Diagnostiquer et résoudre la contention de latchs sur SQL Server
Ce guide décrit comment identifier et résoudre les problèmes de contention de latchs observés lors de l’exécution d’applications SQL Server sur des systèmes à accès concurrentiels élevés avec certaines charges de travail.
À mesure que le nombre de cœurs de processeur sur les serveurs continue de croître, l’augmentation associée des accès concurrentiels peut introduire des points de contention sur les structures de données qui doivent être accessibles en série dans le moteur de base de données. C’est particulièrement vrai pour les charges de travail de traitement transactionnel à haut débit/accès concurrentiels élevés (OLTP). Il existe un certain nombre d’outils, de techniques et de méthodes pour aborder ces défis ainsi que des pratiques qui peuvent être suivies pour concevoir des applications, tous pouvant aider à les éviter totalement. Cet article traite d’un type particulier de contention sur les structures de données qui utilisent des verrouillages tournants pour sérialiser l’accès à ces structures de données.
Note
Ce contenu a été écrit par l’équipe Microsoft SQL Server Customer Advisory Team (SQLCAT) en se basant sur son processus d’identification et de résolution des problèmes liés à la contention de latchs de page dans les applications SQL Server sur des systèmes à accès concurrentiels élevés. Les recommandations et les bonnes pratiques documentées ici sont basées sur une expérience concrète acquise lors du développement et du déploiement de systèmes OLTP réels.
Qu’est-ce que la contention de latchs dans SQL Server ?
Les latchs sont des primitives de synchronisation légères utilisées par le moteur SQL Server pour garantir la cohérence des structures en mémoire, notamment les index, les pages de données et les structures internes, comme des pages non-feuille dans un arbre B (B-Tree). SQL Server utilise des latchs de mémoire tampon pour protéger les pages dans le pool de mémoires tampons et des latchs d’E/S pour protéger les pages qui ne sont pas encore chargées dans le pool de mémoires tampons. Chaque fois que des données sont écrites ou lues dans une page dans le pool de mémoires tampons de SQL Server, un thread de travail doit d’abord acquérir un latch de mémoire tampon pour la page. Différents types de latch de mémoire tampon sont disponibles pour accéder aux pages du pool de mémoires tampons, notamment les latchs exclusifs (PAGELATCH_EX) et les latchs partagés (PAGELATCH_SH). Quand SQL Server tente d’accéder à une page qui n’est pas déjà présente dans le pool de mémoires tampons, une E/S asynchrone est publiée pour charger la page dans le pool de mémoires tampons. Si SQL Server doit attendre que le sous-système d’E/S réponde, il va attendre sur un latch d’E/S exclusif (PAGEIOLATCH_EX) ou partagé (PAGEIOLATCH_SH), en fonction du type de demande ; c’est fait pour empêcher un autre thread de travail de charger la même page dans le pool de mémoires tampons avec un latch incompatible. Les latchs sont également utilisés pour protéger l’accès aux structures de mémoire internes autres que les pages du pool de mémoires tampons ; ceux -ci sont appelés « latchs non-mémoire tampon ».
La contention sur les latchs de page est le scénario le plus courant rencontré sur les systèmes multiprocesseurs : la majeure partie de cet article leur est donc consacrée.
Une contention de latchs se produit quand plusieurs threads tentent simultanément d’acquérir des latchs incompatibles sur la même structure en mémoire. Comme un latch est un mécanisme de contrôle interne, le moteur SQL détermine automatiquement quand les utiliser. Comme le comportement des latchs est déterministe, les décisions prises au niveau des applications, y compris la conception du schéma, peuvent affecter ce comportement. Cet article vise à fournir les informations suivantes :
- Informations générales sur la façon dont les latchs sont utilisés par SQL Server.
- Outils utilisés pour examiner la contention de latchs.
- Comment déterminer si la quantité de contention observée est problématique.
Nous allons explorer quelques scénarios courants et la meilleure façon de les gérer pour réduire la contention.
Comment SQL Server utilise les latchs ?
Une page dans SQL Server a une taille de 8 Ko et peut stocker plusieurs lignes. Pour augmenter la concurrence et les performances, les latchs de mémoire tampon sont conservés seulement pendant la durée de l’opération physique sur la page, contrairement aux verrous, qui sont conservés pendant la durée de la transaction logique.
Les latchs sont internes au moteur SQL et sont utilisés pour assurer la cohérence de la mémoire, tandis que les verrous sont utilisés par SQL Server pour fournir la cohérence transactionnelle logique. Le tableau suivant compare les latchs et les verrous :
| Structure | Objectif | Contrôlé par | Coût en matière de performances | Exposé par |
|---|---|---|---|---|
| Latch | Garantir la cohérence des structures en mémoire. | Moteur SQL Server uniquement. | Le coût en matière de performances est faible. Pour permettre une concurrence et des performances maximales, les latchs sont conservés seulement pendant la durée de l’opération physique sur la structure en mémoire, contrairement aux verrous, qui sont conservés pendant la durée de la transaction logique. | sys.dm_os_wait_stats (Transact-SQL) : Fournit des informations sur les types d’attente PAGELATCH, PAGEIOLATCH et LATCH (LATCH_EX, LATCH_SH est utilisé pour regrouper toutes les attentes de latchs non-mémoire tampon). sys.dm_os_latch_stats (Transact-SQL) : Fournit des informations détaillées sur les attentes de latchs non-mémoire tampon. sys.dm_db_index_operational_stats (Transact-SQL) : cette vue de gestion dynamique fournit des attentes agrégées pour chaque index, ce qui est pratique pour résoudre les problèmes de performances liés aux verrous. |
| Verrouiller | Garantir la cohérence des transactions. | Peut être contrôlé par l’utilisateur. | Le coût en matière de performances est élevé par rapport aux latchs, car les verrous doivent être conservés pendant la durée de la transaction. | sys.dm_tran_locks (Transact-SQL). sys.dm_exec_sessions (Transact-SQL). |
Modes et compatibilité des latchs de SQL Server
Une certaine contention de latchs doit être attendue comme faisant normalement partie du fonctionnement du moteur SQL Server. Il est inévitable que plusieurs demandes simultanées de latchs de compatibilité variable se produisent sur un système à accès concurrentiels élevés. SQL Server applique une compatibilité des latchs en obligeant les requêtes de demandes de latch incompatibles à attendre dans une file d’attente jusqu’à ce que les demandes de latch en attente soient traitées.
Les latchs sont acquis selon un parmi cinq modes différents, qui sont liés au niveau d’accès. Les modes de latch de SQL Server peuvent être résumés comme suit :
KP : Keep Latch (Latch de conservation), garantit que la structure référencée ne peut pas être détruite. Utilisé quand un thread veut examiner une structure de mémoire tampon. Comme le latch KP est compatible avec tous les latchs à l’exception du latch de destruction (DT), le latch KP est considéré comme « léger », ce qui signifie que son utilisation a un impact minimal sur les performances. Comme le latch KP n’est pas compatible avec le latch DT, il va empêcher tout autre thread de détruire la structure référencée. Par exemple, un latch KP va empêcher la structure qu’il référence d’être détruite par le processus d’écriture différée (lazywriter). Pour plus d’informations sur l’utilisation du processus d’écriture différée avec la gestion des pages de mémoire tampon de SQL Server, consultez Écriture de pages.
SH -- Verrou partagé, obligatoire pour lire la structure référencée (par exemple lire une page de données). Plusieurs threads peuvent accéder simultanément à une ressource pour la lecture sous un verrou partagé.
UP --Update Latch (Latch de mise à jour), est compatible avec SH (Latch partagé) et KP, mais pas avec les autres : il ne permet donc pas à un latch EX d’écrire dans la structure référencée.
EX : Exclusive Latch (Latch exclusif), empêche les autres threads d’écrire ou de lire dans la structure référencée. Un exemple d’utilisation serait de modifier le contenu d’une page pour la protection de page endommagée.
DT : Destroy Latch (Latch de destruction), doit être acquis avant de détruire le contenu de la structure référencée. Par exemple, un latch DT doit être acquis par le processus d’écriture différée pour libérer une page nettoyée avant de l’ajouter à la liste des mémoires tampons libres disponibles pour être utilisées par d’autres threads.
Les modes de latch ont différents niveaux de compatibilité : par exemple, un latch partagé (SH) est compatible avec un latch de mise à jour (UP) ou de conservation (KP), mais il est incompatible avec un latch de destruction (DT). Plusieurs latchs peuvent être acquis simultanément sur la même structure tant que les latchs sont compatibles. Quand un thread tente d’acquérir un latch défini dans un mode qui n’est pas compatible, il est placé dans une file d’attente où il attend un signal indiquant que la ressource est disponible. Un verrou tournant de type SOS_Task est utilisé pour protéger la file d’attente en imposant un accès sérialisé à la file d’attente. Ce verrou tournant doit être acquis pour ajouter des éléments à la file d’attente. Le verrou tournant SOS_Task signale également aux threads dans la file d’attente quand des latchs incompatibles sont libérés, ce qui permet aux threads en attente d’acquérir un latch compatible et de continuer à travailler. La file d’attente est traitée sur une base FIFO (premier entré, premier sorti), au fil de la libération des demandes de latch. Les latchs utilisent ce système FIFO pour garantir l’équité et éviter la stagnation indéfinie des threads.
La compatibilité des modes de latch est indiquée dans le tableau suivant (O indique la compatibilité et N indique l’incompatibilité) :
| Mode de latch | KP | SH | UP | EX | DT |
|---|---|---|---|---|---|
| KP | O | O | O | O | N |
| SH | O | O | O | N | N |
| UP | O | O | N | N | N |
| EX | O | N | N | N | N |
| DT | N | N | N | N | N |
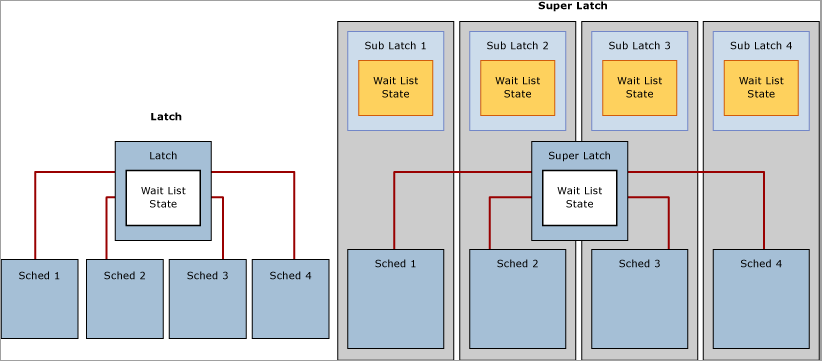
Superlatchs et sublatchs SQL Server
Avec la présence grandissante de systèmes multisockets/multicœurs basés sur NUMA, SQL Server 2005 a introduit les superlatchs, également appelés sublatchs, qui sont effectifs seulement sur les systèmes avec 32 processeurs logiques ou plus. Les superlatchs améliorent l’efficacité du moteur SQL pour certains modèles d’utilisation dans les charges de travail OLTP avec accès concurrentiel élevé : par exemple, quand certaines pages ont un modèle d’accès en lecture seule (SH) intensif, mais qu’elles font rarement l’objet d’écritures. Une page racine (un index) d’arbre B est un exemple de page avec un tel modèle d’accès : le moteur SQL nécessite qu’un latch partagé soit placé sur la page racine quand un fractionnement de page se produit à n’importe quel niveau de l’arbre B. Dans une charge de travail OLTP avec des insertions intensives et des accès concurrentiels élevés, le nombre de fractionnements de pages augmente largement en fonction du débit, ce qui peut dégrader les performances. Les superlatchs permettent de meilleures performances pour l’accès aux pages partagées où plusieurs threads de travail en cours d’exécution simultanée nécessitent des latchs SH. Pour ce faire, le moteur SQL Server va promouvoir dynamiquement un latch en superlatch sur une page de ce type. Un superlatch partitionne un latch en un tableau de structures de sublatchs, un sublatch par partition par cœur de processeur, où le latch principal devient un proxy redirecteur et où la synchronisation de l’état global n’est pas nécessaire pour les latchs en lecture seule. Dans ce cas, le processus de travail, qui est toujours affecté à un processeur spécifique, doit seulement acquérir le sublatch partagé (SH) affecté au planificateur local.
