Décrire le traitement intelligent des requêtes
Dans SQL Server 2017 et 2019, et avec Azure SQL, Microsoft a introduit un grand nombre de nouvelles fonctionnalités dans les niveaux de compatibilité 140 et 150. La plupart de ces fonctionnalités corrigent ce qui était des anti-modèles tels que l’utilisation des fonctions de valeur scalaire définies par l’utilisateur et l’utilisation de variables de table.
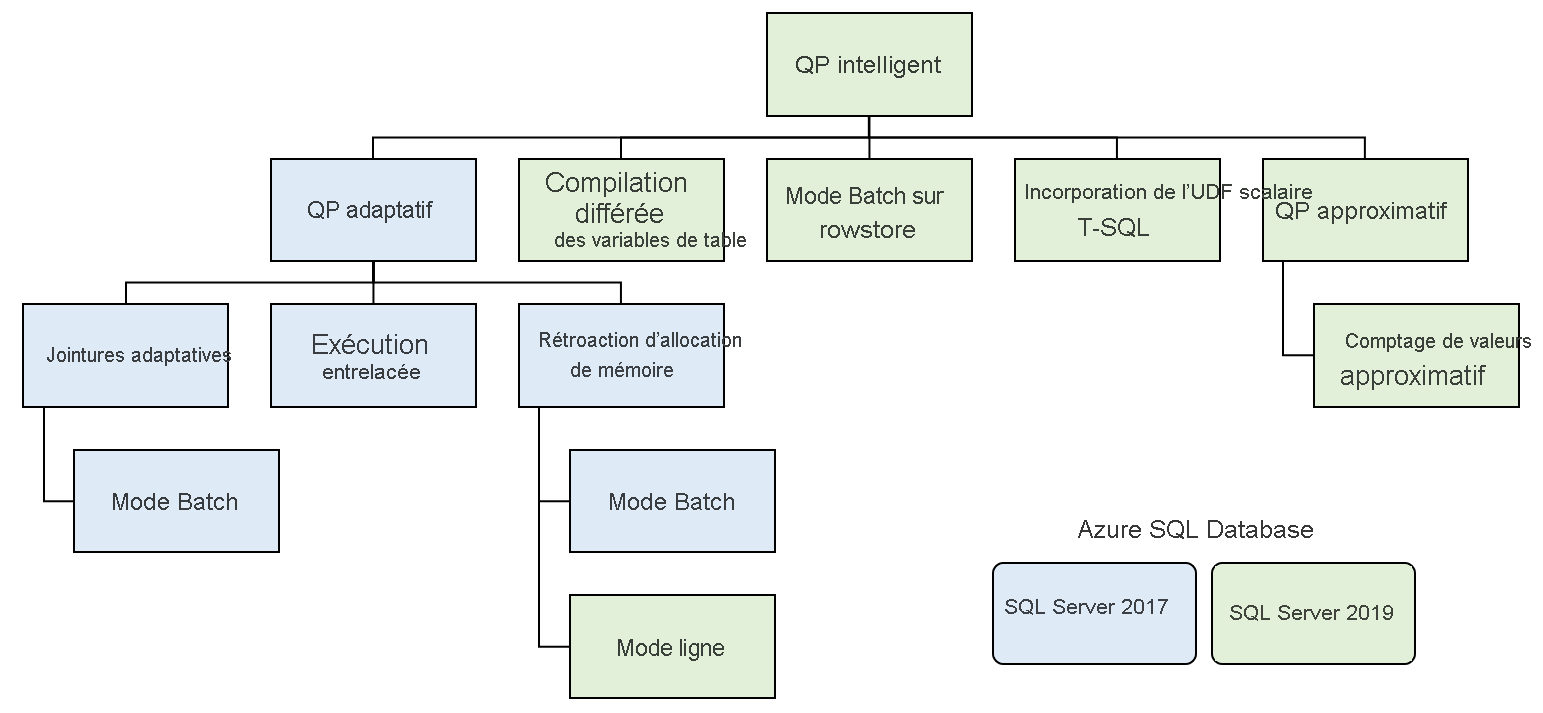
Ces fonctionnalités se divisent en plusieurs familles :
Le traitement intelligent des requêtes inclut des fonctionnalités qui améliorent les performances de charge de travail existantes avec un effort d’implémentation minimal.
Pour que les charges de travail soient automatiquement éligibles au traitement intelligent des requêtes, remplacez le niveau de compatibilité de la base de données applicable par 150. Par exemple :
ALTER DATABASE [WideWorldImportersDW] SET COMPATIBILITY_LEVEL = 150;
Traitement adaptatif des requêtes
Le traitement adaptatif des requêtes comprend un de nombreuses options qui rendent le traitement des requêtes plus dynamique, en fonction du contexte d’exécution d’une requête. Ces options incluent plusieurs fonctionnalités qui améliorent le traitement des requêtes.
Jointures adaptatives : le moteur de base de données déduit le choix de jointure entre le hachage et les boucles imbriquées en fonction du nombre de lignes qui vont dans la jointure. Actuellement, les jointures adaptatives ne fonctionnent qu’en mode d’exécution par lots.
Exécution entrelacée : actuellement, cette fonctionnalité prend en charge les fonctions table multi-instructions (MSTVF, multi-statement table-valued function). Avant SQL Server 2017, les fonctions MSTVF utilisaient une estimation de ligne fixe d’une ou de 100 lignes, selon la version de SQL Server. Cette estimation pouvait aboutir à des plans de requête non optimaux si la fonction retournait beaucoup plus de lignes. Un nombre effectif de lignes est généré à partir de la fonction MSTVF avant la compilation du reste du plan avec l’exécution entrelacée.
Rétroaction d’allocation de mémoire : SQL Server génère une allocation de mémoire dans le plan initial de la requête, en fonction des estimations du nombre de lignes basées sur les statistiques. Une forte asymétrie des données peut entraîner des surestimations ou des sous-estimations du nombre de lignes, pouvant entraîner à leur tour des surallocations de mémoire qui diminuent la concurrence ou des sousallocations sous l’effet desquelles la requête déversera les données dans tempdb. Avec la rétroaction d’allocation de mémoire, SQL Server détecte ces conditions et diminue ou augmente la quantité de mémoire allouée à la requête pour éviter le déversement ou la surallocation.
Toutes ces fonctionnalités sont activées automatiquement sous le mode de compatibilité 150 et ne demandent aucun autre changement à effectuer.
Compilation différée des variables de table.
Comme les fonctions MSTVF, les variables de table dans les plans d’exécution SQL Server réalisent une estimation de nombre de lignes fixe d’une ligne. Tout comme les MSTVF, cette estimation fixe a entraîné des performances médiocres lorsque la variable avait un nombre de lignes plus élevé que prévu. Avec SQL Server 2019, les variables de table sont maintenant analysées et ont un nombre effectif de lignes. La compilation différée est de nature similaire à l’exécution entrelacée pour les fonctions MSTVF, à ceci près qu’elle est effectuée à la première compilation de la requête plutôt que de manière dynamique dans le plan d’exécution.
Le mode batch sur rowstore
Le mode d’exécution par lots permet de traiter les données par lots au lieu de les traiter ligne par ligne. Les requêtes qui entraînent des coûts de processeur significatifs pour les calculs et les agrégations voient le plus grand avantage de ce modèle de traitement. En séparant le traitement par lots et les index columnstore, plus de charges de travail peuvent bénéficier du traitement en mode batch.
Incorporation de fonctions scalaires définies par l’utilisateur
Dans les versions antérieures de SQL Server, les fonctions scalaires n’étaient pas performantes pour plusieurs raisons. Les fonctions scalaires étaient exécutées de manière itérative, traitant une ligne à la fois. Elles n’avaient pas une bonne estimation des coûts dans le plan d’exécution et ne permettaient pas de parallélisme dans un plan de requête. Avec l’incorporation de fonctions définies par l’utilisateur, ces fonctions sont devenues des sous-requêtes scalaires à la place de l’opérateur de fonction définie par l’utilisateur dans le plan d’exécution. Cette transformation peut entraîner des gains significatifs en matière de performances pour les requêtes qui impliquent des appels de fonction scalaire.
Compte approximatif distinct
Un modèle de requête d’entrepôt de données courant consiste à exécuter un compte distinct de commandes ou d’utilisateurs. Ce modèle de requête peut s’avérer coûteux pour une grande table. Le compte approximatif distinct introduit une approche beaucoup plus rapide pour collecter un nombre distinct en regroupant les lignes. Cette fonction garantit un taux d’erreur de 2 % avec un intervalle de confiance de 97 %.