DBCC SHOW_STATISTICS (Transact-SQL)
S’applique à :![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)![]() Point de terminaison analytique SQL dans Microsoft Fabric
Point de terminaison analytique SQL dans Microsoft Fabric![]() Entrepôt dans Microsoft Fabric
Entrepôt dans Microsoft Fabric
Affiche les statistiques d’optimisation de la requête actuelle pour une table ou une vue indexée. L’optimiseur de requête utilise des statiques pour estimer la cardinalité ou le nombre de lignes dans le résultat de la requête, ce qui lui permet de créer un plan de requête de haute qualité. Par exemple, l'optimiseur de requête peut utiliser des estimations de cardinalité afin de choisir l'opérateur de recherche d'index plutôt que l'opérateur d'analyse d'index dans le plan de requête. Cela permettrait d'améliorer les performances des requêtes car le recours à une analyse d'index monopolisant de nombreuses ressources serait ainsi évité.
L'optimiseur de requête stocke des statistiques pour une table ou vue indexée dans un objet des statistiques. Pour une table, l'objet des statistiques est créé sur un index ou sur une liste de colonnes de table. L'objet des statistiques inclut un en-tête contenant des métadonnées sur les statistiques, un histogramme indiquant la distribution des valeurs dans la première colonne clé de l'objet des statistiques, et un vecteur de densité destiné à mesurer la corrélation entre les colonnes. Le Moteur de base de données peut calculer des estimations de cardinalité avec n’importe laquelle des données de l’objet des statistiques. Pour plus d’informations, consultez Statistics et Estimation de la cardinalité (SQL Server).
DBCC SHOW_STATISTICS affiche l'en-tête, l'histogramme et le vecteur de densité sur la base des données stockées dans l'objet des statistiques. La syntaxe vous permet de spécifier une table ou une vue indexée ainsi qu’un nom d'index cible, un nom de statistique ou un nom de colonne.
Mises à jour importantes dans les versions précédentes de SQL Server :
À compter de SQL Server 2012 (11.x) Service Pack 1, la vue de gestion dynamique sys.dm_db_stats_properties permet de récupérer programmatiquement les informations d’en-tête contenues dans l’objet de statistiques pour les statistiques non incrémentielles.
À compter de SQL Server 2014 (12.x) Service Pack 2 et SQL Server 2012 (11.x) Service Pack 1, la vue de gestion dynamique sys.dm_db_incremental_stats_properties permet de récupérer programmatiquement les informations d’en-tête contenues dans l’objet de statistiques pour les statistiques incrémentielles.
À compter de SQL Server 2016 (13.x) Service Pack 1 CU 2, la vue de gestion dynamique sys.dm_db_stats_histogram permet de récupérer programmatiquement les informations d’histogramme contenues dans l’objet de statistiques.
-
Cette syntaxe n’est pas prise en charge par le pool SQL serverless dans Azure Synapse Analytics.
Pour plus d’informations sur les statistiques dans Microsoft Fabric, consultez Statistiques.
![]() Conventions de la syntaxe Transact-SQL
Conventions de la syntaxe Transact-SQL
Syntaxe
Syntaxe pour SQL Server et Azure SQL Database :
DBCC SHOW_STATISTICS ( table_or_indexed_view_name , target )
[ WITH [ NO_INFOMSGS ] < option > [ , ...n ] ]
< option > ::=
STAT_HEADER | DENSITY_VECTOR | HISTOGRAM | STATS_STREAM
[ ; ]
Syntaxe suivante pour Azure Synapse Analytics, Analytics Platform System (PDW) et Microsoft Fabric :
DBCC SHOW_STATISTICS ( table_name , target )
[ WITH { STAT_HEADER | DENSITY_VECTOR | HISTOGRAM } [ , ...n ] ]
[ ; ]
Remarque
Pour afficher la syntaxe Transact-SQL pour SQL Server 2014 (12.x) et versions antérieures, consultez Versions antérieures de la documentation.
Arguments
table_or_indexed_view_name
Nom de la table ou de la vue indexée dont les informations statistiques doivent être affichées.
table_name
Nom de la table qui contient les statistiques à afficher. La table ne peut pas être une table externe.
cible
Nom de l'index, de la statistique ou de la colonne dont les informations statistiques doivent être affichées. target est placé entre crochets, guillemets simples, guillemets doubles, ou se présente tel quel.
