Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S'applique à :![]() SQL Server 2016 (13.x) et versions ultérieures
SQL Server 2016 (13.x) et versions ultérieures ![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Base de données SQL dans Microsoft Fabric
Base de données SQL dans Microsoft Fabric
La virtualisation des données vous permet d’exécuter des requêtes Transact-SQL (T-SQL) sur des données externes sans les charger dans votre base de données. PolyBase est la fonctionnalité moteur de base de données qui implémente la virtualisation des données dans SQL Server et Azure SQL. Vous définissez une source de données externe, un format de fichier facultatif et une table externe, puis interrogez la table externe comme SELECT n’importe quelle autre table.
Ce guide vous aide à :
- Découvrez les fonctionnalités de PolyBase pour votre plateforme SQL et la prise en charge des versions.
- Choisissez entre
OPENROWSETles tables externes etBULK INSERTpour interroger ou ingérer des données. - Suivez les liens pas à pas pour les scénarios courants.
- Passez en revue les performances, la résolution des problèmes et les meilleures pratiques pour les charges de travail de production.
Cas d’utilisation courants
Le tableau suivant décrit les scénarios d’utilisation possibles.
| Scénario | Utilisation |
|---|---|
| Exploration de fichiers ad hoc | OPENROWSET(BULK ...) |
| Interrogation de fichiers réutilisables pour la BI/Reporting | Tables externes sur des fichiers |
| Interrogation inter-bases de données (SQL Server, Oracle, Teradata, MongoDB, ODBC) | Connecteurs PolyBase avec des tables externes |
| Exportation des résultats de la requête vers des fichiers |
CREATE EXTERNAL TABLE AS SELECT (CETAS) |
| Ingestion en bloc dans des tables |
BULK INSERT ou OPENROWSET(BULK ...) avec INSERT ... SELECT |
Quelles fonctionnalités sont disponibles à quel endroit ?
Le tableau suivant indique les principales fonctionnalités de virtualisation de données et PolyBase disponibles sur chaque plateforme SQL. Utilisez ce tableau pour déterminer ce que vous pouvez faire sur votre plateforme avant d’utiliser les guides détaillés.
| Fonctionnalité | SQL Server 2019 | SQL Server 2022 | SQL Server 2025 | Azure SQL Database | Azure SQL Managed Instance (Instance gérée Azure SQL) | Base de données SQL dans Microsoft Fabric |
|---|---|---|---|---|---|---|
| tables externes | Oui | Oui | Oui | Oui | Oui | Oui |
| OPENROWSET (BULK) | Oui 1 | Oui | Oui | Oui | Oui | Oui |
| CETAS (exportation) | Non | Oui | Oui | Non | Oui | Non |
| Fichiers CSV / délimités | Oui 2 | Oui | Oui | Oui | Oui | Oui |
| Fichiers Parquet | Non | Oui | Oui | Oui | Oui | Oui |
| Tables Delta Lake | Non | Oui | Oui | Non | Non | Non |
| Se connecter à un autre serveur SQL Server | Oui | Oui | Oui | Non | Non | Non |
| Se connecter à Azure SQL Database ou Azure SQL Managed Instance | Oui 3 | Oui 3 | Oui 3 | Non | Non | Non |
| Se connecter à Oracle / Teradata / MongoDB | Oui | Oui | Oui | Non | Non | Non |
| Se connecter à Stockage Blob Azure | Oui | Oui | Oui | Oui | Oui | Non |
| Se connecter à ADLS Gen2 | Non | Oui | Oui | Oui | Oui | Non |
| Se connecter au stockage compatible S3 | Non | Oui | Oui | Non | Non | Non |
| Se connecter à OneLake (Fabric) | Non | Non | Non | Non | Non | Oui |
| Calcul pushdown | Oui | Oui | Oui | Non | Non | Non |
| Authentification d’identité managée | Non | Non | Oui 4 | Oui | Oui | Non |
1 SQL Server 2019 (15.x) prend en charge OPENROWSET(BULK...) les chemins de fichiers locaux et réseau. Dans SQL Server 2022 (16.x) et versions ultérieures, OPENROWSET(BULK...) prend également en charge la lecture à partir du stockage cloud avec FORMAT = 'PARQUET', FORMAT = DELTAet FORMAT = 'CSV'.
La prise en charge des fichiers CSV par 2 dans SQL Server 2019 (15.x) nécessitait Hadoop. Dans SQL Server 2022 (16.x) et versions ultérieures, CSV est pris en charge en mode natif sans Hadoop.
3 Utilise le connecteur SQL Server (sqlserver://). Les informations d'identification spécifiques à la base de données ciblent l'endpoint Azure SQL, suivant les mêmes étapes que pour se connecter à un autre serveur SQL.
4 L’authentification par Identité managée est prise en charge pour la connexion au stockage Blob Azure (ABS) et à ADLS Gen2. Il nécessite SQL Server activé par Azure Arc ou SQL Server sur une machine virtuelle Azure pour la gestion de SQL Server sur site. Il est disponible en mode natif sur Azure SQL Database et Azure SQL Managed Instance.
Note
À compter de SQL Server 2025 (17.x), l’interrogation de fichiers de données (CSV, Parquet et Delta) sur stockage Blob Azure, ADLS Gen2 ou S3 est une fonctionnalité de moteur native et ne nécessite plus l’installation ou l’exécution de services PolyBase. Les connecteurs SGBDR (SQL Server, Oracle, Teradata, MongoDB, ODBC) nécessitent toujours l’installation et l’exécution des services PolyBase. SQL Server 2025 (17.x) ajoute également la prise en charge linux de ces connecteurs, qui étaient précédemment disponibles sur Windows uniquement.
Interroger des données externes
Avant de choisir un scénario spécifique, comprenez les trois façons d’interroger des données externes :
| Approche | Syntaxe | À utiliser lorsque | Authentification | PolyBase requis |
|---|---|---|---|---|
| Requêtes ad hoc OLE DB | OPENROWSET(provider, connection, query) |
Vous souhaitez une requête ponctuelle rapide sans objets persistants ou vous avez besoin de l’authentification Microsoft Entra ID | Authentification SQL, authentification Windows, Microsoft Entra ID (MSOLEDBSQL) | Non |
| Déposer des requêtes ad hoc | OPENROWSET(BULK ...) |
Vous souhaitez explorer rapidement ou tester des schémas de fichiers avant de créer une table | Jeton SAP, clé d’accès, Identité managée, ID Microsoft Entra | Oui pour Azure SQL Database et Azure SQL Managed Instance Non pour les instances SQL Server |
| Connecteurs de données persistantes |
CREATE EXTERNAL TABLE avec sqlserver://, oracle://, teradata://, etc. |
Vous avez besoin d’un accès récurrent, d’une gouvernance, d’une statistique et d’un calcul pushdown pour la production | Authentification SQL uniquement | Oui |
Les services PolyBase sont requis pour l’accès aux fichiers cloud dans SQL Server 2019 (15.x) et SQL Server 2022 (16.x). SQL Server 2025 (17.x) et versions ultérieures prennent en charge nativement CSV, Parquet et Delta sans PolyBase.
