Guide d'architecture et gestion du journal des transactions de SQL Server
S’applique à : ![]() SQL Server
SQL Server ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance ![]() Azure Synapse Analytics
Azure Synapse Analytics ![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)
Chaque base de données SQL Server comprend un journal des transactions qui enregistre toutes les transactions et les modifications apportées par chaque transaction. Le journal des transactions est un composant essentiel de la base de données et, en cas de défaillance du système, vous pouvez en avoir besoin pour rétablir la cohérence de la base de données. Ce guide contient des informations sur l'architecture physique et logique du journal des transactions. Ces informations pourront vous aider à gérer plus efficacement les journaux des transactions.
Architecture logique du journal des transactions
Le journal des transactions de SQL Server fonctionne de façon logique comme s'il s'agissait d'une chaîne d'enregistrements de journal. Chacun de ces enregistrements est identifié par un numéro séquentiel dans le journal (LSN). Chaque nouvel enregistrement est écrit à la fin logique du journal avec un LSN supérieur à celui de l'enregistrement qui le précède. Les enregistrements de journal sont stockés dans une séquence en série à mesure qu’ils sont créés de sorte que si LSN2 est supérieur à LSN1, la modification décrite par l'enregistrement de journal référencé par LSN2 se produit après la modification décrite par le numéro LSN1 d'enregistrement de journal. Chacun d'eux contient l'ID de la transaction à laquelle il appartient. Pour chaque transaction, tous les enregistrements de journal associés sont reliés de façon individuelle dans une chaîne grâce aux pointeurs arrière qui accélèrent la restauration de la transaction.
La structure de base d’un LSN est [VLF ID:Log Block ID:Log Record ID]. Pour plus d’informations, consultez les sections VLF et bloc de journal.
Voici un exemple de LSN : 00000031:00000da0:0001, où 0x31 est l’ID du VLF, 0xda0 est l’ID de bloc de journal et 0x1 est le premier enregistrement de journal dans ce bloc de journal. Pour obtenir des exemples de LSN, examinez la sortie de sys.dm_db_log_info DMV et examinez la colonne vlf_create_lsn.
Les enregistrements de journal relatifs aux modifications de données consignent soit l'opération logique effectuée, soit les images avant/après des données modifiées. L'image avant est une copie des données avant que l'opération n'ait été effectuée, tandis que l'image après est une copie des données après que l'opération a été effectuée.
Les étapes pour récupérer une opération dépendent du type de journal d'enregistrement :
Opération logique enregistrée
- Si vous repositionnez l'opération logique avant, elle est effectuée à nouveau.
- Si vous annulez l'opération logique, l'opération inverse est effectuée.
Image avant et après enregistrées
- Si vous repositionnez l'opération avant, l'image après est appliquée.
- Si vous annulez l'opération, l'image avant est appliquée.
De nombreux types d'opérations sont enregistrés dans le journal des transactions. Ces opérations comprennent :
Le début et la fin de chaque transaction.
Chaque modification de données (insertion, mise à jour ou suppression). Les modifications comprennent les changements apportés par les procédures stockées du système ou les instructions du langage de définition des données (DDL) à n'importe quelle table, y compris les tables du système.
Chaque allocation ou désallocation de page et d'étendue.
Création ou suppression d'une table ou d'un index.
Les opérations de restauration sont également consignées dans le journal. Chaque transaction réserve de l'espace dans le journal des transactions afin qu'il existe suffisamment d'espace journal pour prendre en charge une restauration déclenchée par une instruction de restauration explicite ou par la détection d'une erreur. Le volume d'espace réservé dépend des opérations effectuées dans la transaction, mais il est généralement égal au volume d'espace utilisé pour la journalisation de chaque opération. Cet espace réservé est libéré lorsque la transaction est terminée.
La section du fichier journal comprise entre le premier enregistrement de journal nécessaire à une restauration portant sur l’ensemble de la base de données et la fin du journal représente la partie active du journal, le journal actif ou la fin du journal. Cette section est indispensable pour procéder à une récupération complète de la base de données. Aucune partie de ce journal actif ne peut être tronquée. Le numéro séquentiel dans le journal (LSN) de ce premier enregistrement est le LSN de récupération minimum (MinLSN). Pour plus d’informations sur les opérations prises en charge par le journal des transactions, consultez Journal des transactions.
Les sauvegardes différentielles et de journaux font passer la base de données restaurée à une date ultérieure qui correspond à un numéro LSN supérieur.
