Avant le cloud
Maintenant que nous avons défini ce qu’est le cloud computing, examinons des exemples de la façon dont l’informatique a été utilisée dans différents domaines tels que l’informatique métier, l’informatique scientifique et l’informatique personnelle avant l’émergence du cloud computing.
Exemples de domaines et d’applications
Informatique métier : Des exemples de systèmes d’information de gestion traditionnels incluent la logistique et les opérations, la planification des ressources d’entreprise (ERP), la gestion des relations client (CRM), la productivité du bureau et la décisionnel (BI). Ces outils ont permis de rationaliser les processus qui ont conduit à l’amélioration de la productivité et à la réduction des coûts dans diverses entreprises.
Par exemple, un logiciel CRM permet aux entreprises de collecter, stocker, gérer et interpréter diverses données sur des clients passés, actuels et potentiels. Le logiciel CRM offre une vue intégrée (en temps réel ou quasiment en temps réel) de toutes les interactions organisationnelles avec les clients. Par exemple, pour une entreprise de fabrication, le logiciel CRM peut être utilisé par une équipe commerciale pour planifier des réunions, des tâches et des suivis avec des clients. Une équipe de marketing peut cibler des clients via des campagnes basées sur des profils spécifiques. Les équipes de facturation peuvent suivre les devis et les factures. En tant que tel, il s’agit d’un référentiel centralisé pour stocker ces informations. Pour activer cette fonctionnalité, diverses technologies matérielles et logicielles sont utilisées par l’organisation et les équipes commerciales pour collecter les données qui doivent être stockées et analysées à l’aide de différents systèmes de base de données et d’analytique.
Informatique scientifique : L’informatique scientifique utilise des modèles mathématiques et des techniques d’analyse implémentés sur des ordinateurs pour tenter de résoudre des problèmes scientifiques. Un exemple populaire est la simulation par ordinateur des phénomènes physiques. Ce domaine a perturbé les méthodes expérimentales théoriques et de laboratoire traditionnelles en permettant aux scientifiques et aux ingénieurs de reconstruire des événements connus ou de prédire des situations futures grâce à des programmes de simulation et d’étude de différents systèmes dans différentes circonstances. Ces simulations nécessitent généralement un très grand nombre de calculs qui sont souvent exécutés sur des supercalculateurs coûteux ou des plateformes informatiques distribuées.
Informatique personnelle : dans l’informatique personnelle, un utilisateur exécute différentes applications sur un ordinateur à usage général. Ces applications peuvent être destinées à la productivité du bureau, comme le traitement de texte et les feuilles de calcul ; communication, comme les clients de messagerie ; ou divertissement, tels que des jeux vidéo ou des fichiers multimédias. Un utilisateur informatique personnel possède, installe et gère généralement le logiciel et le matériel utilisés pour effectuer ces tâches.
Gérer la mise à l’échelle
L’augmentation de l’échelle de l’informatique a été un processus continu, qu’il s’agisse d’augmenter le nombre de clients et d’événements pour capturer, surveiller et analyser dans CRM, ou augmenter la précision des simulations numériques dans l’informatique scientifique ou le réalisme dans les applications de jeux vidéo. En outre, la nécessité d’une plus grande échelle a été motivée par l’augmentation de l’adoption de la technologie par différents domaines ou l’expansion des entreprises et des marchés, ainsi que l’augmentation continue du nombre d’utilisateurs et de leurs besoins. Les organisations doivent tenir compte de l’augmentation de l’échelle au fur et à mesure qu’elles planifient et budgetent le déploiement de leurs solutions.
Les entreprises planifient généralement leur infrastructure informatique en suivant un processus appelé planification de la capacité. Au cours du processus de planification de la capacité, la croissance de l’utilisation de divers services informatiques est mesurée et utilisée comme référence pour une expansion future. Les organisations doivent planifier à l’avance l’achat, la configuration et la maintenance de serveurs plus récents et améliorés, le stockage et l’équipement réseau. Parfois, les organisations sont limitées par les logiciels, car elles n’ont peut-être acheté qu’un ensemble limité de licences et peuvent nécessiter davantage d’étendre l’infrastructure pour couvrir un plus grand nombre d’utilisateurs.