- Si target est le nom d’une statistique ou d’un index existant dans une table ou une vue indexée, les informations statistiques concernant cette cible sont retournées.
- Si cible est le nom d’une colonne existante et que celle-ci contient un objet de statistiques créé automatiquement, les informations sur cette dernière sont retournées.
S’il n’existe pas de statistique créée automatiquement pour une cible de colonne, le message d’erreur 2767 est retourné.
Dans Azure Synapse Analytics et Analytics Platform System (PDW), la cible ne peut pas être un nom de colonne.
Dans l’entrepôt dans Microsoft Fabric, target peut être le nom d’un histogramme unique ou d’une colonne. Si un nom de colonne est utilisé pour cible, cette commande retourne des informations de distribution uniquement sur la statistique d’histogramme générée automatiquement. Pour afficher les informations relatives à une statistique d’histogramme créée manuellement, spécifiez le nom des statistiques comme target.
NO_INFOMSGS
Supprime tous les messages d'information dont les niveaux de gravité sont compris entre 0 et 10.
STAT_HEADER | DENSITY_VECTOR | HISTOGRAM | STATS_STREAM [ , n ]
La spécification d'une ou de plusieurs de ces options limite les jeux de résultats retournés par l'instruction aux options spécifiées. Si aucune option n'est spécifiée, toutes les informations statistiques sont retournées.
STATS_STREAM est Identifié à titre d'information uniquement. Non pris en charge. La compatibilité future n'est pas garantie.
Jeu de résultats
Le tableau suivant décrit les colonnes retournées dans le jeu de résultats lorsque STAT_HEADER est spécifié.
| Nom de la colonne | Description |
|---|---|
| Nom | Nom de l'objet de statistiques. |
| Mis à jour | Date et heure de la dernière mise à jour des statistiques. La fonction STATS_DATE offre une autre manière de récupérer ces informations. Pour plus d’informations, consultez la section Notes dans cette page. |
| Lignes | Nombre total de lignes dans la table ou la vue indexée au moment de la dernière mise à jour des statistiques. Si les statistiques sont filtrées ou correspondent à un index filtré, le nombre de lignes peut être inférieur à celui de la table. Pour plus d’informations, consultez Statistiques. |
| Lignes échantillonnées | Nombre total de lignes échantillonnées pour le calcul des statistiques. Si Échantillon de lignes < Lignes, l'histogramme et les résultats de densité affichés sont des estimations basées sur les échantillons de lignes. |
| Étapes | Nombre d'étapes dans l'histogramme. Chaque étape couvre une plage de valeurs de colonnes suivie d'une valeur de colonne de limite supérieure. Les étapes d'histogramme sont définies sur la première colonne clé des statistiques. Le nombre maximal d'étapes est 200. |
| Densité | La formule 1 / valeurs distinctes est utilisée pour toutes les valeurs de la première colonne clé de l’objet de statistiques, à l’exception des valeurs limites de l’histogramme. Cette valeur de densité n’est pas utilisée par l’optimiseur de requête. Elle est affichée pour la compatibilité descendante avec les versions antérieures à SQL Server 2008 (10.0.x). |
| Longueur moyenne d'une clé | Nombre moyen d'octets par valeur pour toutes les colonnes clés de l'objet de statistiques. |
| String Index | La valeur Yes indique que l'objet de statistiques contient des statistiques de résumé de chaîne pour améliorer les estimations de cardinalité des prédicats de requête qui utilisent l'opérateur LIKE ; c'est le cas par exemple de WHERE ProductName LIKE '%Bike'. Les statistiques de résumé de chaîne sont stockées à l’écart de l’histogramme et créées sur la première colonne clé de l’objet des statistiques quand il est de type char, varchar, nchar, nvarchar, varchar(max), nvarchar(max) , text ou ntext. |
| Expression de filtre | Prédicat pour le sous-ensemble des lignes de table incluses dans l'objet de statistiques. NULL = statistiques non filtrées. Pour plus d’informations sur les prédicats filtrés, consultez Créer des index filtrés. Pour plus d’informations sur les statistiques filtrées, consultez Statistiques. |
| Lignes non filtrées | Nombre total de lignes dans la table avant l'application de l'expression de filtre. Si l’expression de filtre est NULL, Unfiltered Rows est égal à Rows. |
| Pourcentage d’échantillon persistant | Pourcentage d’échantillon persistant utilisé pour les mises à jour des statistiques qui ne spécifient pas explicitement un pourcentage d’échantillonnage. Si la valeur est zéro, aucun pourcentage d’échantillon persistant n’est défini pour cette statistique. S’applique à : SQL Server 2016 (13.x) Service Pack 1 CU 4 |
Le tableau suivant décrit les colonnes retournées dans le jeu de résultats lorsque DENSITY_VECTOR est spécifié.