Note
De manière générale, la documentation SQL Server utilise le terme B-tree en référence aux index. Dans les index rowstore, SQL Server implémente une structure B+. Cela ne s’applique pas aux index columnstore ou aux magasins de données en mémoire. Pour plus d’informations, consultez le Guide de conception et d’architecture d’index SQL Server et Azure SQL.
L’acquisition de latchs compatibles, comme un superlatch partagé, utilise moins de ressources et permet l’accès à grande échelle aux pages chaudes mieux que ne le ferait un latch partagé non partitionné, car la suppression de l’exigence de synchronisation de l’état global améliore considérablement les performances en accédant seulement à la mémoire NUMA locale. À l’inverse, l’acquisition d’un superlatch exclusif (EX) est plus coûteuse que l’acquisition d’un latch EX normal, car SQL doit envoyer un signal à tous les sublatchs. Quand il est observé qu’un superlatch utilise un modèle d’accès EX intensif, le moteur SQL peut le rétrograder une fois que la page a été supprimée du pool de mémoires tampons. Le diagramme suivant illustre un latch normal et un superlatch partitionné :
Utilisez l’objet SQL Server:Latches et les compteurs associés de l’Analyseur de performances pour recueillir des informations sur les superlatchs, y compris le nombre de superlatchs, les promotions de superlatchs par seconde et les rétrogradations de superlatchs par seconde. Pour plus d’informations sur l’objet SQL Server:Latches et les compteurs associés, consultez SQL Server - Objet Latches.
Types d’attente des latchs
Les informations d’attente cumulatives sont suivies par SQL Server et sont accessibles à l’aide de la vue de gestion dynamique (DMW). sys.dm_os_wait_stats SQL Server utilise trois types d’attente de verrou interne tels que définis par le wait_type correspondant dans la DMV sys.dm_os_wait_stats :
Latch de mémoire tampon (BUF) : : utilisé pour garantir la cohérence des pages d’index et de données pour les objets utilisateur. Ils sont également utilisés pour protéger l’accès aux pages de données que SQL Server utilise pour les objets système. Par exemple, les pages qui gèrent les allocations sont protégées par des latchs de mémoire tampon. Il s’agit des pages PFS (Page Free Space), GAM (Global Allocation Map), SGAM (Shared Global Allocation Map) et IAM (Index Allocation Map). Les verrous de mémoire tampon sont signalés avec
sys.dm_os_wait_statsunwait_typePAGELATCH_ *.Latch non-mémoire tampon (non-BUF) : : utilisé pour garantir la cohérence des structures en mémoire autres que les pages du pool de mémoires tampons. Toutes les attentes pour les verrous non tampons sont signalées en tant que
wait_typeLATCH_*.Latch d’E/S : un sous-ensemble de latchs de mémoire tampon qui garantissent la cohérence des mêmes structures protégées par des latchs de mémoire tampon quand ces structures nécessitent un chargement dans le pool de mémoires tampons avec une opération d’E/S. Les latchs d’E/S empêchent un autre thread de charger la même page dans le pool de mémoires tampons avec un latch incompatible. Associé à un
wait_typePAGEIOLATCH_ *.Note
Si vous voyez une quantité significative d’attentes PAGEIOLATCH, cela signifie que SQL Server est en attente sur le sous-système d’E/S. Alors qu’une certaine quantité d’attentes PAGEIOLATCH est attendue ainsi qu’un comportement normal, si les temps d’attente PAGEIOLATCH moyens sont régulièrement au-dessus de 10 millisecondes (ms), vous devez rechercher la raison pour laquelle le sous-système d’E/S est sous pression.
Si, en regardant la DMV sys.dm_os_wait_stats, vous voyez des verrous non-mémoire tampon, vous devez examiner sys.dm_os_latch_stats pour obtenir une répartition détaillée des informations sur les attentes cumulées pour les verrous non-mémoire tampon. Toutes les attentes de latchs de mémoire tampon sont classifiées sous la classe de latch BUFFER, les autres étant utilisées pour classifier les verrous non-mémoire tampon.
Symptômes et causes de la contention de latchs SQL Server
Sur un système avec accès concurrentiels élevés, il est normal d’observer une contention active sur des structures faisant l’objet d’accès fréquents et qui sont protégées par des latchs et d’autres mécanismes de contrôle dans SQL Server. Il est considéré comme problématique quand la contention et le temps d’attente associés à l’acquisition du latch pour une page sont suffisants pour réduire l’utilisation des ressources (processeur), ce qui entrave le débit.
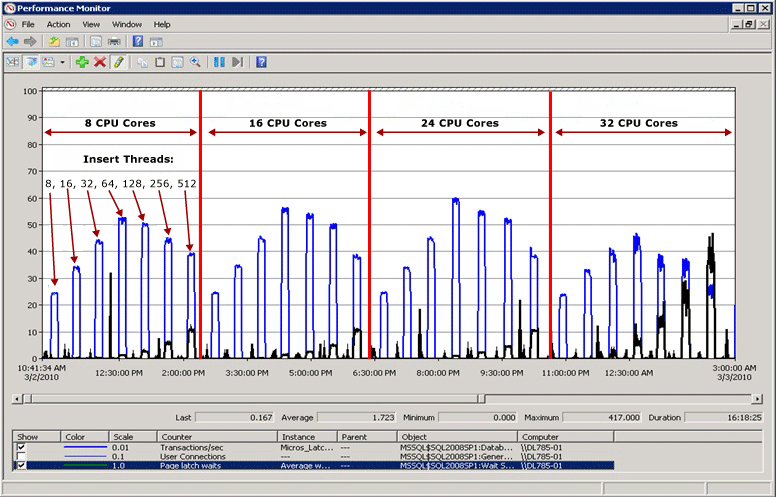
Exemple de contention de latchs
Dans le diagramme suivant, la ligne bleue représente le débit dans SQL Server, mesuré en transactions par seconde ; la ligne noire représente le temps d’attente moyen d’un latch de page. Dans le cas présent, chaque transaction effectue une insertion dans un index cluster avec une valeur de début qui croît séquentiellement, par exemple lors du remplissage d’une colonne d’identité avec le type de données bigint. À mesure que le nombre de processeurs augmente jusqu’à 32, il est évident que le débit global a diminué et que le temps d’attente des latchs de page est passé à environ 48 millisecondes, comme le montre la ligne noire. Cette relation inverse entre le débit et le temps d’attente des latchs de page est un scénario courant qui est facilement diagnostiqué.
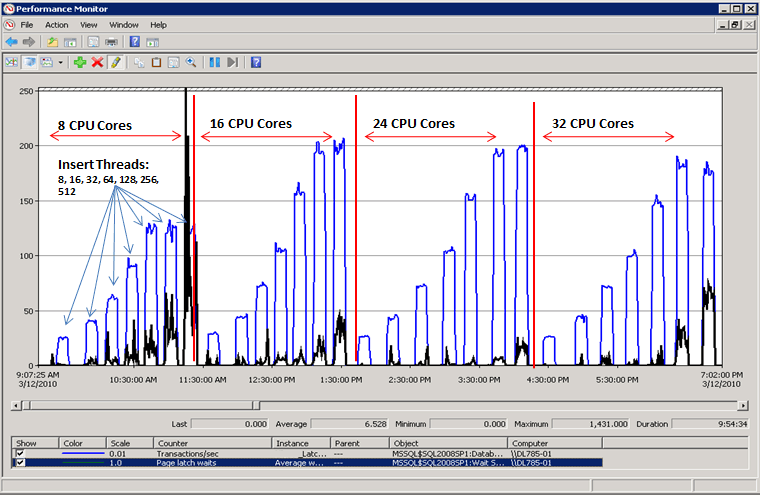
Performances quand la contention de latchs est résolue
Comme le montre le diagramme suivant, SQL Server n’a plus de goulots d’étranglement sur les attentes de latchs de page et le débit est augmenté de 300 %, comme c’est mesuré par les transactions par seconde. Ceci a été accompli avec la technique consistant à utiliser un partitionnement de hachage avec une colonne calculée, qui est décrite plus loin dans cet article. Cette amélioration des performances est destinée aux systèmes avec un grand nombre de cœurs et un niveau élevé d’accès concurrentiels.
Facteurs affectant la contention de latchs
La contention de latchs qui entrave les performances dans les environnements OLTP est généralement causée par des accès concurrentiels élevés associés à un ou plusieurs des facteurs suivants :
| Facteur | Détails |
|---|---|
| Nombre élevé de processeurs logiques utilisés par SQL Server | Une contention des latchs peut se produire sur n’importe quel système multicœur. Dans l’expérience de SQLCAT, une contention excessive des latchs, qui a un impact sur les performances des applications au-delà d’un niveau acceptable, a été observée le plus souvent sur des systèmes avec 16 cœurs de processeur ou plus et elle peut augmenter à mesure que des cœurs supplémentaires sont rendus disponibles. |
| Conception du schéma et modèles d’accès | La profondeur de l’arbre B, la conception des index cluster et non-cluster, la taille et la densité des lignes par page, et les modèles d’accès (activité de lecture/écriture/suppression) sont des facteurs qui peuvent contribuer à une contention excessive des latchs de page. |
| Degré élevé d’accès concurrentiels au niveau de l’application | Une contention excessive des latchs de page se produit généralement en conjonction avec un niveau élevé de demandes simultanées provenant la couche application. Certaines pratiques de programmation peuvent également introduire un grand nombre de demandes pour une page spécifique. |
| Disposition des fichiers logiques utilisés par les bases de données SQL Server | La disposition des fichiers logiques peut affecter le niveau de contention des latchs de page provoqué par des structures d’allocation comme les pages PFS (Page Free Space), GAM (Global Allocation Map), SGAM (Shared Global Allocation Map) et IAM (Index Allocation Map). Pour plus d’informations, consultez Surveillance et résolution des problèmes tempDB : Goulot d’étranglement d’allocation. |
| Performances du sous-système d’E/S | Une quantité significative d’attentes PAGEIOLATCH indique que SQL Server est en attente sur le sous-système d’E/S. |
Diagnostic de la contention de latchs SQL Server
Cette section fournit des informations sur le diagnostic de la contention de latchs SQL Server pour déterminer si elle est problématique pour votre environnement.