Guide de décision
| Scénario | Recommandation |
|---|---|
| J’ai besoin de l’authentification d’ID Microsoft Entra pour SQL distant ou souhaite éviter les services PolyBase | Utiliser OPENROWSET(MSOLEDBSQL, ...) (ad hoc, aucun objet persistant) |
| J’ai besoin de tables, de statistiques ou de calculs pushdown persistants vers des bases de données distantes | Utiliser CREATE EXTERNAL TABLE avec des connecteurs PolyBase (sqlserver://, , oracle://teradata://, mongodb://, odbc://).
OPENROWSET ne prend pas en charge les connecteurs |
| J’explore un nouveau fichier ou teste un schéma | Utiliser OPENROWSET(BULK ...) (itération rapide, aucun objet persistant) |
| J'ingère les données d'un fichier dans une table avec des transformations | Utiliser INSERT ... SELECT à partir de OPENROWSET(BULK ...) |
| J’ai besoin d’un accès partagé ou de gouvernance pour de nombreux utilisateurs ou applications | Utiliser CREATE EXTERNAL TABLE pour que les autorisations et les métadonnées soient centralisées |
| Je travaille dans une base de données SQL dans Fabric | Utilisez OPENROWSET(BULK ...) pour des requêtes OneLake ad hoc ou des tables externes afin d'obtenir un accès réutilisable ; pour le stockage externe, utilisez les raccourcis OneLake. |
Choisir votre scénario
Maintenant que vous comprenez les trois approches, utilisez l’un des guides suivants pour implémenter votre cas d’usage spécifique.
Fichiers de requête (Parquet, CSV ou Delta)
Si vos données se trouvent dans des fichiers Parquet, CSV ou Delta sur stockage Blob Azure, ADLS Gen2, stockage compatible S3 ou OneLake, suivez l’un des guides suivants :
| Scénario | Guide recommandé | Platforms |
|---|---|---|
| Requête ad hoc rapide sur un fichier Parquet ou CSV | Utilisez OPENROWSET. Aucune table externe n’est nécessaire |
SQL Server 2022 (16.x) et versions ultérieures, Azure SQL Database, Azure SQL Managed Instance, SQL Database dans Fabric |
| Requêtes répétées sur des fichiers Parquet avec un schéma persistant | Créer une table externe avec Parquet | SQL Server 2022 (16.x) et versions ultérieures, Azure SQL Database, Azure SQL Managed Instance, SQL Database dans Fabric |
| Interroger des fichiers CSV avec une table externe | Créer une table externe avec un format de fichier pour le texte délimité | SQL Server 2019 (15.x) et versions ultérieures, Azure SQL Database, Azure SQL Managed Instance, SQL Database dans Fabric |
| Interroger des tables Delta Lake | Créer une table externe avec FILE_FORMAT = DeltaLakeFileFormat |
SQL Server 2022 (16.x) et versions ultérieures |
| Exporter les résultats des requêtes vers des fichiers Parquet ou CSV (CETAS) | Utilisez CREATE EXTERNAL TABLE AS SELECT. |
SQL Server 2022 (16.x) et versions ultérieures, Azure SQL Managed Instance |
Vous pouvez également suivre l’un des didacticiels pas à pas suivants :
| Tutoriel | Description |
|---|---|
| Démarrer avec PolyBase dans SQL Server 2022 | Couvre OPENROWSET avec Parquet et CSV, les tables externes et la navigation dans les dossiers. |
| Virtualiser un fichier Parquet dans un stockage d’objets compatible S3 avec PolyBase | Tutoriel pour SQL Server 2022 (16.x) et versions ultérieures. |
| Virtualiser un fichier CSV avec PolyBase | Tutoriel pour SQL Server 2022 (16.x) et versions ultérieures. |
| Virtualiser une table delta avec PolyBase | Tutoriel pour SQL Server 2022 (16.x) et versions ultérieures. |
| Virtualisation des données avec Azure SQL Database (préversion) | Guide Azure SQL Database pour Parquet et CSV. |
| Virtualisation des données avec Azure SQL Managed Instance | Guide Azure SQL Managed Instance pour Parquet, CSV et CETAS. |
| Virtualisation des données dans une base de données SQL dans Fabric | Base de données SQL dans Fabric guide pour les fichiers OneLake. |
Se connecter à une autre instance SQL Server, Azure SQL Database ou SQL Managed Instance
Dans SQL Server 2019 (15.x) et versions ultérieures, PolyBase peut interroger des tables dans une autre instance SQL Server, Azure SQL Database ou Azure SQL Managed Instance, sans utiliser de serveurs liés.
Important
Le sqlserver:// connecteur n’est pas pris en charge dans la base de données SQL dans Fabric. Les connecteurs SGBDR PolyBase utilisent l’authentification SQL via CREATE DATABASE SCOPED CREDENTIAL et ne prennent pas en charge l’authentification Microsoft Entra ID, Managed Identity ou service principal. Étant donné que la base de données SQL dans Fabric nécessite l’authentification Microsoft Entra, vous ne pouvez pas vous y connecter à l’aide de PolyBase.
| Étape | Procédure à suivre |
|---|---|
| 1. Installer PolyBase | Installer PolyBase sur Windows ou installer PolyBase sur Linux |
| 2. Créer un identifiant |
CREATE DATABASE SCOPED CREDENTIAL avec la connexion cible |
| 3. Créer une source de données externe | CREATE EXTERNAL DATA SOURCE ... WITH (LOCATION = 'sqlserver://<server>') |
| 4. Créer une table externe | CREATE EXTERNAL TABLE ... WITH (LOCATION = '<db>.<schema>.<table>') |
| 5. Requête | SELECT * FROM <external_table> |
Conseil / Astuce
Le connecteur SQL Server (sqlserver://) fonctionne également pour Azure SQL Database et Azure SQL Managed Instance. Utilisez les mêmes étapes et définissez LOCATION le point de terminaison Azure SQL (par exemple). sqlserver://myserver.database.windows.net
Pour obtenir un guide détaillé, consultez Configurer PolyBase pour accéder aux données externes dans SQL Server.
