Segments de mémoire (tables sans index cluster)
S’applique à : ![]() SQL Server
SQL Server ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Un segment est une table sans index cluster. Un ou plusieurs index non cluster peuvent être créés sur des tables stockées comme segment. Les données sont stockées dans le segment sans spécifier d'ordre. Généralement, les données sont initialement stockées dans l’ordre dans lequel les lignes sont insérées. Toutefois, le moteur de base de données peut déplacer des données dans le segment de mémoire pour stocker les lignes efficacement. Dans les résultats de la requête, l’ordre des données ne peut pas être prédit. Pour garantir l’ordre des lignes retournées à partir d’un segment, utilisez la clause ORDER BY. Pour spécifier l’ordre logique permanent à appliquer au stockage des lignes, créez un index cluster sur la table, de sorte que celle-ci ne soit pas un segment de mémoire.
Remarque
Il existe parfois de bonnes raisons de conserver une table comme segment plutôt que de créer un index cluster, mais l'utilisation de segments est effectivement une compétence avancée. La plupart des tables doivent avoir un index cluster soigneusement choisi, à moins qu'il n'existe une bonne raison de conserver la table comme segment.
Quand utiliser un segment de mémoire ?
Un segment de mémoire est idéal pour les tables souvent tronquées et rechargées. Le moteur de base de données optimise l’espace dans un segment de mémoire en remplissant l’espace disponible le plus ancien.
Tenez compte des éléments suivants :
- La localisation de l’espace libre dans un segment de mémoire peut être coûteuse, en particulier si de nombreuses suppressions ou mises à jour ont été effectuées.
- Les index cluster offrent des performances stables pour les tables qui ne sont pas souvet tronquées.
Pour les tables qui sont régulièrement tronquées ou recréées, telles que des tables temporaires ou des tables de mise en lots, l’utilisation d’un segment de mémoire est souvent plus efficace.
Le choix entre l’utilisation d’un segment de mémoire et d’un index cluster peut affecter considérablement les performances et l’efficacité de votre base de données.
Lorsqu’une table est stockée en tant que segment de mémoire, les différentes lignes sont identifiées par référence à un identificateur de ligne (RID) de 8 octets composé d’un numéro de fichier, d’un numéro de page de données et de l’emplacement dans la page (FileID:PageID:SlotID). L’ID de ligne est une structure petite et efficace.
Les segments de mémoire peuvent être utilisés en tant que tables de mise en lots pour des opérations d’insertion volumineuses et non ordonnées. Étant donné que les données sont insérées sans appliquer un ordre strict, l’opération d’insertion est généralement plus rapide que l’insertion équivalente dans un index cluster. Si les données du segment de mémoire sont lues et traitées dans une destination finale, il peut être utile de créer un index non cluster étroit qui couvre le prédicat de recherche utilisé par la requête.
Remarque
Les données sont récupérées d’un segment de mémoire dans l’ordre des pages de données, mais pas nécessairement l’ordre dans lequel les données ont été insérées.
Parfois, les professionnels des données utilisent des segments de mémoire lorsque l’accès aux données s’effectue toujours par le biais d’index non-cluster et que le RID est plus petit que la clé d’index cluster.
Si une table est un segment de mémoire et si elle ne comprend pas d’index non-cluster, la table doit être lue dans son intégralité (analyse de table) pour trouver une ligne quelconque. SQL Server ne peut pas rechercher un RID directement dans le segment de mémoire. Ce comportement peut être acceptable si la table est petite.
Quand ne pas utiliser un segment de mémoire ?
N'utilisez pas de segment lorsque les données sont souvent retournées dans un ordre trié. Un index cluster sur la colonne de tri peut éviter l'opération de tri.
N'utilisez pas de segment lorsque les données sont souvent regroupées. Les données doivent être triées avant d'être regroupées et un index cluster sur la colonne de tri peut éviter l'opération de tri.
N'utilisez pas de segment lorsque des plages de données sont souvent interrogées pour la table. Un index cluster sur la colonne de plages évite de devoir trier le segment de mémoire entier.
N'utilisez pas de segment lorsqu'il n'y a pas d'index non cluster et que la table est grande. La seule application de cette conception consiste à retourner l’intégralité du contenu de la table, sans spécifier d’ordre. Dans un segment de mémoire, la moteur de base de données lit toutes les lignes pour trouver une ligne quelconque.
N’utilisez pas de segment de mémoire si les données sont fréquemment mises à jour. Si vous mettez à jour un enregistrement et que la mise à jour utilise plus d’espace dans les pages de données que celles-ci n’utilisent actuellement, l’enregistrement doit être déplacé vers une page de données qui dispose de suffisamment d’espace libre. Cela a pour effet de créer un enregistrement transféré pointant vers le nouvel emplacement des données. Le pointeur de transfert doit être écrit dans la page qui contenait ces données précédemment, afin d’indiquer le nouvel emplacement physique. Cela provoque la fragmentation du segment de mémoire. Lorsque le moteur de base de données analyse un segment de mémoire, il suit ces pointeurs. Cette action limite les performances de lecture anticipée et peut entraîner des E/S supplémentaires qui réduisent les performances de l’analyse.
