Plateformes de supervision
Les plateformes de supervision se répartissent généralement en deux catégories : celles qui sont basées sur des agents et celles qui ne le sont pas. Un agent est un composant distant qui remonte des informations à un contrôleur central ou un hub APM, ou un démon qui agit comme proxy du contrôleur. Avec une APM de base, l’agent effectue régulièrement un test ping sur un serveur ou une application pour vérifier qu’ils sont toujours disponibles. Même les variations entre des tests ping réussis peuvent fournir des informations en indiquant où les connexions sont susceptibles d’être problématiques en raison de la distance ou d’une congestion du trafic. La plupart des agents APM modernes sont plus sophistiqués et envoient des données de télémétrie à des hubs centraux distribués dans le cloud. Certains agents peuvent être attachés à des applications côté client ou à des applications web, et remontent des données sur les performances et la connectivité provenant des agents JavaScript qui s’exécutent dans les navigateurs des utilisateurs.
Plateformes APM basées sur des agents
Dès le début, l’objectif de l’APM était de recueillir des informations sur l’état de fonctionnement d’une application ainsi que des données qui identifient les moments où des événements observables ont eu lieu. Les premiers agents APM étaient des éléments attachés à une page web, qui s’exécutaient dans les navigateurs des utilisateurs et qui remontaient ces données chronologiques, par exemple quand a commencé le rendu de la page, quand le rendu s’est terminé et combien de temps l’utilisateur est resté sur la page avant de la quitter.
Les fournisseurs de plateforme APM modernes utilisent les agents de différentes façons. Par exemple :
Un agent peut injecter du code JavaScript dans le contenu HTML des pages web, ce qui permet aux fonctions du côté client de communiquer des données de performances à des serveurs de plateforme APM.
Un agent peut collecter ou « récupérer » des enregistrements dans les journaux de performances générés par des applications ou par des services exécutés sur le client, ou auprès du client lui-même, indiquant les événements pertinents pour le fonctionnement du système.
Dans certains cas, un agent peut participer à la compilation d’une base de données centrale d’événements système pour des analyses par ou à partir du contrôleur APM.
La fonction automatisée la plus simple d’une plateforme de supervision des performances est l’alerte. Il s’agit d’un avertissement que le contrôleur central peut émettre quand il constate qu’une ou plusieurs des ressources supervisées ont atteint une condition spécifiée, généralement négative, comme une des suivantes :
La valeur d’une métrique supervisée qui représente un niveau de performance est passée sous une quantité de base de référence statique définie à l’avance
La valeur d’une métrique représentant un paramètre de fonctionnement (par exemple l’utilisation du processeur) ou représentant une plage moyenne de niveaux de tolérance (comme le trafic réseau) passe au-delà ou sous un seuil statique défini à l’avance
Le contrôleur observe un ou plusieurs paramètres de fonctionnement qui indiquent collectivement qu’un comportement est passé en dehors de la plage de tolérance définie comme « normale »
Le contrôleur détecte qu’une application s’est plantée ou ne répond plus aux entrées
Alors qu’une plateforme APM peut héberger des centaines d’agents échangeant simultanément des messages avec leur contrôleur ou leur hub, une alerte est un message destiné à être délivré à une personne. Au début des APM, la plateforme s’interfaçait avec des systèmes de paging de poche, de sorte que les opérateurs et les administrateurs pouvaient être avertis de conditions d’erreur. Aujourd’hui, ces messages peuvent être routés par e-mail ou par SMS.
En général, ce n’est pas le travail d’un agent que d’envoyer des alertes. Au lieu de cela, il collecte les données qui sont traitées et analysées par un autre composant APM, à partir duquel des alertes peuvent être générées.