Se connecter à Oracle, Teradata ou MongoDB
SQL Server 2019 (15.x) et versions ultérieures peuvent interroger Oracle, Teradata, MongoDB et Cosmos DB via des connecteurs ODBC PolyBase.
| Source de données | Guide | Exigences |
|---|---|---|
| Oracle | Configurer PolyBase pour accéder à des données externes dans Oracle | SQL Server 2019 (15.x) et versions ultérieures, pilotes clients Oracle |
| Teradata | Configurer PolyBase pour accéder à des données externes dans Teradata | SQL Server 2019 (15.x) et versions ultérieures, pilote ODBC Teradata |
| MongoDB / Cosmos DB | Configurer PolyBase pour accéder à des données externes dans MongoDB | SQL Server 2019 (15.x) et versions ultérieures, pilote ODBC MongoDB |
| N’importe quelle source ODBC | Configurer PolyBase pour accéder à des données externes avec des types génériques ODBC | SQL Server 2019 (15.x) et versions ultérieures (Windows) (Linux commençant par SQL Server 2025 (17.x)) |
Se connecter à Stockage Blob Azure ou à Azure Data Lake Storage Gen2
| Plateforme SQL | Options d’authentification | Guide |
|---|---|---|
| SQL Server 2022 (16.x) et versions ultérieures | Jeton SAS, clé d’accès, Identité managée (à compter de SQL Server 2025 (17.x)) | Configurer PolyBase pour accéder aux données externes dans Stockage Blob Azure |
| SQL Server 2019 (15.x) | Clé d’accès (via le connecteur Hadoop) | Configurer PolyBase pour accéder aux données externes dans Stockage Blob Azure |
| Azure SQL Database | Jeton SAP, Identité managée, Microsoft Entra pass-through | Virtualisation des données avec Azure SQL Database (préversion) |
| Azure SQL Managed Instance (Instance gérée Azure SQL) | Jeton SAP, Identité managée | Virtualisation des données avec Azure SQL Managed Instance |
Dans SQL Server 2022 (16.x), les préfixes d’URI ont changé. Lors de la migration à partir de SQL Server 2019 (15.x) ou des versions antérieures :
-
Stockage Blob Azure : définir
wasb[s]://surabs:// -
ADLS Gen2 : Passer
abfs[s]://àadls://
Pour plus d’informations, consultez Configurer PolyBase pour accéder aux données externes dans Stockage Blob Azure.
Se connecter au stockage d’objets compatible avec S3
SQL Server 2022 (16.x) et versions ultérieures prennent en charge le stockage compatible S3, tel qu’Amazon S3, MinIO et Ceph.
Pour plus d’informations, consultez Configurer PolyBase pour accéder aux données externes dans le stockage d’objets compatible S3.
Exporter des données avec CREATE EXTERNAL TABLE AS SELECT (CETAS)
CETAS exporte les résultats des requêtes vers des fichiers externes (Parquet ou CSV) dans stockage Blob Azure, ADLS Gen2 ou stockage compatible S3.
| Plateforme SQL | Soutenu | Formats d’exportation | Remarques |
|---|---|---|---|
| SQL Server 2022 (16.x) et versions ultérieures | Oui | Parquet, CSV | Configuration requise du serveur : autoriser l’exportation polybase |
| Azure SQL Managed Instance (Instance gérée Azure SQL) | Oui | Parquet, CSV | Désactivé par défaut |
| Azure SQL Database | Non | Aucun | Non disponible |
| Base de données SQL dans Fabric | Non | Aucun | Non disponible |
Pour obtenir la référence Transact-SQL, consultez CREATE EXTERNAL TABLE AS SELECT (CETAS).
Exemples de démarrage rapide
Exemple 1 : Requête ad hoc sur un fichier Parquet (OPENROWSET)
Aucune table externe n’est nécessaire. Fonctionne sur SQL Server 2022 (16.x) et versions ultérieures, Azure SQL Database, Azure SQL Managed Instance et SQL Database dans Fabric.
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet',
FORMAT = 'PARQUET'
) AS [result];
Exemple 2 : Table externe de données en format CSV dans le Stockage Blob Azure
Cet exemple fonctionne sur toutes les plateformes SQL qui prennent en charge PolyBase.
Étape 1 : Créer une clé principale de base de données (DMK). Cette étape est requise, car les informations d’identification stockent le secret d'un jeton SAS. Toutefois, vous pouvez effectuer cette étape si vous utilisez l’authentification Managed Identity ou Microsoft Entra.
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<strong_password>';Étape 2 : Créer des informations d’identification avec un jeton SAP. Omettez le premier
?.CREATE DATABASE SCOPED CREDENTIAL MyStorageCred WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = '<your_SAS_token>'; -- omit the leading '?'Étape 3 : Créer une source de données externe.
CREATE EXTERNAL DATA SOURCE MyAzureStorage WITH ( LOCATION = 'abs://mycontainer@mystorageaccount.blob.core.windows.net', CREDENTIAL = MyStorageCred );Étape 4 : Créer un format de fichier pour le fichier CSV.
CREATE EXTERNAL FILE FORMAT CsvFormat WITH ( FORMAT_TYPE = DELIMITEDTEXT, FORMAT_OPTIONS ( FIELD_TERMINATOR = ',', STRING_DELIMITER = '"', FIRST_ROW = 2 ) );Étape 5 : Créer la table externe.
CREATE EXTERNAL TABLE dbo.SalesExternal ( OrderId INT, OrderDate DATE, Amount DECIMAL (18, 2), Customer NVARCHAR (100) ) WITH ( DATA_SOURCE = MyAzureStorage, LOCATION = '/data/sales/', FILE_FORMAT = CsvFormat );Étape 6 : Interroger la table externe.
SELECT * FROM dbo.SalesExternal WHERE OrderDate >= '2025-01-01';
Exemple 3 : Interroger une table dans un autre serveur SQL Server
Cet exemple fonctionne sur SQL Server 2019 (15.x) et les versions ultérieures.
Étape 1 : Créez une clé principale de base de données (obligatoire, car les informations d’identification stockent un mot de passe).
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<strong_password>';Étape 2 : Créez des informations d’identification pour l’instance SQL Server distante.
CREATE DATABASE SCOPED CREDENTIAL RemoteSqlCred WITH IDENTITY = 'remote_user', SECRET = '<password>';Étape 3 : Créer la source de données externe.
