concevoir une solution d’intégration de données avec Azure Data Factory
Azure Data Factory est un service cloud d’intégration de données qui permet de créer et de planifier des workflows pilotés par les données. Vous pouvez utiliser Azure Data Factory pour orchestrer le déplacement des données et transformer les données à grande échelle. Les workflows pilotés par les données, ou pipelines, ingèrent des données provenant de magasins de données disparates. Azure Data Factory est un processus d’intégration de données ETL (extraire, transformer et charger). Ce processus d’intégration combine les données de plusieurs sources de données dans un même magasin de données.
Points à connaître sur Azure Data Factory
Il y a quatre étapes principales pour créer et implémenter un workflow piloté par les données dans l’architecture Azure Data Factory :
- Se connecter et collecter. Tout d’abord, ingérez les données pour collecter toutes les données des différentes sources dans un emplacement centralisé.
- Transformer et enrichir. Ensuite, transformez les données en utilisant un service de calcul comme Azure Databricks et Azure HDInsight Hadoop.
- Fournir une intégration continue et livraison continue (CI/CD), et publier. Prenez en charge CI/CD en utilisant GitHub et Azure DevOps pour livrer le processus ETL de manière incrémentielle avant de publier les données sur le moteur analytique.
- Surveiller. Enfin, utilisez le portail Azure pour monitorer dans le pipeline les activités planifiées et les défaillances éventuelles.
Le diagramme suivant montre comment Azure Data Factory orchestre l’ingestion des données de différentes sources de données. Les données sont ingérées dans un stockage Blob et stockées dans Azure Synapse Analytics. Les composants d’analyse et de visualisation sont également connectés à Azure Data Factory. Azure Data Factory fournit une interface de gestion commune pour tous vos besoins d’intégration de données.
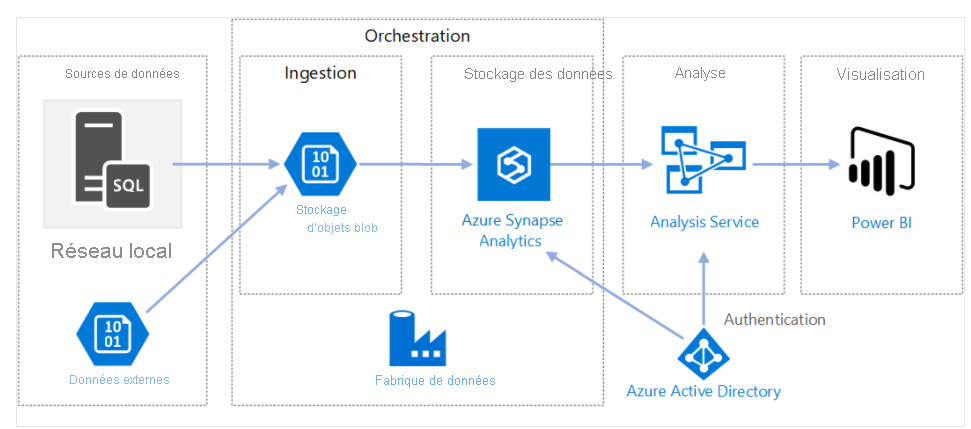
Composants d’Azure Data Factory
Azure Data Factory a les composants suivants qui fonctionnent ensemble pour fournir la plateforme de déplacement et d’intégration des données.
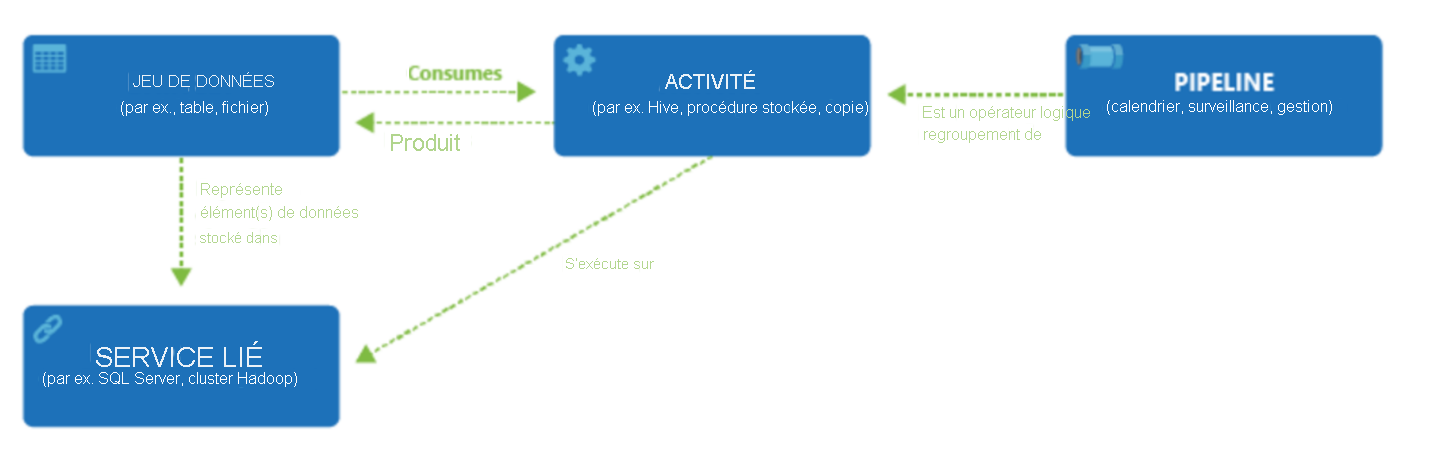
- Pipelines et activités : les pipelines fournissent un regroupement logique d’activités qui exécutent une tâche. Une activité est une étape de traitement unique au sein d’un pipeline. Azure Data Factory prend en charge les activités de déplacement de données, de transformation de données et de contrôle.
- Jeux de données : les jeux de données sont des structures de données au sein de vos magasins de données.
- Services liés : les services liés définissent les informations de connexion nécessaires pour qu’Azure Data Factory se connecte aux ressources externes.
- Flux de données : les flux de données permettent aux ingénieurs Données de développer une logique de transformation des données sans écrire de code. Les activités de flux de données peuvent être opérationnalisées en utilisant les fonctionnalités existantes d’Azure Data Factory pour la planification, le contrôle, les flux et le monitoring.
- Runtimes d’intégration : les runtimes d’intégration forment un pont entre l’activité et les objets de services liés. Il y a trois types de runtime d’intégration : Azure, auto-hébergé et Azure-SSIS.
Scénario d'entreprise
Un des défis majeurs pour un détaillant en pleine expansion dans le domaine de l’aménagement intérieur comme Tailwind Traders est le volume élevé de données stockées dans des systèmes de stockage relationnels, non relationnels et autres, dans le cloud et localement. La gestion souhaite que les insights métier soient exploitables à partir de ces données en temps quasi réel. Par ailleurs, l’équipe commerciale veut configurer et déployer des solutions de ventes incitatives et de ventes croisées. Comment pouvez-vous créer une solution d’ingestion de données à grande échelle dans le cloud ? Quels sont les services et solutions Azure que vous devez adopter pour faciliter le déplacement et la transformation des données entre les différents magasins de données et les ressources de calcul ?
Voyons comment les composants Azure Data Factory sont impliqués dans un scénario de préparation et de déplacement de données pour Tailwind Traders. Ils possèdent de nombreuses sources de données différentes auxquelles se connecter et ces données doivent être ingérées et transformées par des procédures stockées exécutées sur les données. Enfin, les données doivent être poussées sur la plateforme analytique pour être analysées.
- Dans ce scénario, le service lié permet à Tailwind Traders d’ingérer des données de différentes sources, et stocke des chaînes de connexion pour déclencher des services de calcul à la demande.
- Vous pouvez exécuter des procédures stockées pour la transformation de données qui se produit à travers le service lié dans Azure SSIS, environnement du runtime d’intégration pour Tailwind Traders.
- Les composants de jeux de données sont utilisés par l’objet d’activité. Celui-ci contient la logique de transformation.
- Vous pouvez déclencher le pipeline, qui est l’ensemble des activités regroupées.
- Vous pouvez alors utiliser Azure Data Factory pour publier le jeu de données final sur un autre service lié consommé par des technologies comme Power BI ou le machine learning.
Points à prendre en compte pour utiliser Azure Data Explorer
Évaluez Azure Data Factory par rapport aux critères de décision suivants et réfléchissez aux avantages que le service peut apporter à votre solution d’intégration de données pour Tailwind Traders.
- Prenez en compte les exigences de l’intégration de données. Azure Data Factory sert deux communautés : la communauté du Big data et la communauté d’entreposage de données relationnelles qui utilise SQL Server Integration Services (SSIS). En fonction des besoins de données de votre organisation, vous pouvez configurer des pipelines dans le cloud en utilisant Azure Data Factory. Vous pouvez accéder aux données avec des services de données cloud et locaux.
- Prenez en compte le codage des ressources. Si vous préférez une interface graphique pour configurer des pipelines, l’outil de création et de monitoring Azure Data Factory est adapté à vos besoins. Azure Data Factory fournit un processus avec peu ou pas de code pour utiliser les sources de données.
- Prenez en compte la prise en charge de plusieurs sources de données. Azure Data Factory prend en charge plus de 90 connecteurs pour intégrer des sources de données disparates.
- Prenez en compte l’infrastructure serverless. L’utilisation d’une solution serverless complètement managée pour l’intégration de données présente des avantages. Vous n’avez pas besoin de gérer, configurer ou déployer des serveurs, et vous pouvez mettre à l’échelle les charges de travail fluctuantes.