Vue d’ensemble des cubes OLAP Service Manager pour l’analytique avancée
Dans Service Manager, les données présentes dans l’entrepôt de données peuvent être consolidées à partir de différentes sources. Il est présenté via Service Manager à l’aide de cubes de données Microsoft Online Analytical Processing (OLAP) prédéfinis et personnalisés. En bref, l’analytique avancée dans Service Manager consiste à publier, afficher et manipuler des données de cube, généralement dans Microsoft Excel ou Microsoft SharePoint. Excel est principalement utilisé pour afficher et manipuler les données. SharePoint, quant à lui, est essentiellement utilisé pour la publication et le partage des données de cube.
Service Manager inclut un entrepôt de données à l’échelle de System Center. Par conséquent, les données d’Operations Manager, Configuration Manager et Service Manager peuvent être consolidées dans l’entrepôt de données, où vous pouvez facilement utiliser plusieurs vues de données pour obtenir les informations souhaitées. Cette interface vous permet également de placer les données dans le même entrepôt de données que vos propres sources personnalisées, telles que les applications SAP ou autre application tierce de gestion des ressources humaines. Cette consolidation crée un modèle de données commun et permet d'effectuer des analyses enrichies qui vous permettront de constituer un entrepôt de données pour votre service informatique, et de répondre ainsi à l'ensemble de vos besoins en matière de décisionnel et de création de rapports.
Lorsque vos données se trouvent dans un modèle commun, vous avez la possibilité de manipuler des informations et d'avoir des définitions communes, ainsi qu'une taxonomie commune pour l'ensemble de votre entreprise. Pour cela, il vous suffit de déployer des cubes de données OLAP et d'accéder aux informations des cubes, à l'aide d'outils standard, tels qu'Excel et SharePoint. Cela permet à vos utilisateurs d'employer des compétences qu'ils possèdent déjà. Vous contrôlez la définition de votre logique métier de manière centralisée. Par exemple, vous pouvez définir des indicateurs de performance clés, tels que des seuils de temps moyen de résolution des incidents, et des valeurs de seuil (vert, jaune ou rouge). Toutes ces options peuvent être sélectionnées au même endroit, ce qui facilite l'utilisation des données. En outre, la définition commune apparaît dans tous les rapports Excel ou tableaux de bord SharePoint.
À propos des cubes OLAP Service Manager
Les cubes OLAP (Online Analytical Processing) sont une fonctionnalité de Service Manager qui utilise l’infrastructure d’entrepôt de données existante pour fournir des fonctionnalités décisionnels en libre-service aux utilisateurs finaux.
Un cube OLAP est une structure de données supérieure aux bases de données relationnelles grâce à une analyse rapide des données. Les cubes peuvent afficher et additionner de grandes quantités de données, tout en permettant de parcourir le contenu des points de données. De cette façon, les données peuvent être regroupées, segmentées et désécrites selon les besoins pour gérer la plus grande variété de questions pertinentes pour la zone d’intérêt d’un utilisateur.
Les éditeurs de logiciels ou les développeurs informatiques disposant d’une connaissance pratique des cubes OLAP peuvent créer des packs d’administration pour définir leurs propres cubes OLAP extensibles et personnalisables basés sur l’infrastructure de l’entrepôt de données. Ces cubes sont stockés dans SQL Server Analysis Services (SSAS). Les outils d'aide à la décision libre-service tels qu'Excel et SQL Server Reporting Services (SSRS) peuvent vous permettre de cibler ces cubes dans SSAS, et ainsi de les utiliser pour analyser les données de plusieurs façons.
Les bases de données utilisées par une entreprise pour stocker l’ensemble de ses transactions et enregistrements sont appelées bases de données de traitement transactionnel en ligne (OLTP). Ces bases de données comprennent généralement des enregistrements entrés l'un après l'autre, qui contiennent un grand nombre d'informations pouvant être utilisées par les responsables stratégie pour prendre des décisions avisées concernant leur entreprise. Toutefois, les bases de données utilisées pour stocker les données n’ont pas été conçues pour l’analyse. Par conséquent, la récupération de réponses en provenant est à la fois coûteuse et laborieuse. Les bases de données OLAP sont des bases de données spécialisées conçues pour aider à l'extraction de ces informations décisionnelles.
Les cubes OLAP sont en quelque sorte l'apport final d'une solution d'entrepôt de données. Le cube OLAP, également appelé cube multidimensionnel ou hypercube, est une structure de données SQL Server Analysis Services (SSAS) créée à l'aide de bases de données OLAP, qui permet une analyse quasi-instantanée des données. La topologie du système est indiquée dans l'illustration suivante.
