Configurer un groupe de machines virtuelles identiques
Quand vous effectuez une mise à l’échelle, vous ajoutez des instances à votre groupe de machines virtuelles identiques. Dans le scénario de l’entreprise de transport, la mise à l’échelle est une bonne manière de gérer le nombre fluctuant de demandes au fil du temps. La mise à l’échelle ajuste le nombre de machines virtuelles qui exécutent l’application web à mesure que le nombre d’utilisateurs change. De cette façon, le système conserve un temps de réponse uniforme, quelle que soit la charge.
Dans cette unité, vous allez découvrir comment mettre à l’échelle un groupe de machines virtuelles identiques. Vous pouvez effectuer une mise à l’échelle manuelle en définissant explicitement le nombre d’instances de machines virtuelles dans le groupe identique, ou vous pouvez configurer la mise à l’échelle automatique en définissant des règles de mise à l’échelle qui déclenchent l’allocation et la désallocation des machines virtuelles. Ces règles de mise à l’échelle déterminent quand mettre à l’échelle le système en surveillant différentes métriques de performances.
Mettre à l’échelle manuellement des groupes de machines virtuelles identiques
Vous mettez à l’échelle un groupe de machines virtuelles identiques manuellement en augmentant ou en diminuant le nombre d’instances. Vous pouvez effectuer cette tâche par programmation ou dans le portail Azure.
Le code suivant utilise Azure CLI pour changer le nombre d’instances dans un groupe de machines virtuelles identiques :
az vmss scale \
--name MyVMScaleSet \
--resource-group MyResourceGroup \
--new-capacity 6
Mettre l’échelle automatiquement des groupes de machines virtuelles identiques
La mise à l’échelle manuelle est pratique dans certaines circonstances. Cependant, dans de nombreux cas, la mise à l’échelle automatique est préférable. Elle permet au système de contrôler le nombre d’instances d’un groupe identique.
Vous pouvez baser la mise à l’échelle automatique sur :
- Une planification : Utilisez cette approche si vous savez que votre charge de travail augmentera à une date ou une période de temps spécifiée.
- Des métriques : Ajustez la mise à l’échelle en surveillant des métriques de performances associées au groupe identique. Quand ces métriques dépassent un seuil spécifié, le groupe identique peut démarrer automatiquement de nouvelles instances de machine virtuelle. Quand les métriques indiquent que les ressources supplémentaires ne sont plus nécessaires, le groupe identique peut arrêter les instances excédentaires.
Définir les conditions, règles et limites de la mise à l’échelle automatique
La mise à l’échelle automatique est basée sur un ensemble de conditions, de règles et de limites. Une condition de mise à l’échelle combine l’heure et un ensemble de règles de mise à l’échelle. Si l’heure actuelle se trouve dans la période définie dans la condition de mise à l’échelle, les règles de mise à l’échelle de la condition sont évaluées. Les résultats de cette évaluation déterminent s’il faut ajouter ou supprimer des instances dans le groupe identique. La condition de mise à l’échelle définit également les limites de mise à l’échelle pour le nombre maximal et le nombre minimal d’instances.
Dans le scénario de l’entreprise de transport, vous pouvez ajouter des règles de mise à l’échelle qui supervisent l’utilisation du processeur dans le groupe identique. Si l’utilisation du processeur dépasse le seuil de 75 %, la règle de mise à l’échelle peut augmenter le nombre d’instances de machine virtuelle. Une deuxième règle de mise à l’échelle peut également superviser l’utilisation du processeur, mais réduire le nombre d’instances de machines virtuelles quand l’utilisation passe sous les 50 %. Comme l’application est mondiale, ces règles doivent être actives à tout moment, et pas seulement à des heures spécifiques.
Un groupe de machines virtuelles identiques peut contenir de nombreuses conditions de mise à l’échelle. Chaque condition de mise à l’échelle satisfaite est traitée. Un groupe identique contient également une condition de mise à l’échelle par défaut qui est utilisée si aucune autre condition n’est satisfaite pour l’heure actuelle et pour les métriques de performances. La condition de mise à l’échelle par défaut est toujours active. Elle ne contient pas de règles de mise à l'échelle, agissant efficacement comme une condition de mise à l’échelle nulle qui n’effectue pas de scale-in ou de scale-out. Cependant, vous pouvez modifier la condition de mise à l’échelle par défaut pour définir un nombre d’instances par défaut, ou vous pouvez ajouter une paire de règles de mise à l'échelle qui effectuent un scale-out et un scale-in.