La forme la plus simple de mise à l’échelle est appelée mise à l’échelle verticale, dans laquelle les anciens systèmes sont remplacés par des systèmes plus récents et plus performants qui peuvent fournir les mises à niveau nécessaires au niveau du service. Dans de nombreux cas, la mise à l’échelle verticale consiste à mettre à niveau ou à remplacer des serveurs et des systèmes de stockage avec des serveurs plus récents, plus rapides ou des tableaux de stockage avec une capacité accrue. Ce processus peut prendre des mois à planifier et à exécuter, ainsi qu'une période pendant laquelle le service pourrait connaître des interruptions.
Dans certains types de systèmes, la mise à l’échelle est également effectuée horizontalement, en augmentant la quantité de ressources dédiées au système. Par exemple, il s’agit d’un calcul hautes performances, où des serveurs et un stockage supplémentaires peuvent être ajoutés pour améliorer les performances du système, ce qui entraîne un plus grand nombre de calculs pouvant être effectués par seconde ou une augmentation de la capacité de stockage du système. Tout comme la mise à l’échelle verticale, la planification et l’exécution de ce processus peuvent prendre des mois, avec des temps d’arrêt possibles.
Étant donné que les entreprises possèdent et gèrent leur équipement informatique, le coût de l’adaptation continuant à augmenter, les entreprises identifient d’autres méthodes pour réduire les coûts. Les grandes entreprises ont consolidé les besoins informatiques de différents services dans un seul centre de données volumineux dans lequel elles ont consolidé l’immobilier, la puissance, le refroidissement et la mise en réseau afin de réduire les coûts. D’autre part, les petites et moyennes entreprises pourraient louer l’immobilier, le réseau, l’alimentation, le refroidissement et la sécurité physique en plaçant leur équipement informatique dans un centre de données partagé. Il s’agit généralement d’un service de colocalisation, qui a été adopté par les petites et moyennes entreprises qui ne voulaient pas construire leurs propres centres de données en interne. L’adoption de services de colocalisation continue dans différents domaines en tant qu’approche rentable pour réduire les coûts opérationnels.
La mise à l’échelle a affecté tous les aspects de l’informatique métier. Par exemple, l’échelle a affecté les systèmes CRM par le biais de l’augmentation des clients ou de la quantité d’informations stockées et analysées sur les clients. L'informatique d'entreprise a abordé l'échelle par la mise à l'échelle verticale et horizontale, ainsi que par la consolidation des ressources informatiques vers les centres de données et la colocation. En informatique scientifique, des systèmes parallèles et distribués ont été adoptés pour augmenter la taille des problèmes et la précision de leurs simulations numériques. Une définition de traitement parallèle est l’utilisation de plusieurs ordinateurs homogènes qui partagent l’état et fonctionnent comme un seul ordinateur volumineux afin d’exécuter des calculs à grande échelle ou à haute précision. L’informatique distribuée est l’utilisation de plusieurs systèmes informatiques autonomes connectés par un réseau afin de partitionner un problème important en tâches subordonnées qui sont exécutées simultanément et communiquent via des messages sur le réseau. La communauté scientifique a continué d’innover dans ces domaines afin de résoudre les problèmes de mise à l’échelle. Dans l’informatique personnelle, la mise à l’échelle l’a impactée par l’augmentation des demandes des utilisateurs apportées par du contenu plus riche et diverses applications. Les utilisateurs augmentent donc la capacité de leurs appareils informatiques personnels afin de répondre à ces exigences.
Augmentation des services Internet
La fin des années 90 a marqué une augmentation constante de l’adoption de ces applications et plateformes informatiques entre les domaines. Bientôt, le logiciel devrait être non seulement fonctionnel, mais également capable de produire de la valeur et des insights pour les besoins professionnels et personnels. L’utilisation de ces applications est devenue collaborative. Les applications étaient mélangées et appairées pour échanger des informations. L’informatique n’était plus seulement un centre de coûts pour une entreprise, mais une source d’innovation et d’efficacité.