Une plateforme APM basée sur des agents est à bien des égards un hub de messagerie réseau. Les données « machine » (le type de données générées par des machines pour les machines) constituent la majorité des données actuellement utilisées. Une des raisons pour laquelle il y a une telle quantité est la même que celle pour laquelle les annuaires téléphoniques consommaient autant de papier avant l’invention des smartphones : La publication et la distribution de tout à tout le monde semblaient être le moyen le plus efficace de procéder, jusqu’à ce que soudainement, ce ne soit plus le cas. Grâce à l’établissement d’un réseau efficace entre les nœuds des serveurs dédiés à la tâche de maintien des niveaux de service, l’utilisation correcte des APM basées sur des agents peut réduire au fil du temps le volume des données « machine ».
New Relic
La plateforme de supervision New Relic, désormais dénommée New Relic One, est un des nombreux outils de supervision basés sur des agents disponibles sur le marché. Elle est le résultat d’un gros travail pour rendre chaque composant gérable concevable dans une solution visible, observable et gérable. Comme illustré dans la figure 7.2, cette plateforme utilise les classes d’agents suivantes :
Agent APM : collecte des données pertinentes concernant les performances d’une application spécifique. Il peut être installé en même temps que l’application en tant que composant distinct et contacté via une API. Il s’agit de l’option recommandée pour un programme écrit dans un langage compilé, comme C++. Il peut éventuellement être installé en tant que bibliothèque ou code dépendant à l’intérieur d’une application écrite dans un langage interprété, comme Java, Node.js, Python ou Ruby. Cette option offre l’avantage d’un accès plus direct aux fonctions et aux dépendances spécifiées par le code source.
Agent mobile : variante de l’agent APM optimisée pour le déploiement sur des appareils Android et iOS.
Agent de navigateur : un segment ou « extrait » de code JavaScript attaché à une page web via une balise HTML. Ce code contient des instructions permettant à une application côté client en arrière-plan de collecter les données de performances générées par le navigateur et de publier régulièrement ces données sur le collecteur New Relic.
Agent d’infrastructure : installé sur une machine distante ou sur le serveur d’hébergement lui-même (les deux pouvant être une machine virtuelle), pour qu’il soit lancé au démarrage. À partir de là, cet agent s’exécute sans assistance et remonte l’état global du processeur, de la mémoire, de la connectivité réseau et du stockage local. L’agent d’infrastructure collecte des échantillons de métriques à des intervalles relativement non intrusifs, comme toutes les 5, 10 ou 20 secondes.
Un agent New Relic envoie périodiquement (par défaut chaque seconde) des packages de métriques et de données de performances à un hub central appelé collecteur, qui se trouve à l’intérieur du domaine privé de New Relic. Une organisation qui s’abonne à New Relic One peut utiliser son propre navigateur web ou le navigateur de New Relic pour communiquer avec les serveurs de New Relic, où les données compilées par le collecteur ont été stockées pour être distribuées aux abonnés. Les rapports, les graphiques et les tableaux de bord de la plateforme sont tous basés sur un navigateur.