CREATE EXTERNAL DATA SOURCE RemoteSqlServer WITH ( LOCATION = 'sqlserver://remote-server.contoso.com', PUSHDOWN = ON, CREDENTIAL = RemoteSqlCred );Étape 4 : Créer la table externe (nom en trois parties dans
LOCATION).CREATE EXTERNAL TABLE dbo.RemoteCustomers ( CustomerId INT, CustomerName NVARCHAR (200) COLLATE SQL_Latin1_General_CP1_CI_AS ) WITH ( DATA_SOURCE = RemoteSqlServer, LOCATION = 'SalesDB.dbo.Customers' );Étape 5 : Interroger sur plusieurs serveurs.
SELECT c.CustomerName, s.Amount FROM dbo.RemoteCustomers AS c INNER JOIN dbo.LocalSales AS s ON c.CustomerId = s.CustomerId;
Exemple 4 : Exporter des résultats vers Parquet avec CETAS
Fonctionne sur SQL Server 2022 (16.x) et versions ultérieures, Azure SQL Managed Instance.
Étape 1 : Activer CETAS (SQL Server uniquement).
EXECUTE sp_configure 'allow polybase export', 1; RECONFIGURE;Étape 2 : Créer des informations d’identification et une source de données (réutilisation à partir d’exemples précédents).
Étape 3 : créer un format de fichier pour l’exportation Parquet.
CREATE EXTERNAL FILE FORMAT ParquetFormat WITH ( FORMAT_TYPE = PARQUET );Étape 4 : Exporter les résultats de la requête.
CREATE EXTERNAL TABLE dbo.Sales2025Export WITH ( DATA_SOURCE = MyAzureStorage, LOCATION = '/exports/sales_2025.parquet', FILE_FORMAT = ParquetFormat ) AS SELECT * FROM Sales.Orders WHERE OrderDate >= '2025-01-01';
Blocs de construction T-SQL pour PolyBase
Avant d’implémenter un scénario, comprenez les objets T-SQL principaux que PolyBase utilise et comment ils s’intègrent :
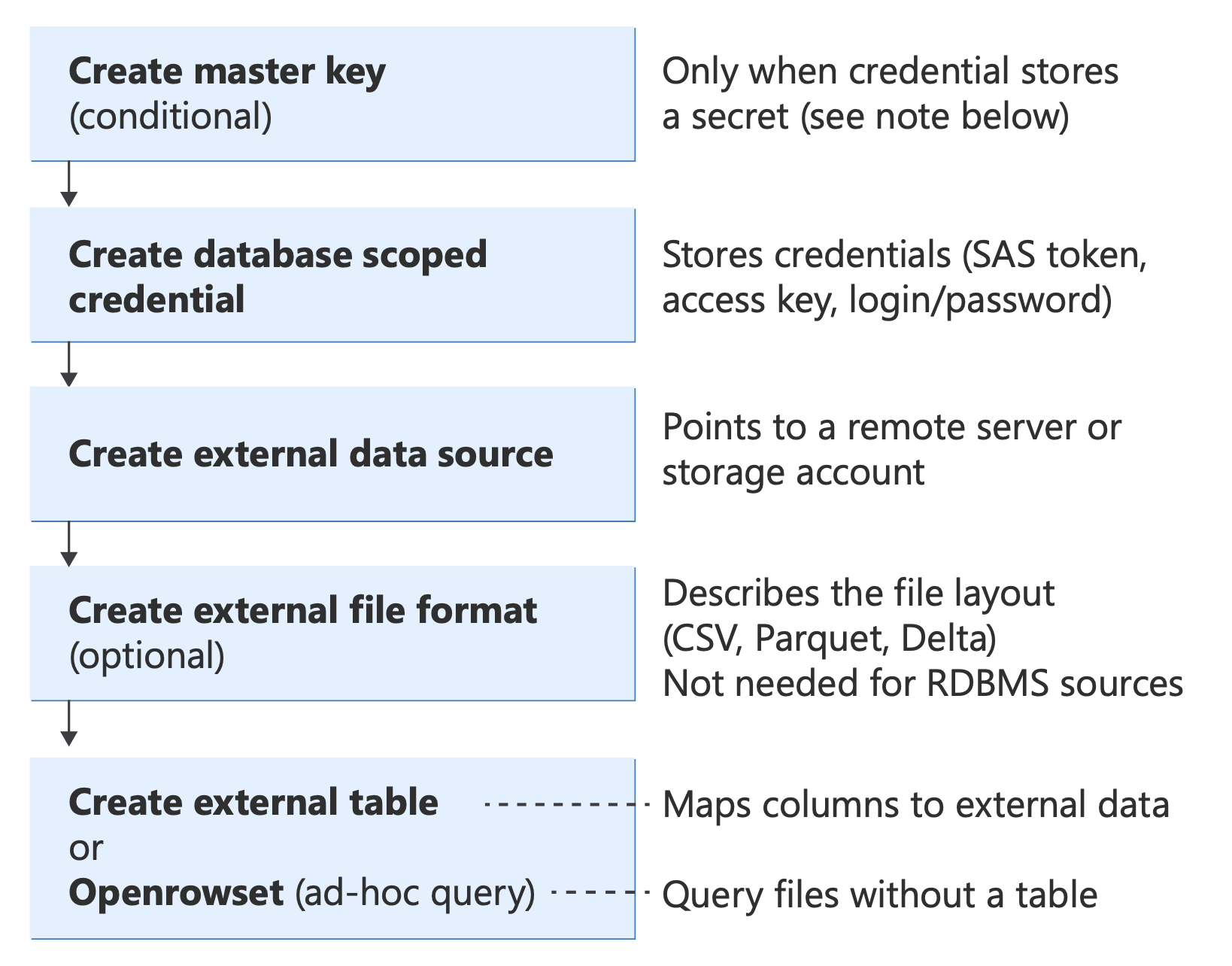
Schéma illustrant les objets T-SQL de PolyBase et leurs relations, depuis l’authentification (clé principale de la base de données, informations d’identification) jusqu’aux méthodes d’interrogation (table externe, OPENROWSET, BULK INSERT, CETAS), en passant par les sources de données et les formats de fichiers.
Pour plus d’informations sur ces instructions T-SQL, consultez :
- CREATE EXTERNAL DATA SOURCE
- CREATE EXTERNAL FILE FORMAT
- CREATE EXTERNAL TABLE
- OPENROWSET
- CREATE EXTERNAL TABLE AS SELECT (CETAS)
Pour obtenir une référence complète Transact-SQL pour tous les objets, consultez la référence Transact-SQL PolyBase.
Important
Vérifiez le mappage de type de données pour votre format de fichier externe. Lorsque vous créez un format de fichier externe ou interrogez des fichiers à l’aide OPENROWSETde , PolyBase mappe automatiquement les types de données sources (Parquet, CSV, Delta, Oracle, Teradata, MongoDB) aux types de données SQL Server. Les types incompatibles peuvent entraîner une troncation silencieuse, une perte de précision ou des erreurs de requête. Par exemple, un Parquet DECIMAL(38,18) se mappe à DECIMAL(18,0). Passez en revue les tables de mappage avant de définir des colonnes de table externes ou une WITH clause. Pour obtenir la référence complète, consultez Mappage de type avec PolyBase.