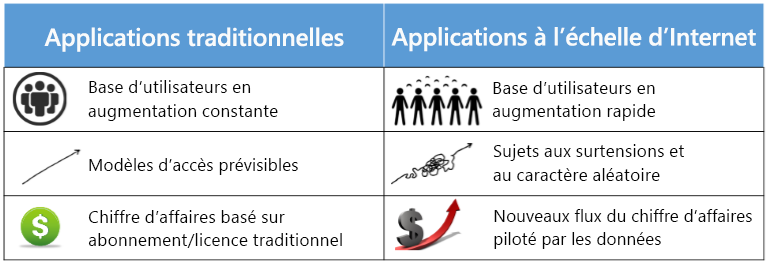
Figure 2 : Comparer les calculs traditionnels et à l’échelle de l’Internet
Le 21e siècle a été marqué par une explosion du volume et de la capacité des communications sans fil, du World Wide Web et de l’Internet. Ces changements ont conduit à une société basée sur le réseau et pilotée par les données, où la production, la diffusion et l’accès aux informations numérisées sont simplifiées. L’Internet est estimé à avoir créé un marché mondial de milliards d’utilisateurs, soit une hausse de 25 millions en 1994. 1 Cette augmentation des données et des connexions est précieuse pour les entreprises. Les données créent de la valeur de plusieurs façons, notamment en activant l’expérimentation, en segmentant les populations et en prenant en charge la prise de décision avec l’automatisation. 2 En adoptant des technologies numériques, les 10 premières économies du monde devraient augmenter leur production d’environ un billion de dollars d’ici 2020.
L'augmentation du nombre de connexions permise par Internet a également accru sa valeur. Les chercheurs ont hypothétisé que la valeur d’un réseau varie de façon superligne en fonction du nombre d’utilisateurs. Ainsi, à l’échelle de l’Internet, gagner et conserver les clients est une priorité. Pour ce faire, créez des services fiables et réactifs et apportez des modifications en fonction des modèles de données observés.
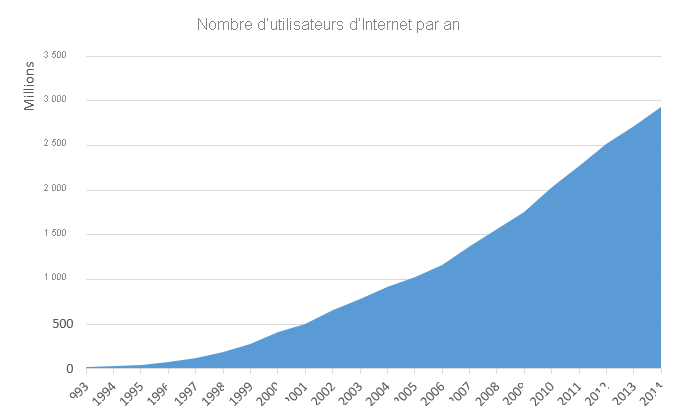
Figure 3 : Nombre croissant d’utilisateurs Internet par année
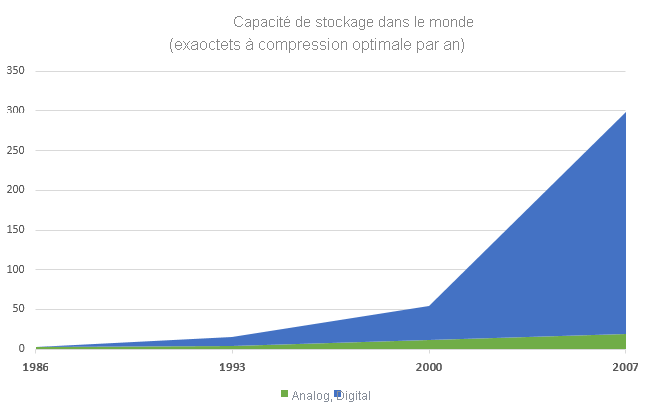
Figure 4 : Quantité croissante de données stockées par an5
Voici quelques exemples de systèmes à l’échelle Internet :
- Moteurs de recherche qui analysent, stockent, indexent et recherchent dans de grands jeux de données (jusqu’à plusieurs pétaoctets). Par exemple, Google a commencé sous forme d’index web géant qui analysait le trafic web une fois tous les quelques jours et établissait une correspondance entre ces index et des mots clés. À présent, il met à jour ses indices en quasi-temps réel et est l’une des méthodes les plus populaires pour accéder aux informations sur Internet. Son index a des billions de pages avec une taille de milliers de téraoctets. 4
- Réseaux sociaux tels que Facebook et LinkedIn, permettant aux utilisateurs d’établir des relations personnelles et professionnelles ainsi que de créer des communautés basées sur des intérêts similaires. Facebook, par exemple, prend désormais en charge plus d’un milliard d’utilisateurs actifs par mois.
