Classifier vos données
Une entreprise de vente au détail en ligne a différents types de données. Chaque type de données peut bénéficier d’une solution de stockage différente.
Les données d’application peuvent être classifiées de l’une des trois manières suivantes : structurées, semi-structurées et non structurées. Vous allez découvrir ici comment classifier vos données pour pouvoir choisir la solution de stockage adaptée au type de données.
Approches de stockage de données dans le cloud
La vidéo suivante présente les options de stockage de données dans le cloud :
Données structurées
Dans les données structurées, parfois appelées données relationnelles, toutes les données ont les mêmes champs ou propriétés. Toutes les données ont la même organisation et la même forme, ou schéma. Le schéma partagé permet de rechercher facilement ce type de données à l’aide de langages de requête tels que SQL (Structured Query Language). Cette fonctionnalité rend ce style de données parfait pour des applications telles que les systèmes CRM, les réservations et la gestion des stocks.
Les données structurées sont souvent stockées dans des tables de bases de données avec des lignes et des colonnes. Dans la table, une colonne clé indique la relation entre une ligne d’une table et les données d’une autre ligne d’une autre table. Dans l’image suivante, une table qui contient des données sur des notes obtient des données à partir d’une table de noms d’étudiants et d’une table de données de classe à l’aide de colonnes clés.
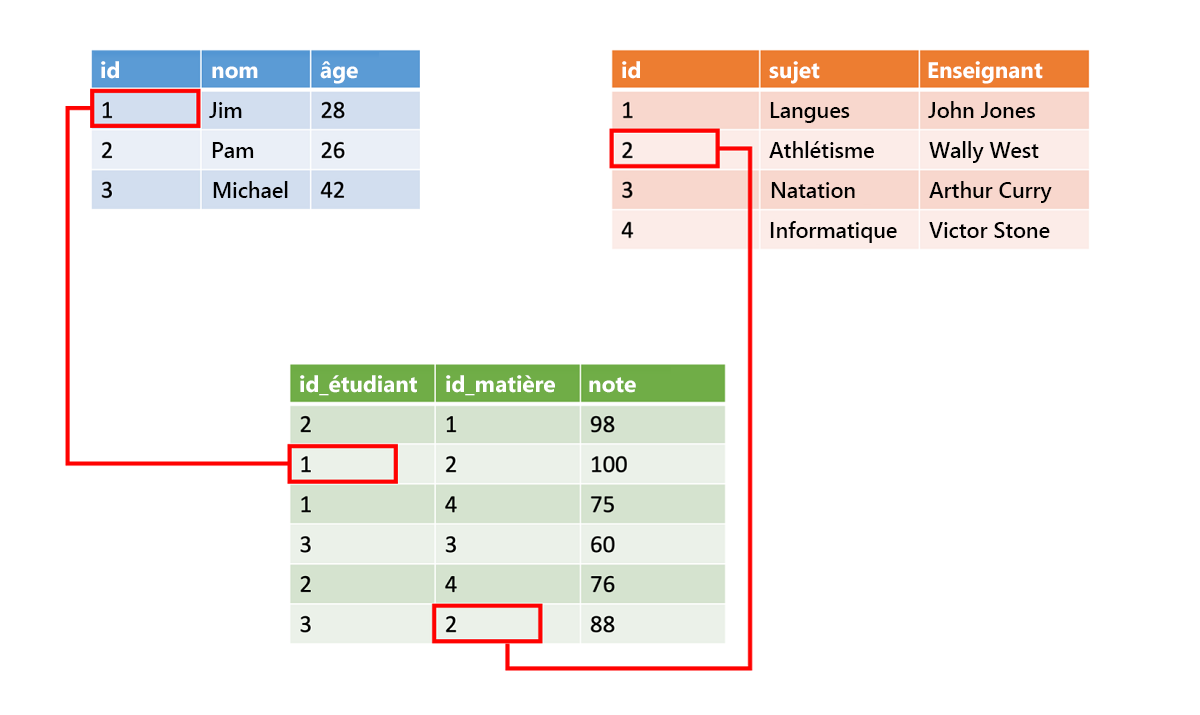
Les données structurées sont simples, car elles sont faciles à entrer, à interroger et à analyser. Toutes les données ont le même format. Toutefois, le fait de forcer une structure cohérente signifie également que l’évolution des données est plus difficile. Si vous ajoutez ou supprimez des champs de données, vous devez mettre à jour chaque enregistrement afin qu’il soit conforme à la nouvelle structure.
