concevoir une solution d’intégration de données avec Azure Data Lake
Un lac de données est un dépôt de données stocké dans son format naturel, généralement sous forme de blobs ou de fichiers. Azure Data Lake Storage est une solution de lac de données complète, évolutive et économique pour l’analytique du Big Data intégrée à Azure. Azure Data Lake Storage allie un système de fichiers à une plateforme de stockage pour vous permettre d’identifier rapidement des insights dans vos données. La solution s’appuie sur les fonctionnalités du Stockage Blob Azure afin de fournir des optimisations pour les charges de travail analytiques. Cette intégration active les fonctionnalités de niveau de performance de l’analyse, de haute disponibilité, de sécurité et de durabilité du stockage Azure.
Notes
L’implémentation actuelle du service est Azure Data Lake Storage Gen2.
Points à connaître sur Azure Data Lake Storage
Pour mieux comprendre Azure Data Lake Storage, examinons les caractéristiques suivantes.
- Azure Data Lake Storage peut stocker n’importe quel type de données à l’aide du format natif des données. Avec la prise en charge des formats de données et des tailles de données massives, Azure Data Lake Storage peut fonctionner avec des données structurées, semi-structurées et non structurées.
- La solution est principalement conçue pour fonctionner avec Hadoop et tous les frameworks qui utilisent le système de fichiers DFS (HDFS) Apache Hadoop comme couche d’accès aux données. Les infrastructures d’analyse de données qui utilisent HDFS comme couche d’accès aux données peuvent y accéder directement.
- Azure Data Lake Storage prend en charge un haut débit pour une analytique intensive en entrée et en sortie, et le déplacement des données.
- Le modèle de contrôle d’accès Azure Data Lake Storage prend en charge le contrôle d’accès en fonction du rôle (RBAC) Azure et les listes de contrôle d’accès (ACL) de l’interface du système d’exploitation portable pour UNIX POSIX (Portable Operating System Interface for Unix).
- Azure Data Lake Storage utilise les modèles de réplication d’objets Blob Azure. Ces modèles assurent la redondance des données dans un centre de données unique avec un stockage localement redondant (LRS).
- Azure Data Lake Storage offre un stockage massif et accepte de nombreux types de données à des fins d’analyse.
- Azure Data Lake Storage est facturé à tous les niveaux d’Azure Blob Storage.
Fonctionnement d’Azure Data Lake Storage
L’utilisation d’Azure Data Lake Storage nécessite trois étapes importantes :
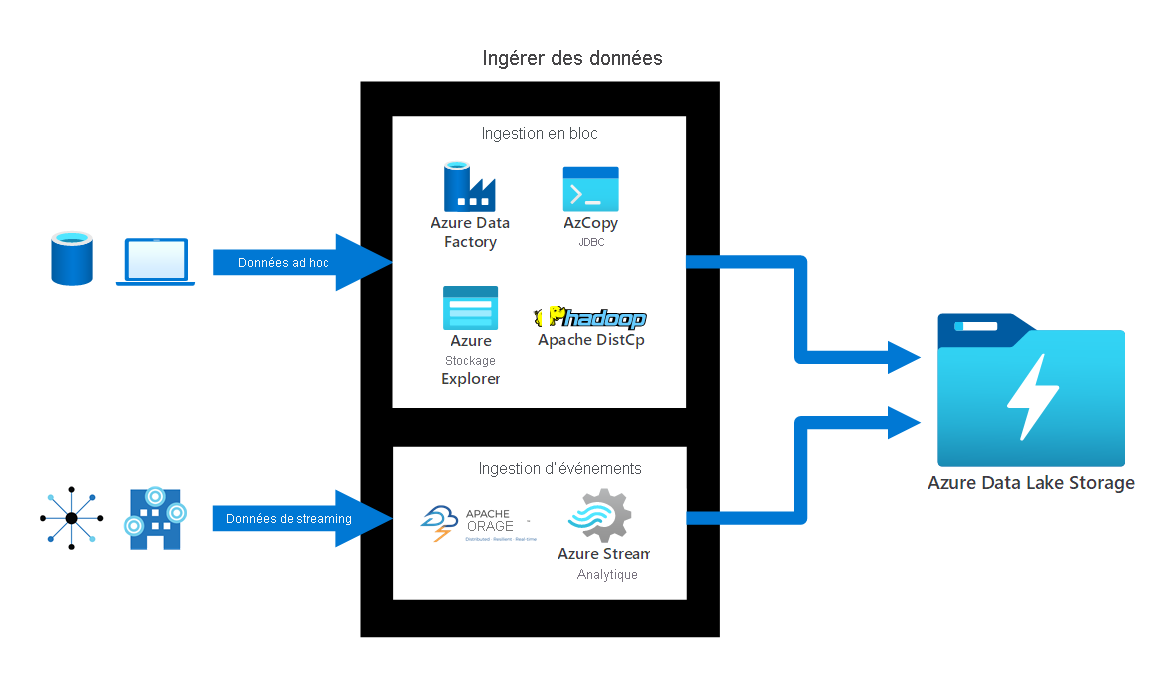
Ingérer des données. Azure Data Lake Storage offre de nombreuses méthodes d’ingestion de données :
- Pour les données non planifiées, vous pouvez utiliser des outils comme AzCopy, Azure CLI, PowerShell et l’Explorateur Stockage Azure.