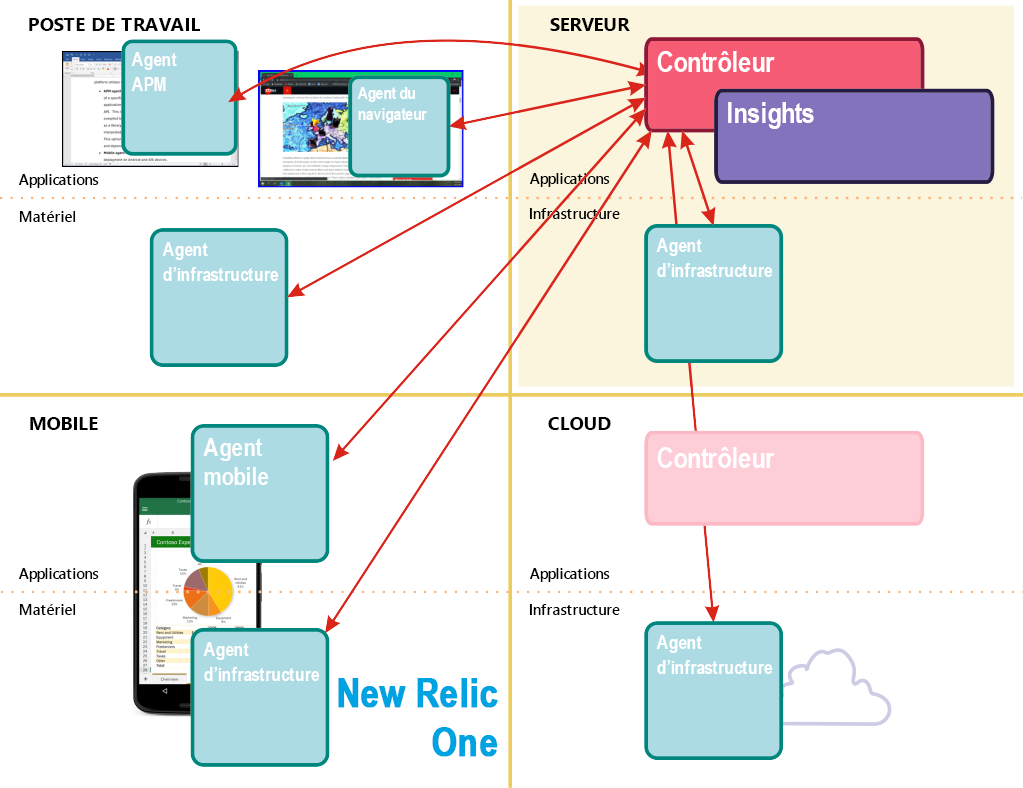
Figure 2 : Composants de supervision en réseau dans New Relic One.
Insights est une marque de New Relic pour le composant qui analyse les données collectées, génère des rapports et des alertes, et produit des tableaux de bord. Une de ses fonctionnalités les plus remarquables est sa carte des services, un graphique actualisé qui mappe les composants actifs d’une application web dans une vue composite assemblée au cours de la dernière demi-heure de captures instantanées prises par tous les agents APM supervisant l’application à distance.
La figure 3 montre un exemple de carte de service New Relic. Les codes de couleur vert, jaune et rouge pour les applications et les services (appelés entités dans New Relic) fournissent des informations vitales et facilement exploitables sur l’état actuel de la solution. Chaque entité reçoit un code de couleur en fonction du nombre et du niveau des violations de trafic non résolues, avec le rouge réservé aux violations les plus critiques.
![Figure 3 : partie d’une carte de service dans l’APM New Relic One.. [Fourni par New Relic]](../../cmu-cloud-admin/cmu-monitor-cloud-resources/media/fig7-3.png)
Figure 3 : Partie d’une carte de service dans l’APM New Relic One. [Avec l’aimable autorisation de New Relic]
Plateformes de supervision sans agent
L’outil ou la plateforme de supervision standard sans agent s’appuie sur l’état actuel d’un serveur, y compris les services système qui prennent en charge son matériel, pour fournir les informations dont la plateforme a besoin pour vérifier l’état de son fonctionnement et pour déterminer si un événement concernant cet état doit être actionnable. Le plus important de ces services est la journalisation.
Pour qu’un journal soit certifié par des organismes de normalisation comme auditable, c’est-à-dire fournissant les informations nécessaires à l’analyse approfondie d’une opération, chacun de ses enregistrements doit inclure les éléments suivants :
L’identité et/ou le type de chaque activité effectuée qui est pertinente pour la catégorie du journal
L’identité du propriétaire de cette activité ou la source authentifiée responsable de son lancement
Les noms des composants ou des objets de l’environnement affectés par l’activité
L’heure à laquelle l’activité a eu lieu
Le résultat de l’activité (ce qui a changé, le cas échéant)
Chaque enregistrement doit être présentable de façon intelligible à un opérateur humain. Certains journaux sont stockés en texte brut, qui est la forme la plus lisible, auquel cas un enregistrement peut apparaître sous la forme d’une seule ligne dans un tableau à plusieurs colonnes. Sinon, un enregistrement peut être stocké dans une base de données de façon compressée ou abrégée, ou avec des étiquettes exclusives représentant des objets, comme des identités. Dans tous les cas, l’enregistrement doit être lisible dans sa forme native ou bien une plateforme de gestion des journaux doit être capable de rendre cet enregistrement intelligible pour l’analyse humaine.
