Exercice - Utiliser le wrangling data dans Azure Data Factory
La fonctionnalité Power Query dans Azure Data Factory vous permet d’utiliser les données et de faire du data wrangling. C’est un objet qui peut être ajouté au concepteur du canevas comme activité dans un pipeline Azure Data Factory pour préparer les données sans code. Il permet aux personnes qui ne sont pas familiarisées avec les technologies de préparation de données classiques comme Spark ou SQL Server et avec des langages tels que Python et T-SQL de préparer les données à l’échelle du cloud de manière itérative.
La fonctionnalité Power Query utilise une interface de type grille pour la préparation des données de base. Cette interface, qui rappelle celle d’Excel, est également appelée éditeur de mashup en ligne. L’éditeur permet aussi aux utilisateurs plus avancés d’effectuer une préparation de données plus complexe à l’aide de formules. Vous devez d’abord créer un service lié à une source de données avant de pouvoir accéder aux données
Les formules fonctionnent avec Power Query Online, ce qui permet aux utilisateurs de fabrique de données d’utiliser les fonctions Power Query M. Power Query traduit ensuite le langage M généré par l’éditeur de mashup en ligne en code Spark pour l’exécution à l’échelle du cloud.
Cette fonctionnalité permet aux ingénieurs et aux analystes de données d’explorer et de préparer les jeux de données de manière interactive. En outre, ils peuvent travailler de manière interactive avec le langage M et prévisualiser le résultat avant de le voir dans le contexte d’un pipeline plus vaste.
Pour ajouter une activité Power Query dans Azure Data Factory, cliquez sur l’icône plus, puis sélectionnez Power Query dans le volet ressources de la fabrique.

Ajoutez un jeu de données source pour votre flux de wrangling data, puis sélectionnez un jeu de données de récepteur. Les sources de données suivantes sont prises en charge.
| Connecteur | Format de données | Type d'authentification |
|---|---|---|
| Stockage Blob Azure | CSV, Parquet | Clé du compte |
| Azure Data Lake Storage Gen1 | CSV | Principal de service |
| Azure Data Lake Storage Gen2 | CSV, Parquet | Clé de compte, Principal de service |
| Azure SQL Database | Authentification SQL | |
| Azure Synapse Analytics | Authentification SQL |
Après avoir sélectionné une source, cliquez sur Créer.