Utiliser la mise à l’échelle automatique basée sur une planification
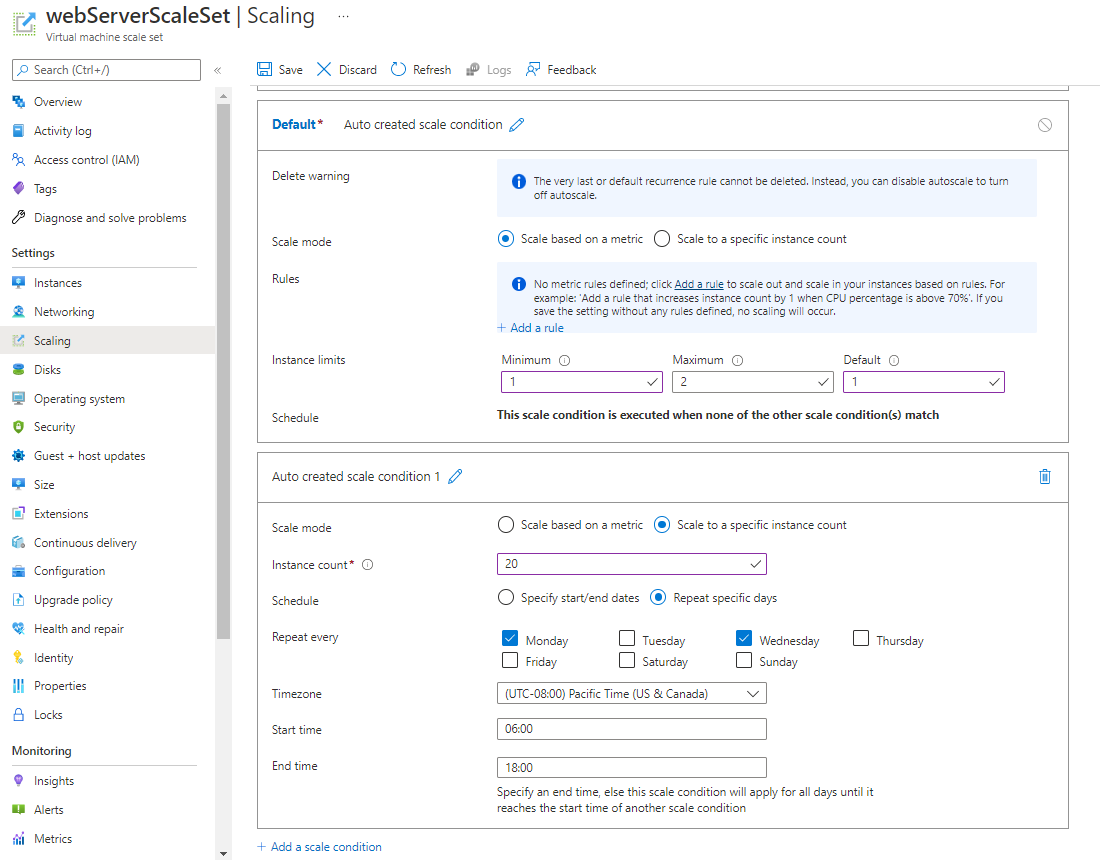
La mise à l’échelle basée sur une planification spécifie une heure de début et une heure de fin ainsi que le nombre d’instances à ajouter au groupe identique. La capture d’écran suivante montre un exemple dans le portail Azure. Le nombre d’instances passe à 20 (scale-out) entre 6h00 et 18h00 le lundi et le mercredi. En dehors de ces heures, s’il n’y a pas d’autres conditions de mise à l’échelle, la condition de mise à l’échelle par défaut est appliquée.
Dans ce cas, la règle par défaut met à l’échelle le système en le ramenant à deux instances. Cette valeur est le Maximum dans cette condition de mise à l’échelle par défaut.
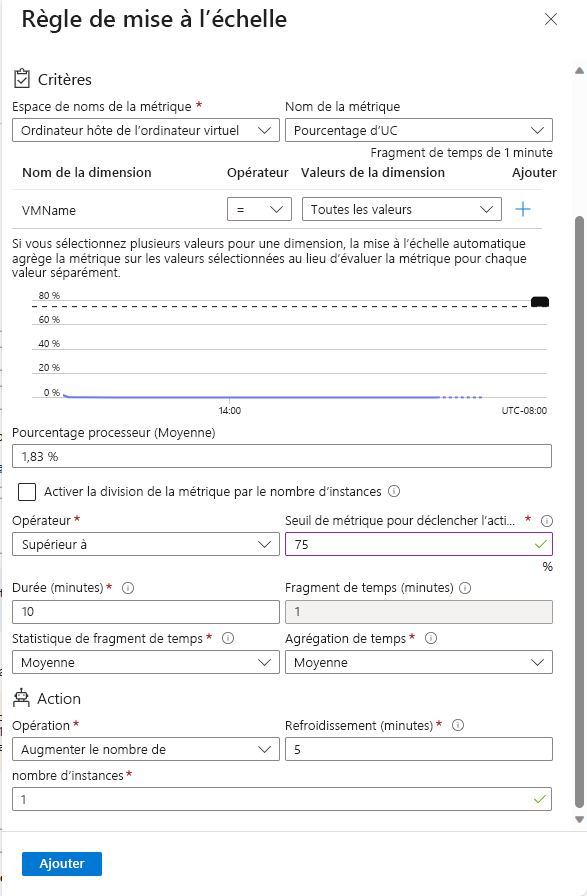
Utiliser une mise à l’échelle automatique basée sur des métriques
Une règle de mise à l’échelle basée sur des métriques spécifie les ressources à superviser, comme l’utilisation du processeur ou le temps de réponse. Cette règle de mise à l’échelle ajoute ou supprime des instances du groupe identique en fonction des valeurs de ces métriques. Vous pouvez spécifier des limites sur le nombre d’instances pour empêcher un scale-in ou un scale-out excessif sur un groupe identique.