Quand est CREATE MASTER KEY nécessaire ?
Une clé principale de base de données (DMK) est créée à l’aide CREATE MASTER KEY de la syntaxe. Le DMK chiffre les secrets stockés dans les identifiants de portée de base de données. Elle n’est requise que lorsque les informations d’identification contiennent une valeur secrète, c’est-à-dire lorsqu’elle stocke un mot de passe, un jeton ou une clé d’accès.
Le DMK est requis (les identifiants contiennent un secret) :
Type d’authentification Valeur IDENTITYPossède un secret DMK Jeton SAS 'SHARED ACCESS SIGNATURE'Oui Obligatoire Clé d'accès S3 'S3 ACCESS KEY'Oui Obligatoire Connexion SQL / authentification de base '<username>'Oui Obligatoire Clé d’accès au compte de stockage '<storage_account_name>'Oui Obligatoire Le DMK n’est pas obligatoire (aucun secret stocké) :
Type d’authentification Valeur IDENTITYPossède un secret DMK Identité gérée 'Managed Identity'Non Non requis Microsoft Entra ID (système d'identification de Microsoft) 'User Identity'ou'Managed Identity'Non Non requis
Conseil / Astuce
S’il n’y a pas de secret dans votre CREATE DATABASE SCOPED CREDENTIAL instruction, vous n’avez pas besoin d’une DMK. Identité managée et authentification Microsoft Entra ID délèguent la confiance à la plateforme. La base de données ne stocke pas les mots de passe ou les jetons.
Exemples :
Dans cet exemple de requête, le DMK est requis (Les informations d’identification stockent un jeton SAP).
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<strong_password>';
CREATE DATABASE SCOPED CREDENTIAL SasCred
WITH IDENTITY = 'SHARED ACCESS SIGNATURE',
SECRET = '<your_SAS_token>';
Dans cet exemple de requête, le DMK n’est pas obligatoire (Identité managée, aucun secret).
CREATE DATABASE SCOPED CREDENTIAL ManagedIdentityCred
WITH IDENTITY = 'Managed Identity';
Dans cet exemple de requête, le DMK n’est pas obligatoire (pass-through Microsoft Entra, aucun secret).
CREATE DATABASE SCOPED CREDENTIAL EntraIdCred
WITH IDENTITY = 'User Identity';
Accès aux données à distance avec OPENROWSET et tables externes
SQL Server offre trois approches distinctes pour interroger des données distantes. Vous pouvez choisir la bonne approche lorsque vous comprenez les différences de syntaxe, d’authentification et d’architecture.
| Approche | Syntaxe | Se connecte au | Authentification | Services PolyBase | Platforms |
|---|---|---|---|---|---|
| Requêtes OLE DB | OPENROWSET(provider, connection, query) |
Toute source OLE DB via MSOLEDBSQL, SQLOLEDB ou d’autres fournisseurs | Authentification SQL, authentification Windows, Microsoft Entra ID (MSOLEDBSQL) | Non | SQL Server (toutes les versions prises en charge) |
| Requêtes de fichiers | OPENROWSET(BULK ...) |
Fichiers sur un disque local, un réseau ou un cloud (Blob Azure, ADLS, S3, OneLake) | Jeton SAP, clé d’accès, Identité managée, ID Microsoft Entra | Oui pour le cloud* ; Non pour local | SQL Server 2005 ; SQL Server 2022 (16.x) et versions ultérieures (cloud) ; Azure SQL |
| Connecteurs PolyBase |
CREATE EXTERNAL TABLE avec CREATE EXTERNAL DATA SOURCE l’utilisation de sqlserver://, oracle://, teradata://, mongodb://, odbc:// |
Serveur SQL distant, Oracle, Teradata, MongoDB, sources ODBC | Authentification SQL uniquement | Oui | SQL Server 2019 (15.x) et versions ultérieures (Windows) ; SQL Server 2025 (17.x) et versions ultérieures (Linux) |
Les services PolyBase sont requis pour l’accès aux fichiers cloud dans SQL Server 2019 (15.x) et SQL Server 2022 (16.x). SQL Server 2025 (17.x) et versions ultérieures prennent en charge les fichiers cloud natifs et ne nécessitent plus PolyBase pour CSV, Parquet ou Delta.
Quand utiliser chaque approche
Utilisez OLE DB OPENROWSET pour :
- Requêtes ad hoc rapides et ponctuelles sans créer d’objets persistants
- Authentification Microsoft Entra ID ou Managed Identity (via MSOLEDBSQL)
- Éviter les dépendances de service PolyBase
- Connexion à n’importe quelle source de données avec un fournisseur OLE DB
Utilisez le fichier OPENROWSET(BULK) pour :
- Exploration de fichiers ad hoc et découverte de schémas
- Transformations rapides et aperçus avant de valider une définition de table
- Transformations flexibles de colonnes en ligne (conversion de type, filtrage, colonnes calculées)
- Données qui ne changent pas fréquemment et n’ont pas besoin de métadonnées persistantes
Utilisez les connecteurs PolyBase avec CREATE EXTERNAL TABLE pour :
- Définitions de table persistantes et réutilisables accessibles par plusieurs utilisateurs ou applications
- Charges de travail de production nécessitant des statistiques et une optimisation du plan de requête
- Calcul pushdown vers des sources distantes (filtres délégués vers Oracle, SQL Server, etc.)
- Gouvernance et sécurité partagées (une fois créés, les utilisateurs ont uniquement besoin
SELECTd’autorisations) - Lorsque vous disposez d’une authentification SQL disponible pour la source distante
OPENROWSET (OLE DB) - requêtes distantes ad hoc (aucun service PolyBase n’est requis)
La forme OLE DB de OPENROWSET se connecte à une source de données distante via un fournisseur OLE DB, exécute une requête directe et retourne les résultats sous forme d’ensemble de lignes. Il s’agit d’une alternative ponctuelle et ad hoc à un serveur lié. Aucune métadonnées persistantes ne sont créées. Cette syntaxe ne nécessite pas de services PolyBase et ne prend pas en charge les fichiers cloud ou les sources de données externes.
Cet exemple de requête se connecte à un serveur SQL Server distant via OLE DB (et non PolyBase).
