Évolution du cloud computing
- 9 minutes
Observons l’évolution du cloud computing.
Événements et innovations
Le concept de cloud computing est apparu au début des années 1950, quand plusieurs universitaires, dont Herb Grosch, John McCarthy et Douglas Parkhill, ont imaginé une informatique disponible à la demande à l’instar de l’énergie électrique.1, 2 Au cours des décennies suivantes, plusieurs technologies émergentes ont jeté les fondements du cloud computing. Plus récemment, la croissance rapide du World Wide Web et l’avènement des géants d’Internet comme Google et Amazon, ont abouti à la création d’un environnement économique et commercial qui a permis l’éclosion du modèle de cloud computing.
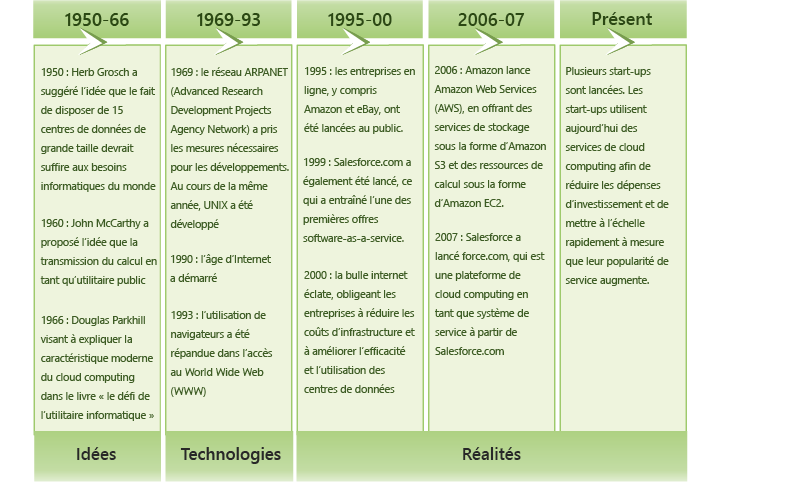
Figure 5 : Évolution du cloud computing
Évolution du cloud computing
Depuis les années 1960, les premiers ordinateurs qu’utilisaient les organisations étaient des ordinateurs mainframe. Plusieurs utilisateurs pouvaient partager des ordinateurs mainframe et s’y connecter via des connexions série de base à l’aide de terminaux. Le mainframe était responsable de la logique, du stockage et du traitement des données, et les terminaux qui y étaient connectés avaient une puissance de calcul faible voire nulle. L’utilisation généralisée de ces systèmes a duré pendant plus de 30 ans et, dans une certaine mesure, continue aujourd’hui.
Avec la naissance de l’informatique personnelle, l’apparition de processeurs et de mémoires plus économiques, plus petits et plus puissants ont conduit au basculement dans la direction opposée, où les utilisateurs exécutaient leurs propres logiciels et stockaient leurs données localement. Cette situation, à son tour, a conduit à des problèmes de partage inefficace des données ainsi qu’à l’établissement de règles pour maintenir l’ordre au sein de l’environnement informatique d’une organisation.
Progressivement, grâce au développement de technologies réseau haut débit, les réseaux locaux (LAN) sont nés, qui permettaient aux ordinateurs de se connecter et de communiquer entre eux. Par conséquent, les fournisseurs ont conçu des systèmes capables de combiner les avantages des ordinateurs personnels et mainframe, qui ont contribué à l’apparition d’applications client-serveur devenues populaires sur les réseaux locaux. En général, les clients exécutaient le logiciel client (et traitaient des données) ou un terminal (pour les applications héritées) connecté à un serveur. Dans le modèle client-serveur, le serveur détient la logique d’application, de stockage et de données.
Finalement, dans les années 1990, l’ère de l’information mondiale a émergé avec l’adoption rapide d’Internet. La bande passante réseau a été considérablement améliorée, l’accès à distance ordinaire cédant la place à la connexion par fibre optique dédiée d’aujourd’hui. Par ailleurs, du matériel plus économique et plus puissant a fait son apparition. De plus, l’évolution du World Wide Web et des sites web dynamiques nécessitait des architectures multicouches.
Les architectures multicouches ont permis la modularisation des logiciels en séparant la présentation, la logique et le stockage de l’application sous forme d’entités individuelles. Grâce à cette modularisation et à ce découplage, les entités logicielles individuelles ne tardèrent pas à s’exécuter sur des serveurs physiques distincts (généralement en raison de différences d’exigences matérielles et logicielles). Cela a conduit à une augmentation du nombre de serveurs au sein des organisations, mais aussi à une faible utilisation moyenne de ceux-ci. En 2009, l’International Data Corporation (IDC) a estimé que le taux d’utilisation moyen d’un serveur x86 était d’environ 5 à 10 %.3
La technologie des machines virtuelles a suffisamment mûri dans les années 2000 pour devenir disponible sous la forme de logiciels commerciaux. La virtualisation permet d’encapsuler un serveur entier dans une image exécutable sans difficulté sur du matériel, et d’exécuter plusieurs serveurs virtuels simultanément tout en partageant des ressources matérielles. La virtualisation permet donc de regrouper des serveurs et, par la même occasion, d’améliorer l’utilisation du système.