- Pour les données relationnelles, vous pouvez utiliser le service Azure Data Factory. Vous pouvez transférer des données à partir de n’importe quelle source, comme Azure Cosmos DB, SQL Database, Azure SQL Managed Instances, etc.
- Pour les données de streaming, vous pouvez utiliser des outils comme Apache Storm sur Azure HDInsight, Azure Stream Analytics, etc.
Le diagramme suivant montre comment les données non planifiées et les données de streaming sont ingérées en bloc ou de manière non planifiée dans Azure Data Lake Storage.
Accéder aux données stockées. Le moyen le plus simple d’accéder à vos données consiste à utiliser l’Explorateur Stockage Azure. L’Explorateur Stockage est une application autonome avec une interface graphique utilisateur (GUI) pour accéder à vos données Azure Data Lake Storage. Vous pouvez également utiliser PowerShell, Azure CLI, HDFS CLI ou d’autres SDK de langage de programmation pour accéder aux données.
Configurer le contrôle d’accès. Contrôlez qui peut accéder aux données stockées dans Azure Data Lake Storage en implémentant un mécanisme d’autorisation. Vous pouvez choisir Azure RBAC ou ACL.
Scénario d'entreprise
Tailwind Traders a plusieurs sources de données, notamment des sites web, des systèmes de point de vente, des sites de réseaux sociaux et des appareils IoT (Internet des objets). L’entreprise aimerait utiliser Azure pour analyser l’ensemble des données métier. Vous êtes chargé de fournir des recommandations sur la façon dont Azure peut améliorer les systèmes décisionnels existants. Vous devez conseiller l’équipe sur l’utilisation des fonctionnalités du stockage Azure pour ajouter de la valeur à la solution décisionnelle de l’entreprise. Pour répondre aux exigences en matière de données, vous prévoyez de recommander Azure Data Lake Storage. Data Lake Storage fournit un référentiel où vous pouvez charger et stocker de gros volumes de données non structurées, avec pour but l’analytique Big Data hautes performances.
Voyons dans quelle mesure Azure Data Lake Storage peut être le choix approprié pour répondre aux besoins de Big Data de l’organisation.
| Scénario | Solution |
|---|---|
| Fournir un entrepôt de données dans le cloud pour gérer de gros volumes de données. | Azure Data Lake Storage s’exécute sur du matériel virtuel dans la plateforme Azure. Le stockage est scalable, rapide et fiable et n’engendre pas de frais importants. Il sépare les coûts de stockage des coûts du calcul. à mesure que le volume de vos données augmente, seuls vos besoins en stockage changent. |
| Prendre en charge une collection variée de types de données comme des fichiers JSON, des fichiers CSV, des fichiers journaux ou d’autres formats. | Azure Data Lake Storage permet la démocratisation des données pour votre organisation en stockant tous vos formats de données (y compris les données brutes) à un seul emplacement. Quand vous éliminez les silos de données, vos utilisateurs peuvent utiliser des outils comme Azure Data Explorer pour accéder à chaque donnée et l’utiliser dans leur compte de stockage. |
| Permettre le stockage et l’ingestion de données en temps réel. | Azure Data Lake Storage peut ingérer des données en temps réel directement à partir d’une instance d’Apache Storm sur Azure HDInsight, Azure IoT Hub, Azure Event Hubs ou Azure Stream Analytics. Il fonctionne également avec des données semi-structurées et vous permet d’ingérer toutes vos données en temps réel dans votre compte de stockage. |
Points à prendre en compte pour choisir entre le Stockage Blob Azure ou Azure Data Lake
Le tableau suivant compare les critères de solution de stockage du Stockage Blob Azure et d’Azure Data Lake. Passez en revue les critères et déterminez la solution optimale pour Tailwind Traders.
| Comparer | Azure Data Lake | Stockage Blob Azure |
|---|---|---|
| Types de données | Adapté au stockage de grands volumes de données de texte | Idéal pour stocker des données non structurées qui ne sont pas basées sur du texte, comme des photos, des vidéos et des sauvegardes |
| Redondance géographique | Doit configurer manuellement la réplication des données | Fournit un stockage géoredondant par défaut |
| Espaces de noms | Prend en charge les espaces de noms hiérarchiques | Prend en charge les espaces de noms plats |
| Compatibilité Hadoop | Les services Hadoop peuvent utiliser des données stockées dans Azure Data Lake | En utilisant le pilote de système de fichiers Blob Azure, les applications et les frameworks peuvent accéder aux données du Stockage Blob Azure |
| Sécurité | Prend en charge l’accès granulaire | Accès granulaire non pris en charge |