SELECT *
FROM OPENROWSET (
'MSOLEDBSQL',
'Server=remote-server;Database=AdventureWorks;Trusted_Connection=yes;',
'SELECT TOP 10 * FROM AdventureWorks.Sales.SalesOrderHeader'
);
OPENROWSET(BULK) - Requêtes basées sur des fichiers (PolyBase)
La forme BULK de OPENROWSET lit les données directement depuis les fichiers. Sur SQL Server 2019 (15.x) et les versions antérieures, il lit à partir des chemins de fichier local ou UNC et nécessite un fichier de format. Dans SQL Server 2022 (16.x) et versions ultérieures, vous pouvez lire à partir du stockage cloud en utilisant les paramètres DATA_SOURCE et FORMAT. Cette approche est la version intégrée à PolyBase utilisée pour la virtualisation des données.
Dans le contexte de PolyBase et de la virtualisation des données, lorsque ce guide fait référence à OPENROWSET, cela désigne la syntaxe OPENROWSET(BULK ...) avec une clause FORMAT pour interroger des fichiers externes.
Exemples :
Cet exemple de requête lit un fichier Parquet à partir d'Stockage Blob Azure (SQL Server 2022 et versions ultérieures).
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'data/sales/*.parquet',
DATA_SOURCE = 'MyAzureStorage',
FORMAT = 'PARQUET'
) AS [result];
Cet exemple de requête lit un fichier Parquet avec un chemin d’accès en ligne (Azure SQL Database, Azure SQL Managed Instance).
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet',
FORMAT = 'PARQUET'
) AS [result];
Quand utiliser OPENROWSET et les tables externes
Les deux, OPENROWSET(BULK ...) et les tables externes, vous permettent d’interroger des données externes avec T-SQL, mais ils sont conçus pour différents cas d’usage. Le tableau suivant récapitule les principales différences pour vous aider à décider quelle approche correspond à votre scénario.
| Capacité | OPENROWSET(BULK ...) |
Table externe |
|---|---|---|
| Purpose | Exploration ad hoc et requêtes ponctuelles | Définition de table persistante et réutilisable |
| Métadonnées stockées dans la base de données | Non. Rien n’est enregistré après l’exécution de la requête | Yes. La définition de table, la source de données et le format de fichier sont stockées en tant qu’objets de base de données |
| Définition de schéma | Déduit automatiquement à partir du fichier (Parquet) ou spécifié directement avec la clause WITH |
Défini explicitement dans l’instruction CREATE EXTERNAL TABLE |
| Permissions | Nécessite ADMINISTER BULK OPERATIONS ou ADMINISTER DATABASE BULK OPERATIONS |
Une fois créée, l’autorisation standard SELECT sur la table est suffisante |
| Colonnes calculées | Yes. Ajoutez des expressions et des colonnes calculées dans la SELECT liste ; les fonctions de métadonnées comme filename() et filepath() sont disponibles uniquement ici. |
Non. Liste de colonnes fixe ; effectuer des transformations dans une vue ou dans la requête qui lit la table externe |
| Statistiques | Azure SQL : statistiques à colonne unique manuelles via sys.sp_create_openrowset_statistics; SQL Server 2022 (16.x) et versions ultérieures : autocréez les statistiques sur les prédicats (pas de statistiques manuelles sur SQL Server). Consultez les statistiques manuelles OPENROWSET. |
Prise en charge complète CREATE STATISTICS sur toutes les plateformes, avec fonction de création automatique dans SQL Server 2022 (16.x) et versions ultérieures. Référez-vous à Créer des statistiques manuelles pour une table externe. |
| Pushdown | Prise en charge limitée. Le moteur peut envoyer des filtres vers l’analyse du fichier, mais il n’y a pas de pushdown vers des sources SGBDR distantes | Yes. Prend en charge le calcul pushdown pour les connecteurs SGBDR (SQL Server, Oracle, Teradata, MongoDB) |
| Idéal pour | Exploration des données, découverte de schémas, requêtes de prototypage, chargements de données ponctuelles, transformations flexibles | Charges de travail de production, requêtes répétées, accès partagé entre les utilisateurs, tableaux de bord et rapports |
Utiliser OPENROWSET quand vous avez besoin de flexibilité
Permet OPENROWSET d’explorer un fichier, de tester différents schémas ou d’ajouter des colonnes et des transformations calculées sans créer d’objets persistants. Par exemple, vous pouvez extraire le chemin d’accès du fichier en tant que colonne, convertir des types de données en ligne ou filtrer sur des expressions calculées dans une seule requête.
Cet exemple de requête inclut des colonnes calculées et des transformations :
SELECT result.filename() AS [FileName],
result.filepath(1) AS [Year],
result.filepath(2) AS [Month],
CAST (OrderDate AS DATE) AS OrderDate,
Amount,
OrderDate
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*/*/*/*.parquet',
FORMAT = 'PARQUET'
) AS result
WHERE result.filepath(1) = '2025';
Conseil / Astuce
Les fonctions filepath() et filename() sont disponibles dans Azure SQL Database, Azure SQL Managed Instance et SQL Server 2022 (16.x) et versions ultérieures. Ils vous permettent de filtrer des parties du chemin d’accès du fichier (élimination de partition) et d’exposer le nom de fichier source sous forme de colonne, ce qui n’est pas directement possible avec les tables externes.
Utiliser des tables externes lorsque vous avez besoin de persistance et de gouvernance
Utilisez des tables externes lorsque plusieurs utilisateurs ou applications doivent interroger les mêmes données externes à plusieurs reprises. Vous définissez le schéma, la source de données et les informations d’identification une fois et les stockez dans la base de données. Les consommateurs ont seulement besoin d’une autorisation SELECT sur la table.
Les tables externes prennent également en charge les statistiques que l’optimiseur de requête utilise pour générer de meilleurs plans d’exécution. Vous pouvez créer manuellement des statistiques ou laisser le moteur les créer automatiquement (SQL Server 2022 (16.x) et versions ultérieures).
Cet exemple de requête crée des statistiques sur une table externe pour de meilleurs plans de requête.
CREATE STATISTICS Stats_OrderDate
ON dbo.SalesExternal(OrderDate)
WITH FULLSCAN;
Pour plus d’informations sur les statistiques des deux approches, consultez les considérations relatives aux performances de PolyBase - Statistiques.
BULK INSERT vs. OPENROWSET(BULK) : Qu’est-ce que je dois utiliser ?