Sumo Logic
Sumo Logic est un exemple de plateforme de supervision sans agent. Il est basé sur un concept qu’il appelle analytique des données machine, qui est centrée sur la gestion des journaux. Comme la plupart des services et applications d’un serveur Linux savent utiliser l’utilitaire syslog de Linux pour générer des journaux dans un format approprié, Sumo Logic peut simplement pointer vers le répertoire approprié et à partir de là, il peut constituer des tableaux de bord et générer des rapports. Avec des services courants comme Apache Web Server, Sumo Logic connaît déjà les facteurs à rechercher et peut générer un tableau de bord approprié en seulement quelques secondes. La figure 4 montre un exemple.
![Figure 4 : Tableau de bord Sumo Logic pour Azure Web Apps. [Fourni par Sumo Logic]](../../cmu-cloud-admin/cmu-monitor-cloud-resources/media/fig7-4.png)
Figure 4 : Un tableau de bord Sumo Logic pour Azure Web Apps. [Avec l’aimable autorisation de Sumo Logic]
L’architecture traditionnelle de Sumo Logic intègre un composant appelé collecteur, qui collecte des données auprès des journaux et les incorpore dans une base de données. Techniquement, le collecteur est un agent. Sumo Logic s’est cependant éloigné du système piloté par agent : il offre à la place un service basé sur le cloud appelé collecteur hébergé. Il s’agit d’un service SaaS qui interagit avec le collecteur local via le réseau.
L’analyse effectuée par la plateforme Sumo Logic commence par des requêtes de base de données effectuées via sa console web. Inspiré par Hadoop et son algorithme MapReduce, Sumo Logic utilise des algorithmes propriétaires qu’il appelle LogReduce pour rechercher des moyens logiques de joindre des données connexes à partir de tables de journaux distincts. Un langage de requête personnalisé permet à un opérateur informatique de récupérer des enregistrements auprès de la base de données organisée par le collecteur, en fonction de critères qui peuvent être exprimés symboliquement. Par exemple, une requête peut récupérer des enregistrements auprès de plusieurs journaux qui contiennent tous le mot « SECURITY », exprimé sous la forme *SECURITY* (avec des astérisques au début et à la fin), puis regrouper ces enregistrements en fonction d’une catégorie de champ commune. Le résultat est une table personnalisée contenant des événements qui peuvent être marqués pour être examinés ultérieurement par le personnel en charge de la sécurité.
Suivi dans les environnements de microservices
Une application traditionnelle incorpore tout son code dans une même unité contiguë. Même s’il utilise des bibliothèques portables qui ont été officiellement incluses dans les déclarations du code, elles existent néanmoins toujours à l’intérieur des murs du proverbial monolithe. Une plateforme de supervision observant une application depuis l’extérieur attend généralement qu’elle effectue une opération visible, par exemple accepter une requête ou produire un résultat, puis elle mesure les niveaux de service de ces actions. Quand un réseau d’entreprise doit améliorer les niveaux de service pour ce réseau, il réplique simplement ces serveurs et place un équilibreur de charge devant ceux-ci pour équilibrer le flux du trafic. Même les plateformes de machines virtuelles modernes automatisent ce processus simple.
