier :
logical_file_name:lelogical_file_nameest le nom utilisé pour faire référence au fichier physique dans toutes les instructions Transact-SQL. Le nom de fichier logique doit respecter les règles régissant les identificateurs SQL Server et doit être unique parmi les noms de fichiers logiques de la base de données.os_file_name:leos_file_nameest le nom du fichier physique, comprenant le chemin du répertoire. Il doit respecter les règles en vigueur pour les noms de fichiers du système d'exploitation.
Pour plus d’informations sur NAME et l’argument FILENAME, voir Options de fichiers et de groupes de fichiers ALTER DATABASE (Transact-SQL).
Conseil
Les données et les fichiers journaux SQL Server peuvent être placés dans les systèmes de fichiers FAT ou NTFS. Sur les systèmes Windows, Microsoft recommande d’utiliser le système de fichiers NTFS pour des raisons de sécurité.
Avertissement
Les fichiers journaux et les groupes de fichiers de données en lecture/écriture ne sont pas pris en charge dans un système de fichiers compressé NTFS. Seuls les groupes de fichiers secondaires en lecture seule et les bases de données en lecture seule sont autorisés à être placés dans un système de fichiers compressé NTFS. Pour économiser de l’espace, il est fortement recommandé d’utiliser la compression des données au lieu de la compression du système de fichiers.
Lorsque plusieurs instances de SQL Server sont exécutées sur un ordinateur unique, chaque instance reçoit son propre annuaire par défaut pour contenir les fichiers des bases de données créées dans l’instance. Pour plus d’informations, consultez Emplacements des fichiers pour les instances par défaut et les instances nommées de SQL Server.
Pages de fichiers de données
Les pages d’un fichier de données SQL Server sont numérotées de manière séquentielle, zéro (0) correspondant à la première page. Chaque fichier d'une base de données possède un numéro d'identification de fichier unique. L'ID de fichier et le numéro de page sont nécessaires pour identifier de manière unique une page d'une base de données. L'exemple ci-dessous montre les numéros de page d'une base de données disposant d'un fichier de données primaire de 4 Mo et d'un fichier de données secondaire de 1 Mo.
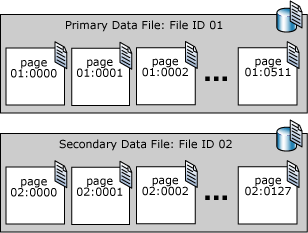
La première page de chaque fichier est une page d'en-tête qui contient des informations sur les attributs du fichier. D'autres pages situées au début du fichier contiennent également des informations sur le système, comme les tables d'allocation. Une des pages système stockée à la fois dans le fichier de données primaire et dans le premier fichier journal est une page d'amorçage de base de données qui contient des informations sur les attributs de la base de données.
Taille du fichier
Les fichiers SQL Server peuvent augmenter automatiquement leur volume et dépasser leur taille d’origine. Lorsque vous définissez un fichier, vous pouvez spécifier un incrément de croissance précis. Chaque fois que le fichier est rempli, sa taille augmente en fonction de l'incrément de croissance. Si un groupe comporte plusieurs fichiers, ces derniers ne s'accroissent pas automatiquement jusqu'à ce que tous les fichiers soient remplis.
Pour plus d’informations sur les pages et les types de page, consultez Guide d’architecture des pages et des étendues.
Chaque fichier peut également avoir une taille maximale. En l'absence de spécification, le fichier continue à s'accroître jusqu'à ce que tout l'espace disque disponible soit utilisé. Cette fonctionnalité s’avère particulièrement utile lorsque SQL Server sert de base de données incorporée dans une application pour laquelle l’utilisateur n’a pas accès à un administrateur système. L'utilisateur peut laisser les fichiers s'accroître automatiquement autant que nécessaire pour réduire la charge administrative liée à la gestion de l'espace disponible dans la base de données et à l'affectation manuelle d'espace supplémentaire.
Pour plus d’informations sur la gestion du fichier journal de transactions, consultez Gérer la taille du fichier journal des transactions.
Fichiers d'instantanés de base de données
Le format de fichier utilisé par un instantané de base de données pour stocker ses données de copie lors de l'écriture varie selon que l'instantané a été créé par un utilisateur ou utilisé en interne :
- Un instantané de base de données créé par un utilisateur stocke ses données dans un ou plusieurs fichiers partiellement alloués. La technologie des fichiers partiellement alloués constitue une fonctionnalité du système de fichiers NTFS. Au départ, un fichier partiellement alloué ne contient pas de données utilisateur et aucun espace disque pour les données utilisateur ne lui a été alloué. Pour des informations générales sur l’utilisation des fichiers partiellement alloués dans un instantané de base de données et sur le schéma de croissance des instantanés de bases de données, consultez Afficher la taille du fichier partiellement alloué d’un instantané de base de données (Transact-SQL).