Données semi-structurées
Les données semi-structurées sont moins organisées que les données structurées. Les données semi-structurées ne sont pas stockées dans un format relationnel, car les champs ne s’intègrent pas correctement dans des tables, des lignes et des colonnes. Les données semi-structurées contiennent des mots clés qui mettent en évidence l’organisation et la hiérarchie des données. En guise d’exemple, nous pourrions citer les paires clé/valeur. Les données semi-structurées sont aussi désignées sous le nom de données non relationnelles ou NoSQL (not only SQL).
Les données semi-structurées sont définies par un langage de sérialisation. Dans la classification des données, la sérialisation est le processus qui consiste à convertir des données dans un format qui peut être transmis ou stocké.
Les développeurs de logiciels utilisent des langages de sérialisation des données pour écrire des données stockées en mémoire dans un fichier, qui peuvent ensuite être envoyées à un autre système, analysées et lues. L’expéditeur et le destinataire n’ont pas besoin de connaître les détails de l’autre système. Tant que le même langage de sérialisation est utilisé, les données peuvent être comprises par les deux systèmes.
Langages de sérialisation courants
XML, JSON et YAML sont trois langages de sérialisation courants.
XML
XML (Extensible Markup Language) est l’un des premiers langages de données à avoir été utilisé largement. XML est basé sur du texte, ce qui le rend facilement lisible par l’homme et l’ordinateur. Des analyseurs XML sont disponibles pour presque toutes les plateformes de développement populaires.
Vous pouvez utiliser le langage XML pour exprimer des relations. XML inclut des normes pour le schéma, la transformation et même l’affichage sur le web.
Voici l’exemple d’une personne dont le nom, l’âge et les loisirs sont exprimés en XML :
<Person Age="23">
<FirstName>Quinn</FirstName>
<LastName>Anderson</LastName>
<Hobbies>
<Hobby Type="Sports">Golf</Hobby>
<Hobby Type="Leisure">Reading</Hobby>
<Hobby Type="Leisure">Guitar</Hobby>
</Hobbies>
</Person>
XML exprime la forme des données à l’aide de balises définies à l’intérieur de chevrons. Ces balises se présentent sous deux formes : des éléments comme <FirstName> et des attributs qui peuvent être exprimés dans du texte tel que Age="23". Les éléments peuvent avoir des éléments enfants pour exprimer des relations. Par exemple, la balise <Hobbies> exprime une collection d’éléments Hobby.
XML est flexible et peut exprimer facilement des données complexes. Il a toutefois tendance à être plus détaillé et donc plus volumineux à stocker, traiter et transférer sur un réseau. D’autres formats sont donc devenus plus populaires.
JSON
JSON (JavaScript Object Notation) a une spécification légère et utilise des accolades pour indiquer la structure des données. JSON est moins détaillé et plus facile à lire par les humains que XML. JSON est fréquemment utilisé par les services web pour retourner des données.
Voici le nom, l’âge et les loisirs de la même personne exprimées en JSON :
{
"firstName": "Quinn",
"lastName": "Anderson",
"age": "23",
"hobbies": [
{ "type": "Sports", "value": "Golf" },
{ "type": "Leisure", "value": "Reading" },
{ "type": "Leisure", "value": "Guitar" }
]
}
Le format JSON n’est pas aussi formel que XML. Il se rapproche plus d’un modèle de paire clé/valeur que d’une expression de données formelle. Comme vous pouvez le deviner, le langage de programmation JavaScript intègre une prise en charge de ce format, et est donc très populaire pour le développement web. Comme XML, d’autres langages incluent des analyseurs que vous pouvez utiliser pour utiliser ce format de données. L’inconvénient de JSON est qu’il a tendance à être plus orienté programmeur ; sa lecture et sa modification sont donc plus compliquées pour des personnes non techniques.
YAML
YAML (YAML Ain’t Markup Language) est un langage de sérialisation de données plus récemment développé. L’un des avantages de l’utilisation de YAML est qu’il est plus facile à lire pour les humains que d’autres langages. La structure des données est définie par la mise en retrait et la séparation de ligne. Le format YAML réduit la dépendance envers des caractères structurels comme les parenthèses, les virgules et les crochets.
