Qu’est-ce qu’AutoML ?
AutoML est une fonctionnalité d'Azure Databricks qui vous permet d'automatiser l’entraînement et l'évaluation d'un modèle Machine Learning en utilisant différentes combinaisons d'algorithmes et de valeurs d'hyperparamètres. Grâce à AutoML, vous pouvez réduire l'effort qu’implique un processus itératif d’entraînement de modèle et créer plus rapidement un modèle optimal pour vos données.
Comment fonctionne AutoML ?
AutoML fonctionne en générant plusieurs exécutions d'expériences, chacune entraînant un modèle à l'aide d'une combinaison différente d’algorithmes et d'hyperparamètres. À chaque exécution, un modèle est entraîné et évalué sur la base des données et de la métrique prédictive que vous spécifiez. Azure Databricks assure le suivi des exécutions et des modèles produits en utilisant MLflow, ce qui vous permet d'identifier le modèle le plus performant et de le déployer en production.
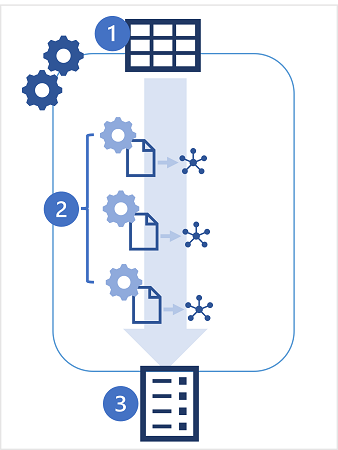
- Vous démarrez une expérience AutoML en spécifiant une table dans votre espace de travail Azure Databricks comme source de données pour l’entraînement et la métrique de performance spécifique pour laquelle vous souhaitez optimiser votre processus.
- L'expérience AutoML génère plusieurs exécutions de MLflow, chacune produisant un notebook avec du code pour prétraiter les données avant l'entraînement et la validation d'un modèle. Les modèles entraînés sont enregistrés sous forme d'artefacts dans les exécutions MLflow ou de fichiers dans le magasin DBFS.
- Les exécutions d’expériences sont classées par ordre de performance, les modèles les plus performants étant présentés en premier. Vous pouvez explorer les notebooks générés pour chaque exécution, choisir le modèle que vous souhaitez utiliser, puis l'enregistrer et le déployer.
Conseil
Pour plus de détails sur les transformations de prétraitement et les algorithmes d'entraînement spécifiques utilisés par AutoML, voir Fonctionnement d’Azure Databricks AutoML dans la documentation Azure Databricks.
Préparer les données pour AutoML
AutoML a besoin d'une source de données de formation incluant les valeurs des fonctionnalités et des étiquettes. Pour fournir ces données, créez une table dans le metastore Hive de votre espace de travail Azure Databricks.
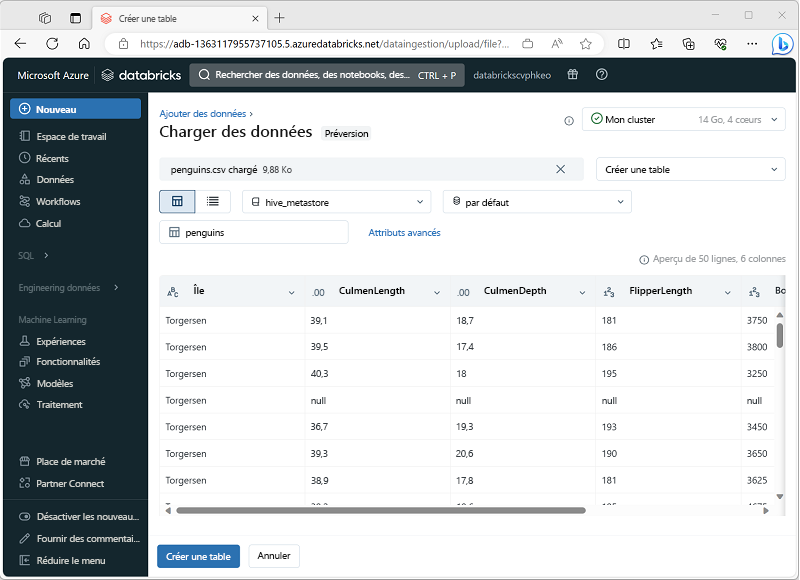
Un moyen simple de créer une table de données d'entraînement pour AutoML consiste à charger un fichier de données dans le portail Azure Databricks, comme illustré ici.
AutoML génère du code pour traiter les tâches courantes de prétraitement des données, notamment le codage des variables catégorielles, la mise à l'échelle des variables numériques, la gestion des valeurs nulles et le traitement des jeux de données déséquilibrés.