| Nom de la colonne | Description |
|---|---|
| Toutes les densités | La densité est calculée selon la formule 1 / valeurs distinctes. Les résultats affichent la densité pour chaque préfixe des colonnes de l'objet de statistiques, à raison d'une ligne par densité. Une valeur distincte est une liste distincte des valeurs de colonnes par ligne et par préfixe de colonne. Par exemple, si l'objet de statistiques contient des colonnes clés (A, B, C), les résultats rapportent la densité des listes distinctes de valeurs dans chacun des préfixes de colonnes suivants : (A), (A,B) et (A, B, C). Avec le préfixe (A, B, C), chacune des listes suivantes est une liste de valeurs distincte : (3, 5, 6), (4, 4, 6), (4, 5, 6), (4, 5, 7). Avec le préfixe (A, B) les listes de valeurs distinctes suivantes sont associées aux mêmes valeurs de colonnes : (3, 5), (4, 4) et (4, 5) |
| Longueur moyenne | Longueur moyenne, en octets, pour le stockage d'une liste des valeurs de colonnes pour le préfixe de colonne. Par exemple, si les valeurs dans la liste (3, 5, 6) nécessitent 4 octets chacune, la longueur est égale à 12 octets. |
| Colonnes | Noms des colonnes dans le préfixe dont les valeurs Toutes les densités et Longueur moyenne sont affichées. |
Le tableau suivant décrit les colonnes retournées dans le jeu de résultats lorsque l'option HISTOGRAM est spécifiée.
| Nom de la colonne | Description |
|---|---|
| RANGE_HI_KEY | Valeur de colonne de limite supérieure pour une étape d'histogramme. La valeur de colonne est également appelée « valeur de clé ». |
| RANGE_ROWS | Nombre estimé de lignes dont la valeur de colonne est comprise dans une étape d'histogramme, à l'exception de la limite supérieure. |
| EQ_ROWS | Nombre estimé de lignes dont la valeur de colonne est égale à la limite supérieure de l'étape d'histogramme. |
| DISTINCT_RANGE_ROWS | Nombre estimé de lignes ayant une valeur de colonne distincte dans une étape d'histogramme, à l'exception de la limite supérieure. |
| AVG_RANGE_ROWS | Nombre moyen de lignes ayant des valeurs de colonnes dupliquées dans une étape d’histogramme, à l’exception de la limite supérieure. Quand DISTINCT_RANGE_ROWS est supérieur à 0, AVG_RANGE_ROWS est calculé en divisant RANGE_ROWS par DISTINCT_RANGE_ROWS. Quand DISTINCT_RANGE_ROWS est 0, AVG_RANGE_ROWS retourne 1 pour l’étape d’histogramme. |
Remarques
La date de mise à jour des statistiques est stockée dans l’objet blob de statistiques avec l’histogramme et le vecteur de densité, et non dans les métadonnées. Quand aucune donnée n’est lue pour générer des données de statistiques, le blob des statistiques n’est pas créé, la date n’est pas disponible et la colonne mise à jour a la valeur NULL. C’est le cas pour les statistiques filtrées pour lesquelles le prédicat ne renvoie aucune ligne, ou pour les nouvelles tables vides.