Outils et méthodes pour le diagnostic de la contention de latchs
Les principaux outils utilisés pour diagnostiquer la contention de latchs sont les suivants :
Analyseur de performances, pour surveiller l’utilisation du processeur et les temps d’attente dans SQL Server, et déterminer s’il existe une relation entre l’utilisation du processeur et les temps d’attente des latchs.
Les vues de gestion dynamiques de SQL Server, qui peuvent être utilisées pour déterminer le type spécifique de latch qui est à l’origine du problème et la ressource affectée.
Dans certains cas, il est nécessaire d’obtenir des images mémoire du processus SQL Server et de les analyser avec les outils de débogage Windows.
Note
Ce niveau avancé de résolution des problèmes est généralement nécessaire seulement pour les problèmes liés à la contention des latchs non-mémoire tampon. Vous pouvez faire appel aux services de support technique Microsoft pour ce type de dépannage avancé.
Le processus technique de diagnostic de la contention des latchs peut être résumé dans les étapes suivantes :
Déterminez s’il existe de la contention qui peut être liée aux latchs.
Utilisez les vues DMV fournies dans l’annexe : Scripts de contention de latch SQL Server pour déterminer le type de verrou et de ressource affecté.
Réduisez la contention en utilisant une des techniques décrites dans Gestion de la contention des latchs pour différents modèles de table.
Indicateurs de contention des latchs
Comme indiqué précédemment, la contention des latchs ne pose problème que si la contention et le temps d’attente associés à l’acquisition de latchs de page empêchent l’augmentation du débit quand des ressources de processeur sont disponibles. La détermination d’une quantité acceptable de contention nécessite une approche holistique qui prend en compte les exigences de performances et de débit ainsi que les ressources d’E/S et de processeur disponibles. Cette section vous guide dans la détermination de l’impact de la contention de latchs sur une charge de travail, comme suit :
Mesurez les temps d’attente globaux pendant un test représentatif.
Classez-les dans l’ordre.
Déterminez la proportion de ceux qui sont liés aux latchs.
Les informations d’attente cumulatives sont disponibles à partir du sys.dm_os_wait_stats DMV. Le type de contention de latch le plus courant est la contention de latch tampon, observé comme une augmentation des temps d’attente pour les verrous avec une wait_type PAGELATCH_ *. Les verrous non tampons sont regroupés sous le type d’attente LATCH* . Comme le montre le diagramme suivant, vous devez tout d’abord regarder le cumul des attentes au niveau du système en utilisant la vue de gestion dynamique sys.dm_os_wait_stats pour déterminer le pourcentage du temps d’attente global qui est dû aux verrous de mémoire tampon ou non-mémoire tampon. Si vous rencontrez des verrous non tampons, la sys.dm_os_latch_stats DMV doit également être examinée.
Le diagramme suivant décrit la relation entre les informations retournées par les sys.dm_os_wait_statssys.dm_os_latch_stats DMV.

Pour plus d’informations sur la sys.dm_os_wait_stats vue DMV, consultez sys.dm_os_wait_stats (Transact-SQL) dans l’aide de SQL Server.
Pour plus d’informations sur la sys.dm_os_latch_stats vue DMV, consultez sys.dm_os_latch_stats (Transact-SQL) dans l’aide de SQL Server.
Les mesures suivantes de temps d’attente de latchs sont des indicateurs d’une contention excessive des latchs affectant les performances de l’application :
Temps d’attente moyen de latch de page augmente de façon cohérente avec le débit : si les temps d’attente de verrous de page moyens augmentent constamment avec le débit et si les temps d’attente de latch de mémoire tampon moyenne augmentent également au-dessus des temps de réponse de disque attendus, vous devez examiner les tâches d’attente actuelles à l’aide de la
sys.dm_os_waiting_tasksvue dynamique. Les moyennes peuvent être trompeuses si elles sont analysées isolément : il est donc important d’examiner le système en activité quand c’est possible pour comprendre les caractéristiques de la charge de travail. En particulier, vérifiez s’il y a des temps d’attente élevés sur les demandes PAGELATCH_EX et/ou PAGELATCH_SH sur des pages. Suivez ces étapes pour diagnostiquer une augmentation des temps d’attente moyens des latchs de page avec le débit :- Utilisez les exemples de scripts Interroger sys.dm_os_waiting_tasks triés par ID de session ou Calculer les temps d’attente sur une période de temps pour examiner les tâches actives en attente et mesurer le temps d’attente moyen des latchs.
- Utilisez l’exemple de script Interroger les descripteurs de mémoire tampon pour déterminer les objets à l’origine de la contention de latchs pour déterminer l’index et la table sous-jacente sur laquelle la contention se produit.
- Mesurez le temps d’attente moyen du verrou de page avec le compteur De performances MSSQL%InstanceName%\Wait Statistics\Page Latch Waits\Average Waits ou en exécutant la
sys.dm_os_wait_statsvue DMV.
Note
Pour calculer le temps d’attente moyen d’un type d’attente particulier (retourné par
sys.dm_os_wait_statswt_:type), divisez le temps d’attente total (retourné en tant que ) par le nombre de tâches en attente (retournées en tant quewait_time_mswaiting_tasks_count).Pourcentage du temps d’attente total passé sur les types d’attente de verrous pendant les pics de charge : si le temps d’attente moyen du verrou augmente en pourcentage du temps d’attente global augmente en ligne avec la charge de l’application, la contention de latch peut affecter les performances et doit être examinée.
Mesurez les temps d’attente des latchs de page et les temps d’attente des latchs de non-page avec les compteurs de performances de SQLServer - Objet Statistiques d’attente. Ensuite, comparez les valeurs de ces compteurs de performances aux compteurs de performance associés au processeur, aux E/S, à la mémoire et au débit réseau. Par exemple, Transactions/s et Nombre de requêtes de lots/s sont deux bonnes mesures d’utilisation des ressources.
Note
Le temps d’attente relatif pour chaque type d’attente n’est pas inclus dans la
sys.dm_os_wait_statsDMV, car ce DMW mesure les temps d’attente depuis la dernière fois que l’instance de SQL Server a démarré ou que les statistiques d’attente cumulatives ont été réinitialisées à l’aide de DBCC SQLPERF. Pour calculer le temps d’attente relatif pour chaque type d’attente, prenez un instantané avant le pic desys.dm_os_wait_statscharge, après la charge maximale, puis calculez la différence. L’exemple de script Calculer les temps d’attente sur une période de temps peut être utilisé à cette fin.Pour un environnement hors production uniquement, désactivez la
sys.dm_os_wait_statsvue dynamique avec la commande suivante :dbcc SQLPERF ('sys.dm_os_wait_stats', 'CLEAR')Une commande similaire peut être exécutée pour effacer la
sys.dm_os_latch_statsvue dynamique :dbcc SQLPERF ('sys.dm_os_latch_stats', 'CLEAR')Le débit n’augmente pas et, dans certains cas, diminue, à mesure que la charge de l’application augmente et que le nombre de processeurs disponibles pour SQL Server augmente : ceci a été illustré dans l’exemple de contention de latch.
L’utilisation du processeur n’augmente pas à mesure que la charge de travail de l’application augmente : si l’utilisation du processeur sur le système n’augmente pas à mesure que la concurrence pilotée par le débit de l’application augmente, il s’agit d’un indicateur indiquant que SQL Server attend quelque chose et présente une contention de verrous.
Cause racine possible. Même si chacune des conditions précédentes est vraie, il est toujours possible que la cause racine des problèmes de performances se trouve ailleurs. En fait, dans la majorité des cas, une utilisation non optimale du processeur est causée par d’autres types d’attentes, comme le blocage sur des verrous, des attentes liées aux E/S ou des problèmes liés au réseau. En règle générale, il est toujours préférable de résoudre le problème de l’attente de ressources, qui représente la plus grande part du temps d’attente global avant de procéder à une analyse plus approfondie.
Analyse des latchs de mémoire tampon d’attente actuels
Les manifestes de contention de latch de mémoire tampon sont une augmentation des temps d’attente pour les verrous avec un PAGELATCH_* ou PAGEIOLATCH_* comme indiqué dans la sys.dm_os_wait_stats vue dynamique.wait_type Pour examiner le système en temps réel, exécutez la requête suivante sur un système pour joindre les vues dynamiques et sys.dm_exec_requests les sys.dm_os_wait_statssys.dm_exec_sessions DMV. Les résultats peuvent être utilisés pour déterminer le type d’attente actuel pour les sessions qui s’exécutent sur le serveur.