- Services de vente au détail en ligne comme Amazon qui conservent un inventaire mondial de millions de produits, qui sont vendus à plus de 200 millions de clients, avec des volumes de ventes nets de près de 90 milliards de dollars par an.
- Applications multimédias riches en streaming qui permettent aux utilisateurs de regarder et de partager des vidéos et d’autres formes de contenu enrichi. L’un de ces exemples, YouTube, gère les chargements de 300 minutes de vidéo par seconde.
- Systèmes de communication en temps réel pour les conversations audio, vidéo et texte comme Skype, qui horlogent plus de 50 milliards de minutes d’appels par mois.
- Suites de productivité et de collaboration qui servent des millions de documents à de nombreux utilisateurs simultanés, ce qui permet des mises à jour persistantes en temps réel. Par exemple, Microsoft 365 prétend prendre en charge 50 millions de collaborateurs actifs mensuels.
- Applications CRM par fournisseurs tels que Salesforce déployés à plus de cent mille organisations. Les grandes crms fournissent désormais des tableaux de bord intuitifs pour suivre l’état, l’analytique pour rechercher les clients qui génèrent le plus d’activités et les prévisions de revenus pour prédire la croissance future.
- Applications d’exploration de données et d’aide à la décision qui analysent l’utilisation d’autres services (comme ceux décrits ci-dessus) afin de détecter des inefficacités et des opportunités de monétisation.
Ces systèmes doivent clairement traiter un grand nombre d’utilisateurs simultanés. Cela nécessite une infrastructure avec la capacité de gérer de grandes quantités de trafic réseau, de générer des données et de stocker en toute sécurité les données, sans aucun délai notable. Ces services tirent leur valeur de la fourniture d’un niveau de qualité constant et fiable. Ils fournissent également des interfaces utilisateur riches pour les appareils mobiles et les navigateurs web, ce qui les rend faciles à utiliser mais plus difficiles à créer et à gérer.
Voici un résumé des exigences des systèmes à l’échelle internet :
- Ubiquity : Accessible depuis n’importe où à tout moment, à partir d’une multitude d’appareils. Par exemple, un commercial s’attend à ce que son service de gestion de la relation client fournisse des mises à jour en temps opportun sur un appareil mobile afin que ses visites aux clients soient plus courtes, plus rapides et plus efficaces. Le service doit fonctionner de manière fluide via diverses connexions réseau.
- Haute disponibilité : le service doit être « toujours opérationnel ». Les temps de disponibilité sont mesurés en termes de nombre de neufs. Trois neuf (99,9 %) signifient qu’un service sera indisponible 9 heures par an. Cinq neuf (environ 6 minutes par an) est un seuil classique pour un service haute disponibilité. Quelques minutes de temps d’arrêt dans des applications de vente au détail en ligne peuvent avoir une incidence mesurable en millions de dollars de ventes.
- Faible latence : temps d’accès rapide et réactif. Même des temps de chargement de page légèrement plus lents ont été montrés pour réduire considérablement l’utilisation de cette page web. Par exemple, l’augmentation de la latence de recherche de 100 ms à 400 ms diminue le nombre de recherches par utilisateur de 0,8% à 0,6%, et la modification persiste même après la réduction de la latence aux niveaux d’origine.