À la fois BULK INSERT et OPENROWSET(BULK ...) importez des données à partir de fichiers dans SQL Server à l’aide du même moteur de chargement en bloc sous-jacent. Toutefois, ils diffèrent de la syntaxe, de la flexibilité et de ce que vous pouvez faire avec les résultats. Le tableau suivant résume les principales différences :
Note
BULK INSERT n’est pas disponible dans la base de données SQL dans Fabric. Pour Fabric, utilisez OPENROWSET(BULK ...) contre OneLake.
| Capacité | BULK INSERT |
OPENROWSET(BULK ...) |
|---|---|---|
| Objectif de base | Charge des données à partir d’un fichier directement dans une table cible | Renvoie un ensemble de lignes que vous utilisez dans une SELECT ou INSERT ... SELECT instruction |
| Modèle d’utilisation | Déclaration autonome : BULK INSERT <table> FROM '<file>' |
Doit être utilisé à l’intérieur d’une requête : SELECT * FROM OPENROWSET(BULK ...) ou INSERT INTO <table> SELECT * FROM OPENROWSET(BULK ...) |
| Nécessite une table cible ? | Yes. Écrit toujours directement dans une table | Non. Vous pouvez SELECT à partir de celui-ci sans insérer n’importe où, ou insérer dans une table ou une table temporaire |
| Transformations de colonne pendant le chargement | Prise en charge limitée. Les données circulent d’un fichier vers une table en l'état (mappage contrôlé par fichier de format ou ordre de colonne) | Prise en charge complète. Vous pouvez ajouter des expressions, des CASTWHERE filtres, JOIN d’autres tables et des colonnes calculées dans l’environnementSELECT |
| Indicateurs de table | La WITH clause inclut la prise en charge de BATCHSIZE, CHECK_CONSTRAINTS, FIRE_TRIGGERS, KEEPIDENTITY, KEEPNULLS, TABLOCK, et bien plus encore |
Prend en charge les indices de table via la syntaxe INSERT ... SELECT * FROM OPENROWSET(BULK ...) WITH (TABLOCK, IGNORE_CONSTRAINTS, ...) |
| Importation à valeur unique d’objets volumineux (LOB) | Non pris en charge | Yes. Prend en charge SINGLE_BLOB, SINGLE_CLOBSINGLE_NCLOB pour importer un fichier entier en tant que valeur varbinary(max), varchar(max)ou nvarchar(max) |
| Mettre en forme des fichiers | Yes. Pris en charge par (XML et non-XML) | Yes. Pris en charge (XML et non-XML) |
| Accès aux fichiers cloud (Stockage Blob Azure, ADLS Gen2, S3) | Yes. Pris en charge par le paramètre DATA_SOURCE (SQL Server 2017 (14.x) et versions ultérieures, Azure SQL) |
Yes. Prise en charge via un DATA_SOURCE paramètre ou une URL inline avec FORMAT clause (SQL Server 2022 (16.x) et versions ultérieures, Azure SQL) |
| Fichiers Parquet ou Delta | Non pris en charge. Texte csv/délimité uniquement | Yes. Pris en charge avec FORMAT = 'PARQUET' ou FORMAT = 'DELTA' (SQL Server 2022 (16.x) et versions ultérieures, Azure SQL) |
| Autorisation requise |
ADMINISTER BULK OPERATIONS ou ADMINISTER DATABASE BULK OPERATIONS, plus INSERT sur la table cible |
ADMINISTER BULK OPERATIONS ou ADMINISTER DATABASE BULK OPERATIONS |
| Journalisation minimale | Yes. Pris en charge sous des modèles de restauration simples ou en vrac avec TABLOCK |
Yes. Prise en charge lorsqu’elle est utilisée avec INSERT ... SELECT et TABLOCK |
Quand choisir BULK INSERT
Utilisez cette option BULK INSERT lorsque vous disposez d’une charge de fichier à table simple et que vous n’avez pas besoin de transformer, de filtrer ou de joindre des données pendant l’importation. Il utilise une syntaxe plus simple pour csv ou d’autres fichiers délimités :
Cet exemple de requête charge un fichier CSV à partir du Stockage Blob Azure directement dans une table.
BULK INSERT Sales.Invoices
FROM 'invoices/inv-2025-01.csv'
WITH (
DATA_SOURCE = 'MyAzureBlobStorage',
FORMAT = 'CSV',
FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR = '\n'
);
Cet exemple de requête charge un fichier local avec un fichier de format pour le mappage de colonnes.
BULK INSERT dbo.Products
FROM 'C:\Data\products.csv'
WITH (
FORMATFILE = 'C:\Data\products.fmt',
FIRSTROW = 2,
TABLOCK
);
Quand choisir OPENROWSET(BULK)
Utilisez OPENROWSET(BULK ...) quand vous avez besoin d’une ou plusieurs des conditions suivantes :
- Interroger ou afficher un aperçu des données de fichier sans créer de table en premier.
- Transformez, filtrez ou joignez des données pendant l’importation.
-
Chargez des fichiers Parquet ou Delta (seul
OPENROWSETprend en charge ces formats). -
Importez un fichier entier en tant que valeur LOB unique (
SINGLE_BLOB,SINGLE_CLOB,SINGLE_NCLOB).
Cet exemple de requête affiche un aperçu d’un fichier CSV à partir du Stockage Blob Azure sans insérer les données n’importe où.
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'invoices/inv-2025-01.csv',
DATA_SOURCE = 'MyAzureBlobStorage',
FORMAT = 'CSV',
FIRSTROW = 2,
FIELDTERMINATOR = ','
) AS src;
Cet exemple de requête insère des données avec transformation et filtrage.
INSERT INTO Sales.Invoices (InvoiceDate, Amount, Customer)
SELECT CAST (InvoiceDate AS DATE),
Amount * 1.1, -- Apply a 10% markup
UPPER(Customer)
FROM OPENROWSET (
BULK 'invoices/inv-2025-01.csv',
DATA_SOURCE = 'MyAzureBlobStorage',
FORMAT = 'CSV',
FIRSTROW = 2
) WITH (
InvoiceDate VARCHAR (10),
Amount DECIMAL (18, 2),
Customer VARCHAR (100)
) AS src
WHERE Amount IS NOT NULL;
Cet exemple de requête charge un fichier Parquet (pas possible avec BULK INSERT).
INSERT INTO Sales.Invoices
SELECT *
FROM OPENROWSET (
BULK 'data/invoices/*.parquet',
DATA_SOURCE = 'MyAzureStorage',
FORMAT = 'PARQUET') AS src;
Cet exemple de requête importe un fichier XML entier sous forme de valeur varbinary(max).
INSERT INTO dbo.XmlDocuments (DocContent)
SELECT BulkColumn
FROM OPENROWSET (
BULK 'C:\Data\catalog.xml',
SINGLE_BLOB
) AS x;
Conseil / Astuce
Une approche consiste à commencer avec OPENROWSET(BULK ...) dans un SELECT pour explorer et valider les données de fichier, puis à passer à BULK INSERT pour la charge de production finale si vous n’avez pas besoin de transformations. Si vous avez besoin d’une prise en charge de Parquet ou Delta ou d’un filtrage en ligne, conservez OPENROWSET.