Avec les microservices, les modules de code d’une application deviennent des applications en elles-mêmes, qui interagissent avec et se passent le contrôle entre elles via le réseau. Pour se trouver, elles peuvent utiliser des adresses IP brutes, mais il est plus probable qu’elles utilisent un serveur DNS pour la découverte des services, ou elles peuvent utiliser un service Mesh pour découvrir les identités et les emplacements les unes des autres. Un orchestrateur comme Kubernetes améliore les niveaux de service en répliquant autant de microservices individuels que ce dont le cluster a besoin pour tenir compte du volume de trafic fluctuant, puis il peut supprimer ces réplicas quand le trafic diminue.
La prise en charge d’un environnement de microservices avec une plateforme de supervision conventionnelle qui observe les événements de l’extérieur revient à équiper une agglomération de plus d’un million de personnes avec un circuit téléphonique de type ligne partagée. En théorie, cela pourrait fonctionnerait avec une contrainte de temps infinie, mais les communications sur un tel système seraient trop lentes pour être praticables. Par conséquent, des plateformes APM spécialisées sont disponibles pour la supervision des solutions basées sur des microservices.
Prometheus
Un des premiers outils de supervision à répondre aux exigences d’un environnement de microservices a été Prometheus. En 2012, les développeurs du service d’hébergement de podcasts et de musique SoundCloud en sont venus à la conclusion que leur modèle de service monolithique existant était insuffisant pour leur base de clients en croissance rapide. Ils ont donc réarchitecturé leur plate-forme pour en faire une architecture de microservices, en plaçant les fonctions clés sur un réseau évolutif et permettant l’observation de ces fonctions. En même temps, ils ont élaboré leur propre supervision des microservices et ont adapté des moteurs open source de base de données de série chronologique (TSDB)1 pour que plusieurs microservices puissent les utiliser en parallèle.
Au bout de trois années de travail, l’équipe de SoundCloud a pu intégrer ses outils de supervision dans un tout nouveau type de plateforme de supervision qu’elle a appelé Prometheus. L’entreprise a opté pour le support de sa plateforme en publiant son projet dans la communauté open source.2 Elle est désormais pilotée par la Cloud Native Computing Foundation, qui héberge Kubernetes.
Comme le montre la figure 5, le composant principal de Prometheus n’est pas un contrôleur centralisé. Il n’existe pas de moteur de traitement de règles qui génère indépendamment des alertes dans le cas d’une anomalie du comportement ou des performances. Au lieu de déployer des agents d’application sur des applications et des fonctions portables comme une mission de surveillance clandestine, Prometheus s’appuie sur les capacités des développeurs et leur volonté de créer une instrumentation dans le code source de leurs applications conteneurisées.
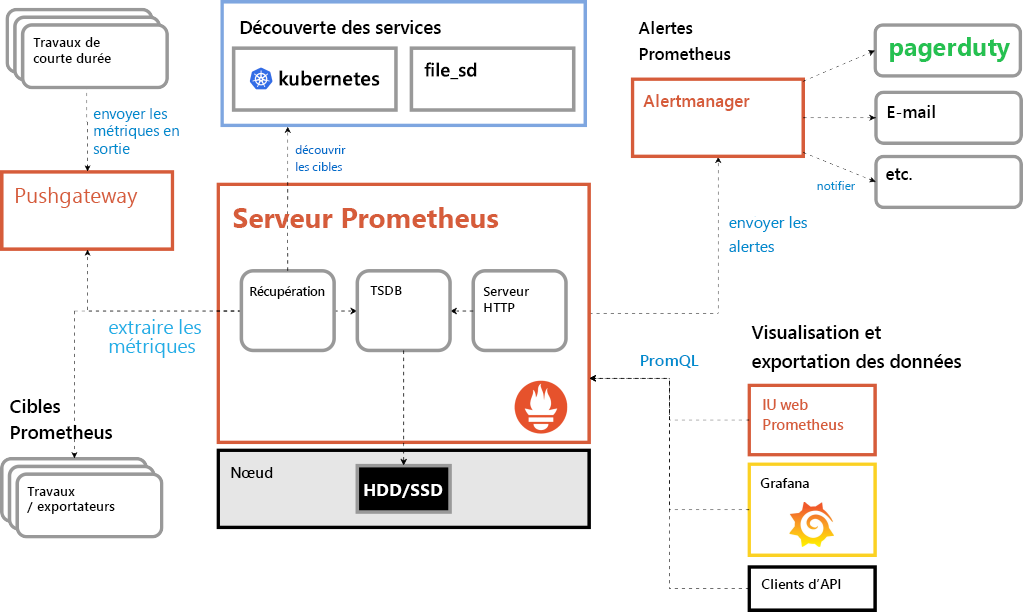
Figure 5 : Architecture modulaire et dépendances des services de Prometheus.