Architecture physique du journal des transactions
Le journal des transactions d'une base de données s'étend sur un ou plusieurs fichiers physiques. D'un point de vue conceptuel, le fichier journal est une chaîne d'enregistrements. D'un point de vue physique, la séquence des enregistrements du journal est stockée de façon efficace dans l'ensemble de fichiers physiques qui implémente le journal des transactions. Chaque base de données doit posséder au moins un fichier journal.
Fichiers journaux virtuels (VLF, Virtual Log Files)
Le moteur de base de données de SQL Server divise chaque fichier journal physique en un certain nombre de fichiers journaux virtuels (VLF).. Les fichiers journaux virtuels n'ont pas de taille fixe et il n'y a pas de nombre fixe de fichiers journaux virtuels pour un fichier journal physique. Le moteur de base de données choisit dynamiquement la taille des fichiers journaux virtuels en créant ou en étendant des fichiers journaux. La Moteur de base de données tente de gérer quelques fichiers virtuels. Après une extension du fichier journal, la taille des fichiers virtuels est la somme de la taille du journal existant et de la taille du nouvel incrément de fichier. La taille et le nombre des fichiers journaux virtuels ne peuvent être ni configurés, ni définis par les administrateurs.
Création de fichiers journaux virtuels
La création du fichier journal virtuel suit cette méthode :
- Dans SQL Server 2014 (12.x) et les versions ultérieures, si la prochaine croissance est inférieure à 1/8 de la taille physique du journal actuel, créez 1 fichiers journal virtuel qui couvre la taille de la croissance.
- Si la croissance suivante est supérieure à 1/8 de la taille actuelle du journal, utilisez la méthode antérieure à 2014 :
- Si la croissance est inférieure à 64 Mo, créez 4 fichiers journaux virtuels qui couvrent la taille de croissance (par exemple, pour une croissance de 1 Mo, créez quatre fichiers journaux virtuels de 256 Ko).
- Dans Azure SQL Database et à partir de SQL Server 2022 (16.x) (toutes les éditions), la logique est légèrement différente. Si la croissance est inférieure ou égale à 64 Mo, le Moteur de base de données crée un seul VLF pour couvrir la taille de croissance.
- Si la croissance se situe entre 64 Mo et 1 Go, créez 8 fichiers journaux virtuels qui couvrent la taille de croissance (par exemple, pour une croissance de 512 Mo, créez huit fichiers journaux virtuels de 64 Mo).
- Si la croissance est supérieure à 1 Go, créez 16 fichiers journaux virtuels qui couvrent la taille de croissance (par exemple, pour une croissance de 8 Go, créez seize fichiers journaux virtuels de 512 Ko).
- Si la croissance est inférieure à 64 Mo, créez 4 fichiers journaux virtuels qui couvrent la taille de croissance (par exemple, pour une croissance de 1 Mo, créez quatre fichiers journaux virtuels de 256 Ko).
Si les fichiers journaux atteignent une taille importante en plusieurs petits incréments, ils se retrouvent avec de nombreux fichiers journaux virtuels. Cela peut ralentir le démarrage de la base de données, les opérations de sauvegarde et de restauration des journaux, et provoquer une réplication transactionnelle/CDC modifiées et une latence de rétablissement de Always On. À l’inverse, si les fichiers journaux sont définis avec une grande taille et avec un seul incrément ou peu d’incréments, ils contiennent peu de fichiers journaux virtuels très volumineux. Pour plus d’informations sur une estimation correcte de la taille nécessaire et de la croissance automatique d’un journal des transactions, reportez-vous à la section Recommandations de Gérer la taille du fichier journal des transactions.
Nous vous recommandons de créer vos fichiers journaux à une taille proche de la taille finale requise, en utilisant les incréments nécessaires pour obtenir une distribution optimale des VLF, et d'avoir une valeur growth_increment relativement importante.
Consultez les conseils suivants pour déterminer la distribution optimale des fichiers journaux virtuels pour la taille actuelle du journal des transactions :
- La valeur size, telle que définie par l’argument
SIZEdeALTER DATABASEest la taille initiale du fichier journal. - La valeur de growth_increment (également appelée valeur d’accroissement automatique), telle que définie par l’argument
FILEGROWTHdeALTER DATABASE, correspond à la quantité d’espace ajoutée au fichier chaque fois de l’espace supplémentaire s’avère nécessaire.
Pour plus d’informations sur les arguments FILEGROWTH et SIZE de ALTER DATABASE, consultez le fichier ALTER DATABASE (Transact-SQL) et les options de groupe de fichiers.
Conseil
Pour déterminer la distribution optimale des fichiers journaux virtuels pour la taille actuelle du journal des transactions de toutes les bases de données dans une instance donnée, ainsi que les incréments de croissance pour atteindre la taille nécessaire, consultez ce script de correction de VLF sur GitHub..