- Scalabilité : capacité à gérer une charge variable généralement en raison de la saisonnalité et de la viralité, ce qui provoque des pics et des creux dans le trafic sur de longues et courtes périodes de temps. Les jours comme « Black Friday » et « Cyber Monday », les détaillants comme Amazon doivent gérer plusieurs fois le trafic réseau que en moyenne.
- Rentabilité : un service à l’échelle Internet nécessite beaucoup plus d’infrastructure qu’une application traditionnelle, ainsi qu’une meilleure gestion. Une façon de simplifier les coûts consiste à faciliter la gestion des services et à réduire le nombre d’administrateurs qui gèrent un service. Les services de plus petite taille peuvent se permettre d’avoir un faible ratio service/administrateur (par exemple, 2: 1, ce qui signifie qu’un administrateur doit gérer deux services). Pour maintenir la rentabilité, les services tels que Microsoft Bing doivent avoir un ratio de service à administrateur élevé (par exemple, 2500:1, ce qui signifie qu’un seul administrateur gère 2 500 services). 6
- Interopérabilité : un grand nombre de ces services sont souvent utilisés ensemble et doivent donc fournir une interface facile à réutiliser et doivent prendre en charge des mécanismes standardisés pour l’importation et l’exportation de données. Par exemple, de nombreux autres services (comme Uber) peuvent intégrer Google Maps dans leurs produits pour fournir des informations de navigation et d’emplacement simplifiées aux utilisateurs.
Nous allons maintenant explorer certaines des premières solutions aux différents problèmes ci-dessus. 7 Le premier défi à relever était le grand temps d’aller-retour pour les services web précoces qui étaient principalement situés aux États-Unis. Les premiers mécanismes pour traiter les problèmes de latence (dus à des serveurs distants) et de défaillance de serveur reposaient simplement sur la redondance. L’une des techniques permettant d’y parvenir était de « mettre en miroir » du contenu, dans lequel des copies de pages web populaires seraient stockées à différents endroits du monde. Cela a réduit la quantité de charge sur le serveur central, réduit la latence perçue par les utilisateurs finaux et autorise le passage du trafic vers un autre serveur en cas de défaillance. L’inconvénient de ce problème était une augmentation de la complexité à gérer les incohérences si même une copie des données devait être modifiée. Ainsi, cette technique est utile pour les charges de travail statiques, lourdes en lecture, comme le traitement d’images, de vidéos ou de musique. En raison de l’efficacité de cette technique, la plupart des services à l’échelle Internet utilisent des réseaux de distribution de contenu (CDN) pour stocker des caches globaux distribués de contenu populaire. Par exemple, Cable News Network (CNN) gère désormais des réplicas de ses vidéos sur plusieurs serveurs « edge » à différents emplacements dans le monde entier, avec une publicité personnalisée par emplacement.
Bien entendu, il n’était pas toujours logique que des entreprises achètent des dizaines de serveurs à travers le monde. Les services d’hébergement partagé permettaient souvent de réaliser des économies de coûts. Ici, les partages d’un même serveur web étaient loués à plusieurs locataires, ce qui permettait d’amortir les coûts de maintenance du serveur. Les services d’hébergement partagé peuvent être hautement efficaces en termes de ressources, car les ressources peuvent être surprovisionnés selon l’hypothèse que tous les services ne fonctionnent pas en même temps à une capacité maximale. (Un serveur physique surprovisionné est un serveur physique où la capacité d’agrégation de tous les locataires est supérieure à la capacité réelle du serveur.) L’inconvénient était qu’il était presque impossible d’isoler les services des locataires de ceux de leurs voisins. Ainsi, un seul service surchargé ou sujet aux erreurs pourrait avoir une incidence négative sur tous ses voisins. Un autre problème résultait du fait que des locataires pouvaient souvent être malveillants et essayer de tirer parti de la colocalisation pour dérober des données ou refuser le service à d’autres utilisateurs.
Pour remédier à cela, des serveurs privés virtuels ont été développés en tant que variantes du modèle d’hébergement partagé. Un locataire est fourni avec une machine virtuelle sur un serveur physique partagé. (Nous parlons plus tard des machines virtuelles et de leurs propriétés.) Ces machines virtuelles étaient souvent allouées statiquement et liées à une seule machine physique, de sorte qu’elles étaient difficiles à mettre à l’échelle et ont souvent besoin d’une récupération manuelle à partir de toute défaillance. Si elles ne pouvaient plus être sur approvisionnées, elles offraient de meilleures performances et une meilleure isolation de la sécurité entre les services colocalisés qu’un simple partage de ressources.