À cette fin, l’équipe fournit une bibliothèque de code portable que les développeurs incluent avec leur code. Chaque instance de la bibliothèque a sa propre base de données locale, qui agit comme une sorte de boîte d’envoi pour les messages sortants. Au lieu d’attendre que les messages soient envoyés (« push »), dans sa direction, le serveur Prometheus extrait de cette base de données locale les mises à jour des séries chronologiques (ou les y « racle », comme le disent certains ingénieurs de chez Prometheus) .
Le serveur Prometheus détermine périodiquement si les alertes sont justifiées, en se basant sur les règles d’alerte établies par un administrateur. Au lieu de publier lui-même ces alertes, il les envoie à un gestionnaire d’alertes indépendant. Comme les files d’attente de messagerie sur des systèmes distribués peuvent être construites de différentes façons, Prometheus choisit de ne pas réinventer la roue. Son gestionnaire d’alertes est conçu pour être intégré à n’importe quel service de messagerie ou de file d’attente déjà utilisé par l’organisation. Il prépare les alertes pour la distribution et les établit en conséquence.
Plateformes APM intégrées
De plus en plus, les fournisseurs de services cloud comme Amazon et Microsoft offrent des services de supervision natifs intégrés à leurs plateformes cloud. Par exemple, Azure prend en charge Azure Monitor (Figure 6), qui comprend un ensemble de services que les développeurs et les administrateurs peuvent utiliser pour collecter, analyser et agir sur la télémétrie concernant les performances des applications et l’infrastructure qui les héberge. Les événements émanant des applications, des machines virtuelles et d’autres ressources sont journalisés et utilisés pour calculer des métriques de performance. Différents services, comme Azure Log Analytics et Microsoft Power BI, peuvent être connectés aux sources de données où les journaux et les métriques sont stockés, pour générer des insights actionnables et créer des tableaux de bord visuels. De plus, les développeurs peuvent instrumenter leurs applications avec Azure Application Insights pour générer des données de télémétrie personnalisées. Ceci fournit une couche supplémentaire de supervision qui est spécifique à l’application et qui peut être extrêmement utile pour diagnostiquer les erreurs et leurs causes racine, souvent sans devoir se plonger dans le code source.