Que se passe-t-il quand vous avez trop de VLF ?
Au cours des étapes initiales d’un processus de récupération de base de données, SQL Server découvre toutes les fonctions VLF dans tous les fichiers journaux des transactions et génère une liste de ces VLF. Ce processus peut prendre beaucoup de temps en fonction du nombre de VLF présents dans la base de données spécifique. Plus les VLF sont longues, plus le processus est long. Une base de données peut se retrouver avec un grand nombre de VLF si la croissance automatique du journal des transactions fréquente ou la croissance manuelle est rencontrée par petits incréments. Lorsque le nombre de VLF atteint la plage de plusieurs centaines de milliers, vous pouvez rencontrer quelques-uns ou la plupart des symptômes suivants :
- Une ou plusieurs bases de données prennent beaucoup de temps pour terminer la récupération au démarrage de SQL Server.
- La restauration d’une base de données prend beaucoup de temps.
- Les tentatives d’attachement d’une base de données prennent beaucoup de temps.
- Lorsque vous essayez de configurer la mise en miroir de bases de données, vous rencontrez des messages d’erreur 1413, 1443 et 1479, indiquant un délai d’expiration.
- Vous rencontrez des erreurs liées à la mémoire comme 701 lorsque vous tentez de restaurer une base de données.
- La réplication transactionnelle ou la capture de données modifiées peuvent rencontrer une latence significative.
Lorsque vous examinez le journal des erreurs SQL Server, vous remarquerez peut-être qu’un certain temps s’est écoulé avant la phase d’analyse du processus de récupération de base de données. Par exemple :
2022-05-08 14:42:38.65 spid22s Starting up database 'lot_of_vlfs'.
2022-05-08 14:46:04.76 spid22s Analysis of database 'lot_of_vlfs' (16) is 0% complete (approximately 0 seconds remain). Phase 1 of 3. This is an informational message only. No user action is required.
En outre, SQL Server peut consigner une erreur de MSSQLSERVER_9017 lorsque vous restaurez une base de données comportant un grand nombre de fonctions VLF :
Database %ls has more than %d virtual log files which is excessive. Too many virtual log files can cause long startup and backup times. Consider shrinking the log and using a different growth increment to reduce the number of virtual log files.
Pour plus d’informations, consultez MSSQLSERVER_9017.
Corriger les bases de données avec un grand nombre de VLF
Pour conserver le nombre total de VLF à un montant raisonnable, tel qu’un maximum de plusieurs milliers, vous pouvez réinitialiser le fichier journal des transactions pour contenir un plus petit nombre de VLF en effectuant les étapes suivantes :
Réduisez manuellement les fichiers journaux des transactions.
Augmentez les fichiers à la taille requise manuellement en une étape à l’aide du script T-SQL suivant :
ALTER DATABASE <database name> MODIFY FILE (NAME='Logical file name of transaction log', SIZE = <required size>);Remarque
Cette étape est également possible dans SQL Server Management Studio, à l’aide de la page des propriétés de la base de données.
Après avoir défini la nouvelle disposition du fichier journal des transactions avec moins de VLF, passez en revue et apportez les modifications nécessaires aux paramètres de croissance automatique du journal des transactions. La validation de ce paramètre permet de s'assurer que le fichier journal ne rencontrera pas le même problème à l'avenir.
Avant d’effectuer l’une de ces opérations, assurez-vous que vous disposez d’une sauvegarde pouvant être restaurée valide si vous rencontrez des problèmes ultérieurement.
Pour déterminer la distribution optimale des fichiers journaux virtuels pour la taille actuelle du journal des transactions de toutes les bases de données dans une instance donnée, ainsi que les incréments de croissance pour atteindre la taille nécessaire, vous pouvez utiliser le script GitHub suivant pour corriger les VLFs.
Blocs de journal
Chaque VLF contient un ou plusieurs blocs de journal. Chaque bloc de journal se compose des enregistrements de journal (alignés à une limite de 4 octets). Un bloc de journal est variable de taille et est toujours un entier multiple de 512 octets (la taille minimale de secteur prise en charge par SQL Server), avec une taille maximale de 60 Ko. Un bloc de journal est l’unité de base des E/S pour la journalisation des transactions.
En résumé, un bloc de journal est un conteneur d’enregistrements de journal utilisés comme unité de base de la journalisation des transactions lors de l’écriture d’enregistrements de journal sur le disque.
Chaque bloc de journal dans un VLF est traité de manière unique par son décalage de bloc. Le premier bloc a toujours un décalage de bloc qui pointe au-delà des 8 premiers Ko dans le VLF.