Histogramme
Un histogramme mesure la fréquence des occurrences de chaque valeur distincte dans un jeu de données. L'optimiseur de requête calcule un histogramme sur les valeurs de colonnes de la première colonne clé de l'objet de statistiques, en sélectionnant les valeurs de colonnes au moyen d'un échantillonnage statistique des lignes ou d'une analyse complète de toutes les lignes dans la table ou la vue. Si l’histogramme est créé à partir d’un jeu de lignes échantillonnées, les totaux stockés pour le nombre de lignes et le nombre de valeurs distinctes sont des estimations et ne doivent pas nécessairement être des nombres entiers.
Pour créer l'histogramme, l'optimiseur de requête trie les valeurs de colonnes, calcule le nombre de valeurs qui correspondent à chaque valeur de colonne distincte, puis regroupe les valeurs de colonnes dans 200 étapes d'histogramme contiguës au maximum. Chaque étape inclut une plage de valeurs de colonnes suivie d'une valeur de colonne de limite supérieure. La plage comprend toutes les valeurs de colonnes possibles entre des valeurs limites, à l'exception des valeurs limites elles-mêmes. La plus basse des valeurs de colonnes triées est la valeur de limite supérieure pour la première étape d'histogramme.
Le diagramme suivant illustre un histogramme avec six étapes : La zone située à gauche de la première valeur limite supérieure représente la première étape.

Pour chaque étape d'histogramme :
- La ligne en gras représente la valeur limite supérieure (RANGE_HI_KEY) et le nombre d'occurrences (EQ_ROWS) correspondant.
- La zone pleine située à gauche de RANGE_HI_KEY représente la plage de valeurs de colonnes et le nombre moyen d'occurrences de chacune des valeurs de colonnes (AVG_RANGE_ROWS). La valeur AVG_RANGE_ROWS pour la première étape d'histogramme est toujours 0.
- Les lignes pointillées représentent les valeurs échantillonnées utilisées pour estimer le nombre total de valeurs distinctes dans la plage (DISTINCT_RANGE_ROWS) et le nombre total de valeurs dans la plage (RANGE_ROWS). L’optimiseur de requête utilise les valeurs RANGE_ROWS et DISTINCT_RANGE_ROWS pour calculer la valeur AVG_RANGE_ROWS ; il ne stocke pas les valeurs échantillonnées.
L'optimiseur de requête définit les étapes d'histogramme en fonction de leur importance statistique. Il utilise un algorithme de nombre maximal de différences pour réduire le nombre d'étapes dans l'histogramme tout en augmentant la différence entre les valeurs limites. Le nombre maximal d'étapes est 200. Le nombre d'étapes d'histogramme peut être inférieur au nombre de valeurs distinctes, même pour les colonnes comportant moins de 200 points de limite. Par exemple, une colonne avec 100 valeurs distinctes peut avoir un histogramme comportant moins de 100 points de limite.
Vecteur de densité
L'optimiseur de requête utilise des densités afin d'améliorer les estimations de cardinalité pour les requêtes qui retournent plusieurs colonnes à partir de la même table ou vue indexée. Le vecteur de densité contient une densité pour chaque préfixe des colonnes dans l'objet de statistiques. Par exemple, si un objet de statistiques contient les colonnes clés CustomerId, ItemId et Price, la densité est calculée à partir des préfixes de colonnes suivants :
| Préfixe de colonne | Densité calculée sur |
|---|---|
(CustomerId) |
Lignes avec des valeurs correspondantes pour CustomerId |
(CustomerId, ItemId) |
Lignes avec des valeurs correspondantes pour CustomerId et ItemId |
(CustomerId, ItemId, Price) |
Lignes avec des valeurs correspondantes pour CustomerId, ItemIdet Price |
Limites
DBCC SHOW_STATISTICS ne fournit pas de statistiques pour les index spatiaux ni pour les index columnstore à mémoire optimisée.
Autorisations pour SQL Server et SQL Database
Pour afficher l’objet de statistiques, l’utilisateur doit disposer de l’autorisation SELECT sur la table.
Les exigences suivantes doivent être remplies pour que les autorisations SELECT permettent d'exécuter la commande :
- Les utilisateurs doivent posséder des autorisations sur toutes les colonnes dans l'objet de statistiques.
- Les utilisateurs doivent posséder une autorisation sur toutes les colonnes dans une condition de filtre (le cas échéant).
- La table ne peut pas avoir une stratégie de sécurité au niveau des lignes.