Gérer les segments de mémoire
Pour créer un segment, créez une table sans index cluster. Si la table possède déjà un index cluster, supprimez-le afin de reconvertir la table en segment.
Pour supprimer un segment, créez un index cluster sur le segment.
Pour reconstruire un segment afin de récupérer de l’espace perdu :
- Créez un index cluster dans le segment, puis supprimez cet index.
- Utilisez la commande
ALTER TABLE ... REBUILDpour reconstruire le segment de mémoire.
Avertissement
La création ou suppression d'index cluster nécessite de réécrire la table entière. Si la table a des index non cluster, tous les index non cluster doivent être recréés à chaque fois que l'index cluster est modifié. Par conséquent, le passage d’un segment à une structure d’index cluster (ou inversement) peut prendre beaucoup de temps et nécessiter de l’espace disque pour réorganiser les données dans tempdb.
Identifier les segments de mémoire
La requête suivante retourne une liste de segments de mémoire depuis la table base de données active. La liste comprend :
- Noms de table
- Noms de schémas
- Nombre de lignes
- Taille de table en Ko
- Taille de l’index en Ko
- Espace inutilisé
- Colonne permettant d’identifier un segment de mémoire
SELECT t.name AS 'Your TableName',
s.name AS 'Your SchemaName',
p.rows AS 'Number of Rows in Your Table',
SUM(a.total_pages) * 8 AS 'Total Space of Your Table (KB)',
SUM(a.used_pages) * 8 AS 'Used Space of Your Table (KB)',
(SUM(a.total_pages) - SUM(a.used_pages)) * 8 AS 'Unused Space of Your Table (KB)',
CASE
WHEN i.index_id = 0
THEN 'Yes'
ELSE 'No'
END AS 'Is Your Table a Heap?'
FROM sys.tables t
INNER JOIN sys.indexes i
ON t.object_id = i.object_id
INNER JOIN sys.partitions p
ON i.object_id = p.object_id
AND i.index_id = p.index_id
INNER JOIN sys.allocation_units a
ON p.partition_id = a.container_id
LEFT JOIN sys.schemas s
ON t.schema_id = s.schema_id
WHERE i.index_id <= 1 -- 0 for Heap, 1 for Clustered Index
GROUP BY t.name,
s.name,
i.index_id,
p.rows
ORDER BY 'Your TableName';
Structures des segments de mémoire
Un segment est une table sans index cluster. Les segments ont une ligne dans sys.partitions, avec index_id = 0 pour chaque partition utilisée par le segment. Par défaut, un segment comporte une partition unique. Lorsqu'un segment comporte plusieurs partitions, chacune d'elles possède une structure de segment contenant les données la concernant. Par exemple, si un segment comporte quatre partitions, il y a quatre structures de segment, une dans chaque partition.
Selon les types de données du segment, chaque structure contient une ou plusieurs unités d'allocation pour stocker et gérer les données d'une partition spécifique. Chaque segment de mémoire a au minimum une unité d’allocation IN_ROW_DATA par partition. Le segment de mémoire a aussi une unité d’allocation LOB_DATA par partition s’il contient des colonnes LOB (Large Object). En outre, il a une unité d’allocation ROW_OVERFLOW_DATA par partition s’il contient des colonnes de longueur variable qui dépassent la limite de taille de ligne de 8 060 octets.
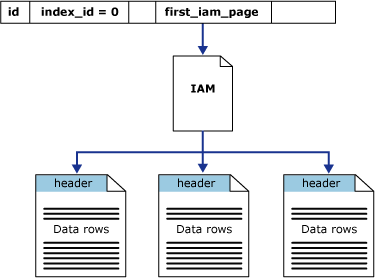
La colonne first_iam_page de la vue système sys.system_internals_allocation_units pointe vers la première page IAM de la chaîne de pages IAM gérant l’espace alloué au segment de mémoire dans une partition spécifique. SQL Server utilise les pages IAM pour se déplacer à travers le segment de mémoire. Les pages de données et les lignes qu'elles contiennent ne sont ni classées dans un ordre spécifique, ni liées. La seule connexion logique entre les pages de données concerne les informations enregistrées dans les pages IAM.
Important
La vue système sys.system_internals_allocation_units est réservée exclusivement à un usage interne de SQL Server. La compatibilité future n'est pas garantie.
Les analyses de table ou les lectures séquentielles d'un segment explorent les pages IAM pour rechercher les étendues contenant des pages pour le segment. Comme la page IAM représente les étendues dans le même ordre d'apparition que dans les fichiers de données, les analyses en série du segment s'effectuent uniformément de haut en bas de chaque fichier. L'utilisation des pages IAM pour la définition de la séquence d'analyse signifie également que les lignes du segment ne sont généralement pas retournées dans l'ordre de leur insertion.
L’illustration suivante montre comment le moteur de base de données SQL Server utilise les pages IAM pour extraire des lignes de données dans un segment de mémoire de partition unique.
Contenu associé
CREATE INDEX (Transact-SQL)
DROP INDEX (Transact-SQL)
Description des index cluster et non cluster