En général, un VLF est toujours rempli avec des blocs de journal. Il est possible que le dernier bloc de journal dans un VLF soit vide (par exemple, ne contient aucun enregistrement de journal). Cela se produit lorsqu’un enregistrement de journal à écrire ne tient pas dans le bloc de journal actuel et lorsque l’espace laissé sur le VLF est insuffisant pour contenir cet enregistrement de journal. Dans ce cas, un bloc de journal vide est créé et remplit la VLF. L’enregistrement du journal est inséré dans le premier bloc du VLF suivant.
Nature circulaire du journal des transactions
Le journal des transactions est un fichier cumulatif. Considérons, par exemple, une base de données possédant un fichier journal physique divisé en quatre fichiers journaux virtuels. Lors de la création de la base de données, le fichier journal logique commence au début du fichier journal physique. Les nouveaux enregistrements du journal sont ajoutés à la fin du journal logique, qui s'étend vers la fin du journal physique. Le fait de tronquer le journal permet de libérer tous les journaux virtuels dont les enregistrements précèdent tous le MinLSN (numéro séquentiel dans le journal minimum). Le MinLSN est le numéro séquentiel dans le journal du plus ancien enregistrement du journal requis pour une opération de restauration réussie de l’ensemble de la base de données. Le journal des transactions de la base de données de l'exemple ressemblerait à celui du diagramme suivant.
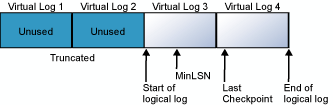
Lorsque la fin du journal logique atteint la fin du fichier journal physique, le nouvel enregistrement du journal revient au début du fichier journal physique.
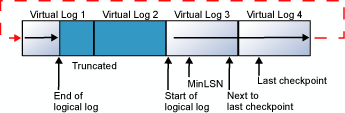
Le cycle se répète indéfiniment tant que la fin du journal logique n'a pas atteint le début du journal logique. Si les anciens enregistrements du journal sont tronqués suffisamment souvent pour laisser de la place à tous les nouveaux enregistrements créées jusqu'au point de contrôle suivant, le journal ne se remplit jamais. Si la fin du journal logique atteint le début du journal logique, l'une ou l'autre des situations suivantes se produit :
Si le paramètre
FILEGROWTHest activé pour le journal et que l’espace disque est suffisant, le fichier s’étend en fonction de la taille spécifiée dans le paramètre growth_increment, les nouveaux enregistrements du journal étant ajoutés à l’extension. Pour plus d’informations sur le paramètreFILEGROWTH, consultez Options de fichiers et de groupes de fichiers ALTER DATABASE (Transact-SQL).Si le paramètre
FILEGROWTHn’est pas activé ou si l’espace disque réservé au fichier journal est inférieur à la taille spécifiée dans growth_increment, l’erreur 9002 est générée. Pour plus d’informations, consultez Résoudre les problèmes liés à un journal des transactions saturé (Erreur de serveur SQL 9002).
Si le journal contient plusieurs fichiers journaux physiques, le journal logique va se déplacer dans tous les fichiers journaux physiques avant de revenir au début du premier fichier journal physique.
Important
Pour plus d’informations sur la gestion de la taille du journal des transactions, consultez Gérer la taille du fichier journal des transactions.
Troncation de journal
La troncation du journal est essentielle pour empêcher que le journal se remplisse. La troncation du journal supprime les fichiers journaux virtuels inactifs du journal des transactions logique d'une base de données SQL Server, ce qui libère de l'espace dans le journal logique de façon à ce qu'il soit réutilisé par le journal des transactions physique. Si un journal des transactions n’est jamais tronqué, il finit par occuper tout l’espace disque alloué aux fichiers journaux physiques. Toutefois, une opération de point de contrôle est requise avant que le journal des transactions puisse être tronqué. Un point de contrôle écrit les pages modifiées en mémoire actuelles (appelées pages de modifications) et les informations du journal des transactions de la mémoire vers le disque. Lorsque le point de contrôle est créé, la partie inactive du journal des transactions est marquée comme réutilisable. Par la suite, une troncature du journal peut libérer la partie inactive. Pour plus d’informations sur les points de contrôle, consultez Points de contrôle de base de données (SQL Server).
Le diagramme suivant montre un journal des transactions avant et après une troncation. le premier diagramme montre un journal des transactions qui n'a jamais été tronqué. Actuellement, quatre fichiers journaux virtuels sont utilisés par le journal logique. Le journal logique commence avant le premier fichier journal virtuel et se termine au journal virtuel 4. L'enregistrement NSEmin se trouve dans le journal virtuel 3. Les journaux virtuels 1 et 2 contiennent uniquement des enregistrements de journal inactifs. Ces enregistrements peuvent être tronqués. Le journal virtuel 5 est encore inutilisé et ne fait pas partie du journal logique actuel.