- Si l’une des colonnes d’un objet de statistiques est masquée par des règles Dynamic Data Masking, l’utilisateur doit disposer, en plus de l’autorisation
SELECT, de l’autorisationUNMASKou être un membre du rôle db_ddladmin.
Dans les versions antérieures à SQL Server 2012 (11.x) Service Pack 1, l’utilisateur doit être propriétaire de la table, ou être membre du rôle serveur fixe administrateur système, du rôle de base de données fixe db_owner ou du rôle de base de données fixe db_ddladmin.
Remarque
Pour rétablir le comportement antérieur à SQL Server 2012 (11.x) Service Pack 1, utilisez l’indicateur de trace 9485.
Autorisations pour Azure Synapse Analytics et Analytics Platform System (PDW)
DBCC SHOW_STATISTICS exige l’autorisation SELECT sur la table ou l’appartenance au rôle serveur fixe sysadmin, au rôle de base de données fixe db_owner ou au rôle de base de données fixe db_ddladmin.
Limitations et restrictions pour Azure Synapse Analytics et Analytics Platform System (PDW)
DBCC SHOW_STATISTICS affiche les statistiques stockées dans la base de données Shell au niveau du nœud de contrôle. Il n’affiche pas les statistiques créées automatiquement par SQL Server sur les nœuds de calcul.
DBCC SHOW_STATISTICS n’est pas pris en charge sur les tables externes.
Dans Microsoft Fabric, DBCC SHOW_STATISTICS affiche uniquement les résultats pour les statistiques d’histogramme, et non les statistiques ACE-*.
Exemples : SQL Server et Azure SQL Database
R. Retourner toutes les informations statistiques
L’exemple suivant affiche toutes les informations statistiques relatives à l’index AK_Address_rowguid de la table Person.Address dans la base de données AdventureWorks2022.
DBCC SHOW_STATISTICS ("Person.Address", AK_Address_rowguid);
GO
B. Utiliser l'option HISTOGRAM
Cela limite les informations statistiques affichées pour Customer_LastName aux données HISTOGRAM.
DBCC SHOW_STATISTICS ("dbo.DimCustomer", Customer_LastName) WITH HISTOGRAM;
GO
Exemples : Azure Synapse Analytics et Analytics Platform System (PDW)
C. Afficher le contenu d’un objet des statistiques
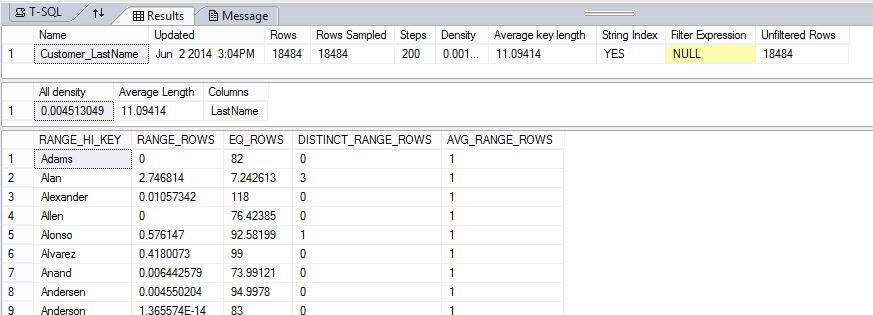
L'exemple suivant crée un objet de statistiques, puis affiche le contenu des statistiques Customer_LastName sur la table DimCustomer de l'exemple de base de données AdventureWorksPDW2022.
-- Uses AdventureWorksPDW
--First, create a statistics object
CREATE STATISTICS Customer_LastName
ON AdventureWorksPDW2012.dbo.DimCustomer (LastName);
GO
DBCC SHOW_STATISTICS ("dbo.DimCustomer", Customer_LastName);
GO
Les résultats indiquent l’en-tête, le vecteur de densité et une partie de l’histogramme.
Voir aussi
- Statistiques
- Statistiques dans Microsoft Fabric
- sys.dm_db_stats_properties (Transact-SQL)
- sys.dm_db_stats_histogram (Transact-SQL)
- sys.dm_db_incremental_stats_properties (Transact-SQL)
Étapes suivantes
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour