Modélisation des données pour Dataverse
Lorsque vous stockez ou affichez des données avec votre application, la structure des données constitue un aspect essentiel de la conception. Vous devez non seulement tenir compte de l’utilisation de ces données dans une application ou un écran spécifique, mais aussi de l’utilisation de ces données par les autres utilisateurs. En vous référant à vos personnages, tâches, processus métier et objectifs, vous pouvez définir les données à stocker et comment les structurer.
Types de tables
Dataverse comporte trois types de tables :
- Standard : les tables dans lesquelles vous pouvez stocker des données et ajouter à la navigation dans les applications basées sur des modèles. La plupart des tables que vous créez seront des tables standard. Il existe plusieurs tables standard créées à partir du schéma Common Data Model dans un environnement Dataverse.
- Activité : ces tables sont utilisées pour stocker des interactions telles que les appels téléphoniques, les tâches et les rendez-vous. Une base de données Dataverse compte un ensemble de tables d’activité.
- Virtuelle : ces tables vous permettent de créer la table et les colonnes dans Dataverse, et d’utiliser ensuite une source de données externe pour stocker les données. Pour l’utilisateur, les données apparaissent dans ses applications comme toutes les autres données.
Lorsque vous créez une table standard personnalisée, vous devez spécifier sa propriété :
- Utilisateur/Équipe : option par défaut
- Organisation : utilisée pour les données de référence.

Tables d’activité personnalisées
Les tables d’activité permettent de stocker des interactions. Elles ont une relation avec toutes les tables où Activer pour les activités est défini sur leurs métadonnées de table. Les tables d’activité partagent le même ensemble de colonnes et les mêmes privilèges de sécurité. Les lignes des tables d’activité apparaissent dans la chronologie sur les formulaires d’application pilotée par modèle. Dans cet exemple, une table d’activités personnalisée appelée Don a été créée.
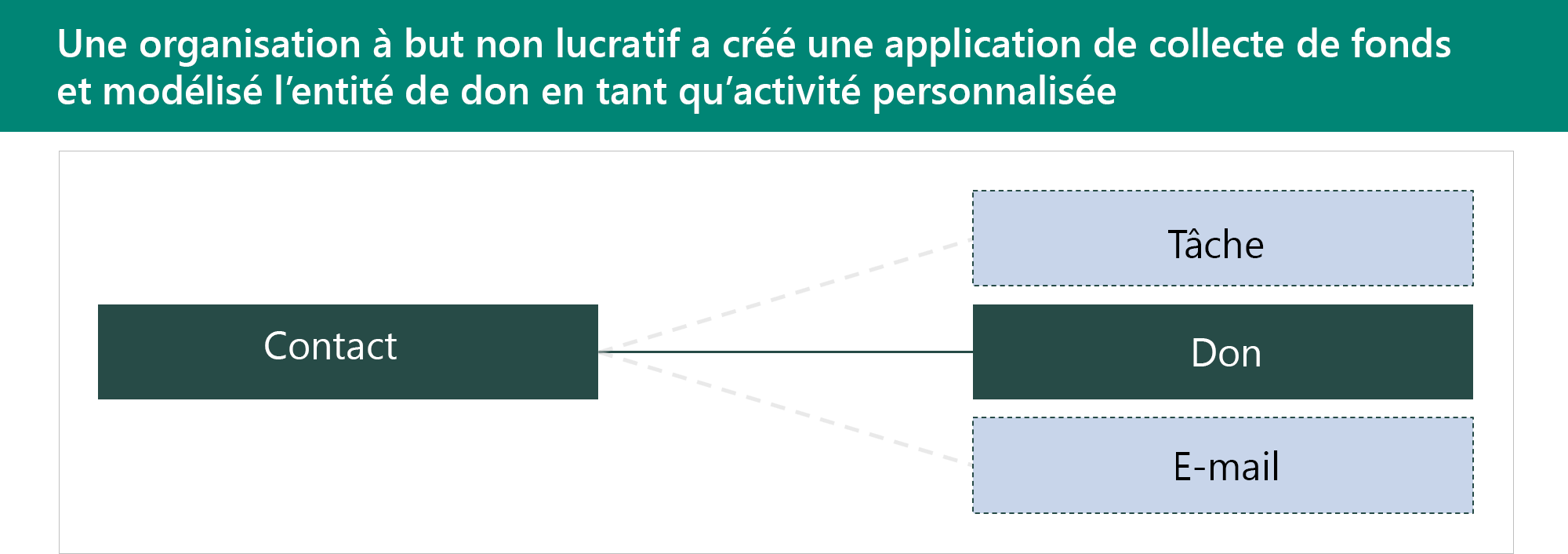
L’utilisation de tableaux d’activités personnalisés présente certains avantages :
- S’affiche dans une liste avec d’autres activités.
- Peut être cumulé avec d’autres activités.
- Peut créer un don dans n’importe quelle table qui soutient des activités.
L’utilisation de tableaux d’activités personnalisés présente également des inconvénients majeurs :
- Impossible de configurer la sécurité différemment de toute autre activité.
- Impossible de contrôler les tables liées à un don.
Types données colonne
Vous devez choisir judicieusement le type de données pour les colonnes. Cela est particulièrement vrai pour les types de données numériques car vous ne pouvez pas comparer des colonnes numériques avec différents types et il existe des restrictions sur les types de données pour les colonnes calculées et de cumul. Une fois qu’un type est choisi, il ne peut pas être modifié.
| Type de données | Commentaires |
|---|---|
| Oui/Non | Assurez-vous de ne jamais avoir besoin de plus de choix |
| Fichier et Image | Permet de stocker des fichiers et des images en ligne dans Dataverse |
| Client | Peut être un contact ou un compte |
| Rechercher/Options | Assurez-vous de choisir le meilleur |
| Date/heure | Assurez-vous de choisir le comportement approprié |
| Numérique | Beaucoup de choix, choisissez judicieusement |
Table de choix ou table de recherche
Vous pouvez, selon la situation, décider d’utiliser une table de recherche ou une table de choix.
Utilisez une table de choix lorsque vous souhaitez une table qui :
- stocke uniquement le libellé et la valeur sous forme de paire clé-valeur ;
- dispose d’une localisation intégrée ;
- est traitée comme un composant de solution ;
- ne dispose d’aucun moyen intégré de retirer des valeurs ;
- offre une expérience utilisateur fonctionnant sur environ 200 éléments ;
- peut être filtrée à l’aide de JavaScript ;
- est stockée sous forme de nombre entier sur la ligne.
Utilisez une table de recherche lorsque vous souhaitez une table qui :
- peut stocker d’autres données dans des colonnes sur la ligne ;
- requiert la création de la localisation ;
- est traitée comme des données de référence ;
- prend en charge l’état inactif ;
- offre une expérience utilisateur qui s’adapte à de nombreux éléments ;
- peut filtrer par vues et sécurité ;
- est stockée en tant que référence d’entité.
Le stockage d’autres données sur la table de recherche permet l’accès lors de l’exécution de flux de travail ou d’autres personnalisations qui référencent les données. Par exemple, une propriété associée peut être utilisée dans une condition de vérification.
En tant que composant de solution, une table de choix gère la résolution de fusion en préfixant la valeur avec le préfixe de l’éditeur.
L’ajout de valeurs sur une table de choix nécessite un accès de niveau administrateur/personnalisateur, tandis que les valeurs de recherche peuvent être modifiées par un utilisateur s’il y est autorisé au moyen de rôles de sécurité.
L’expérience utilisateur (UX) pour les choix est idéale pour les petits volumes de données, mais ne fonctionne pas bien pour les grands jeux. Les recherches fournissent des fonctionnalités de type de recherche non disponibles sur les choix.
Si vous avez des colonnes à choix multiples dépendant les unes des autres, cela ne peut être réalisé qu’avec un script basé sur un formulaire, tandis que les recherches peuvent être filtrées sur d’autres recherches à l’aide de la configuration.
Stockage des données de fichier et d’image
Vous disposez de plusieurs choix pour stocker les fichiers et les images :
- Dataverse : stockez des fichiers et des images grâce aux types de données Fichier et Image.
- SharePoint : adapté à la collaboration, mais présente un problème de sécurité. La sécurité des fichiers suit les autorisations SharePoint et n’est pas synchronisée avec les autorisations de ligne Dataverse.
- Stockage Azure : adapté à l’archivage et l’accès externe. Ce choix dispose d’une sécurité autonome, mais peut être accordé pour de courtes périodes de temps en fonction du lien généré pour la consommation (modèle de valet). Stockage Azure peut également gérer des fichiers volumineux.
Caractéristiques des types de données fichier et image :
- Ils sont adaptés pour le chargement et la référence.
- La sécurité suit les autorisations d’enregistrement.
- Ils sont limités par la taille.
Colonnes calculées (colonnes de formule Fx)
Les colonnes calculées permettent d’effectuer des calculs simples sur les données d’une ligne et elles :
- sont calculées lors de la récupération d’un enregistrement ;
- disposent d’une valeur en lecture seule ;
- peuvent inclure des colonnes de la même ligne et des colonnes dans des relations plusieurs-à-un ;
- peuvent inclure des colonnes de cumul dans le calcul ;
- ne peuvent pas déclencher un événement pour un flux de travail, un plug-in ou Power Automate.
- Elles sont créées à l’aide du langage de formule Fx.
Colonnes de cumul
Les colonnes de cumul permettent des agrégations pour les lignes associées dans des relations de type un-à-plusieurs et elles :
- sont calculées sur une base planifiée (minimum 1 heure) et peuvent être mises à jour à la demande par un utilisateur ;
- disposent d’une valeur en lecture seule ;
- peuvent cumuler les colonnes calculées ;
- peuvent utiliser la hiérarchie des enregistrements associés ;
- peuvent filtrer les tables liées ;
- ne peuvent pas déclencher un événement pour un flux de travail, un plug-in ou Power Automate.
Vous pouvez cumuler des colonnes calculées « simples », c’est-à-dire que les colonnes calculées qui incluent des fonctions non déterministes ne peuvent pas être cumulées.
Relations
Les relations définissent la façon dont les lignes sont reliées les unes aux autres dans Dataverse. Chaque table dans Dataverse a une clé primaire pour fournir une référence unique aux lignes de la table. Dans Dataverse, la clé primaire est un identificateur unique global (GUID) qui est généré automatiquement par Dataverse lorsqu’une ligne est créée. Les relations sont créées en ajoutant une référence à la clé primaire, appelée clé étrangère. Dans Dataverse, les relations sont créées en utilisant une colonne sur une table pour contenir la valeur de clé étrangère. Cette clé étrangère est un pointeur vers la clé primaire sur l’autre table.
Deux types de relation sont pris en charge dans Dataverse :
- Un-à-plusieurs (1:N)
- Plusieurs à plusieurs (N:N)
Relation un-à-plusieurs
La note de frais suivante est un exemple de relation un-à-plusieurs (1 : N).
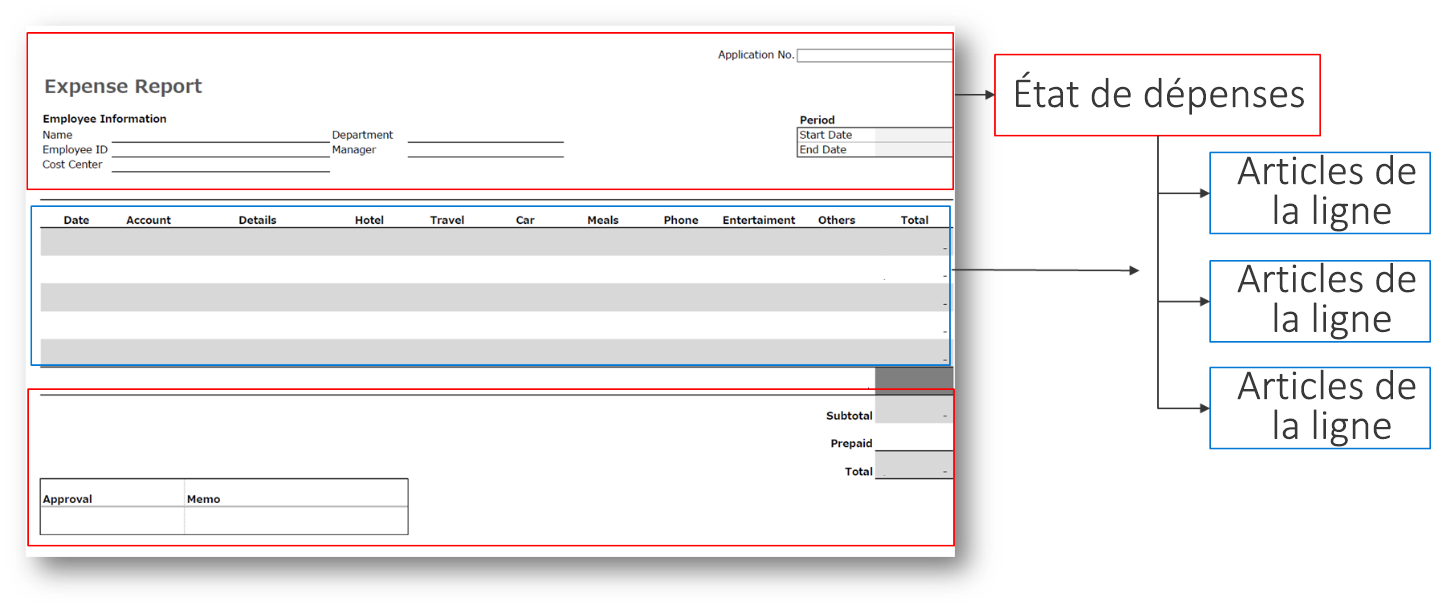
La capture d’écran précédente illustre la partie principale de la note de frais, qui contient le nom du collaborateur et les détails du service. Sous la partie principale, vous voyez plusieurs lignes de description pour chaque article acheté. Dans le cadre de cet exemple, ces descriptions sont appelées éléments de ligne. Les éléments de ligne ont une structure différente de la partie principale de la note de frais. Par conséquent, chaque note de frais contient plusieurs éléments de ligne.
La relation entre la note de frais et l’élément de ligne est un exemple de relation un-à-plusieurs (1:N). La partie principale de la note de frais est liée à plusieurs éléments de ligne. Vous pouvez également visualiser la relation du point de vue des éléments de ligne : chaque élément de ligne ne peut être lié qu’à une seule note de frais, ce qui constitue une relation plusieurs-à-un (N:1).
Relation plusieurs-à-plusieurs
Une structure de données plusieurs-à-plusieurs est un type spécial, utilisé lorsque plusieurs enregistrements peuvent être associés à plusieurs ensembles d’autres enregistrements. Votre réseau de partenaires commerciaux constitue un bon exemple de structure de données plusieurs-à-plusieurs. Vous avez plusieurs partenaires commerciaux (clients et fournisseurs) avec lesquels vous travaillez, et ces partenaires commerciaux travaillent également avec plusieurs de vos collègues.
Les sections suivantes fournissent des exemples de différents types de structures de données plusieurs-à-plusieurs.
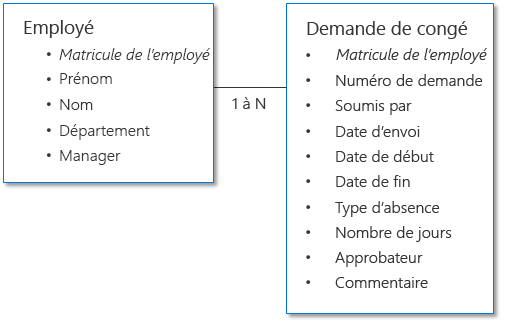
Exemple 1 : demande d’approbation de congé
L’exemple suivant montre deux jeux de données : l’un représente le collaborateur et l’autre représente la demande de congé. Comme chaque collaborateur envoie plusieurs demandes, la relation dans ce scénario est de type un-à-plusieurs, où « un » est le collaborateur et « plusieurs » sont les demandes. Les données des collaborateurs et les données des demandes de congé sont liées les unes aux autres avec le numéro de collaborateur comme colonne commune (également appelée clé).
Exemple 2 : approbation d’achat
Dans cet exemple, la structure de données semble sophistiquée, mais elle est similaire à l’exemple de note de frais qui a été abordé au début de cet article. Chaque fournisseur est associé à plusieurs commandes fournisseurs. Chaque collaborateur est en charge de plusieurs commandes fournisseurs. Par conséquent, ces deux ensembles de données ont une structure de données un-à-plusieurs.
Étant donné que les collaborateurs n’utilisent pas toujours le même fournisseur, les fournisseurs sont utilisés par plusieurs collaborateurs et chaque collaborateur travaille avec plusieurs fournisseurs. Par conséquent, la relation entre les collaborateurs et les fournisseurs est une relation plusieurs-à-plusieurs.
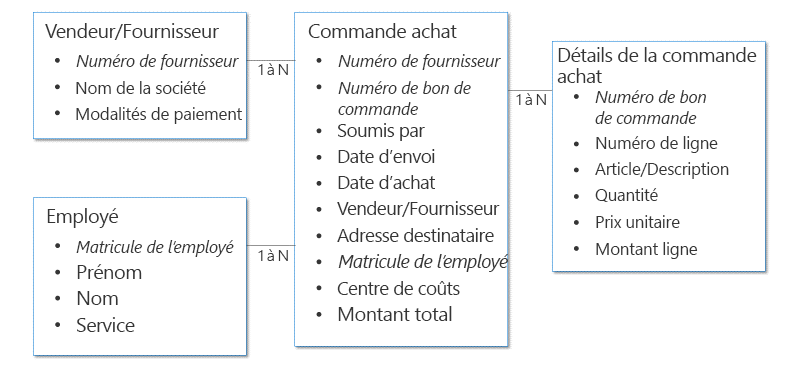
Exemple 3 : rapports de dépenses
L’exemple suivant montre un schéma entité/association (ERD) qui contient plusieurs tables pour une solution de note de frais.

Exemple 4 : suivre les deux avantages sélectionnés par le VIP
Dans cet exemple, nous avons deux VIP, John et Mary. John a choisi les avantages WiFi et Blanchisserie, et Mary a choisi les avantages WiFi et Mini-bar. Vous pouvez modéliser ce scénario de différentes manières. La première consiste à modéliser le scénario sous la forme d’une relation 1:N.
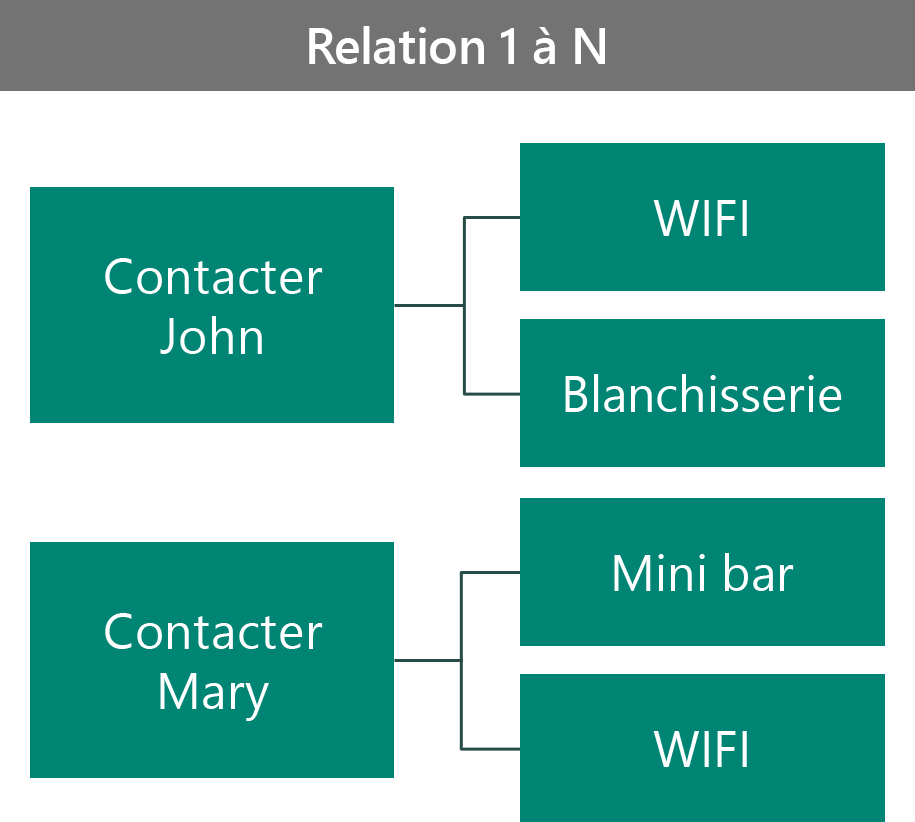
Dans cette configuration :
- L’enregistrement des avantages est unique au contact.
- Il n’est pas possible d’examiner tous les contacts qui choisissent un certain avantage.
- Vous pouvez bénéficier de la sécurité des enregistrements en fonction du propriétaire du contact.
- Vous pouvez stocker plus de données sur l’enregistrement des avantages spécifiques au contact.
- La relation à l’avantage est parentale, sinon vous rendez les enregistrements d’avantages orphelins.
La deuxième manière consiste à modéliser le scénario sous la forme d’une relation N:N.
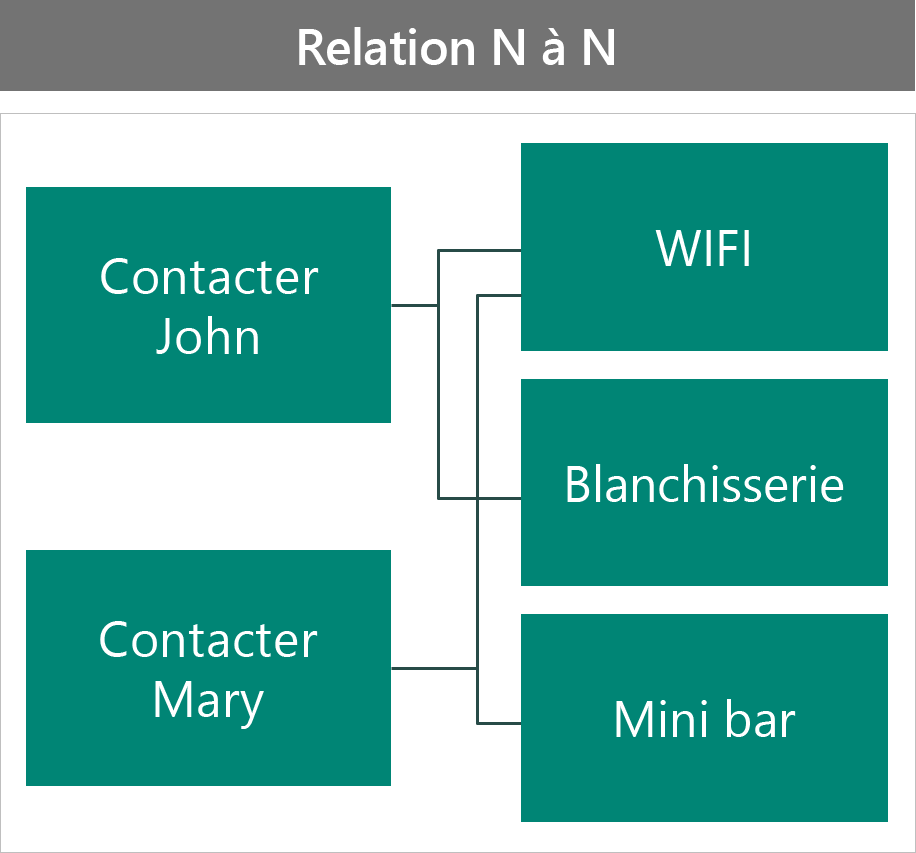
Dans cette configuration :
- Les enregistrements associés de l’avantage affichent tous les contacts qui choisissent cet avantage.
- La sécurité sur l’avantage est partagée pour tous les contacts, donc il n’est pas possible de s’adapter à chaque contact.
- Tous les attributs de l’avantage sont partagés pour tous les contacts, donc il n’y a pas de données spécifiques au contact.
- Vous devez utiliser la relation de référence, sinon vous supprimez l’avantage des autres contacts.
Aucune des deux configurations n’est idéale.
L’exemple suivant montre la création d’une table personnalisée (interjeu) pour contenir les avantages du VIP.
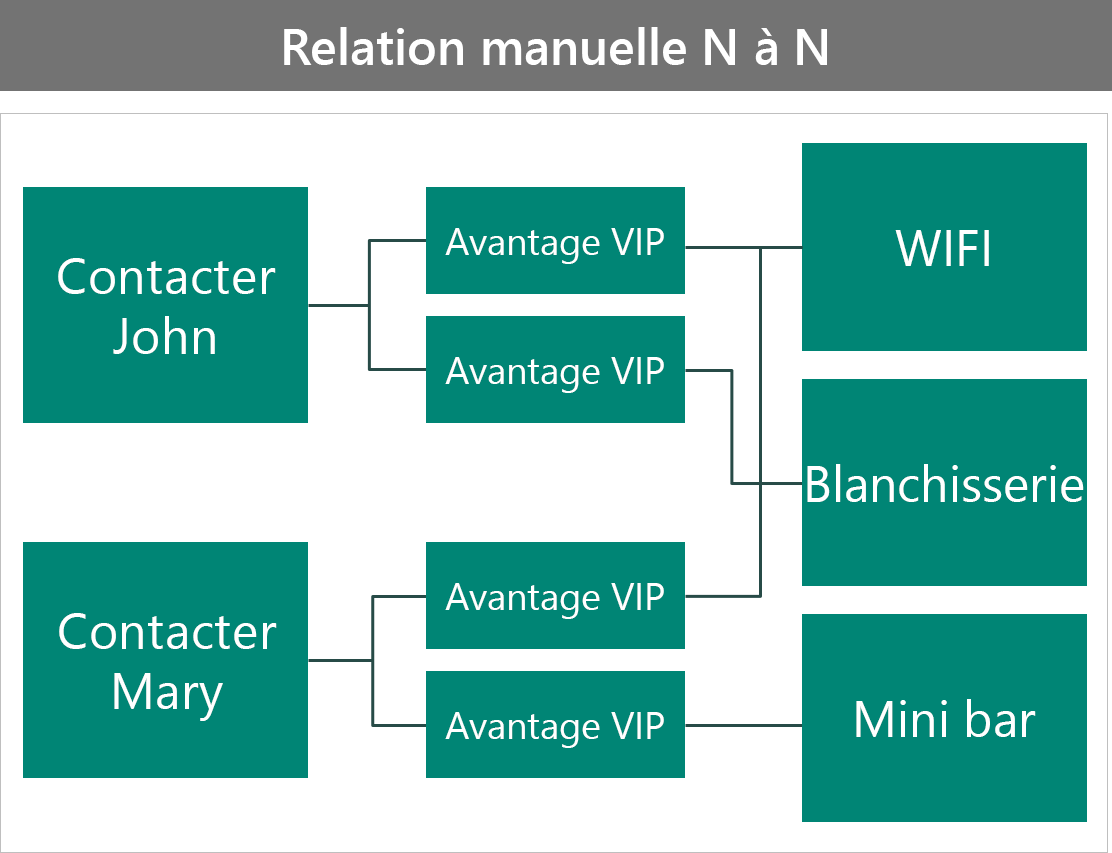
Cette configuration :
- Ajoute la possibilité de stocker plus de données sur le tableau des avantages spécifiques à ce contact.
- Nécessite plus de travail pour l’utilisateur pour connecter les enregistrements, il doit maintenant créer la ligne d’intersection manuellement.
- Les avantages peuvent être sécurisés individuellement.
- L’interrogation est plus difficile, car vous n’avez pas la possibilité d’accéder directement aux attributs de la table des avantages.
L’exemple suivant montre comment utiliser les colonnes sur la table Contact.
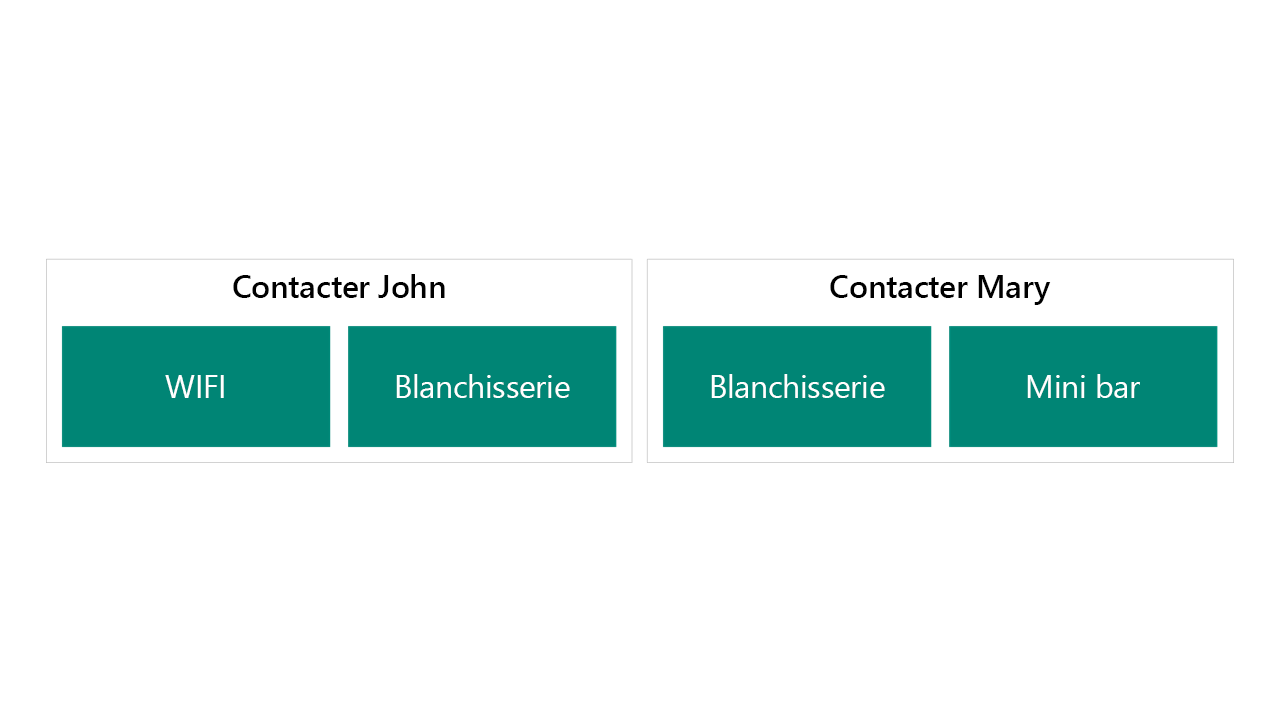
Cette configuration :
- fonctionne bien pour les avantages primaires et secondaires, mais ne permettrait pas de suivre de nombreux avantages ;
- simplifie les requêtes et Power BI en libre-service pour les utilisateurs ;
- suit la même sécurité que celle de l’enregistrement du contact ;
- vous oblige à créer une requête qui analyse les avantages principaux et secondaires si vous interrogez tous les utilisateurs qui choisissent un avantage principal.
Cette configuration est un bon exemple lorsque l’avantage doit être enregistré à des fins de conformité/statistiques mais n’a aucun impact sur l’entreprise ou le traitement.
Comportements des relations
Les comportements relationnels contrôlent la manière dont certaines actions se répercutent sur les lignes liées à la ligne de la table principale via la relation 1:N. Les comportements maintiennent l’intégrité référentielle et peuvent empêcher les enregistrements orphelins d’être laissés de côté.
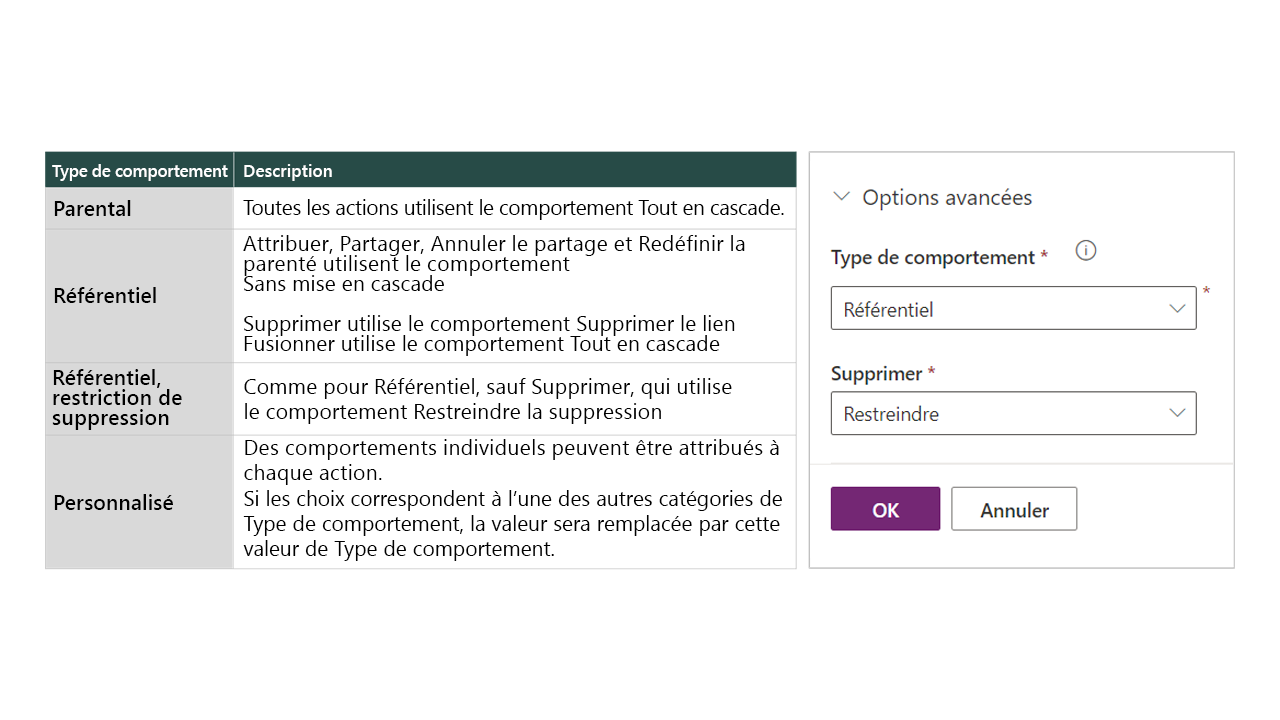
Important
La définition des comportements relationnels est importante car la cascade d’enregistrements attribués peut entraîner l’attribution d’enregistrements associés. En cas de doute, définissez le comportement sur Référentiel et Restreindre.
Clés secondaires
Des clés secondaires sont utilisées dans les intégrations pour réduire le besoin d’effectuer une requête pour trouver un enregistrement. À l’aide d’une clé secondaire, une ligne peut être mise à jour sans connaître son GUID.
Clés secondaires :
- Sont parfaites pour une utilisation dans les récupérations et les mises à jour.
- Peut contenir des nombres décimaux, des nombres entiers, des champs de texte, des dates et des champs de recherche.
- Vous pouvez créer jusqu’à cinq clés secondaires par table.
- Créez un index unique Nullable dans les coulisses pour appliquer l’unicité de la clé.
Lorsqu’une clé est créée, le système valide que cette clé peut être prise en charge par la plateforme.
Bonnes pratiques relatives au schéma ERD
Lors de la création d’ERD pour Dataverse, vous devez :
- éviter la duplication des données ; Chaque élément de données doit être unique. Au lieu de dupliquer les mêmes données entre plusieurs tables, utilisez des fonctionnalités telles que les formulaires d’aperçu et l’affichage des données de table associées dans les vues.
- Utilisez les associations ERD pour examiner et identifier les éventuels comportements en cascade susceptibles d’impacter la logique métier. Par exemple, avec les relations parentales, des autorisations comme Affecter, Partager, Annuler le partage, Apparenter à nouveau, Supprimer et Fusionner sont automatiquement appliquées aux enregistrements associés lors de la mise à jour d’un enregistrement parent.