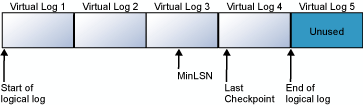
Le deuxième diagramme montre le journal après sa troncation. Les journaux virtuels 1 et 2 ont été libérés en vue de leur réutilisation. Le journal logique commence désormais au début du journal virtuel 3. Le journal virtuel 5 est encore inutilisé et ne fait pas partie du journal logique actuel.
La troncation du journal se produit automatiquement après les événements suivants, à moins qu'elle ne soit retardée pour une raison quelconque :
- En mode de récupération simple, après un point de contrôle.
- En mode de restauration complète ou en mode de récupération utilisant les journaux de transactions, après une sauvegarde du journal, si un point de contrôle s'est produit depuis la dernière sauvegarde.
La troncation du journal peut être retardée pour différents motifs. En cas de retard prolongé de la troncation du journal, le journal des transactions peut se remplir complètement. Pour plus d’informations, consultez Facteurs pouvant retarder la troncation du journal et Résoudre les problèmes liés à un journal des transactions saturé (Erreur SQL Server 9002).
Journal des transactions à écriture anticipée
Cette section décrit le rôle que joue le journal des transactions à écriture anticipée (journal WAL) au niveau de l'enregistrement sur disque des modifications apportées aux données. SQL Server utilise un algorithme WAL (write-ahead logging) qui garantit qu’aucune modification de données n’est écrite sur le disque avant l’écriture du journal associé sur celui-ci. Ainsi, les propriétés ACID (Atomicité, Cohérence, Isolation et Durabilité) d'une transaction sont conservées.
Pour plus d’informations sur WAL, consultez Notions de base des E/S de SQL Server.
Pour comprendre le fonctionnement de la journalisation à écriture anticipée, il est important de savoir comment les données modifiées sont écrites sur le disque. SQL Server gère un cache des tampons (aussi appelé pool de tampons) dans lequel il lit les pages de données lorsque celles-ci doivent être extraites. Lorsqu’une page est modifiée dans le cache des tampons, elle n’est pas réécrite immédiatement sur le disque, mais elle est marquée comme erronée. Une page peut avoir plusieurs écritures logiques exécutées avant son écriture physique sur le disque. Pour chaque écriture logique, un enregistrement du journal des transactions est inséré dans le cache du journal qui enregistre la modification. L'enregistrement doit être écrit sur le disque avant que la page de modifications associée n'ait été supprimée du cache et écrite sur le disque. Le processus de point de contrôle analyse régulièrement le cache à la recherche de tampons contenant des pages issues d'une base de données spécifiée et écrit toutes les pages de modifications sur le disque. Les points de contrôle permettent une récupération ultérieure du système en créant un point où toutes les pages de modifications sont effectivement écrites sur le disque.
Le processus d'écriture d'une page de données modifiée, du cache des tampons vers le disque, porte le nom de vidage. SQL Server possède une logique qui empêche la suppression d’une page de modifications avant que l’enregistrement du journal associé n’ait été écrit. Les enregistrements de journal sont écrits sur le disque quand les tampons de journaux sont vidés. Cela se produit chaque fois qu’une transaction est validée ou que les tampons de journaux sont saturés.
Sauvegardes du journal des transactions
Cette section présente les concepts sur la sauvegarde et la restauration (application) des journaux de transactions. En mode de récupération complète et en mode de récupération utilisant les journaux de transactions, la sauvegarde régulière des journaux de transactions (sauvegardes des journaux) est indispensable pour pouvoir récupérer les données. Sauvegardez le journal pendant l'exécution d'une sauvegarde complète. Pour plus d’informations sur les modes de récupération, consultez Sauvegarde et restauration des bases de données SQL Server.
Avant de pouvoir créer la première sauvegarde du journal, vous devez créer une sauvegarde complète, telle qu'une sauvegarde de base de données ou la première d'une série de sauvegardes de fichiers. La restauration d'une base de données à l'aide seulement de sauvegardes de fichiers peut être complexe. Par conséquent, nous vous recommandons de commencer par une sauvegarde de base de données complète dès que possible. Puis, sauvegardez le journal des transactions régulièrement. Vous pouvez ainsi réduire les risques de perte de travail mais aussi permettre la troncation du journal des transactions. En général, le journal des transactions est tronqué après chaque sauvegarde de journal conventionnelle.