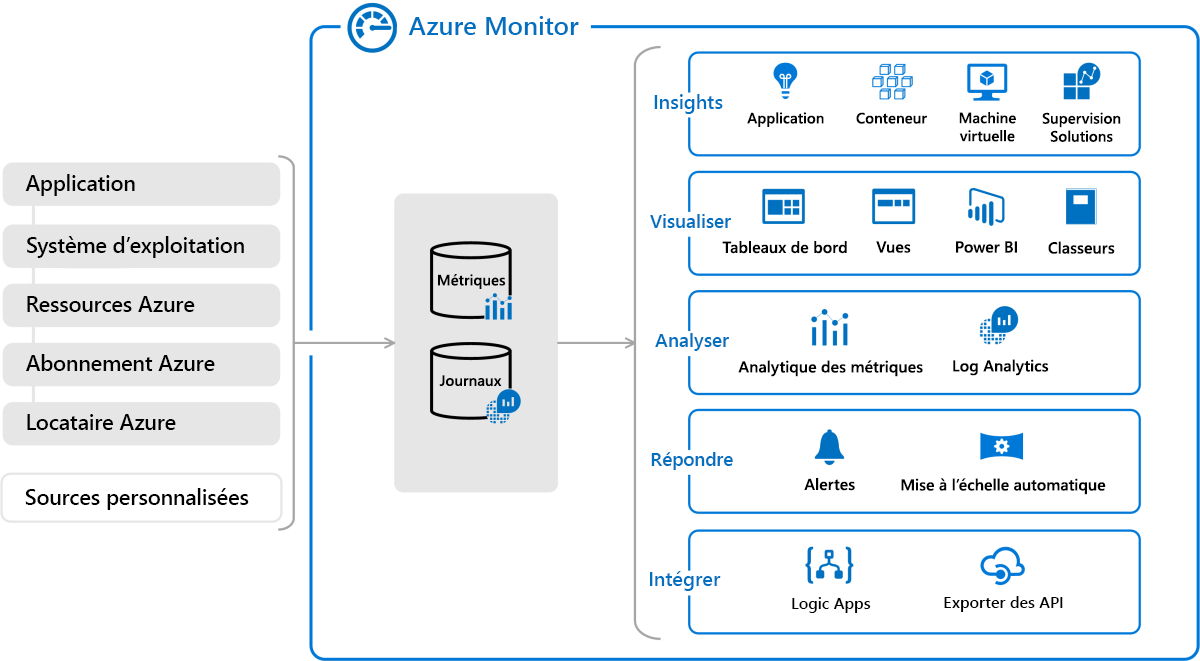
Figure 6 : La plateforme APM Azure Monitor.
AWS offre des fonctionnalités similaires avec Amazon CloudWatch, service de supervision complet pour les ressources cloud AWS et les applications qui s’exécutent sur AWS. Entre autres choses, CloudWatch peut être utilisé pour superviser l’utilisation des processeurs sur les instances EC2, pour collecter des métriques concernant les bases de données et les volumes de stockage AWS, pour superviser les journaux système et d’application existants de façon à détecter les problèmes et déclencher des alarmes quand les métriques dépassent un seuil spécifié. Vous pouvez également créer des workflows personnalisés qui appliquent automatiquement des actions que vous définissez quand des changements se produisent sur les ressources AWS d’une solution.
Les utilisateurs d’AWS et d’Azure ne sont pas obligés d’utiliser CloudWatch et Azure Monitor ; des plateformes APM de tiers, comme Relic One et Sumo Logic peuvent être utilisées à la place. Cependant, le fait que CloudWatch et Azure Monitor soient intégrés dans leurs plateformes respectives offre certains avantages, l’un d’entre eux étant la possibilité de mettre automatiquement à l’échelle les ressources cloud en réponse à des événements émanant du service de supervision. Par exemple, il est relativement simple de mettre à l’échelle le nombre d’instances de machine virtuelle quand l’utilisation moyenne du processeur dépasse une plage spécifiée. Cette mise à l’échelle peut également être accomplie via des connecteurs personnalisés pour que la plateforme cloud prenne en charge les notifications provenant de plateformes de supervision externes, mais la supervision intégrée réduit la complexité en éliminant le besoin de telles personnalisations.
Références
Une base de données de séries chronologiques stocke des séquences de valeurs dans le temps, en enregistrant leur progression et leur historique. Certains considèrent qu’il s’agit d’une forme de journalisation, bien que les créateurs de Prometheus ne seraient pas d’accord avec ce point de vue, en faisant valoir qu’un journal est essentiellement une table, alors qu’une base de données de séries chronologiques est une série.
The New Stack. SoundCloud’s Prometheus: A Monitoring System and Time Series Database Suited for Containers. https://thenewstack.io/soundclouds-prometheus-monitoring-system-time-series-database-suited-containers/.