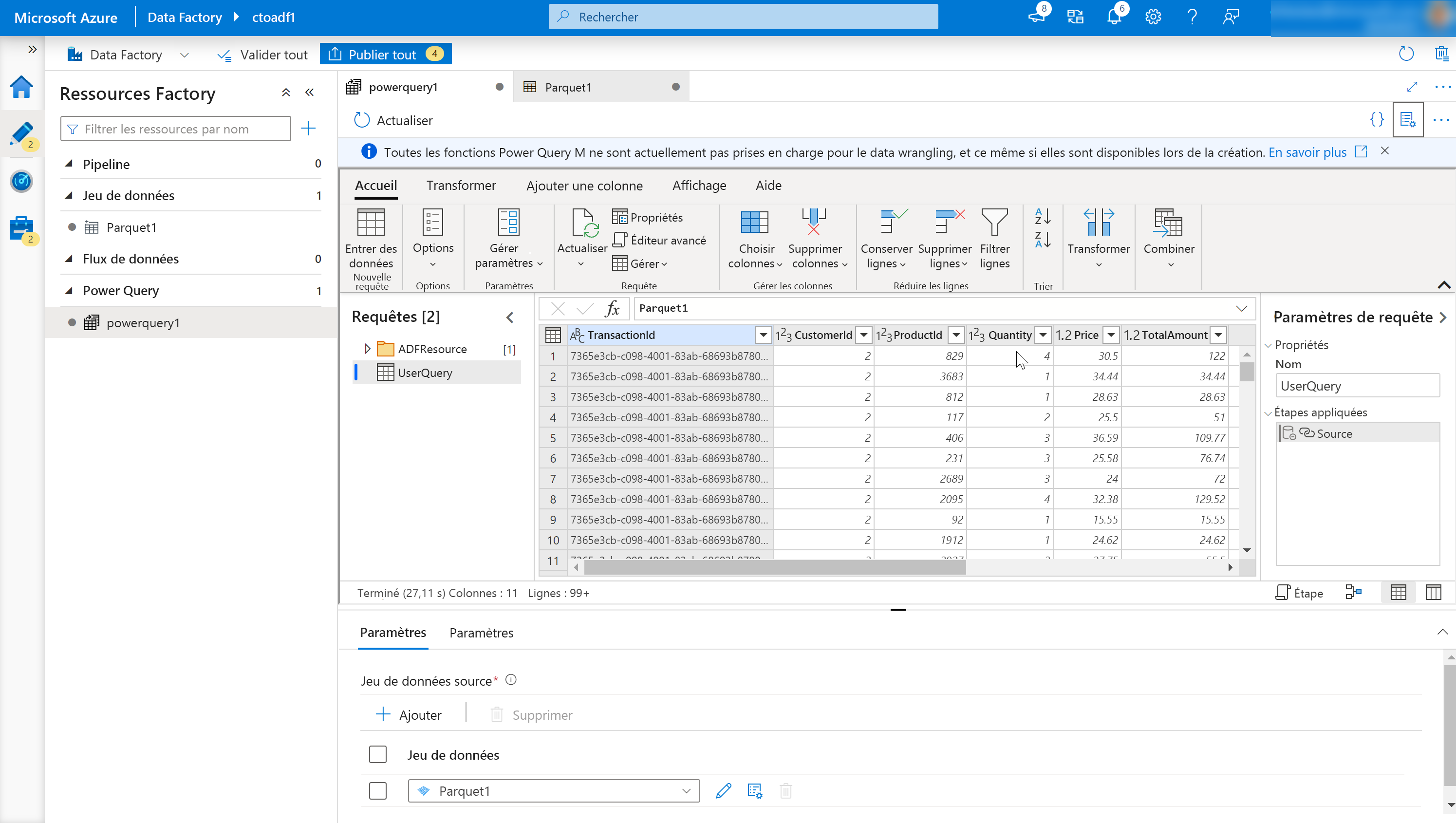
L’éditeur de mashup en ligne s’ouvre.

Elle se compose des éléments suivants :
Liste des jeux de données
Elle présente les jeux de données qui ont été définis comme source pour le data wrangling.
Barre d’outils des fonctions de wrangling
La barre d’outils met à la disposition de l’utilisateur une variété de fonctions de data wrangling pour manipuler les données, notamment :
- Gestion des colonnes
- Transformation de tables
- Réduction de lignes
- Ajout de colonnes.
- Combinaison de tables
Chaque élément dépend du contexte et contient des sous-fonctions spécifiques.
En-têtes de colonne
Quand vous cliquez avec le bouton droit, vous pouvez non seulement renommer les colonnes, mais également accéder à des éléments permettant de gérer les colonnes, en fonction du contexte.
Paramètres.
Cette option vous permet d’ajouter ou de modifier des sources de données et des récepteurs de données et de modifier le paramétrage de la tâche de data wrangling.
Fenêtre des étapes
Cette fenêtre affiche les étapes qui ont été appliquées à la sortie du wrangling. Dans cette capture, l’étape nommée « Source » a été appliquée à la sortie de wrangling nommée « UserQuery ».
Liste de sortie Power Query.
Liste les sorties de data wrangling qui ont été définies.
Bouton Publier
Vous permet de publier le travail qui a été créé.
Une tâche Power Query peut être ajoutée au concepteur de canevas de la même façon qu’une tâche d’activité Copy ou une tâche Flux de données de mappage et peut être gérée et supervisée de la même façon.