Important
Nous vous recommandons d’effectuer des sauvegardes de journaux suffisamment fréquentes pour répondre à vos besoins, en particulier votre tolérance des pertes de données comme celles causées par un stockage de journal endommagé.
La fréquence appropriée des sauvegardes de journaux dépend de votre gestion des risques liés aux pertes de données et du nombre de sauvegardes de journaux qu'il vous est possible de stocker, gérer et potentiellement restaurer. Pensez à l’objectif de délai de récupération et à l’objectif de point de récupération quand vous implémentez votre stratégie de récupération, en particulier la cadence des sauvegardes de fichier journal. Réaliser une sauvegarde de journal tous les 15 à 30 minutes peut être suffisant. Si vos besoins nécessitent de minimiser les risques de perte de travail, vous devez envisager des sauvegardes de journaux plus fréquentes. Une meilleure fréquence pour les sauvegardes de fichiers journaux offre l'avantage d'augmenter la fréquence de la troncation des journaux qui produit des fichiers journaux plus petits.
Pour limiter le nombre des sauvegardes de fichiers journaux à restaurer, il est essentiel de sauvegarder vos données régulièrement. Vous pouvez, par exemple, planifier une sauvegarde complète hebdomadaire et des sauvegardes différentielles quotidiennes de la base de données.
Là encore, pensez à l’objectif de délai de récupération et à l’objectif de point de récupération quand vous implémentez votre stratégie de récupération, en particulier la cadence des sauvegardes différentielles et complètes de base de données.
Pour plus d’informations sur les sauvegardes des journaux de transactions, consultez Sauvegardes des journaux de transactions (SQL Server).
Séquence de journaux de transactions consécutifs
Une séquence continue de sauvegardes de journaux s’appelle une séquence de journaux de transactions consécutifs. Une séquence de journaux de transactions consécutifs commence par une sauvegarde complète de la base de données. Généralement, une nouvelle séquence de journaux de transactions consécutifs ne démarre que lorsque la base de données est sauvegardée pour la première fois ou après que le mode de récupération simple est remplacé par le mode de récupération complète ou le mode de récupération utilisant les journaux de transactions. Si vous ne choisissez pas de remplacer les jeux de sauvegarde existants lors de la création d'une sauvegarde complète de base de données, la séquence de journaux de transactions consécutifs existante reste intacte. Grâce à la séquence de journaux de transactions consécutifs intacte, vous pouvez restaurer votre base de données à partir d'une sauvegarde complète de base de données du support de sauvegarde, suivie de toutes les sauvegardes de fichiers journaux suivantes jusqu'à votre point de récupération. Le point de récupération peut être la fin de la dernière sauvegarde de fichier journal ou un point de récupération spécifique dans chacune des sauvegardes de fichiers journaux. Pour plus d’informations, consultez Sauvegardes du journal des transactions (SQL Server).
Pour restaurer une base de données jusqu'au point d'échec, la séquence de journaux de transactions consécutifs doit être intacte. Autrement dit, la séquence ininterrompue des sauvegardes des journaux de transactions doit aller jusqu'au point de défaillance. Le point de commencement de cette séquence du journal dépend du type des sauvegardes de données que vous restaurez : base de données, partielle ou fichiers. Pour une sauvegarde partielle ou de base de données, la séquence des sauvegardes des journaux doit s'étendre à partir de la fin d'une sauvegarde partielle ou de base de données. Pour un jeu de sauvegardes de fichiers, la séquence des sauvegardes des journaux doit s'étendre à partir du début d'un jeu complet de sauvegardes de fichiers. Pour plus d’informations, consultez Appliquer les sauvegardes de fichier journal (SQL Server).
Restaurer des sauvegardes du journal
La restauration d'une sauvegarde de journal restaure par progression les modifications enregistrées dans le journal des transactions, afin de recréer l'état exact de la base de données qui existait au début de la sauvegarde du journal. Lorsque vous restaurez une base de données, vous devez restaurer les sauvegardes des journaux créées à la suite de la sauvegarde complète de base de données que vous restaurez ou à partir de la première sauvegarde de fichiers que vous restaurez. En règle générale, vous devez restaurer une série de sauvegardes de journaux jusqu'au point de récupération, après avoir restauré les données les plus récentes ou une sauvegarde différentielle. Ensuite, vous récupérez la base de données. Cette opération restaure toutes les transactions qui n'étaient pas terminées au début de la récupération et place la base de données en ligne. Une fois la base de données récupérée, vous ne pouvez plus restaurer des sauvegardes. Pour plus d’informations, consultez Appliquer les sauvegardes de fichier journal (SQL Server).