Dans le même temps, le Grid Computing (informatique en grille) faisait des adeptes au sein de la communauté scientifique pour la résolution de problèmes à grande échelle de manière distribuée. Avec le Grid Computing, des ressources informatiques de plusieurs domaines administratifs travaillent de concert pour atteindre un objectif commun. Le Grid Computing a donné naissance à de nombreux outils de gestion des ressources (par exemple, des planificateurs et des équilibreurs de charge) permettant de gérer des ressources informatiques à grande échelle.
L’économie de l’informatique a évolué au même rythme que les différentes technologies informatiques. Dès le début de l’ère des ordinateurs mainframe, des entreprises comme IBM proposèrent d’héberger et d’exécuter des ordinateurs et des logiciels pour diverses organisations, comme les banques et les compagnies aériennes. À l’ère d’Internet, l’hébergement web par des tiers est également devenu populaire. Toutefois, avec la virtualisation, les fournisseurs disposent d’une flexibilité sans pareille pour accueillir plusieurs clients sur un seul serveur, en partageant le matériel et les ressources entre eux.
Le développement de ces technologies, conjugué au modèle économique de l’informatique à la demande, a finalement abouti au cloud computing.
Technologies habilitantes
Le cloud computing s’appuie sur diverses technologies habilitantes : réseau, virtualisation et gestion des ressources, informatique à la demande, modèles de programmation, informatique distribuée et parallèle, et technologies de stockage.
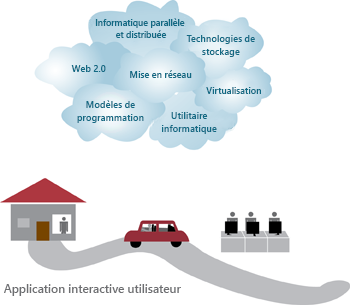
Figure 6 : Technologies habilitantes dans le cloud computing
L’émergence de technologies de réseau haut débit et ubiquitaire a largement contribué à faire du cloud computing un paradigme viable. Les réseaux modernes permettent aux ordinateurs de communiquer de manière rapide et fiable, ce qui est important si nous voulons utiliser les services d’un fournisseur de cloud. Cela permet de comparer l’expérience utilisateur d’un logiciel s’exécutant dans un centre de données distant à celle d’un logiciel s’exécutant sur un ordinateur personnel. La messagerie web en est un exemple connu, tout comme les logiciels de productivité bureautique. De plus, la virtualisation est essentielle pour le cloud computing. Comme nous l’avons mentionné, elle permet de gérer la complexité du cloud via l’abstraction et le partage des ressources entre utilisateurs sur plusieurs machines virtuelles. Chaque machine virtuelle peut exécuter son propre système d’exploitation et les programmes d’application associés. La virtualisation pour le cloud computing est traitée par la suite dans un autre module.
Des technologies comme les systèmes de stockage à grande échelle, les systèmes de fichiers distribués et les nouvelles architectures de base de données sont essentielles pour la gestion et le stockage des données dans le cloud. Les technologies de stockage cloud sont traitées par la suite dans un autre module.
L’informatique à la demande offre de nombreuses structures de facturation pour la location de ressources informatiques. Par exemple, le paiement par heure d’utilisation de ressource, le paiement par débit garanti, le paiement par données stockées par mois.
L’informatique distribuée et parallèle permet à des entités distribuées sur des ordinateurs en réseau de communiquer et de coordonner leurs actions afin de résoudre certains problèmes, représentées sous forme de programmes parallèles. L’écriture de programmes parallèles pour des clusters distribués est difficile par nature. Pour obtenir un haut niveau d’efficacité et de flexibilité de la programmation dans le cloud, un modèle de programmation est nécessaire.
Les modèles de programmation pour les clouds offrent aux utilisateurs la possibilité d’exprimer des programmes parallèles sous forme d’unités de calcul séquentielles (par exemple, des fonctions dans MapReduce et des sommets dans GraphLab). Généralement, les systèmes de runtime de ce type de modèles de programmation parallélisent, distribuent et planifient les unités de calcul, gèrent les communications entre unités et tolèrent les pannes. Les modèles de programmation cloud sont traités par la suite dans un autre module.
Références
- Simson L. Garfinkel (1999). Architectes de la Société de l’Information : Trente-cinq ans du Laboratoire d'Informatique au MIT Press
- Douglas J. Parkhill (1966). Le défi de l’utilitaire informatique Addison-Wesley Société de publication, Reading, MA
- Michelle Bailey (2009). L'économie de la virtualisation : vers un modèle de coût basé sur les applications - Livre blanc IDC parrainé par VMware