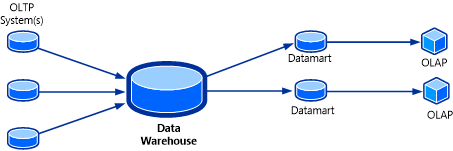
L'intérêt du cube OLAP est que les données qu'il contient peuvent être agrégées. Aux yeux de l'utilisateur, le cube semble avoir les réponses à l'avance, car les assortiments de valeurs y sont déjà précalculés. Le cube peut renvoyer les réponses à de nombreuses questions presque instantanément, sans avoir à interroger la base de données de source OLAP.
L’objectif principal des cubes OLAP Service Manager est de donner aux développeurs de logiciels ou de technologies informatiques la possibilité d’effectuer une analyse quasi instantanée des données à des fins d’analyse historique et de tendance. Service Manager effectue cette opération en procédant comme suit :
- Il permet de définir les cubes OLAP des packs d'administration qui seront créés automatiquement dans SSAS une fois le pack d'administration déployé.
- Il effectue une maintenance automatique du cube sans intervention de l'utilisateur, qui se traduit notamment par des tâches de traitement, de partitionnement, de traduction et de localisation, et de modifications des schémas.
- Il permet aux utilisateurs d'utiliser les outils d'aide à la décision libre-service tels qu'Excel, pour analyser les données de plusieurs façons.
- Il enregistre les rapports Excel générés pour référence ultérieure.
Pour voir comment les cubes d’entrepôt de données sont représentés dans la console Service Manager, accédez à l’espace de travail Data Warehouse , puis sélectionnez Cubes.
Cubes OLAP service Manager
L'illustration suivante est une capture d'écran de SQL Server Business Intelligence Development Studio (BIDS) montrant les principaux éléments requis pour les cubes OLAP. Ces éléments sont la source de données, la vue de source de données, les cubes et les dimensions. Les sections suivantes abordent les différents éléments du cube OLAP, ainsi que les actions possibles.
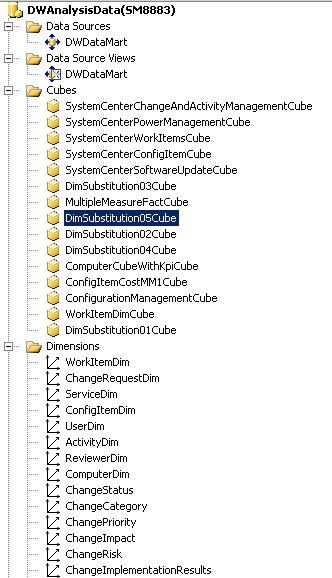
Source de données
Une source de données est l'origine de toutes les données contenues dans un cube OLAP. Un cube OLAP se connecte à une source de données pour lire et traiter des données brutes afin d'effectuer des calculs et des agrégations pour les mesures qui lui sont associées. La source de données de tous les cubes OLAP Service Manager est les data marts, qui incluent les data marts pour Operations Manager et Configuration Manager. Les informations d'authentification de la source de données doivent être stockées dans SQL Server Analysis Services (SSAS) afin d'établir le niveau d'autorisations approprié.
Vue de source de données
La vue de source de données (DSV) est une collection de vues qui représentent la dimension, les faits et les tables d’outrigger de la source de données, telles que les magasins de données Service Manager. La vue de source de données contient toutes les relations établies entre les tables, telles que les clés primaires et étrangères. En d'autres termes, la vue de source de données spécifie la manière dont la base de données SSAS sera mappée vers le schéma relationnel, et fournit une couche d'abstraction par-dessus la base de données relationnelle. Grâce à cette couche d'abstraction, des relations peuvent être définies entre les tables de faits et de dimensions, même s'il n'existe aucune relation dans la base de données relationnelle source. Les calculs nommés, les mesures personnalisées et les nouveaux attributs peuvent également être définis dans la vue de source de données qui peut ne pas exister nativement dans le schéma de dimensions de l'entrepôt de données. Par exemple, un calcul nommé qui définit une valeur booléenne pour incidents résolus calcule la valeur comme true si l’état d’un incident est résolu ou fermé. À l’aide du calcul nommé, Service Manager peut ensuite définir une mesure pour afficher des informations utiles telles que le pourcentage d’incidents résolus, le nombre total d’incidents résolus et le nombre total d’incidents qui ne sont pas résolus.
Un autre exemple de calcul nommé est ReleasesImplementedOnSchedule. Ce calcul nommé permet une vérification rapide de l'état d'intégrité des enregistrements de version dont la date de fin est antérieure ou identique à la date de fin planifiée.
Cubes OLAP
Un cube OLAP est une structure de données supérieure aux bases de données relationnelles grâce à une analyse rapide des données. Les cubes OLAP peuvent afficher et additionner de grandes quantités de données tout en fournissant aux utilisateurs un accès pouvant faire l’objet d’une recherche à tous les points de données afin que les données puissent être regroupées, segmentées et désécrites selon les besoins pour gérer la plus grande variété de questions pertinentes pour la zone d’intérêt d’un utilisateur.