SELECT wt.session_id, wt.wait_type
, er.last_wait_type AS last_wait_type
, wt.wait_duration_ms
, wt.blocking_session_id, wt.blocking_exec_context_id, resource_description
FROM sys.dm_os_waiting_tasks wt
JOIN sys.dm_exec_sessions es ON wt.session_id = es.session_id
JOIN sys.dm_exec_requests er ON wt.session_id = er.session_id
WHERE es.is_user_process = 1
AND wt.wait_type <> 'SLEEP_TASK'
ORDER BY wt.wait_duration_ms desc
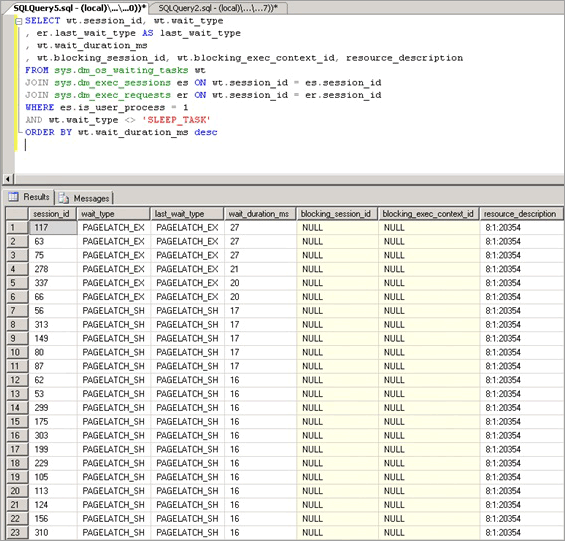
Les statistiques exposées par cette requête sont décrites ci-dessous :
| Statistique | Description |
|---|---|
| Session_id | ID de la session associée à la tâche. |
| Wait_type | Type d’attente que SQL Server a enregistré dans le moteur, qui empêche l’exécution d’une requête en cours. |
| Last_wait_type | Si la demande a été bloquée précédemment, cette colonne indique le type de la dernière attente. N'accepte pas la valeur NULL. |
| Wait_duration_ms | Temps d’attente total en millisecondes passé à attendre ce type d’attente depuis le démarrage de SQL Server instance ou depuis la réinitialisation des statistiques d’attente cumulées. |
| Blocking_session_id | ID de la session qui bloque la demande. |
| Blocking_exec_context_id | ID du contexte d'exécution associé à la tâche. |
| Resource_description | La colonne resource_description indique la page exacte attendue dans le format suivant : <database_id>:<file_id>:<page_id> |
La requête suivante retourne des informations pour tous les latchs non-mémoire tampon :
select * from sys.dm_os_latch_stats where latch_class <> 'BUFFER' order by wait_time_ms desc;
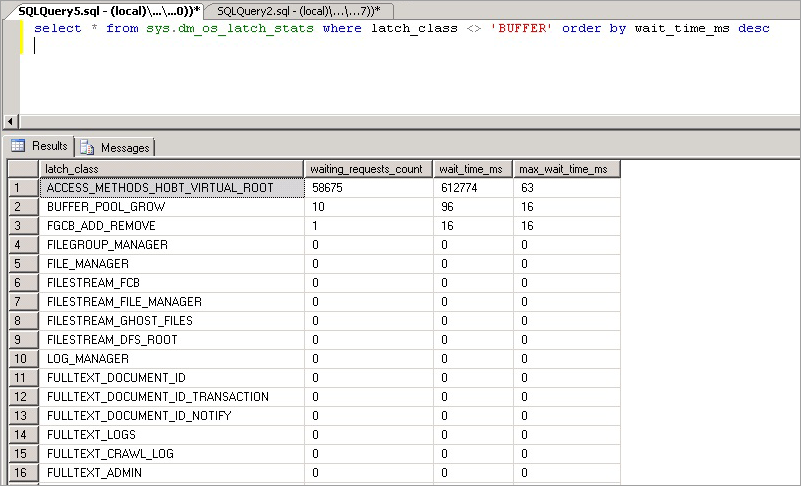
Les statistiques exposées par cette requête sont décrites ci-dessous :
| Statistique | Description |
|---|---|
| latch_class | Type de latch que SQL Server a enregistré dans le moteur, qui empêche l’exécution d’une requête en cours. |
| waiting_requests_count | Nombre d’attentes sur les latchs de cette classe depuis le redémarrage de SQL Server. Ce compteur est incrémenté au début d'une attente de verrou interne. |
| wait_time_ms | Temps d’attente total en millisecondes passé à attendre ce type de latch. |
| max_wait_time_ms | Durée maximale en millisecondes pendant laquelle une requête a été en attente sur ce type de latch. |
Note
Les valeurs retournées par cette vue de gestion dynamique sont cumulatives depuis le dernier redémarrage du moteur de base de données ou la réinitialisation de la vue de gestion dynamique. Utilisez la colonne sqlserver_start_time dans sys.dm_os_sys_info pour rechercher la dernière heure de démarrage du moteur de base de données. Sur un système qui s’exécute depuis longtemps, cela signifie que certaines statistiques telles que max_wait_time_ms sont rarement utiles. La commande suivante peut être utilisée pour réinitialiser les statistiques d’attente pour cette vue de gestion dynamique :
DBCC SQLPERF ('sys.dm_os_latch_stats', CLEAR);
Scénarios de contention des latchs SQL Server
Il a été observé que les scénarios suivants provoquaient une contention excessive des latchs.
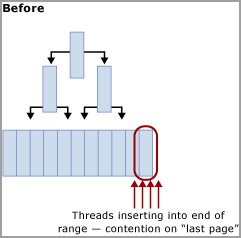
Contention des insertions dans la dernière page/page de fin.
Une pratique OLTP courante est de créer un index cluster sur une colonne d’identité ou de date. Ceci permet de maintenir une bonne organisation physique de l’index, ce qui peut grandement améliorer les performances des lectures et des écritures dans l’index. Cette conception du schéma peut cependant entraîner incidemment une contention de latchs. Ce problème se produit le plus souvent avec une grande table, avec de petites lignes et avec des insertions dans un index contenant une colonne clé de début qui augmente de façon séquentielle, comme une clé croissante de type integer ou datetime. Dans ce scénario, l’application effectue rarement si ce n’est jamais des mises à jour ou des suppressions, à l’exception des opérations d’archivage.
Dans l’exemple suivant, le thread 1 et le thread 2 veulent tous deux effectuer une insertion d’un enregistrement qui sera stocké sur la page 299. Du point de vue du verrouillage logique, il n’y a pas de problème, car des verrous de niveau ligne vont être utilisés et des verrous exclusifs sur les deux enregistrements de la même page peuvent être détenus en même temps. Cependant, pour garantir l’intégrité de la mémoire physique, un seul thread à la fois peut acquérir un latch exclusif pour que l’accès à la page soit sérialisé afin d’éviter les pertes de mises à jour en mémoire. Dans ce cas, le thread 1 acquiert le latch exclusif et le thread 2 attend, ce qui enregistre une attente PAGELATCH_EX pour cette ressource dans les statistiques d’attente. Cela s’affiche par le biais de la wait_type valeur dans la sys.dm_os_waiting_tasks vue dynamique.
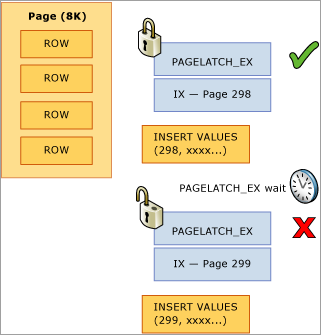
Cette contention est communément appelée contention d’« insertion de dernière page », car elle se produit sur le bord le plus à droite de l’arbre B, comme le montre le diagramme suivant :
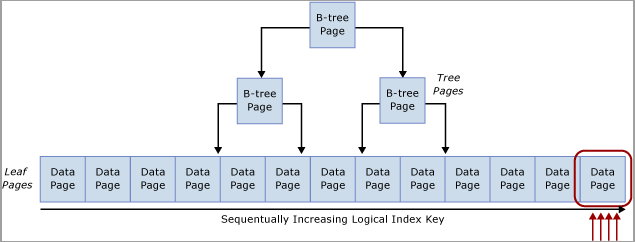
Ce type de contention de latch peut être expliqué comme suit. Quand une nouvelle ligne est insérée dans un index, SQL Server utilise l’algorithme suivant pour effectuer la modification :
Parcourir l’arbre B pour localiser la page appropriée qui contiendra le nouvel enregistrement.
Appliquer un latch sur la page avec PAGELATCH_EX, empêchant ainsi d’autres utilisateurs de la modifier, et acquérir des latchs partagés (PAGELATCH_SH) sur toutes les pages non-feuille.
Note
Dans certains cas, le moteur SQL impose aussi l’acquisition de latchs EX sur les pages d’arbre B non-feuille. Par exemple, quand un fractionnement de page se produit, les pages qui seront directement affectées doivent faire l’objet d’un latch exclusif (PAGELATCH_EX).
Enregistrer une entrée de journal indiquant que la ligne a été modifiée.
Ajouter la ligne à la page et marquer la page comme étant en cours de modification.
Annuler les latchs sur toutes les pages.
Si l’index de la table est basé sur une clé qui augmente séquentiellement, chaque nouvelle insertion sera sur la même page à la fin de l’arbre B, jusqu’à ce que cette page soit pleine. Dans les scénarios d’accès concurrentiel élevé, ceci peut entraîner de la contention sur le bord le plus à droite de l’arbre B, et se produire sur des index cluster et non cluster. Les tables affectées par ce type de contention acceptent principalement les INSERT et les pages des index problématiques sont normalement relativement denses (par exemple, une taille de ligne ~165 octets (y compris la surcharge de ligne) est égale à ~49 lignes par page. Dans cet exemple d’insertions intensives, il est attendu que des PAGELATCH_EX/PAGELATCH_SH se produisent, et ceci est couramment constaté. Pour examiner les attentes des verrous de page et les attentes de verrou d’arborescence, utilisez la sys.dm_db_index_operational_stats vue dynamique.
Le tableau suivant récapitule les principaux facteurs observés avec ce type de contention de latch :
| Facteur | Observations courantes |
|---|---|
| Processeurs logiques utilisés par SQL Server | Ce type de contention de latch se produit principalement sur les systèmes à 16 cœurs de processeur et plus, et plus fréquemment sur des systèmes à 32 cœurs de processeur et plus. |
| Conception du schéma et modèles d’accès | Utilise une valeur d’identité croissant séquentiellement comme colonne de début dans un index sur une table pour des données transactionnelles. L’index a une clé primaire croissante avec un taux élevé d’insertions. L’index a au moins une valeur de colonne croissant séquentiellement. En général, une taille de ligne réduite avec plusieurs lignes par page. |
| Type d’attente observé | De nombreux threads sont en contention pour la même ressource avec des attentes de verrou exclusif (EX) ou partagé (SH) associés à la même resource_description dans la vue de gestion dynamique sys.dm_os_waiting_tasks, telle que retournée par la requête Interroger sys.dm_os_waiting_tasks commandé par la durée d’attente. |
| Facteurs de conception à prendre en compte | Envisagez de changer l’ordre des colonnes d’index comme décrit dans la stratégie de limitation des index non séquentiels si vous pouvez garantir que les insertions seront distribuées en permanence uniformément dans l’arbre B. Si la stratégie de limitation des partitions de hachage est utilisée, elle supprime la possibilité d’utiliser le partitionnement à d’autres fins, comme l’archivage par fenêtre glissante. L’utilisation de la stratégie de limitation des partitions de hachage peut entraîner des problèmes d’élimination de partition pour les requêtes SELECT utilisées par l’application. |
Contention de latchs sur des petites tables avec un index non cluster et des insertions aléatoires (table de file d’attente)
Ce scénario se produit généralement quand une table SQL est utilisée comme file d’attente temporaire (par exemple dans un système de messagerie asynchrone).
Dans ce scénario, une contention de latchs exclusifs (EX) et partagés (SH) peut se produire dans les conditions suivantes :
- Les opérations d’insertion, de sélection, de mise à jour ou de suppression se produisent dans un contexte d’accès concurrentiel élevé.
- La taille de ligne est relativement petite (ce qui se traduit par des pages denses).
- Le nombre de lignes dans la table est relativement petit, conduisant à un arbre B peu profond, défini avec une profondeur d’index de deux ou de trois.
Note
Même les arbres B avec une plus grande profondeur peuvent connaître une contention avec ce type de modèle d’accès si la fréquence des opérations DML et l’accès concurrentiel du système sont suffisamment élevés. Le niveau de contention de latchs peut devenir important quand les accès concurrentiels augmentent et que 16 cœurs de processeur ou plus sont disponibles pour le système.
Une contention de latchs peut se produire même si l’accès est aléatoire dans l’arbre B, par exemple quand une colonne non séquentielle est la clé de début dans un index cluster. La capture d’écran suivante provient d’un système connaissant ce type de contention de latchs. Dans cet exemple, la contention est due à la densité des pages provoquée par une petite taille de ligne et un arbre B relativement peu profond. À mesure que l’accès concurrentiel augmente, la contention de latchs sur les pages se produit même si les insertions sont aléatoires dans l’arbre B, car un GUID était la colonne de début dans l’index.