Un autre problème lié au partage de ressources publiques était qu’il nécessitait un stockage de données privées sur une infrastructure tierce. Certains des services à l’échelle internet décrits ci-dessus ne pouvaient pas se permettre de perdre le contrôle sur le stockage des données, car toute divulgation des données privées de leurs clients aurait des conséquences catastrophiques. Par conséquent, ces entreprises devaient créer leur propre infrastructure globale. Avant l’avènement du cloud public, de tels services ne pouvaient être déployés que par de grandes entreprises telles que Google et Amazon. Chacune de ces entreprises créerait de grands centres de données homogènes dans le monde entier à l’aide de composants de base hors-plateau, où un centre de données pourrait être considéré comme un ordinateur à grande échelle d’entrepôt (WSC) unique. Un WSC offrait une abstraction facile pour distribuer des applications et des données à l’échelle mondiale, tout en conservant la propriété.
En raison des économies d’échelle, l’utilisation d’un centre de données peut être optimisée pour réduire les coûts. Même si cela n’était toujours pas aussi efficace que le partage public de ressources (le cloud), ces ordinateurs à l’échelle de l’entrepôt possédaient de nombreuses propriétés souhaitables qui servaient de fondement à la création de services à l’échelle internet. L’échelle des applications informatiques est passée de la gestion d’une base d’utilisateurs fixe à celle d’une population mondiale dynamique. Les WSC standardisés permettaient à de grandes entreprises de servir des audiences aussi importantes. Une infrastructure idéale combinerait les performances et la fiabilité d’un WSC avec le modèle d’hébergement partagé. Cela permettrait même à une petite entreprise de développer et de lancer une application mondialement compétitive, sans la surcharge élevée de la construction de grands centres de données.
Une autre approche pour partager des ressources était le Grid Computing qui permettait le partage de systèmes informatiques autonomes entre institutions et emplacements géographiques. Plusieurs institutions académiques et scientifiques collaboreraient et regrouperaient leurs ressources vers un objectif commun. Chaque institution rejoint ensuite une « organisation virtuelle » en dédicant un ensemble spécifique de ressources via des règles de partage bien définies. Les ressources étaient souvent hétérogènes et faiblement couplées, nécessitant des constructions de programmation complexes pour les assembler. Les grilles ont été conçues pour soutenir la recherche non commerciale et les projets universitaires, et elles s’appuyaient sur des technologies open source existantes.
Le cloud était un successeur logique qui combinait la plupart des fonctionnalités des solutions ci-dessus. Par exemple, au lieu que les universités contribuent et partagent l’accès à un pool de ressources à l’aide d’une grille, le cloud leur permet de louer une infrastructure informatique qui a été gérée de manière centralisée par un fournisseur de services cloud (CSP). Étant donné que le fournisseur central a conservé un pool de ressources volumineux pour satisfaire tous les clients, le cloud facilite le scale-up et la baisse dynamique de la demande dans un court laps de temps. Au lieu de normes ouvertes comme la grille, toutefois, le cloud computing s’appuie sur des protocoles propriétaires et a besoin de l’utilisateur pour placer un certain niveau de confiance dans le fournisseur de solutions Cloud.
Plus loin dans ce module, nous abordons la façon dont le cloud a évolué pour rendre l’informatique publique qui peut être mesurée et utilisée.
références
- Projet de statistiques en temps réel (2015). Statistiques d’Internet Live
- IBM (2017). Qu’est-ce que Big Data ?
- Google Inc. (2015). Fonctionnement de la recherche
- Hilbert, Martin et Lopez, Priscila (2011). Capacité technologique du monde à stocker, communiquer et calculer des informations
- Hamilton, James R et autres (2007). Lors de la conception et du déploiement de services Internet-Scale
- Brewer, Eric et autres (2001). Leçons des services à grande échelle