Dimensions
Une dimension dans SSAS fait référence à une dimension de l’entrepôt de données Service Manager. Dans Service Manager, une dimension équivaut approximativement à une classe de pack d’administration. Chaque classe de pack d'administration possède une liste de propriétés. Les dimensions, quant à elles, contiennent chacune une liste d'attributs, où chacun d'eux est mappé vers une propriété de classe. Les dimensions permettent de filtrer, de regrouper et d'étiqueter des données. Par exemple, vous pouvez filtrer les ordinateurs par système d'exploitation, et les groupes de personnes des catégories par âge ou par sexe. Les données peuvent ensuite être présentées dans un format où les données sont classées naturellement dans ces hiérarchies et catégories pour permettre une analyse plus approfondie. Les dimensions peuvent également avoir des hiérarchies naturelles pour permettre aux utilisateurs de « descendre dans la hiérarchie » vers des niveaux de détail plus détaillés. Par exemple, la dimension Date possède une hiérarchie pouvant être détaillée par année, trimestre, mois, semaine et jour.
L'illustration suivante montre un cube OLAP contenant les dimensions Date, Region et Product.
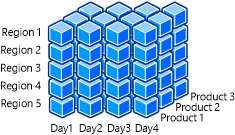
Par exemple, les membres de l’équipe Microsoft peuvent souhaiter un résumé rapide et simple des ventes de la console de jeu Xbox One dans la version applicable. Ils peuvent l'explorer au niveau du détail pour obtenir les chiffres des ventes pour une période plus ciblée. Les analystes professionnels peuvent souhaiter examiner la façon dont les ventes de consoles Xbox One ont été affectées par le lancement de la nouvelle conception de console et de Kinect pour Xbox One. Cela leur permet de connaître les tendances actuelles des ventes, ainsi que les éventuelles révisions nécessaires de la stratégie commerciale. Grâce au filtrage par dimension Date, ces informations peuvent être rapidement fournies et utilisées. Ce découpage des données est possible uniquement parce que les dimensions ont été conçues avec des attributs et des données pouvant être facilement filtrées et regroupées par client.
Dans Service Manager, tous les cubes OLAP partagent un ensemble commun de dimensions. Toutes les dimensions utilisent le mini-Data Warehouse principal comme source, même lorsqu'il existe plusieurs mini-Data Warehouse. L'existence de plusieurs mini-Data Warehouse peut entraîner des erreurs de clé de dimension pendant le traitement du cube.
Groupe de mesures
Un groupe de mesures correspond à ce que l'on appelle un fait dans l'entrepôt de données. De la même façon que les faits de l'entrepôt de données contiennent des mesures numériques, les groupes de mesures contiennent les mesures d'un cube OLAP. Toutes les mesures de cube OLAP dérivées d'une même table de faits appartenant à une vue de source de données peuvent également être considérées comme un groupe de mesures. Toutefois, dans certains cas, il est possible d'avoir plusieurs tables de faits desquelles seront dérivées les mesures d'un cube OLAP. Les mesures ayant le même niveau de détail sont rassemblées au sein d'un groupe de mesures. Les groupes de mesures permettent de définir les données à charger dans le système, la façon dont elles doivent être chargées, ainsi que la façon dont elles sont liées au cube multidimensionnel.
Chaque groupe de mesures contient également une liste de partitions, où les données sont contenues dans des sections distinctes et non superposées. Les groupes de mesures comprennent également la conception d'agrégation, qui définit les ensembles de données précondensées qui sont calculés pour chaque groupe de mesures afin d'améliorer les performances des requêtes utilisateur.
Mesures
Les mesures sont les valeurs numériques que les utilisateurs souhaitent segmenter, dés, agréger et analyser ; c’est l’une des raisons fondamentales pour lesquelles vous souhaitez créer des cubes OLAP à l’aide de l’infrastructure d’entreposage de données. À l'aide de SSAS, vous pouvez créer des cubes OLAP qui appliqueront des règles d'entreprise et des calculs pour mettre en forme et afficher les mesures dans un format personnalisable. Lors du développement de cubes OLAP, vous consacrerez la majeure partie de votre temps à déterminer et définir les mesures qui devront être affichées, ainsi que la façon dont elles devront être calculées.
Les mesures sont des valeurs qui sont généralement mappées vers les colonnes numériques d'une table de faits de l'entrepôt de données, mais peuvent également être créées dans les attributs des dimensions (dégénérées ou non). Ces mesures sont les valeurs analysées les plus importantes d'un cube OLAP. Elles constituent en outre l'intérêt principal des utilisateurs finaux qui parcourent le contenu d'un cube OLAP. ActivityTotalTimeMeasure est l'une des mesures présentes dans l'entrepôt de données. ActivityTotalTimeMeasure provient d'ActivityStatusDurationFact qui représente la durée que reste une activité dans un état donné. Le niveau de détail d'une mesure est constitué de toutes les dimensions référencées. Par exemple, le niveau de détail du fait de relation ComputerHostsOperatingSystem est constitué des dimensions Computer et Operating System.