Voici les mêmes données exprimées en YAML :
firstName: Quinn
lastName: Anderson
age: 23
hobbies:
- type: Sports
value: Golf
- type: Leisure
value: Reading
- type: Leisure
value: Guitar
Ce format est plus lisible que JSON, et souvent utilisé pour les fichiers de configuration qui doivent être écrits par des personnes mais analysés par des programmes. YAML est le plus récent de ces formats de données.
Que sont les données semi-structurées ou NoSQL ?
La vidéo suivante décrit les options de stockage de données semi-structurées et NoSQL :
Les données non structurées
L’organisation des données non structurées est non définie. Les données non structurées sont souvent fournies dans un format de fichier, par exemple des fichiers photo ou vidéo. Le fichier vidéo lui-même peut avoir une structure globale et comporter des métadonnées semi-structurées, mais les données qui forment la vidéo proprement dite sont non structurées. Ainsi, les photos, les vidéos et autres fichiers similaires sont considérés comme des données non structurées.
Voici des exemples de données non structurées :
- Fichiers multimédias tels que des photos, des vidéos et des fichiers audio
- Fichiers Microsoft 365, tels que les documents Word
- Fichiers texte
- Fichiers journaux
Classification des données : Évaluer vos types de données
Vous pouvez classifier les données de l’une des trois manières suivantes : structurées, semi-structurées et non structurées. La compréhension des différences pour pouvoir classifier vos données vous aidera à choisir la bonne solution de stockage.
Les données structurées sont des données organisées qui s’intègrent parfaitement dans des tables ou des colonnes de données. Les données semi-structurées sont toujours organisées, présentent des propriétés et valeurs claires, mais il existe une certaine diversité. Les données non structurées ne s’intègrent pas correctement dans des tables ou des colonnes, et elles n’ont pas de schéma uniforme.
Examinons les jeux de données utilisés dans une entreprise de vente au détail en ligne et classifions-les.
Données du catalogue de produits
Les données du catalogue de produits pour un détaillant en ligne sont de nature semi-structurée. Chaque produit est associé à une référence (SKU) de produit, une description, une quantité, un prix, des options de taille, des options de couleur, une photo et éventuellement une vidéo. Ainsi, ces données semblent relationnelles au départ, car elles ont toutes la même structure. Toutefois, à mesure que vous introduisez de nouveaux produits ou différents types de produits, vous souhaiterez peut-être ajouter des champs de données. Par exemple, Bluetooth est activé sur les nouvelles chaussures de tennis que vous portez, afin de transmettre des données de capteur à partir de la chaussure vers une application de fitness sur votre téléphone. Cette fonctionnalité semblant être une tendance croissante, vous souhaitez offrir aux clients la possibilité de filtrer sur des chaussures « Bluetooth ». Vous ne souhaitez pas mettre à jour toutes vos données de chaussures avec une propriété Bluetooth. Vous souhaitez ajouter cette nouvelle propriété uniquement aux nouvelles chaussures.
Avec l’ajout de la propriété Bluetooth, vos données de chaussures ne sont plus homogènes. Vous avez introduit des différences dans le schéma. Si ce changement est la seule exception que vous pensez trouver, vous pouvez normaliser les données existantes afin que tous les produits comprennent un champ « Bluetooth » pour conserver une organisation relationnelle structurée. Toutefois, s’il ne s’agit que de l’un des nombreux champs de produits spécialisés que vous envisagez de prendre en charge à l’avenir, la classification des données est semi-structurée. Les données sont organisées par étiquettes, mais chaque produit du catalogue peut contenir des champs uniques.
La classification des données de catalogue de produits est semi-structurée.
Photos et vidéos
Les photos et vidéos affichées dans les pages de produits sont des données non structurées. Bien que le fichier multimédia puisse contenir des métadonnées, le corps du fichier multimédia est non structuré.
La classification des données pour les photos et les vidéos est non structurée.
Données métier
Les analystes d’entreprise souhaitent implémenter le décisionnel pour effectuer des évaluations de pipeline des stocks et des révisions de données de ventes. Pour effectuer ces opérations, les données de plusieurs mois doivent être agrégées, puis interrogées. En raison de la nécessité d’agréger des données similaires, ces données doivent être structurées pour permettre la comparaison d’un mois à un autre.
La classification des données métier est structurée.