Dans la capture d’écran suivante, les attentes se produisent à la fois sur les pages de données de mémoire tampon et les pages PFS (Page Free Space). Pour plus d’informations sur la contention de verrou de page PFS, consultez le billet de blog tiers suivant sur SQLSkills : Benchmark : Plusieurs fichiers de données sur les DISQUES SSD. Même quand le nombre de fichiers de données a été augmenté, la contention de latchs était très fréquente sur les pages de données de mémoire tampon.
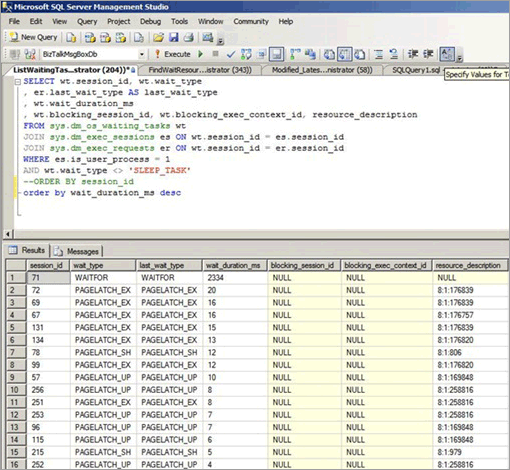
Le tableau suivant récapitule les principaux facteurs observés avec ce type de contention de latch :
| Facteur | Observations courantes |
|---|---|
| Processeurs logiques utilisés par SQL Server | La contention de latchs se produit principalement sur les ordinateurs avec 16 cœurs de processeur ou plus. |
| Conception du schéma et modèles d’accès | Modèles d’accès avec un taux élevé d’insertions/sélections/mises à jour/suppression sur de petites tables. Arbre B peu profond (profondeur d’index de deux ou trois). Petite taille des lignes (beaucoup d’enregistrements par page). |
| Niveau d’accès concurrentiel | La contention de latchs va se produire seulement sous des niveaux élevés de demandes simultanées provenant de la couche Application. |
| Type d’attente observé | Des attentes sont observées sur le latch de mémoire tampon (PAGELATCH_EX et PAGELATCH_SH) et non-mémoire tampon ACCESS_METHODS_HOBT_VIRTUAL_ROOT en raison des fractionnements de la racine. Il y a aussi des attentes PAGELATCH_UP sur les pages PFS. Pour plus d’informations sur les attentes de latchs non-mémoire tampon, consultez sys.dm_os_latch_stats (Transact-SQL) dans l’aide de SQL Server. |
La combinaison d’un arbre B peu profond et d’insertions aléatoires dans l’index est susceptible de provoquer des fractionnements de pages dans l’arbre B. Pour effectuer un fractionnement de page, SQL Server doit acquérir des latchs partagés (SH) à tous les niveaux, puis acquérir des latchs exclusifs (EX) sur les pages de l’arbre B impliquées dans les fractionnements de pages. En outre, quand l’accès concurrentiel est élevé et que des données sont insérées et supprimées continuellement, des fractionnements de la racine de l’arbre B peuvent se produire. Dans ce cas, d’autres insertions peuvent être amenées à attendre les latchs non-mémoire tampon acquis sur l’arbre B. Ceci va se manifester sous la forme d’un grand nombre d’attentes sur le type de verrou ACCESS_METHODS_HOBT_VIRTUAL_ROOT observé dans la vue de gestion dynamique sys.dm_os_latch_stats.
Le script suivant peut être modifié pour déterminer la profondeur de l’arbre B pour les index sur la table affectée.
select o.name as [table],
i.name as [index],
indexProperty(object_id(o.name), i.name, 'indexDepth')
+ indexProperty(object_id(o.name), i.name, 'isClustered') as depth, --clustered index depth reported doesn't count leaf level
i.[rows] as [rows],
i.origFillFactor as [fillFactor],
case (indexProperty(object_id(o.name), i.name, 'isClustered'))
when 1 then 'clustered'
when 0 then 'nonclustered'
else 'statistic'
end as type
from sysIndexes i
join sysObjects o on o.id = i.id
where o.type = 'u'
and indexProperty(object_id(o.name), i.name, 'isHypothetical') = 0 --filter out hypothetical indexes
and indexProperty(object_id(o.name), i.name, 'isStatistics') = 0 --filter out statistics
order by o.name;
Contention de latchs sur les pages PFS (Page Free Space)
PFS est l’acronyme Page Free Space.SQL Server alloue une page PFS pour chaque groupe de 8 088 pages (en commençant à PageID = 1) dans chaque fichier de base de données. Chaque octet de la page PFS enregistre des informations, y compris la quantité d’espace libre sur la page, si elle est allouée ou non, et si la page stocke des enregistrements fantômes. La page PFS contient des informations sur les pages disponibles pour une allocation quand une nouvelle page est requise par une opération d’insertion ou de mise à jour. La page PFS doit être mise à jour dans un certain nombre de scénarios, notamment quand une allocation ou une désallocation se produit. Comme l’utilisation d’un latch de mise à jour (UP) est nécessaire pour protéger la page PFS, une contention de latchs sur les pages PFS peut se produire si vous avez relativement peu de fichiers de données dans un groupe de fichiers et un grand nombre de cœurs de processeur. Un moyen simple de résoudre cela est d’augmenter le nombre de fichiers par groupe de fichiers.
Avertissement
Le fait d’augmenter le nombre de fichiers par groupe de fichiers peut nuire aux performances de certaines charges, comme celles qui sont soumises à de nombreuses grandes opérations de tri nécessitant un débordement de la mémoire sur le disque.
Si de nombreuses attentes PAGELATCH_UP sont observées pour les pages PFS ou SGAM dans tempdb, effectuez les étapes suivantes pour éliminer ce goulet d’étranglement :
Ajoutez des fichiers de données à tempdb afin que le nombre de fichiers de données de tempdb soit égal au nombre de cœurs de processeur de votre serveur.
Activez l’indicateur de trace SQL Server 1118.
Pour plus d’informations sur les goulots d’étranglement d’allocation provoqués par une contention sur les pages système, consultez le billet de blog What is allocation bottleneck?.
Fonctions table et contention de latchs sur tempdb
Il existe d’autres facteurs au-delà de la contention d’allocation qui peuvent entraîner une contention de latchs sur tempdb, comme une utilisation intensive de fonctions table dans les requêtes.
Gestion de la contention des latchs pour différents modèles de table
Les sections suivantes décrivent les techniques qui peuvent être utilisées pour résoudre ou contourner les problèmes de performances liés à une contention excessive de latchs.
Utiliser une clé d’index de début non séquentielle
Une manière de gérer une contention de verrous consiste à remplacer une clé d’index séquentielle par une clé non séquentielle pour distribuer uniformément les insertions dans une plage d’index.
En règle générale, cela se fait via une colonne de début dans l’index qui va distribuer la charge de travail de façon proportionnelle. Il y a ici deux options :
Option : Utiliser une colonne dans la table pour distribuer des valeurs dans la plage de clés d’index
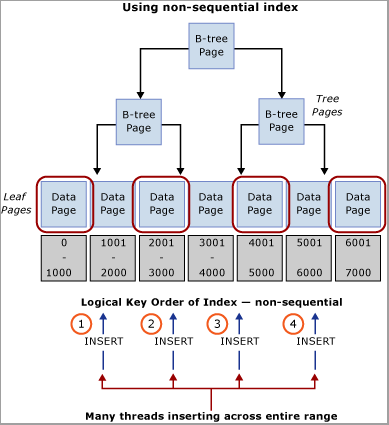
Évaluez votre charge de travail pour obtenir une valeur naturelle qui peut être utilisée pour distribuer les insertions dans la plage de clés. Prenons l’exemple d’un scénario du domaine bancaire avec un ATM, où ATM_ID peut être un bon candidat pour la distribution des insertions dans une table de transactions pour les retraits, car un client ne peut utiliser qu’un seul ATM à la fois. De même, dans un système de points de vente, il se peut que Checkout_ID ou un ID de magasin soit une valeur naturelle qui peut être utilisée pour distribuer des insertions dans une plage de clés. Cette technique nécessite la création d’une clé d’index composite dont la colonne clé de début est soit la valeur de la colonne identifiée, soit un hachage de cette valeur combinée avec une ou plusieurs colonnes supplémentaires pour assurer l’unicité. Dans la plupart des cas, un hachage de la valeur fonctionnera mieux, car un trop grand nombre de valeurs distinctes entraînent une mauvaise organisation physique. Par exemple, dans un système de points de vente, un hachage peut être créé à partir de l’ID de magasin qui est un modulo, qui s’aligne avec le nombre de cœurs de processeur. Cette technique se traduirait par un nombre relativement faible de plages dans la table. cependant, il serait suffisant de distribuer les insertions de façon à éviter les contentions de latchs. L’image suivante illustre cette technique.
Important
Ce modèle contredit les bonnes pratiques d’indexation traditionnelles. Si cette technique va permettre d’assurer la distribution uniforme des insertions dans l’arbre B, elle peut aussi nécessiter une modification du schéma au niveau de l’application. En outre, ce modèle peut nuire aux performances des requêtes nécessitant de parcourir les plages qui utilisent l’index cluster. Une analyse des modèles de charge de travail est nécessaire pour déterminer si cette approche de la conception va bien fonctionner. Ce modèle doit être implémenté si vous avez la possibilité de sacrifier les performances des parcours séquentiels pour gagner en débit et en quantité pour les insertions.
Ce modèle a été implémenté lors d’un labo consacré aux performances et il a permis de résoudre une contention de latchs sur un système avec 32 cœurs de processeur physiques. La table a été utilisée pour stocker le solde final à la fin d’une transaction ; chaque transaction commerciale effectuait une seule insertion dans la table.
Définition de table d’origine
Lors de l’utilisation de la définition de table d’origine, une contention excessive de latchs a été observée sur l’index cluster pk_table1 :
create table table1
(
TransactionID bigint not null,
UserID int not null,
SomeInt int not null
);
go
alter table table1
add constraint pk_table1
primary key clustered (TransactionID, UserID);
go
Note
Les noms d’objets dans la définition de table ont été modifiés par rapport à leurs valeurs d’origine.
Définition de l’index réorganisé
La réorganisation la colonne clé de l’index avec UserID comme colonne de début dans la clé primaire a fourni une distribution presque aléatoire des insertions dans les pages. La distribution obtenue n’était pas à 100 % aléatoire, car tous les utilisateurs ne sont pas en ligne en même temps, mais cette distribution était suffisamment aléatoire pour réduire la contention excessive de latchs. L’inconvénient de la réorganisation de la définition d’index est que toutes les requêtes SELECT sur cette table doivent être modifiées de façon à utiliser à la fois UserID et TransactionID comme prédicats d’égalité.