Les fonctions d'agrégation sont calculées à l'aide des mesures pour permettre l'analyse de données supplémentaires. La fonction d'agrégation la plus courante est Sum. L'une des requêtes courantes de cube OLAP, par exemple, additionne la durée totale de toutes les activités dont l'état est In Progress. Les autres fonctions d'agrégation courantes sont notamment Min, Max et Count.
Une fois les données brutes traitées au sein du cube OLAP, les utilisateurs peuvent exécuter des calculs et des requêtes plus complexes à l'aide d'expressions multidimensionnelles (MDX), afin de définir leurs propres expressions de mesures et membres calculés. Les expressions multidimensionnelles constituent la norme en matière d'interrogation et d'accès aux données stockées sur les systèmes OLAP. SQL Server n’a pas été conçu pour fonctionner avec le modèle de données pris en charge par les bases de données multidimensionnelles.
Exploration
Lorsqu'un utilisateur explore en détail les données d'un cube OLAP, il peut les analyser à différents niveaux de synthèse. Le niveau de détail des données change à mesure que l'utilisateur descend dans la hiérarchie (« drill down »). À mesure que les utilisateurs descendent, ils passent des informations récapitulatives aux données avec un focus plus étroit. Voici quelques exemples d'exploration des détails :
- Exploration des données démographiques des États-Unis, puis de l'État de Washington, puis de la région de Seattle, puis de la ville de Redmond, puis de la société Microsoft.
- Descendre dans les chiffres de vente des consoles Xbox One pour l’année civile 2015, puis le quatrième trimestre de l’année, puis le mois de décembre, puis la semaine avant Noël, et enfin la veille de Noël.
Extraire
Lorsque les utilisateurs explorent les données, ils souhaitent voir toutes les transactions individuelles qui ont contribué aux données agrégées du cube OLAP. En d'autres termes, ils peuvent récupérer des données davantage synthétisées pour une valeur de mesure donnée. Par exemple, lorsque vous recevez les données de ventes d’un mois et d’une catégorie de produit particuliers, vous pouvez explorer ces données pour afficher une liste de chaque ligne de table contenue dans cette cellule de données.
Il est courant de confondre les termes dans la hiérarchie et d’explorer les uns avec les autres. La principale différence entre eux est qu’une exploration fonctionne sur une hiérarchie prédéfinie de données, par exemple aux États-Unis, puis dans Washington, puis dans Seattle dans le cube OLAP. L'extraction, quant à elle, permet d'accéder directement à un niveau de détail moins élevé, et de récupérer un ensemble de lignes provenant d'une source de données et ayant été agrégées au sein d'une même cellule.
Indicateur de performance clé
Les organisations peuvent utiliser des indicateurs de performance clés (KPI) pour évaluer la santé de leur entreprise, ainsi que leurs performances, en mesurant les progrès réalisés dans le cadre des objectifs prédéfinis. Les indicateurs de performance clés sont des mesures pouvant être définies pour évaluer les progrès réalisés dans le cadre des objectifs prédéfinis. Un indicateur de performance clé a une valeur cible et une valeur réelle, qui représente un objectif quantitatif essentiel au succès de l’organisation. Les indicateurs de performance clés sont affichés dans des groupes sur une carte de performance pour afficher l’intégrité globale de l’entreprise dans un instantané rapide.
Un exemple d'indicateur de performance clé est le fait de pouvoir effectuer toutes les demandes de modification en 48 heures. Un indicateur de performance clé peut servir à calculer le pourcentage de demandes de modification ayant été effectuées au cours de cette période. Vous pouvez créer des tableaux de bord pour représenter visuellement les indicateurs de performance clés. Par exemple, vous pouvez souhaiter définir la valeur cible d'indicateur de performance clé sur 75 % (des demandes de modification effectuées en 48 heures).
Partitions
Une partition est une structure de données qui contient une partie ou la totalité des données d'un groupe de mesures. Chaque groupe de mesures est divisé en partitions. Une partition définit le sous-ensemble de données de faits qui est chargé dans le groupe de mesures. SSAS Standard Edition n'autorise qu'une seule partition par groupe de mesures, tandis que SSAS Enterprise Edition permet aux groupes de mesures de contenir plusieurs partitions. Les partitions sont une fonctionnalité transparente pour l’utilisateur final, mais elles ont un impact majeur sur les performances et l’extensibilité des cubes OLAP. Toutes les partitions d'un groupe de mesures se trouvent toujours dans la même base de données physique.
Les partitions permettent à un administrateur de mieux gérer un cube OLAP et d’améliorer les performances d’un cube OLAP. Par exemple, vous pouvez supprimer ou retraiter les données dans une partition d'un groupe de mesures sans affecter le reste du groupe de mesures. Lorsque vous chargez des nouvelles données dans une table de faits, seules les partitions devant contenir les nouvelles données sont affectées.