Pour plus d’informations, consultez les guides connexes suivants :
- Utilisez BULK INSERT ou OPENROWSET(BULK...) pour importer des données dans SQL Server : guide détaillé côte à côte avec considérations de sécurité.
-
Importation et exportation en bloc de données (SQL Server) : vue d’ensemble de toutes les méthodes de déplacement de données en bloc (bcp,
BULK INSERT,OPENROWSET). - BULK INSERT (Transact-SQL) : référence T-SQL complète.
- OPENROWSET BULK (Transact-SQL) : référence T-SQL complète.
- Exemples d’accès en bloc aux données dans Stockage Blob Azure : exemples côte à côte utilisant les deux méthodes avec stockage Azure.
-
Importez en bloc des données volumineuses avec le fournisseur d’ensembles de lignes en bloc OPENROWSET (SQL Server) :
SINGLE_BLOB,SINGLE_CLOBetSINGLE_NCLOBdes exemples. - Utilisez un fichier de format pour importer en bloc des données (SQL Server) : Utilisation du fichier de format avec les deux méthodes.
Fonctions de métadonnées utiles
Lorsque vous interrogez des fichiers externes avec ou des OPENROWSET tables externes, vous pouvez utiliser plusieurs fonctions et procédures intégrées pour inspecter les métadonnées de fichier, découvrir des schémas et implémenter des requêtes prenant en charge les partitions.
filepath() et filename()
Les fonctions filepath() et les fonctions filename() retournent des parties du chemin d'accès du fichier ou du nom de fichier pour chaque ligne du jeu de résultats. Ils sont particulièrement utiles pour :
Élimination de partition : filtrez les segments de dossiers (par exemple, les partitions année/mois/jour) afin que le moteur lit uniquement les fichiers correspondants au lieu d’analyser tout.
Exposition des métadonnées sources : incluez le nom ou le chemin d’accès du fichier d’origine en tant que colonne dans les résultats de la requête, ce qui est utile pour l’audit ou le débogage.
| Fonction | Retours | Exemple |
|---|---|---|
filename() |
Nom de fichier (y compris l’extension) du fichier source pour chaque ligne | sales_2025_01.parquet |
filepath(N) |
le Nème segment de dossier depuis le caractère générique (*) dans le chemin BULK, où N commence à 1 |
Pour le chemin sales/2025/01/*.parquet, filepath(1) retourne 2025, filepath(2) retourne 01 |
S’applique à : Azure SQL Database, Azure SQL Managed Instance, SQL Server 2022 (16.x) et versions ultérieures, base de données SQL dans Fabric.
Cet exemple de requête utilise filepath() pour l’élimination de partition et filename() pour identifier les fichiers sources. Il lit uniquement les fichiers sous le /2025/ dossier et lit uniquement les fichiers sous le /06/ sous-dossier.
SELECT result.filename() AS SourceFile,
result.filepath(1) AS [Year],
result.filepath(2) AS [Month],
*
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*/*/*.parquet',
FORMAT = 'PARQUET'
) AS result
WHERE result.filepath(1) = '2025'
AND result.filepath(2) = '06';
Conseil / Astuce
Placez les filtres filepath() dans la clause WHERE plutôt que dans une sous-requête ou un CTE. Lorsque le filtre se trouve dans la WHERE clause, le moteur peut effectuer l’élimination de partition au niveau de l’analyse du fichier, ce qui réduit considérablement les E/S.
sp_describe_first_result_set - découvrir les types de colonnes OPENROWSET
Lorsque vous utilisez des fichiers Parquet avec OPENROWSET, le moteur infère automatiquement les types de données de colonne (inférence de schéma). Les types déduits peuvent être plus grands que nécessaire. Par exemple, les colonnes de caractères sont souvent déduites en tant que varchar(8000), car les métadonnées Parquet n’incluent pas de longueur maximale. Ce choix peut dégrader les performances et consommer plus de mémoire.
Permet sp_describe_first_result_set d’inspecter le schéma déduit avant de finaliser votre requête. Après avoir vu les types déduits, spécifiez des types plus étroits dans une WITH clause pour améliorer les performances.
Étape 1 : Inspecter le schéma déduit.
EXECUTE sp_describe_first_result_set N' SELECT * FROM OPENROWSET( BULK ''abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet'', FORMAT = ''PARQUET'' ) AS result';La sortie affiche le nom de chaque colonne, le type de données déduit, la longueur maximale, la précision et l’échelle de chaque colonne. Si vous voyez varchar(8000) alors qu’un varchar(100) suffirait, modifiez-le :
Étape 2 : Utiliser des types explicites pour améliorer les performances.
SELECT TOP 100 * FROM OPENROWSET ( BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet', FORMAT = 'PARQUET' ) WITH ( OrderId INT, OrderDate DATE, Amount DECIMAL (18, 2), Customer VARCHAR (100) -- much narrower than the inferred varchar(8000) ) AS result;
L’inférence de schéma fonctionne uniquement avec les fichiers Parquet. Pour les fichiers CSV, spécifiez toujours des définitions de colonne dans une WITH clause (for OPENROWSET) ou dans l’instruction CREATE EXTERNAL TABLE .
sp_describe_first_result_set est une procédure générale de SQL Server et Azure SQL, mais elle est particulièrement utile pour les requêtes OPENROWSET. Pour plus d’informations, voir sp_describe_first_result_set.
Performances, résolution des problèmes et meilleures pratiques
Après avoir implémenté la virtualisation des données, utilisez ces guides pour optimiser les performances, diagnostiquer les problèmes et garantir la préparation de la production :
| Domaine | Article | Détails |
|---|---|---|
| Les performances de PolyBase | Considérations relatives aux performances dans PolyBase pour SQL Server | Statistiques, pushdown, parallélisme et gestion de la mémoire |
| Calcul pushdown | Calculs pushdown dans PolyBase | Spécifie quelles opérations poussent vers la source distante |
| Comment savoir si un pushdown s’est produit | Guide pratique pour savoir si un pushdown externe s’est produit | Plans de requête et DMV |
| Résolution des problèmes | Surveiller et résoudre les problèmes de PolyBase | Problèmes courants et leur résolution |
| Connectivité Kerberos | Résoudre des problèmes de connectivité de PolyBase Kerberos | |
| FORUM AUX QUESTIONS | Questions fréquemment posées sur PolyBase | |
| Erreurs et solutions | Erreurs PolyBase et solutions possibles |