Important
Veillez à tester minutieusement les modifications apportées à un environnement de test avant d’exécuter dans un environnement de production.
create table table1
(
TransactionID bigint not null,
UserID int not null,
SomeInt int not null
);
go
alter table table1
add constraint pk_table1
primary key clustered (UserID, TransactionID);
go
Utilisation d’une valeur de hachage comme colonne de début dans une clé primaire
La définition de table suivante peut être utilisée pour générer un modulo qui s’aligne sur le nombre de processeurs ; HashValue est généré en utilisant la valeur de TransactionID croissant séquentiellement pour garantir une distribution uniforme dans l’arbre B :
create table table1
(
TransactionID bigint not null,
UserID int not null,
SomeInt int not null
);
go
-- Consider using bulk loading techniques to speed it up
ALTER TABLE table1
ADD [HashValue] AS (CONVERT([tinyint], abs([TransactionID])%(32))) PERSISTED NOT NULL
alter table table1
add constraint pk_table1
primary key clustered (HashValue, TransactionID, UserID);
go
Option : Utiliser un GUID comme colonne clé principale de l’index
S’il n’existe pas de séparateur naturel, une colonne de GUID peut être utilisée comme colonne clé de début de l’index pour garantir la distribution uniforme des insertions. Bien que l’utilisation du GUID comme colonne de début dans l’approche avec la clé d’index permette d’utiliser le partitionnement pour d’autres fonctionnalités, cette technique peut également introduire des inconvénients potentiels : davantage de fractionnements de pages, une organisation physique médiocre et des densités de pages faibles.
Note
L’utilisation d’un GUID comme colonnes de clé de début dans les index est un sujet donnant lieu a beaucoup de débats. Une discussion approfondie des avantages et des inconvénients de cette méthode n’entre pas dans le cadre de cet article.
Utiliser un partitionnement de hachage avec une colonne calculée
Le partitionnement de table dans SQL Server peut être utilisé pour limiter une contention excessive de latchs. La création d’un schéma de partitionnement de hachage avec une colonne calculée sur une table partitionnée est une approche courante qui peut être effectuée en suivant ces étapes :
Créez un groupe de fichiers ou utilisez un groupe de fichiers existant pour y stocker les partitions.
Si vous utilisez un nouveau groupe de fichiers, distribuez équitablement les fichiers individuels sur le numéro d’unité logique (LUN), en veillant à utiliser une disposition optimale. Si le modèle d’accès implique un taux élevé d’insertions, veillez à créer le même nombre de fichiers que de cœurs de processeur physiques sur l’ordinateur SQL Server.
Utilisez la commande CREATE PARTITION FUNCTION pour partitionner les tables en X partitions, où X est le nombre de cœurs de processeur physiques sur l’ordinateur SQL Server. (au moins 32 partitions)
Note
Un alignement 1:1 du nombre de partitions sur le nombre de cœurs de processeur n’est pas toujours nécessaire. Dans de nombreux cas, il peut s’agir d’une valeur inférieure au nombre de cœurs de processeur. Le fait de disposer d’un plus grand nombre de partitions peut entraîner une charge plus importante pour les requêtes, qui doivent effectuer une recherche dans toutes les partitions : dans ce cas, un nombre moins élevé de partitions va aider. Dans les tests de SQLCAT sur les systèmes de 64 et 128 processeurs logiques avec des charges de travail de clients réelles, un nombre de 32 partitions a été suffisant pour résoudre la contention excessive de latchs et pour atteindre les objectifs de mise à l’échelle. Au final, le nombre idéal de partitions doit être déterminé via des tests.
Utilisez la commande CREATE PARTITION SCHEME :
- Liez la fonction de partition aux groupes de fichiers.
- Ajoutez une colonne de hachage de type tinyint ou smallint à la table.
- Calculez une bonne distribution de hachage. Par exemple, utilisez hashbytes avec modulo ou binary_checksum.
L’exemple de script suivant peut être personnalisé en fonction des objectifs de votre implémentation :
--Create the partition scheme and function, align this to the number of CPU cores 1:1 up to 32 core computer
-- so for below this is aligned to 16 core system
CREATE PARTITION FUNCTION [pf_hash16] (tinyint) AS RANGE LEFT FOR VALUES
(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15);
CREATE PARTITION SCHEME [ps_hash16] AS PARTITION [pf_hash16] ALL TO ( [ALL_DATA] );
-- Add the computed column to the existing table (this is an OFFLINE operation)
-- Consider using bulk loading techniques to speed it up
ALTER TABLE [dbo].[latch_contention_table]
ADD [HashValue] AS (CONVERT([tinyint], abs(binary_checksum([hash_col])%(16)),(0))) PERSISTED NOT NULL;
--Create the index on the new partitioning scheme
CREATE UNIQUE CLUSTERED INDEX [IX_Transaction_ID]
ON [dbo].[latch_contention_table]([T_ID] ASC, [HashValue])
ON ps_hash16(HashValue);
Ce script peut être utilisé pour hacher la partition d’une table qui rencontre des problèmes provoqués par une Contention des insertions dans la dernière page/page de fin. Cette technique déplace la contention hors de la dernière page en partitionnant la table et en distribuant les insertions entre les partitions de la table avec une opération de modulo des valeurs de hachage.
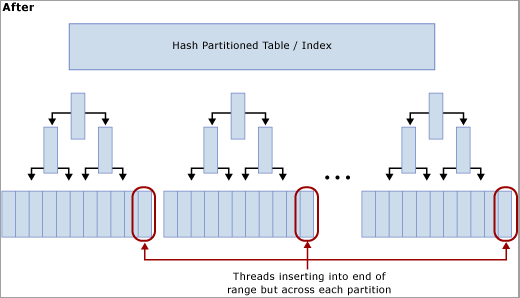
Ce que fait un partitionnement de hachage avec une colonne calculée
Comme l’illustre le diagramme suivant, cette technique déplace la contention hors de la dernière page en reconstruisant l’index sur la fonction de hachage et en créant le même nombre de partitions qu’il y a de cœurs de processeur physiques sur l’ordinateur SQL Server. Les insertions se font toujours à la fin de la plage logique (une valeur qui croît de façon séquentielle), mais l’opération de modulo de la valeur de hachage garantit que les insertions sont réparties entre les différents arbres B, ce qui réduit le problème de goulot d’étranglement. Cela est illustré dans les diagrammes suivants :
Compromis lors de l’utilisation du partitionnement de hachage
Bien que le partitionnement de hachage puisse éliminer la contention sur les insertions, plusieurs compromis sont à prendre en compte pour décider s’il faut ou non utiliser cette technique :
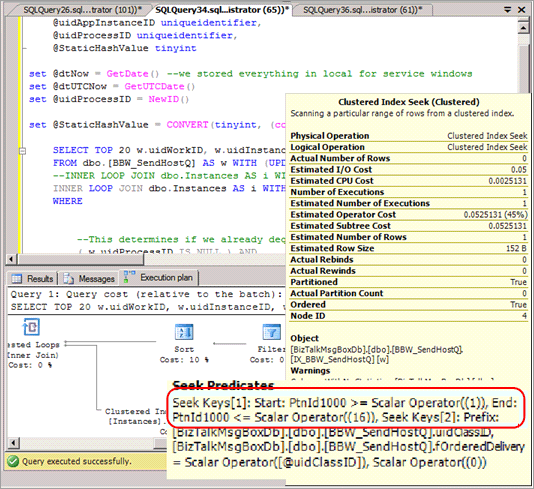
Dans la plupart des cas, les requêtes SELECT doivent être modifiées de façon à inclure la partition de hachage dans le prédicat, ce qui va aboutir à un plan de requête qui ne fournit pas d’élimination des partitions quand ces requêtes sont émises. La capture d’écran suivante montre un mauvais plan sans élimination des partitions après l’implémentation du partitionnement de hachage.
Il ne donne pas la possibilité d’éliminer les partitions sur certaines autres requêtes, comme les rapports basés sur une plage.
Lors de la jointure d’une table partitionnée par hachage à une autre table, pour obtenir l’élimination des partitions, la deuxième table doit être partitionnée par hachage sur la même clé et la clé de hachage doit faire partie des critères de la jointure.
Le partitionnement de hachage empêche l’utilisation du partitionnement pour d’autres fonctionnalités de gestion, comme l’archivage par fenêtre glissante et le basculement de partition.
Le partitionnement de hachage est une stratégie efficace pour limiter la contention excessive de latchs, car il augmente le débit global du système en réduisant la contention sur les insertions. Comme certains compromis sont impliqués, il ne s’agit pas forcément de la solution optimale pour certains modèles d’accès.
Récapitulatif des techniques utilisées pour résoudre la contention de latchs
Les deux sections suivantes fournissent un récapitulatif des techniques qui peuvent être utilisées pour résoudre la contention excessive de latchs :
Clé/index non séquentiels
Avantages :
- Permet l’utilisation d’autres fonctionnalités du partitionnement, comme l’archivage des données en utilisant un schéma de fenêtre glissante et le basculement de partition.
Inconvénients :
- Difficultés possibles pour le choix d’une clé/d’un index pour garantir en permanence une distribution la plus uniforme possible des insertions.
- Un GUID peut être utilisé comme colonne de début pour garantir une distribution uniforme, avec l’inconvénient que cela peut entraîner des opérations de fractionnement de page excessives.
- Les insertions aléatoires dans l’arbre B peuvent entraîner un trop grand nombre d’opérations de fractionnement de page et provoquer une contention de latchs sur des pages non-feuille.
Partitionnement de hachage avec une colonne calculée
Avantages :
- Transparent pour les insertions.
Inconvénients :
- Le partitionnement ne peut pas être utilisé pour certaines fonctionnalités de gestion normalement disponibles, comme l’archivage des données en utilisant des options de basculement de partition.
- Peut entraîner des problèmes d’élimination des partitions pour les requêtes, notamment les requêtes de sélection/mise à jour individuelles et basées sur une plage, et pour les requêtes qui effectuent une jointure.
- L’ajout d’une colonne calculée persistante est une opération hors connexion.
Astuce
Pour d’autres techniques, consultez le billet de blog PAGELATCH_EX waits and heavy inserts.
Procédure pas à pas : diagnostiquer une contention de verrou
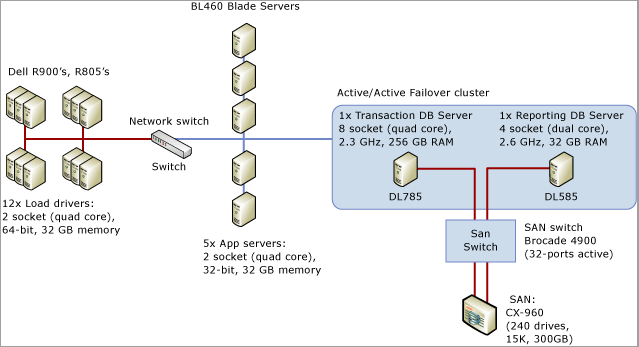
La procédure pas à pas suivante montre les outils et les techniques décrits dans Diagnostic de la contention de latchs SQL Server et Gestion de la contention des latchs pour différents modèles de table pour résoudre un problème dans un scénario réel. Ce scénario décrit un engagement client pour effectuer un test de charge d’un système de points de vente qui simulait environ 8 000 magasins effectuant des transactions sur une application SQL Server qui était exécutée sur un système à 8 sockets et 32 cœurs physiques avec 256 Go de mémoire.
Le diagramme suivant détaille le matériel utilisé pour tester le système de points de vente :
Symptôme : verrous chauds
Dans ce cas-ci, nous avons observé des attentes élevées pour PAGELATCH_EX, où nous définissons généralement « élevé » comme une moyenne supérieure à 1 ms. Ici, nous avons observé régulièrement des attentes dépassant 20 ms.