Le partitionnement améliore également les performances de traitement et de requête pour les cubes OLAP. SSAS peut traiter plusieurs partitions en parallèle, conduisant à une utilisation beaucoup plus efficace des ressources processeur et mémoire sur le serveur. Pendant qu’elle exécute une requête, SSAS extrait, traite et agrège également les données de plusieurs partitions, seules les partitions qui contiennent les données pertinentes pour une requête sont analysées, ce qui réduit la quantité globale d’entrée et de sortie.
Un exemple de stratégie de partitionnement consiste à placer les données de faits pour chaque mois dans une partition mensuelle. À la fin de chaque mois, les nouvelles données passent dans une nouvelle partition, ce qui conduit à une distribution physique des données avec des valeurs qui ne superposent pas.
Agrégations
Les agrégations dans un cube OLAP sont des ensembles de données résumés au préalable. Elles sont analogues à une instruction SQL SELECT avec une clause GROUP BY. SSAS peut utiliser ces agrégations lorsqu'il répond aux requêtes afin de réduire la quantité de calculs nécessaires, ce qui lui permet de répondre rapidement à l'utilisateur. Les agrégations intégrées dans le cube OLAP réduisent la quantité d'agrégations que SSAS a effectuées au moment de la requête. La création d'agrégations correctes peut considérablement améliorer les performances des requêtes. Ce processus évolue souvent tout au long de la durée de vie du cube OLAP à mesure que ses requêtes et son utilisation changent.
Un ensemble de base d'agrégations est généralement créé et il sera utile pour la plupart des requêtes sur le cube OLAP. Les agrégations sont créées pour chaque partition d'un cube OLAP dans un groupe de mesures. Lors de la génération d'une agrégation, certains attributs des dimensions sont inclus dans le jeu de données résumé au préalable. Les utilisateurs peuvent interroger rapidement les données selon ces agrégations lorsqu'ils parcourent le cube OLAP. Les agrégations doivent être conçues avec soin, car le nombre d'agrégations potentielles est tellement grand que la création de tous occuperait une quantité excessive d'espace de stockage et prendrait beaucoup de temps.
Service Manager utilise les deux options suivantes quand il génère et conçoit des agrégations dans des cubes OLAP Service Manager :
- Les gains de performance atteignent
- Optimisation basée sur l'utilisation
L'option Les gains de performance atteignent définit le pourcentage d'agrégations créées. Par exemple, la définition de cette option sur la valeur par défaut et la valeur recommandée de 30 % signifie que les agrégations seront conçues pour donner au cube OLAP un gain de performance estimé à 30 %. Toutefois, cela ne signifie pas que 30 % des agrégations possibles seront générées.
L'optimisation basée sur l'utilisation permet à SSAS de journaliser les demandes de données de sorte que lorsqu'une requête est exécutée, les informations sont chargées dans le processus de conception d'agrégation. Ensuite, SSAS passe en revue les données et recommande les agrégations qui doivent être générées pour fournir le meilleur gain de performance possible.
Partitionnement de cube Service Manager
Chacun des groupes de mesures d'un cube est divisé en partitions, lesquelles définissent chacune une portion de données de fait qui est chargée dans un groupe de mesures. SQL Server Analysis Services (SSAS) sur SQL Server Édition Standard autorise une seule partition par groupe de mesures, tandis que plusieurs partitions sont autorisées dans le Êdition Entreprise. Bien que simples à comprendre pour l'utilisateur final, les partitions ont un impact considérable sur les performances et l'extensibilité. Par exemple, elles peuvent être traitées séparément et en parallèle. Ils peuvent avoir des conceptions d’agrégation différentes. Il est possible de retraiter une partition sans affecter les autres partitions du même groupe de mesures. En outre, SSAS analyse uniquement les partitions qui contiennent les données nécessaires à une requête particulière, ce qui peut améliorer considérablement les performances des requêtes.
Le partitionnement d'un cube est effectué à chaque maintenance de l'entrepôt de données, qui, par défaut, est exécutée toutes les heures. Le module de processus qui est exécuté s'appelle ManageCubePartitions. Il est toujours exécuté après l'étape CreateMartPartitions. Ces données de dépendance sont stockées dans la table infra.moduletriggercondition.
La bibliothèque de liens dynamiques (DLL) principale qui gère le partitionnement se trouve dans la DLL de l'utilitaire de l'entrepôt nommée Microsoft.EnterpriseManagement.Warehouse.Utility, dans la classe PartitionUtil. Plus précisément, il existe une méthode ManagePartitions() dans la classe qui gère toutes les maintenances de partition. La DLL de maintenance de l'entrepôt de données Microsoft.EnterpriseManagement.Warehouse.Maintenance, et la DLL OLAP de l'entrepôt de données Microsoft.EnterpriseManagement.Warehouse.Olap, appellent toutes les deux Microsoft.EnterpriseManagement.Warehouse.Utility pour gérer les partitions pendant la maintenance et le déploiement des cubes. La gestion des partitions est donc effectuée dans la DLL commune de l'utilitaire de l'entrepôt de données afin d'éviter toute duplication de code ou de logique.