Points de contrôle et partie active du journal
Les points de contrôle vident les pages de données incorrectes de la mémoire cache de la base de données active sur le disque, ce qui réduit la partie active du journal devant être traitée durant une récupération complète d'une base de données. Au cours d'une récupération complète, les types d'actions suivants sont effectués :
- Les enregistrements de journal concernant des modifications qui n'ont pas été vidées sur le disque avant l'arrêt du système sont restaurés par progression.
- Toutes les modifications associées à des transactions incomplètes (telles que les transactions pour lesquelles il n'existe pas d'enregistrement de journal COMMIT ou ROLLBACK) sont restaurées.
Opération de point de contrôle
Un point de contrôle effectue les processus suivants dans la base de données :
Écrit un enregistrement dans le fichier journal qui marque le début du point de contrôle.
Stocke les informations enregistrées pour le point de contrôle dans une chaîne d'enregistrements de journal des points de contrôle.
L'une des informations consignées dans le point de contrôle est le numéro séquentiel dans le journal du premier enregistrement de journal qui doit être présent pour permettre une restauration à l'échelle de la base de données. Ce NSE porte le nom de NSE de récupération minimum (NSEmin). Le NSEmin est le minimum de :
- NSE du début du point de contrôle ;
- NSE du début de la transaction active la plus ancienne ;
- LSN du début de la transaction de réplication la plus ancienne qui n'a pas encore été transmise à la base de données de distribution.
Les enregistrements de point de contrôle contiennent également une liste de toutes les transactions actives qui ont modifié la base de données.
Si la base de données utilise le mode de récupération simple, signalez pour une utilisation ultérieure l'espace qui précède le NSEmin.
Écrit sur le disque toutes les pages de journal et de données incorrectes.
Écrit un enregistrement marquant la fin du point de contrôle dans le fichier journal.
Écrit le numéro LSN du début de cette chaîne dans la page de démarrage de la base de données.
Activités entraînant un point de contrôle
Des points de contrôle interviennent dans les situations suivantes :
- Une instruction CHECKPOINT est exécutée explicitement. Un point de contrôle intervient dans la base de données active pour la connexion.
- Une opération journalisée minimale est effectuée dans la base de données ; par exemple, une opération de copie en bloc est réalisée sur une base de données qui se sert du mode de récupération utilisant les journaux de transactions.
- Des fichiers de base de données ont été ajoutés ou supprimés à l'aide de l'instruction ALTER DATABASE.
- Une instance de SQL Server est arrêtée par une instruction SHUTDOWN ou via l’arrêt du service SQL Server (MSSQLSERVER). Ces opérations provoquent la création d’un point de contrôle dans chaque base de données dans l’instance de SQL Server.
- Une instance de SQL Server génère régulièrement des points de contrôle automatiques dans chaque base de données, afin de réduire la durée nécessaire à l’instance pour récupérer la base de données.
- Une sauvegarde de la base de données est effectuée.
- Une activité nécessitant l'arrêt de la base de données est effectuée. Cela peut se produire lorsque l’option AUTO_CLOSE est ACTIVÉE et que la dernière connexion utilisateur à la base de données est fermée. Un autre exemple est le moment où une modification d’option de base de données est apportée qui nécessite un redémarrage de la base de données.
Points de contrôle automatiques
Le moteur de base de données SQL Server génère des points de contrôle automatiques. L'intervalle entre les points de contrôle automatiques est basé sur la quantité d'espace de journal utilisée et la durée écoulée depuis le dernier point de contrôle. Cet intervalle de temps entre les points de contrôle automatiques peut varier fortement et être long si les modifications apportées à la base de données sont peu nombreuses. Inversement, les points de contrôle automatiques peuvent être fréquents si les données modifiées sont nombreuses.
Utilisez l’option de configuration de serveur intervalle de récupération pour calculer l’intervalle pour toutes les bases de données sur une instance de serveur. Cette option spécifie la durée maximale que le moteur de base de données doit utiliser pour récupérer une base de données durant un redémarrage du système. Le moteur de base de données estime le nombre d’enregistrements de journal qu’il peut traiter au cours de l’ intervalle de récupération durant une opération de récupération.
L'intervalle entre les points de contrôle automatiques dépend également du mode de récupération :
Si la base de données utilise le mode de restauration complète ou le mode de récupération utilisant les journaux de transactions, un point de contrôle automatique est généré chaque fois que le nombre d’enregistrements du journal atteint une valeur que le moteur de base de données estime pouvoir traiter pendant la durée spécifiée dans l’option intervalle de récupération.