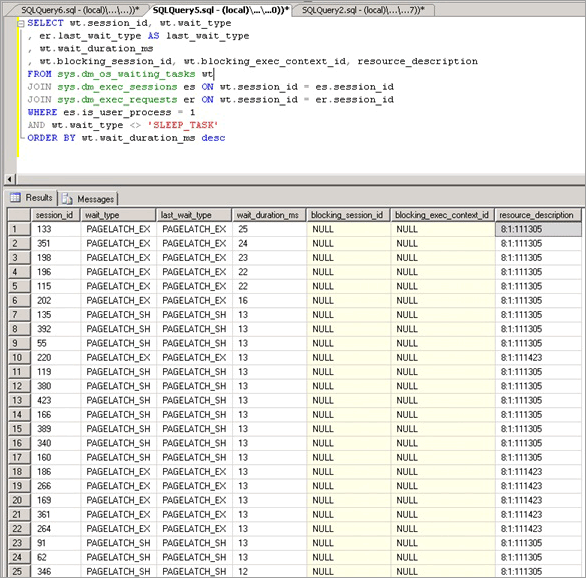
Une fois que nous avons déterminé que la contention de latchs était problématique, nous avons cherché à déterminer ce qui la provoquait.
Isolement de l’objet provoquant une contention de latchs
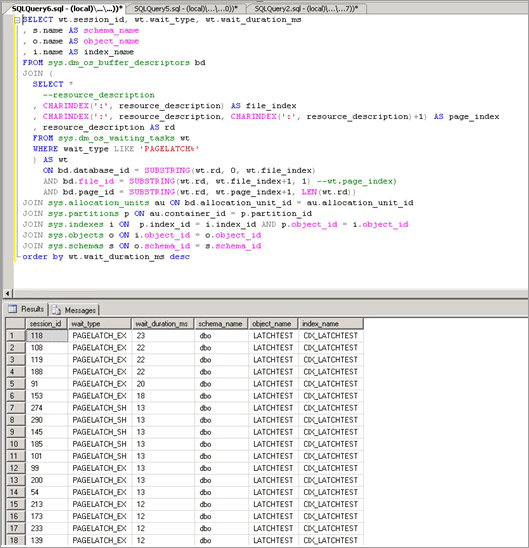
Le script suivant utilise la colonne resource_description pour isoler l’index à l’origine de la contention PAGELATCH_EX :
Note
La colonne resource_description retournée par ce script fournit la description de ressource au format <DatabaseID,FileID,PageID> où le nom de la base de données associée à DatabaseID peut être déterminé en passant la valeur de DatabaseID à la fonction DB_NAME ().
SELECT wt.session_id, wt.wait_type, wt.wait_duration_ms
, s.name AS schema_name
, o.name AS object_name
, i.name AS index_name
FROM sys.dm_os_buffer_descriptors bd
JOIN (
SELECT *
--resource_description
, CHARINDEX(':', resource_description) AS file_index
, CHARINDEX(':', resource_description, CHARINDEX(':', resource_description)+1) AS page_index
, resource_description AS rd
FROM sys.dm_os_waiting_tasks wt
WHERE wait_type LIKE 'PAGELATCH%'
) AS wt
ON bd.database_id = SUBSTRING(wt.rd, 0, wt.file_index)
AND bd.file_id = SUBSTRING(wt.rd, wt.file_index+1, 1) --wt.page_index)
AND bd.page_id = SUBSTRING(wt.rd, wt.page_index+1, LEN(wt.rd))
JOIN sys.allocation_units au ON bd.allocation_unit_id = au.allocation_unit_id
JOIN sys.partitions p ON au.container_id = p.partition_id
JOIN sys.indexes i ON p.index_id = i.index_id AND p.object_id = i.object_id
JOIN sys.objects o ON i.object_id = o.object_id
JOIN sys.schemas s ON o.schema_id = s.schema_id
order by wt.wait_duration_ms desc;
Comme indiqué ici, la contention se produit sur la table LATCHTEST et le nom d’index CIX_LATCHTEST. Notez que les noms ont été changés de façon à anonymiser la charge de travail.
Pour obtenir un script plus avancé qui interroge à plusieurs reprises et qui utilise une table temporaire pour déterminer le temps d’attente total sur une période configurable, consultez Interroger les descripteurs de mémoire tampon pour déterminer les objets à l’origine de la contention de latchs dans l’annexe.
Technique alternative pour isoler l’objet provoquant une contention de latchs
Parfois, il peut être difficile d’interroger sys.dm_os_buffer_descriptors. À mesure que la mémoire du système est augmentée et qu’elle est disponible pour le pool de mémoires tampons, le temps nécessaire à l’exécution de cette vue de gestion dynamique augmente. Sur un système avec 256 Go, jusqu’à 10 minutes ou plus peuvent être nécessaire pour l’exécution de cette vue de gestion dynamique. Une technique alternative est disponible : elle est décrite dans les grandes lignes ci-dessous et est illustrée avec une charge de travail différente, que nous avons exécutée dans le labo :
Interrogez les tâches en attente en cours en utilisant le script Interroger sys.dm_os_waiting_tasks triée par durée d’attente de l’Annexe.
Identifiez la page clé où un convoi est observé, ce qui se produit quand plusieurs threads sont en compétition sur la même page. Dans cet exemple, les threads effectuant l’insertion sont en compétition sur la page de fin de l’arbre B et attendent de pouvoir acquérir un latch EX. Ceci est indiqué par resource_description dans la première requête, soit dans notre cas 8:1:111305.
Activez l’indicateur de trace 3604, qui expose des informations supplémentaires sur la page via DBCC PAGE avec la syntaxe suivante (remplacez la valeur entre parenthèses par la valeur que vous avez obtenue via resource_description) :
--enable trace flag 3604 to enable console output dbcc traceon (3604); --examine the details of the page dbcc page (8,1, 111305, -1);Examinez la sortie de DBCC. Il doit y avoir un ObjectID de métadonnées associé, dans notre cas « 78623323 ».
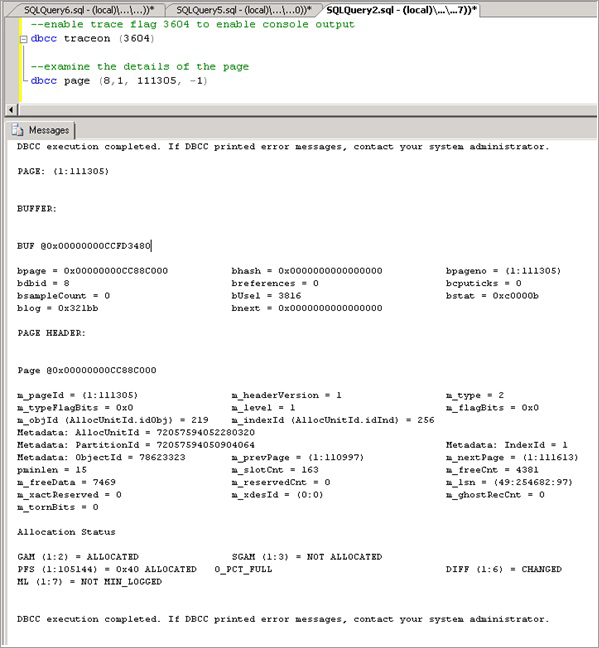
Nous pouvons maintenant exécuter la commande suivante pour déterminer le nom de l’objet à l’origine de la contention, qui est comme attendu LATCHTEST.
Note
Vérifiez que vous êtes dans le contexte de base de données approprié, sinon la requête va retourner NULL.
--get object name select OBJECT_NAME (78623323);
Récapitulatif et résultats
En utilisant la technique ci-dessus, nous avons pu vérifier que la contention se produisait sur un index cluster avec une valeur de clé croissant séquentiellement sur la table, qui recevait de loin le plus grand nombre d’insertions. Ce type de contention n’est pas rare pour les index avec une valeur de clé croissant séquentiellement, comme datetime, identité ou un transactionID généré par l’application.
Pour résoudre ce problème, nous avons utilisé le partitionnement de hachage avec une colonne calculée et nous avons observé une amélioration des performances de 690 %. Le tableau suivant récapitule les performances de l’application avant et après l’implémentation du partitionnement de hachage avec une colonne calculée. L’utilisation du processeur augmente en gros de façon linéaire avec le débit, comme attendu après la suppression du goulot d’étranglement de contention de latchs :
| Mesure | Avant le partitionnement de hachage | Après le partitionnement de hachage |
|---|---|---|
| Transactions commerciales/s | 36 | 249 |
| Temps d’attente moyen d’un latch de page | 36 millisecondes | 0,6 millisecondes |
| Attentes des latchs/s | 9 562 | 2 873 |
| Temps processeur SQL | 24 % | 78 % |
| Requêtes de lots SQL/s | 12 368 | 47 045 |
Comme le montre le tableau ci-dessus, l’identification et la résolution correctes des problèmes de performances provoqués par une contention excessive de latchs de page peuvent avoir un impact positif sur les performances globales de l’application.
Annexe : Autre technique
Une stratégie possible pour éviter une contention excessive des latchs de page consiste à compléter les lignes avec une colonne de type CHAR pour garantir que chaque ligne va utiliser une page entière. Cette stratégie est une option quand la taille globale des données est réduite et que vous devez résoudre un problème de contention excessive de latchs de page EX dus à la combinaison de facteurs suivante :
- Taille de ligne réduite
- Arbre B peu profond
- Modèle d’accès avec un taux élevé d’opérations aléatoires d’insertion, de sélection, de mise à jour et de suppression
- Tables de petite taille, comme des tables de file d’attente temporaires
En remplissant des lignes de façon à occuper une page entière, vous imposez à SQL d’allouer des pages supplémentaires, ce qui fait que plus de pages sont disponibles pour les insertions et réduit la contention de latchs de page EX.
Remplissage de lignes pour garantir que chaque ligne occupe une page entière
Un script similaire à celui-ci peut être utilisé pour remplir les lignes de façon à occuper une page entière :
ALTER TABLE mytable ADD Padding CHAR(5000) NOT NULL DEFAULT ('X');
Note
Utilisez le plus petit nombre possible de caractères forçant une ligne par page, de façon à réduire l’utilisation supplémentaire du processeur pour la valeur de remplissage et l’espace supplémentaire nécessaire pour enregistrer la ligne. Chaque octet compte dans un système à hautes performances.
Cette technique est expliquée de façon à être complet ; en pratique SQLCAT n’a utilisé cette méthode que sur une petite table avec 10 000 lignes dans un seul engagement relatif aux performances. Cette technique a une application limitée en raison du fait qu’elle augmente la sollicitation de la mémoire sur SQL Server pour les grandes tables et peut entraîner une contention de verrous non-mémoire tampon sur des pages non-feuille. La sollicitation supplémentaire de la mémoire peut être un facteur de limitation significatif pour l’application de cette technique. Avec la quantité de mémoire disponible sur un serveur moderne, une grande partie du travail pour les charges de travail OLTP se fait généralement en mémoire. Quand le jeu de données s’accroît jusqu’à une taille qui ne tient plus dans la mémoire, une baisse significative des performances va se produire. Par conséquent, cette technique est s’applique seulement aux petites tables. Cette technique n’est pas utilisée par SQLCAT pour des scénarios comme la contention des insertions sur la dernière page/page de fin pour les grandes tables.