Les tâches suivantes peuvent être effectuées lors de la maintenance du partitionnement des cubes :
- Créer des partitions
- Suppression de partitions
- Mise à jour des limites des partitions
Pour ce faire, la table SQL etl.TablePartition est lue afin de connaître toutes les partitions de faits qui ont été créées pour un groupe de mesures donné. Les actions suivantes se produisent :
- Démarrez le traitement du cube pour chaque groupe de mesures du cube en question.
- Obtenez toutes les partitions de la table etl.TablePartition pour le groupe de mesures en question.
- Supprimez toutes les partitions qui sont présentes dans le groupe de mesures, mais absentes de la table etl.TablePartition.
- Ajoutez toutes les partitions récemment créées qui n'existent que dans la table etl.TablePartition.
- Mettez à jour les partitions susceptibles d'avoir été modifiées en les comparant à RangeStartDate et RangeEndDate dans la table etl.TablePartition.
N'oubliez pas les éléments suivants concernant le traitement des cubes :
- Seuls les groupes de mesures ciblés aux faits contiennent plusieurs partitions dans SQL Server Édition Standard. Par défaut, les groupes de mesures et les dimensions contiennent une seule partition. Par conséquent, la partition n’a aucune condition de limite.
- Les limites d'une partition sont définies par une liaison de requête basée sur des datekey qui correspondent à ceux de la partition de fait correspondante dans la table etl.TablePartition.
Déploiement de cube OLAP Service Manager
Le déploiement de cube de traitement analytique en ligne (OLAP) utilise l’infrastructure de déploiement Service Manager pour créer des cubes OLAP dans la base de données SQL Server Analysis Services (SSAS).
Pour résumer, un élément déployable retourne un agent de déploiement avec un ensemble de ressources sérialisées qui sont utilisées pour créer le cube OLAP dans la base de données SSAS. Pour les cubes OLAP, le nom de l'objet déployable est CubeDeployable pour l'élément SystemCenterCube, et CubeExtensionDeployable pour l'élément CubeExtension. L'agent de déploiement de ces deux éléments est CubeDeployer.
La table dbo.Selector de la base de données DWStagingAndConfig contient une entrée pour chacun des éléments de pack d'administration SystemCenterCube et CubeExtension. Le moteur de déploiement utilise ces métadonnées si un traitement de déploiement supplémentaire est nécessaire pour l'un des éléments de pack d'administration, lors de l'importation du pack dans l'entrepôt de données à l'aide d'une tâche MPSync.
Les déploiements utilisent l'API AMO (Analysis Management Objects) pour créer et modifier tous les composants de cube de la base de données SSAS. Plus précisément, AMO en mode déconnecté est utilisé, car l’élément CubeDeployable n’a pas de connexion à la base de données SSAS. L'utilisation d'AMO en mode déconnecté permet de créer l'arborescence entière d'objets AMO sans établir de connexion au serveur. Service Manager sérialise ensuite la hiérarchie des objets en tant que ressources de flux et les attache à l’objet de déploiement passé à l’infrastructure de déploiement. L'objet d'agent de déploiement est ensuite désérialisé. Il établit alors une connexion à la base de données SSAD, puis crée les objets en envoyant les requêtes appropriées au serveur.
Seuls les objets principaux peuvent être sérialisés. Dans AMO, les objets principaux sont considérés comme des classes représentant un objet complet ou entité complète, et non comme faisant partie d'un autre objet. Par exemple, les objets principaux incluent Server, Cube et Dimension, qui sont toutes des entités autonomes. Toutefois, DimensionAttribute n’est pas un objet majeur, car il ne peut être créé que dans le cadre d’un objet principal parent de Dimension. DimensionAttribute, par conséquent, est un objet secondaire. La conception d'un cube OLAP se concentre sur la création de tous les objets principaux nécessaires aux cubes, ainsi que sur tous les objets secondaires dépendants. Ces objets principaux sont les objets qui seront sérialisés et, finalement, désérialisés avant la création des objets dans la base de données SSAS.