- Les instantanés de base de données sont utilisés en interne par certaines commandes DBCC. Ces commandes sont les suivantes :
DBCC CHECKDB,DBCC CHECKTABLE,DBCC CHECKALLOCetDBCC CHECKFILEGROUP. Un instantané interne de base de données utilise les flux de données de remplacement éparses des fichiers de la base de données d'origine. Comme les fichiers partiellement alloués, les flux de données de remplacement sont une fonctionnalité du système de fichiers NTFS. L'utilisation de flux de données de remplacement éparses permet d'associer plusieurs affectations de données avec un seul fichier ou dossier sans influer sur les statistiques de taille de fichier ou de volume.
Groupes de fichiers
- Le groupe de fichiers primaire contient le fichier de données primaire et tous les fichiers secondaires qui n'ont pas été placés dans d'autres groupes de fichiers.
- Il est possible de créer des groupes de fichiers définis par l'utilisateur pour regrouper des fichiers de données à des fins d'administration, d'allocation des données et de placement.
Par exemple, Data1.ndf, Data2.ndf et Data3.ndf peuvent être créés sur trois lecteurs, respectivement, puis affectés au groupe de fichiers fgroup1. Une table peut alors être créée spécifiquement pour le groupe de fichiers fgroup1. Les requêtes portant sur des données de la table seront réparties sur les trois disques, ce qui permettra d'améliorer les performances. Une amélioration similaire des performances pourra être obtenue en créant un fichier unique sur un jeu de bandes RAID (Redundant Array of Independent Disks). Cependant, les fichiers et les groupes de fichiers vous permettent d'ajouter facilement des fichiers sur de nouveaux disques.
Tous les fichiers de données sont stockés dans les groupes de fichiers répertoriés dans le tableau suivant.
| Groupe de fichiers | Description |
|---|---|
| Principal | Groupe de fichiers qui contient le fichier primaire. Toutes les tables système sont allouées au groupe de fichiers primaire. |
| Données optimisées en mémoire | Un groupe de fichiers optimisé en mémoire est basé sur un groupe de fichiers Filestream |
| Filestream | |
| Défini par l’utilisateur | Tout groupe de fichiers créé par l'utilisateur lorsque celui-ci crée la base de données ou lorsqu'il la modifie ultérieurement. |
Groupe de fichiers (principal) par défaut
Lorsque des objets sont créés dans la base de données, sans spécifier le groupe de fichiers auquel ils appartiennent, ces objets sont affectés au groupe de fichiers par défaut. À tout moment, un groupe de fichiers précis est désigné comme étant le groupe de fichiers par défaut. Les fichiers du groupe de fichiers par défaut doivent être suffisamment volumineux pour contenir tous les nouveaux objets qui ne sont pas affectés à d'autres groupes de fichiers.
Le groupe de fichiers PRIMARY est le groupe de fichiers par défaut sauf s'il est modifié par l'instruction ALTER DATABASE. Les objets et tables système restent affectés au groupe de fichiers PRIMARY, et non au nouveau groupe par défaut.
Groupe de fichiers de données à mémoire optimisée
Pour plus d’informations sur les groupes de fichiers optimisés en mémoire, consultez Groupes de fichiers optimisés en mémoire.
Groupe de fichiers FILESTREAM
Pour plus d’informations sur les groupes de fichiers FILESTREAM, consultez FILESTREAM et Créer une base de données compatible FILESTREAM.
Exemple de fichier et de groupe de fichiers
L’exemple ci-dessous crée une base de données sur une instance de SQL Server. La base de données possède un fichier de données primaire, un groupe de fichiers défini par l'utilisateur et un fichier journal. Le fichier de données primaire fait partie du groupe de fichiers primaire et le groupe de fichiers défini par l'utilisateur possède deux fichiers de données secondaires. Une instruction ALTER DATABASE fait du groupe de fichiers défini par l'utilisateur le groupe par défaut. Une table est ensuite créée en spécifiant le groupe de fichiers défini par l'utilisateur. Cet exemple utilise le chemin générique c:\Program Files\Microsoft SQL Server\MSSQL.1 pour éviter de spécifier une version de SQL Server.
USE master;
GO
-- Create the database with the default data
-- filegroup, filestream filegroup and a log file. Specify the
-- growth increment and the max size for the
-- primary data file.
CREATE DATABASE MyDB
ON PRIMARY
( NAME='MyDB_Primary',
FILENAME=
'c:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_Prm.mdf',
SIZE=4MB,
MAXSIZE=10MB,
FILEGROWTH=1MB),
FILEGROUP MyDB_FG1
( NAME = 'MyDB_FG1_Dat1',
FILENAME =
'c:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_FG1_1.ndf',
SIZE = 1MB,
MAXSIZE=10MB,
FILEGROWTH=1MB),
( NAME = 'MyDB_FG1_Dat2',
FILENAME =
'c:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_FG1_2.ndf',
SIZE = 1MB,
MAXSIZE=10MB,
FILEGROWTH=1MB),
FILEGROUP FileStreamGroup1 CONTAINS FILESTREAM
( NAME = 'MyDB_FG_FS',
FILENAME = 'c:\Data\filestream1')
LOG ON
( NAME='MyDB_log',
FILENAME =
'c:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB.ldf',
SIZE=1MB,
MAXSIZE=10MB,
FILEGROWTH=1MB);
GO
ALTER DATABASE MyDB
MODIFY FILEGROUP MyDB_FG1 DEFAULT;
GO
-- Create a table in the user-defined filegroup.