Important
L’utilisation de cette stratégie peut entraîner un grand nombre d’attentes sur le type de verrou ACCESS_METHODS_HOBT_VIRTUAL_ROOT, car elle peut conduire à un grand nombre de divisions de page dans les niveaux non feuille de l’arbre B (B-tree). Si cela se produit, SQL Server doit acquérir des latchs partagés (SH) à tous les niveaux, suivis de latchs exclusifs (EX) sur les pages de l’arbre B où un fractionnement de page est possible. Regardez dans la vue de gestion dynamique sys.dm_os_latch_stats s’il y a un nombre élevé d’attentes sur le type de verrou ACCESS_METHODS_HOBT_VIRTUAL_ROOT après avoir procédé au remplissage des lignes.
Annexe : Scripts de contention de verrous SQL Server
Cette section contient des scripts qui peuvent être utilisés pour diagnostiquer et résoudre les problèmes de contention de latchs.
Requête sys.dm_os_waiting_tasks triée par ID de session
L’exemple de script suivant interroge sys.dm_os_waiting_tasks et retourne les attentes de verrou interne triées par ID de session :
-- WAITING TASKS ordered by session_id
SELECT wt.session_id, wt.wait_type
, er.last_wait_type AS last_wait_type
, wt.wait_duration_ms
, wt.blocking_session_id, wt.blocking_exec_context_id,
resource_description
FROM sys.dm_os_waiting_tasks wt
JOIN sys.dm_exec_sessions es ON wt.session_id = es.session_id
JOIN sys.dm_exec_requests er ON wt.session_id = er.session_id
WHERE es.is_user_process = 1
AND wt.wait_type <> 'SLEEP_TASK'
ORDER BY session_id;
Requête sys.dm_os_waiting_tasks ordonnée par durée d’attente
L’exemple de script suivant interroge sys.dm_os_waiting_tasks et retourne les attentes de verrou interne triées par durée d’attente :
-- WAITING TASKS ordered by wait_duration_ms
SELECT wt.session_id, wt.wait_type
, er.last_wait_type AS last_wait_type
, wt.wait_duration_ms
, wt.blocking_session_id, wt.blocking_exec_context_id, resource_description
FROM sys.dm_os_waiting_tasks wt
JOIN sys.dm_exec_sessions es ON wt.session_id = es.session_id
JOIN sys.dm_exec_requests er ON wt.session_id = er.session_id
WHERE es.is_user_process = 1
AND wt.wait_type <> 'SLEEP_TASK'
ORDER BY wt.wait_duration_ms desc;
Calculer les temps d’attente sur une période de temps
Le script suivant calcule et retourne les attentes de latchs sur une période de temps.
/* Snapshot the current wait stats and store so that this can be compared over a time period
Return the statistics between this point in time and the last collection point in time.
**This data is maintained in tempdb so the connection must persist between each execution**
**alternatively this could be modified to use a persisted table in tempdb. if that
is changed code should be included to clean up the table at some point.**
*/
use tempdb
go
declare @current_snap_time datetime;
declare @previous_snap_time datetime;
set @current_snap_time = GETDATE();
if not exists(select name from tempdb.sys.sysobjects where name like '#_wait_stats%')
create table #_wait_stats
(
wait_type varchar(128)
,waiting_tasks_count bigint
,wait_time_ms bigint
,avg_wait_time_ms int
,max_wait_time_ms bigint
,signal_wait_time_ms bigint
,avg_signal_wait_time int
,snap_time datetime
);
insert into #_wait_stats (
wait_type
,waiting_tasks_count
,wait_time_ms
,max_wait_time_ms
,signal_wait_time_ms
,snap_time
)
select
wait_type
,waiting_tasks_count
,wait_time_ms
,max_wait_time_ms
,signal_wait_time_ms
,getdate()
from sys.dm_os_wait_stats;
--get the previous collection point
select top 1 @previous_snap_time = snap_time from #_wait_stats
where snap_time < (select max(snap_time) from #_wait_stats)
order by snap_time desc;
--get delta in the wait stats
select top 10
s.wait_type
, (e.waiting_tasks_count - s.waiting_tasks_count) as [waiting_tasks_count]
, (e.wait_time_ms - s.wait_time_ms) as [wait_time_ms]
, (e.wait_time_ms - s.wait_time_ms)/((e.waiting_tasks_count - s.waiting_tasks_count)) as [avg_wait_time_ms]
, (e.max_wait_time_ms) as [max_wait_time_ms]
, (e.signal_wait_time_ms - s.signal_wait_time_ms) as [signal_wait_time_ms]
, (e.signal_wait_time_ms - s.signal_wait_time_ms)/((e.waiting_tasks_count - s.waiting_tasks_count)) as [avg_signal_time_ms]
, s.snap_time as [start_time]
, e.snap_time as [end_time]
, DATEDIFF(ss, s.snap_time, e.snap_time) as [seconds_in_sample]
from #_wait_stats e
inner join (
select * from #_wait_stats
where snap_time = @previous_snap_time
) s on (s.wait_type = e.wait_type)
where
e.snap_time = @current_snap_time
and s.snap_time = @previous_snap_time
and e.wait_time_ms > 0
and (e.waiting_tasks_count - s.waiting_tasks_count) > 0
and e.wait_type NOT IN ('LAZYWRITER_SLEEP', 'SQLTRACE_BUFFER_FLUSH'
, 'SOS_SCHEDULER_YIELD','DBMIRRORING_CMD', 'BROKER_TASK_STOP'
, 'CLR_AUTO_EVENT', 'BROKER_RECEIVE_WAITFOR', 'WAITFOR'
, 'SLEEP_TASK', 'REQUEST_FOR_DEADLOCK_SEARCH', 'XE_TIMER_EVENT'
, 'FT_IFTS_SCHEDULER_IDLE_WAIT', 'BROKER_TO_FLUSH', 'XE_DISPATCHER_WAIT'
, 'SQLTRACE_INCREMENTAL_FLUSH_SLEEP')
order by (e.wait_time_ms - s.wait_time_ms) desc ;
--clean up table
delete from #_wait_stats
where snap_time = @previous_snap_time;
Descripteurs de mémoire tampon de requête pour déterminer les objets à l’origine de la contention de latch
Le script suivant interroge les descripteurs de mémoire tampon pour déterminer quels sont les objets associés aux temps d’attente de latch les plus longs.
IF EXISTS (SELECT * FROM tempdb.sys.objects WHERE [name] like '#WaitResources%') DROP TABLE #WaitResources;
CREATE TABLE #WaitResources (session_id INT, wait_type NVARCHAR(1000), wait_duration_ms INT,
resource_description sysname NULL, db_name NVARCHAR(1000), schema_name NVARCHAR(1000),
object_name NVARCHAR(1000), index_name NVARCHAR(1000));
GO
declare @WaitDelay varchar(16), @Counter INT, @MaxCount INT, @Counter2 INT
SELECT @Counter = 0, @MaxCount = 600, @WaitDelay = '00:00:00.100'-- 600x.1=60 seconds
SET NOCOUNT ON;
WHILE @Counter < @MaxCount
BEGIN
INSERT INTO #WaitResources(session_id, wait_type, wait_duration_ms, resource_description)--, db_name, schema_name, object_name, index_name)
SELECT wt.session_id,
wt.wait_type,
wt.wait_duration_ms,
wt.resource_description
FROM sys.dm_os_waiting_tasks wt
WHERE wt.wait_type LIKE 'PAGELATCH%' AND wt.session_id <> @@SPID
--select * from sys.dm_os_buffer_descriptors
SET @Counter = @Counter + 1;
WAITFOR DELAY @WaitDelay;
END;
--select * from #WaitResources;
update #WaitResources
set db_name = DB_NAME(bd.database_id),
schema_name = s.name,
object_name = o.name,
index_name = i.name
FROM #WaitResources wt
JOIN sys.dm_os_buffer_descriptors bd
ON bd.database_id = SUBSTRING(wt.resource_description, 0, CHARINDEX(':', wt.resource_description))
AND bd.file_id = SUBSTRING(wt.resource_description, CHARINDEX(':', wt.resource_description) + 1, CHARINDEX(':', wt.resource_description, CHARINDEX(':', wt.resource_description) +1 ) - CHARINDEX(':', wt.resource_description) - 1)
AND bd.page_id = SUBSTRING(wt.resource_description, CHARINDEX(':', wt.resource_description, CHARINDEX(':', wt.resource_description) +1 ) + 1, LEN(wt.resource_description) + 1)
--AND wt.file_index > 0 AND wt.page_index > 0
JOIN sys.allocation_units au ON bd.allocation_unit_id = AU.allocation_unit_id
JOIN sys.partitions p ON au.container_id = p.partition_id
JOIN sys.indexes i ON p.index_id = i.index_id AND p.object_id = i.object_id
JOIN sys.objects o ON i.object_id = o.object_id
JOIN sys.schemas s ON o.schema_id = s.schema_id;
select * from #WaitResources order by wait_duration_ms desc;
GO
/*
--Other views of the same information
SELECT wait_type, db_name, schema_name, object_name, index_name, SUM(wait_duration_ms) [total_wait_duration_ms] FROM #WaitResources
GROUP BY wait_type, db_name, schema_name, object_name, index_name;
SELECT session_id, wait_type, db_name, schema_name, object_name, index_name, SUM(wait_duration_ms) [total_wait_duration_ms] FROM #WaitResources
GROUP BY session_id, wait_type, db_name, schema_name, object_name, index_name;
*/
--SELECT * FROM #WaitResources
--DROP TABLE #WaitResources;
Script de partitionnement de hachage
L’utilisation de ce script est décrite dans Utiliser un partitionnement de hachage avec une colonne calculée et doit être personnalisé en fonction des objectifs de votre implémentation.
--Create the partition scheme and function, align this to the number of CPU cores 1:1 up to 32 core computer
-- so for below this is aligned to 16 core system
CREATE PARTITION FUNCTION [pf_hash16] (tinyint) AS RANGE LEFT FOR VALUES
(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15);
CREATE PARTITION SCHEME [ps_hash16] AS PARTITION [pf_hash16] ALL TO ( [ALL_DATA] );
-- Add the computed column to the existing table (this is an OFFLINE operation)
-- Consider using bulk loading techniques to speed it up
ALTER TABLE [dbo].[latch_contention_table]
ADD [HashValue] AS (CONVERT([tinyint], abs(binary_checksum([hash_col])%(16)),(0))) PERSISTED NOT NULL;
--Create the index on the new partitioning scheme
CREATE UNIQUE CLUSTERED INDEX [IX_Transaction_ID]
ON [dbo].[latch_contention_table]([T_ID] ASC, [HashValue])
ON ps_hash16(HashValue);
Étapes suivantes
Pour plus d’informations sur les outils de supervision des performances, consultez Outils de supervision et d’optimisation des performances.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour