Modélisation des données
La modélisation des données sur Microsoft Power Platform examine l’ensemble de l’architecture des données et inclut un aperçu logique des données de Dataverse, de lacs de données et des sources externes utilisant des connecteurs.
Plusieurs types et normes pour la modélisation des données sont disponibles, notamment Unified Modeling Language (UML), IDEF1X et autres. Certaines normes de modèle de données sortent du cadre de cette unité, mais les modèles de données pour les structures de données Dataverse se répartissent généralement en deux catégories générales :
- Modèles de données logiques
- Modèles de données physiques
Diagrammes entité/association (ERD)
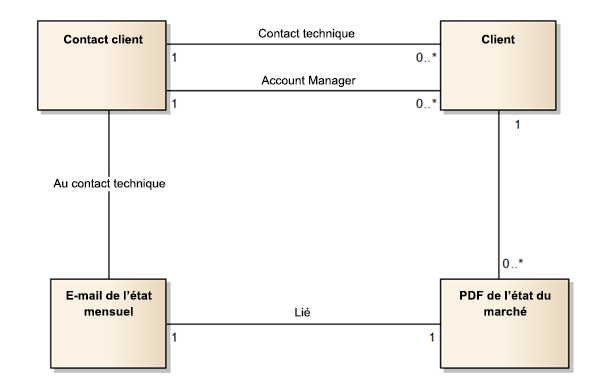
Les modèles de données logiques sont des diagrammes généraux qui montrent la manière dont les données circulent dans le système. Ils sont fréquemment rassemblés au début du projet lors de la découverte et avant que toutes les colonnes aient été définies. En général, le diagramme de modèle de données logique utilise les noms commerciaux des entités, et non les noms des schémas.
Les schémas de modèles de données logiques illustrent le flux de données dans une solution sans se soucier de l’implémentation physique.
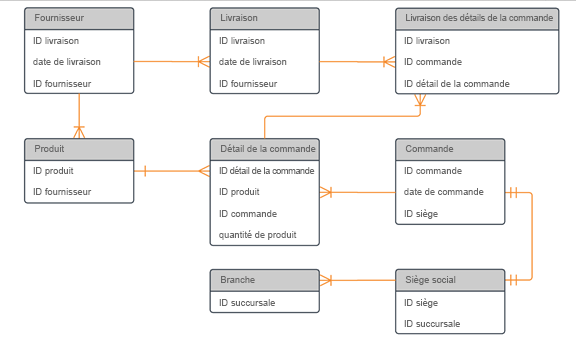
Les modèles de données physiques sont de niveau inférieur aux modèles de données logiques. Ils incluent généralement des détails au niveau de la colonne et des relations de conception plus précisément. Le modèle de données physique est créé lorsque la conception logique de haut niveau est convertie en entités physiques.
Les diagrammes de modèles de données physiques doivent inclure Dataverse, Microsoft Azure Data Lake Storage, Analysis Services Connector ou d’autres limites du magasin de données.
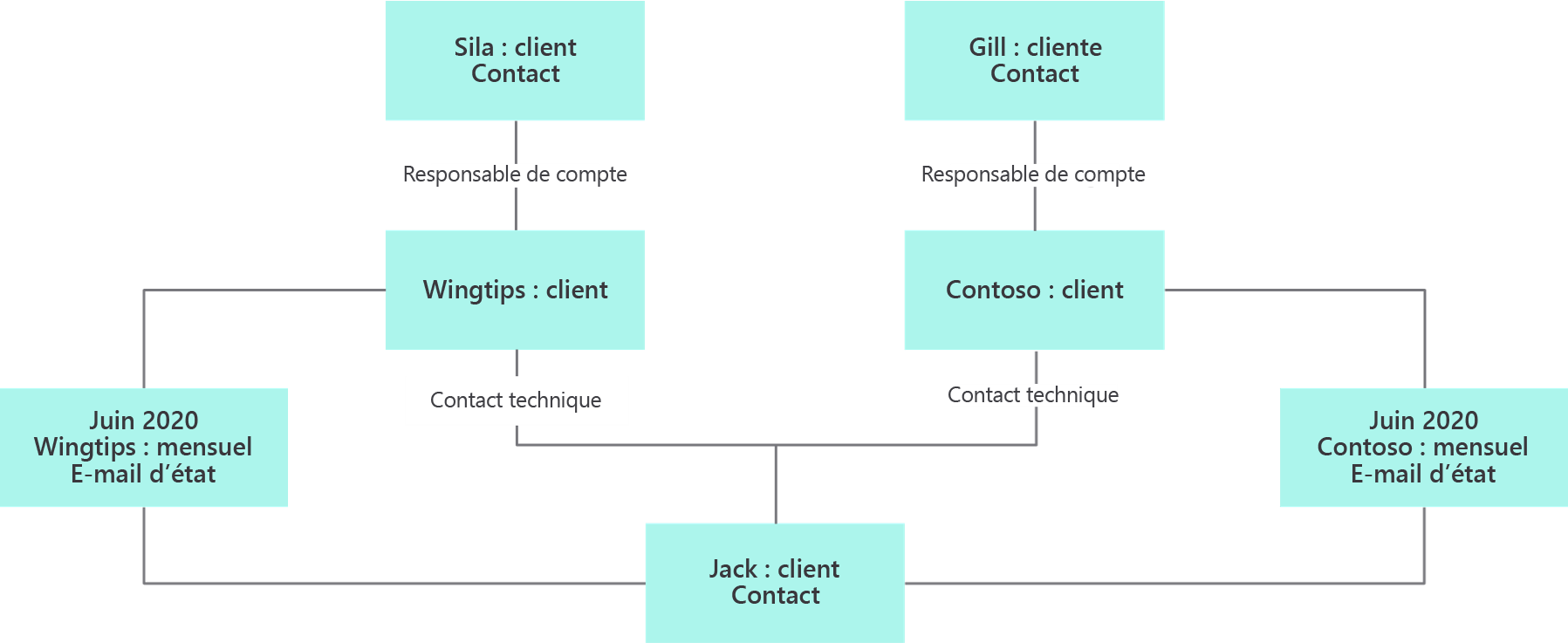
Vous pouvez également créer des diagrammes d’objet. Les diagrammes d’objets vous montrent ce que vous voulez savoir et, surtout, ce que vous ne voulez pas savoir. Les diagrammes d’objets doivent être réalisés lors de sessions de modélisation avec des experts du domaine.
Stratégies de modélisation de données
Tenez compte des instructions suivantes pour créer un modèle de données :
- Commencer par les tables et les relations principales : souvent, les équipes sont détournées du problème dans son ensemble ; toutefois, il est finalement plus facile de résoudre de petites parties du défi et de l’examiner de manière holistique plus tard.
- Sur normalisation : les équipes composées de personnes ayant de solides expériences d’architecte de données ont tendance à créer un modèle de données Dataverse comme s’ils créaient une base de données SQL Server traditionnelle. Cette approche peut conduire à une mauvaise expérience utilisateur et à des exigences de traitement supplémentaire. Les architectes de solution doivent travailler avec ces personnes pour déterminer la cause et l’effet des relations dans l’expérience utilisateur afin de les aider à comprendre l’objectif.
- Besoins d’aujourd’hui : une excellente fonctionnalité de Dataverse est qu’il peut être créé de manière incrémentielle en utilisant un processus agile ; cependant, avoir une vision de l’avenir à court et à long terme aide à établir une base. Veillez à ne pas vous plonger dans l’identification de tous les besoins futurs auxquels vous pouvez penser.
- Preuve de concept : Dataverse simplifie le processus consistant à créer un environnement, à essayer un modèle, à le jeter et à réessayer. Parfois, le fait de confronter deux équipes au même problème de modélisation des données peut produire des résultats utiles.
Influenceurs de modèles de données
Le modèle de données peut être influencé par une série de facteurs :
- Exigences de sécurité : les architectes de solution doivent toujours s’efforcer de simplifier les choses, mais ces simplifications peuvent entraîner des exigences dans le modèle de données.
- Expérience utilisateur : un concept que l’on oublie facilement est qu’à mesure que vous ajoutez la normalisation et les relations, vous créez des dispositifs dont les utilisateurs ont besoin pour naviguer dans les applications.
- Localisation et conservation des données : toutes les données ne peuvent pas être stockées. Souvent, les données des services ne peuvent pas être mises en cache et les entreprises ont des politiques internes qui régissent l’utilisation des données. Certaines données sont protégées par des lois gouvernementales ou peuvent avoir des exigences spécifiques en matière de stockage, par exemple, des informations identifiables, des numéros de cartes de crédit, etc.
- Rapports en libre-service : s’il faut un architecte de données pour naviguer dans le modèle de données, il y a de fortes chances que de nombreux outils de Power BI et d’exportation vers Excel soient moins utiles à l’utilisateur. La plupart des fonctionnalités en libre-service de Dataverse permettent la navigation d’un niveau de relation.
- Systèmes existants : déterminez si les systèmes sont des systèmes hérités, s’il existe une API ou si les données peuvent être consultées ou copiées.
- Localisation : évaluez si les exigences sont multirégionales, multilingues ou multidevises.