Dans l’exemple de scénario, vous voulez augmenter le nombre d’instances d’une unité quand l’utilisation moyenne du processeur dépasse 75 %. Vous voulez aussi limiter l’opération de scale-out à 50 instances. Cette limite peut aider à empêcher une mise à l’échelle coûteuse provoquée par une attaque. De même, vous voulez effectuer un scale-in quand l’utilisation moyenne du processeur passe sous la barre des 50 %.
Ces métriques sont couramment utilisées pour superviser un groupe de machines virtuelles identiques :
- Pourcentage d’UC : Cette métrique indique l’utilisation du processeur sur toutes les instances. Une valeur élevée indique que les instances commencent à utiliser le processeur de manière intensive, ce qui peut retarder le traitement des demandes des clients.
- Flux entrants et Flux sortants : Ces métriques indiquent la vitesse à laquelle le trafic réseau circule vers et depuis les machines virtuelles du groupe identique.
- Opérations de lecture sur disque/s et Opérations d’écriture sur disque/s : Ces métriques indiquent le volume d’E/S disque sur le groupe identique.
- Longueur de file d’attente de disque de données : Cette métrique indique le nombre de demandes d’E/S en attente de traitement sur les disques de données des machines virtuelles.
Une règle de mise à l’échelle agrège les valeurs récupérées pour une métrique sur toutes les instances. Elle agrège les valeurs sur une période appelée fragment de temps. Chaque métrique a un fragment de temps intrinsèque, mais dans la plupart des cas, cette période est d’une minute. La valeur agrégée est appelée agrégation de temps. Les options d’agrégation de temps sont Moyenne, Minimum, Maximum, Total, Dernier et Nombre.
Un intervalle d’une minute est trop court pour déterminer si un changement de la métrique est suffisamment long pour justifier une mise à l’échelle automatique. Une règle de mise à l’échelle passe à une deuxième étape, agrégeant la valeur de l’agrégation de temps sur une période plus longue spécifiée par l’utilisateur. Cette période est appelée durée. La durée minimale est de cinq minutes. Par exemple, si la durée est définie sur 10 minutes, la règle de mise à l’échelle agrège les dix valeurs calculées pour le fragment de temps.
Le calcul de l’agrégation de la durée peut différer du calcul de l’agrégation du fragment de temps. Par exemple, supposons que l’agrégation de temps est Moyenne et que la statistique collectée est Pourcentage d’UC sur un fragment de temps d’une minute. Pour chaque minute, le pourcentage moyen d’utilisation du processeur sur toutes les instances pendant cette minute sera calculé. Si la statistique du fragment de temps est définie sur Maximum et que la durée de la règle est définie sur 10 minutes, la valeur maximale des 10 valeurs moyennes pour l’utilisation du pourcentage de processeur détermine si le seuil de la règle a été dépassé.
Quand une règle de mise à l’échelle détecte qu’une métrique a franchi un seuil, elle peut effectuer une action de mise à l’échelle. Une action de mise à l’échelle peut être un scale-out ou un scale-in. Une action de scale-out augmente le nombre d’instances. Une action de scale-in réduit le nombre d’instances.
Une action de mise à l’échelle utilise un opérateur, comme inférieur à, supérieur à ou égal à, pour déterminer comment réagir par rapport au seuil. En règle générale, les actions de scale-out utilisent l’opérateur supérieur à pour comparer la valeur de la métrique au seuil. Les actions de scale-in ont tendance à comparer la valeur de la métrique au seuil avec l’opérateur inférieur à. Une action de mise à l’échelle définit également le nombre d’instances à un niveau spécifique, au lieu d’en incrémenter ou d’en décrémenter le nombre disponible.
Une action de mise à l’échelle a une période de refroidissement, qui est exprimée en minutes. Pendant cette période, la règle de mise à l’échelle n’est pas redéclenchée. Le « refroidissement » permet au système de se stabiliser entre des événements de mise à l’échelle. Le démarrage ou l’arrêt des instances prenant un certain temps, les métriques collectées peuvent ne pas présenter de changements significatifs pendant plusieurs minutes. La période de refroidissement minimale est de cinq minutes.
Enfin, vous devriez planifier un scale-in quand la charge de travail diminue. Envisagez de définir des règles de mise à l’échelle par paires dans la même condition de mise à l’échelle. Une règle de mise à l’échelle doit indiquer comment effectuer un scale-out du système quand une métrique dépasse un seuil supérieur. L’autre règle doit définir comment effectuer un scale-in du système quand la même métrique passe en dessous d’un seuil inférieur. Ne définissez pas les deux seuils sur la même valeur. Sinon, vous pourriez déclencher une série d’événements oscillant entre le scale-out et le scale-in.
L’illustration suivante montre un exemple de règle de mise à l’échelle définie dans le portail Azure.