Les ressources qui englobent les objets principaux doivent être créées dans un ordre spécifique pour que le déploiement soit réussi et réponde aux exigences des éléments de cube OLAP en matière de dépendance. Les deux listes suivantes illustrent la séquence de déploiement des éléments SystemCenterCube et CubeExtension, respectivement :
- Éléments DataSourceView
- Éléments de dimension
- Élément de dimension de date
- Élément de cube
- Éléments DataSourceView
- Élément de cube
Traitement du cube OLAP Service Manager
Lorsqu’un cube OLAP (Online Analytical Processing) a été déployé et que toutes ses partitions ont été créées, elle est prête à être traitée afin qu’elle soit visible. Le traitement d'un cube est la dernière étape qui suit l'extraction, la transformation et le chargement (ETL). Ces étapes sont effectuées de la façon suivante :
- Extraction : extrait les données du système source
- Transformation : applique les fonctions afin de rendre les données conformes au schéma de dimensions standard
- Chargement : charge les données dans le mini-Data Warehouse en vue de leur consommation
- Processus : charge les données dans le cube OLAP depuis le mini-Data Warehouse pour permettre l'exploration des données
Le traitement d'un cube OLAP se produit lorsque toutes les agrégations du cube sont calculées, et que celui-ci est chargé avec ces agrégations et ses données. Les tables de dimensions et de faits sont lues, puis les données sont calculées et chargées dans le cube. Lors de la conception d'un cube OLAP, le traitement doit faire l'objet d'une attention particulière, en raison des conséquences potentiellement importantes dans un environnement de production comprenant des millions d'enregistrements. Un processus complet de toutes les partitions d’un tel environnement peut prendre n’importe où de jours à semaines, ce qui peut rendre l’infrastructure service Manager et les cubes inutilisables pour les utilisateurs finaux. Il est recommandé de désactiver la planification de traitement des cubes qui ne sont pas utilisés pour réduire la surcharge sur le système.
Le traitement du cube OLAP se compose de deux tâches distinctes :
- Traitement des dimensions
- Traitement des partitions
Chaque cube OLAP a un travail de traitement correspondant dans la console Service Manager et s’exécute selon une planification configurable par l’utilisateur. Chacun de ces types de tâche de traitement est décrit dans les sections suivantes.
Traitement des dimensions
Lorsqu'une nouvelle dimension est ajoutée à la base de données SQL Server Analysis Server (SSAS), elle doit faire l'objet d'un traitement complet afin que son état reflète un tel traitement. Une fois qu’une dimension a été traitée, toutefois, il n’existe aucune garantie qu’elle sera traitée à nouveau lorsqu’un autre cube qui cible la même dimension est traité. En ne retraiteant pas automatiquement la dimension, Service Manager ne peut pas retraiter chaque dimension pour chaque cube. Cela est particulièrement vrai si la dimension a été récemment traitée, car il est peu probable que de nouvelles données existent qui n’ont pas encore été traitées. Pour optimiser l’efficacité du traitement, il existe une classe singleton, définie dans le pack d’administration Microsoft.SystemCenter.Datawarehouse.OLAP.Base, nommé Microsoft.SystemCenter.Warehouse.Dimension.ProcessingInterval. En voici un exemple :
<!-- This singleton class defines the minimum interval of time in minutes that must elapse before a shared dimension is reprocessed. -->
<ClassType ID="Microsoft.SystemCenter.Warehouse.Dimension.ProcessingInterval" Accessibility="Public" Abstract="false" Base="AdminItem!System.AdminItem" Singleton="true">
<Property ID="IntervalInMinutes" Type="int" Required="true" DefaultValue="60"/>
</ClassType>
Cette classe singleton contient une propriété, IntervalInMinutes, qui décrit la fréquence de traitement d'une dimension. Par défaut, cette propriété est définie sur 60 minutes. Par exemple, si une dimension a été traitée à 3 h 05 et qu’un autre cube qui cible la même dimension est traité à 3 h 45, la dimension ne sera pas retraitée. L'inconvénient de cette approche est la probabilité accrue d'erreurs relatives aux clés de dimension. Un mécanisme de nouvelle tentative gère les erreurs de clé de dimension afin de traiter à nouveau la dimension, puis la partition de cube. Pour plus d’informations sur les échecs de traitement, consultez la section « Problèmes courants liés au débogage et à la résolution des problèmes ».
Après le traitement complet d'une dimension, un traitement incrémentiel est exécuté à l'aide de ProcessUpdate . Le seul autre cas dans lequel ProcessFull est exécuté est lorsque le schéma d'une dimension est modifié, car celle-ci retourne à un état non traité. N’oubliez pas que si ProcessFull est effectué sur une dimension, tous les cubes affectés et leurs partitions existent alors dans un état non traité et doivent être entièrement traités lors de leur prochaine exécution planifiée.
Traitement des partitions
Le traitement de partition doit être soigneusement pris en compte, car le retraitement d’une grande partition est lent et consomme de nombreuses ressources processeur sur le serveur qui héberge SSAS. En règle générale, le traitement des partitions est plus long que celui des dimensions. Contrairement au traitement de dimensions, le traitement de partitions n'a aucun effet secondaire sur les autres objets. Les deux seuls types de traitement effectués sur les cubes System Center - Service Manager OLAP sont ProcessFull et ProcessAdd.