Si la base de données utilise le mode de récupération simple, un point de contrôle automatique est généré chaque fois que le nombre des enregistrements de journal atteint la plus faible de ces deux valeurs :
- Le journal est saturé à 70 %.
- Le nombre d’enregistrements de journal atteint le nombre que le moteur de base de données estime pouvoir traiter au cours de la durée spécifiée dans l’option intervalle de récupération.
Pour plus d’informations sur la configuration de l’intervalle de récupération, consultez Configurer l'intervalle de récupération (min) (option de configuration du serveur).
Conseil
L'option de configuration avancée de SQL Server-k permet à un administrateur de base de données de limiter le comportement d'E/S des points de contrôle en fonction du débit du sous-système d'E/S pour certains types de points de contrôle. L’option d’installation -k s’applique aux points de contrôle automatiques, ainsi qu’à tous les points de contrôle non accélérés.
Les points de contrôle automatiques tronquent la section inutilisée du journal des transactions si la base de données utilise le mode de récupération simple. Toutefois, si la base de données utilise les modèles de récupération complète ou en bloc, le journal n'est pas tronqué par les points de contrôle automatiques. Pour plus d’informations, consultez Journal des transactions.
L’instruction CHECKPOINT fournit désormais un argument checkpoint_duration facultatif qui spécifie la durée demandée, en secondes, permettant aux points de contrôle de terminer leurs tâches. Pour plus d’informations, consultez CHECKPOINT.
journal actif
La section du fichier journal comprise entre le MinLSN et le dernier enregistrement de journal écrit s’appelle la partie active du journal, ou journal actif. Cette section est indispensable pour procéder à une récupération complète de la base de données. Aucune partie de ce journal actif ne peut être tronquée. Tous les enregistrements de journal doivent être tronqués à partir des parties du journal situées avant le MinLSN.
Le diagramme suivant présente une version simplifiée de la fin d'un journal de transactions comportant deux transactions actives. Les enregistrements du point de contrôle ont été compactés en un enregistrement unique.

LSN 148 est le dernier enregistrement du journal des transactions. Au moment où le point de contrôle enregistré au numéro LSN 147 était traité, Tran 1 avait été validée et Tran 2 était la seule transaction active. Ainsi, le premier enregistrement de Tran 2 est l'enregistrement de journal le plus ancien pour une transaction active au moment du dernier point de contrôle. Par ailleurs, le numéro LSN 142 est l'enregistrement du début de la transaction pour Tran 2, la valeur MinLSN.
Transactions de longue durée
Le journal actif doit contenir chaque partie de toutes les transactions non validées. Une application qui démarre une transaction et qui ne la valide pas ou ne la restaure pas empêche le moteur de base de données de faire progresser le MinLSN. Cette situation peut provoquer deux types de problèmes :
- Si le système est arrêté après que la transaction a effectué de nombreuses modifications non validées, la phase de récupération lors du démarrage ultérieur peut être beaucoup plus longue que la durée spécifiée dans l’option intervalle de récupération .
- Le journal peut devenir très volumineux parce qu'il ne peut pas être tronqué au-delà du MinLSN. Cela se produit même si la base de données utilise le modèle de récupération simple, dans lequel le journal des transactions est généralement tronqué sur chaque point de contrôle automatique.
La récupération des transactions de longue durée et les problèmes décrits dans cet article peuvent être évités à l’aide de la récupération de base de données accélérée, une fonctionnalité disponible à partir de SQL Server 2019 (15.x) et dans Azure SQL Database.
Transactions de réplication
L'Agent de lecture du journal surveille le journal des transactions de chaque base de données configurée pour la réplication transactionnelle et copie les transactions devant être répliquées à partir du journal des transactions dans la base de données de distribution. Le journal actif doit contenir toutes les transactions qui sont marquées pour la réplication mais qui n'ont pas encore été transmises à la base de données de distribution. Si ces transactions ne sont pas répliquées à temps, elles peuvent empêcher la troncature du journal. Pour plus d’informations, consultez Réplication transactionnelle.
Contenu connexe
- Le journal des transactions
- Gérer la taille du fichier journal des transactions
- Sauvegardes du journal des transactions (SQL Server)
- Points de contrôle de base de données (SQL Server)
- Configurer l’intervalle de récupération (min) (option de configuration de serveur)
- Récupération de base de données accélérée
- sys.dm_db_log_info (Transact-SQL)
- sys.dm_db_log_space_usage (Transact-SQL)
- Fonctionnement de la journalisation et de la récupération dans SQL Server, par Paul Randall
- Gestion du journal des transactions SQL Server de Tony Davis et Gail Shaw