USE MyDB;
CREATE TABLE MyTable
( cola int PRIMARY KEY,
colb char(8) )
ON MyDB_FG1;
GO
-- Create a table in the filestream filegroup
CREATE TABLE MyFSTable
(
cola int PRIMARY KEY,
colb VARBINARY(MAX) FILESTREAM NULL
)
GO
L’illustration suivante récapitule les résultats de l’exemple précédent (excepté pour les données Filestream).

Stratégie de remplissage des fichiers et des groupes de fichiers
Dans un groupe de fichiers, le remplissage des fichiers s'effectue selon un mode proportionnel. Au fur et à mesure que les données sont écrites dans le groupe de fichiers, le moteur de base de données SQL Server écrit les données en les répartissant entre les fichiers du groupe proportionnellement à l'espace disponible dans chaque fichier, au lieu de remplir toutes les données dans le premier fichier. Il écrit ensuite dans le fichier suivant. Par exemple, si le fichier f1 a 100 Mo et le fichier f2 200 Mo d'espace libre, une extension est allouée à partir de f1, deux extensions à partir de f2, et ainsi de suite. De cette façon, les deux fichiers arrivent à peu près en même temps à saturation et le résultat est un entrelacement simple.
Par exemple, un groupe de fichiers contient trois fichiers définis en mode de croissance automatique. En cas de saturation de tous les fichiers du groupe de fichiers, seul le premier fichier sera étendu. Si le premier fichier est saturé, et qu'il n'est plus possible d'enregistrer des données dans le groupe de fichiers, le deuxième fichier est étendu. Si le deuxième fichier est plein et qu'il n'est plus possible d'enregistrer des données dans le groupe de fichiers, le troisième fichier sera étendu. Si le troisième fichier est plein et qu'il n'est plus possible d'enregistrer des données dans le groupe de fichiers, le premier fichier sera à nouveau étendu, et ainsi de suite.
Règles pour concevoir des fichiers et des groupes de fichiers
Les règles suivantes s'appliquent aux fichiers et aux groupes de fichiers :
- Un fichier ou un groupe de fichiers ne peut pas être utilisé par plusieurs bases de données. Par exemple, les fichiers
sales.mdfetsales.ndf, qui contiennent des données et des objets de la base de données sales, ne peuvent pas être utilisés par une autre base de données. - Un fichier ne peut appartenir qu'à un seul groupe.
- Les fichiers journaux des transactions ne peuvent jamais faire partie d'un groupe de fichiers.
Recommandations
Suggestions relatives à l’utilisation de fichiers et de groupes de fichiers :
- La plupart des bases de données fonctionnent très bien avec un seul fichier de données et un seul fichier journal des transactions.
- Si vous utilisez plusieurs fichiers de données, créez un second groupe de fichiers pour les fichiers supplémentaires et utilisez-le comme groupe de fichiers par défaut. Ainsi, le fichier primaire ne contiendra que les objets et les tables système.
- Pour optimiser les performances, créez si possible les fichiers et les groupes de fichiers sur différents disques disponibles. Placez dans des groupes de fichiers différents les objets qui se disputent fortement l'espace disque.
- Utilisez les groupes de fichiers pour permettre le placement des objets sur des disques physiques spécifiques.
- Placez dans des groupes différents les tables qui sont utilisées dans les mêmes requêtes jointes. Cette étape permettra d'améliorer les performances, grâce aux entrées/sorties de disques parallèles qui recherchent les données jointes.
- Placez dans des groupes de fichiers différents les tables fréquemment consultées et les index non-cluster qui leur appartiennent. L'utilisation de différents groupes de fichiers améliorera les performances, en raison des entrées/sorties parallèles si les fichiers sont situés sur des disques physiques différents.
- Ne placez pas les fichiers journaux de transactions sur le même disque physique que les autres fichiers et groupes de fichiers.
- Si vous devez étendre un volume ou une partition où se trouvent des fichiers de base de données en utilisant des outils comme DiskPart, vous devez d’abord sauvegarder toutes les bases de données système et utilisateur, et arrêter les services SQL Server. En outre, une fois que les volumes de disque ont été étendus, vous devez exécuter la commande
DBCC CHECKDBpour garantir l’intégrité physique de toutes les bases de données résidant sur le volume.
Pour plus d’informations sur les recommandations relatives à la gestion du fichier journal de transactions, consultez Gérer la taille du fichier journal des transactions.
Contenu connexe
- CREATE DATABASE (SQL Server Transact-SQL)
- Options de fichiers et de groupes de fichiers ALTER DATABASE (Transact-SQL)
- Attacher et détacher une base de données (SQL Server)
- Guide d’architecture et gestion du journal des transactions SQL Server
- Guide d’architecture des pages et des étendues
- Gérer la taille du fichier journal des transactions