Comme pour les dimensions, la création de partitions dans un cube OLAP nécessite l'exécution d'une tâche ProcessFull pour que les partitions puissent être interrogées. La tâche ProcessFull étant une opération coûteuse, elle ne doit être exécutée que lorsque cela est nécessaire, par exemple, lors de la création d'une partition ou de la mise à jour d'une ligne. Dans les scénarios dans lesquels des lignes ont été ajoutées et aucune ligne n’a été mise à jour, Service Manager peut effectuer une tâche ProcessAdd. Pour ce faire, Service Manager utilise des filigranes et d’autres métadonnées. Plus précisément, les tables etl.cubepartition et etl.tablepartition sont interrogées afin de déterminer le type de traitement à effectuer.
Le diagramme suivant illustre la façon dont Service Manager détermine le type de traitement à effectuer en fonction des données de filigrane.
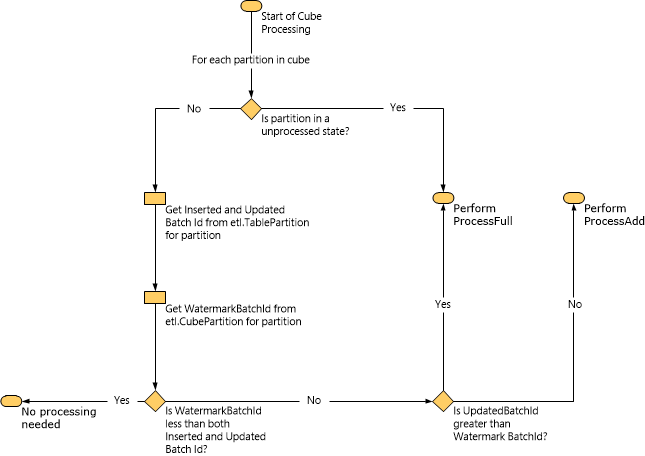
Lorsqu’une tâche ProcessAdd est effectuée, Service Manager limite l’étendue de la requête à l’aide de filigranes. Par exemple, si la valeur d'InsertedBatchId est de 100 et celle de WatermarkBatchId est de 50, la requête chargera uniquement les données du mini-Data Warehouse où la valeur d'InsertedBatchId est comprise entre 50 et 100.
Enfin, il est important de noter que Service Manager ne prend pas en charge le traitement manuel des cubes OLAP à l’aide de SSAS ou business Intelligence Development Studio. Le traitement de cubes en dehors des méthodes fournies dans System Center - Service Manager, y compris la console Service Manager et les applets de commande Service Manager, ne met pas à jour les tables de filigrane. Par conséquent, il est possible que des problèmes d’intégrité des données se produisent. Si vous avez accidentellement retraché le cube manuellement, une solution de contournement possible consiste à annuler manuellement le traitement du cube OLAP de la même manière. Ensuite, la prochaine fois que Service Manager traite le cube, il effectue automatiquement une tâche ProcessFull, car les partitions sont dans un état non traité. De cette façon, tous les filigranes et toutes les métadonnées seront mis à jour, et les éventuels problèmes d'intégrité des données seront résolus.
Gérer les cubes OLAP Service Manager
Les sections suivantes abordent les meilleures pratiques de maintenance des cubes de traitement analytique en ligne (OLAP).
Retraiter régulièrement les dimensions Analysis Services
Selon les meilleures pratiques SQL Server Analysis Services (SSAS), il est recommandé d'effectuer régulièrement un traitement complet des dimensions SSAS. Le traitement complet des dimensions permet de reconstruire les index et d'optimiser le stockage des données multidimensionnelles, ce qui a pour effet d'améliorer les performances des requêtes et des cubes qui peuvent se dégrader avec le temps. Ce processus est similaire à celui de la défragmentation régulière du disque dur d'un ordinateur.
Toutefois, l'un des inconvénients du traitement complet des dimensions SSAS est que tous les cubes OLAP concernés passent à l'état non traité, alors qu'ils doivent également faire l'objet d'un traitement complet afin de pouvoir retourner à l'état dans lequel ils étaient au moment de la requête. Service Manager ne traite pas explicitement les dimensions SSAS. Par conséquent, vous devez décider du moment auquel effectuer cette tâche de maintenance.
Considérations relatives à la mémoire
Si vous exécutez toutes les opérations de type extraction, transformation et chargement (ETL) de l'entrepôt de données, ainsi que toutes les fonctions de cube OLAP sur le même serveur, vous devrez prévoir les besoins en mémoire du système d'exploitation, de l'entrepôt de données et de SQL Server Analysis Services, afin de garantir que le serveur pourra faire face aux opérations exécutées simultanément nécessitant de nombreuses ressources. La planification est particulièrement importante, car le traitement des cubes OLAP nécessite beaucoup de mémoire.
Étapes suivantes
- Modélisez les cubes OLAP dans les packs d’administration.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour