Comprendre le traitement par lots et par flux
Le traitement des données est juste la conversion de données brutes en informations significatives via un processus. Il existe deux méthodes générales pour traiter les données :
- Traitement par lots, dans lequel plusieurs enregistrements de données sont collectés et stockés avant d’être traités ensemble, en une seule opération.
- Traitement par flux, dans lequel une source de données est constamment analysée et traitée en temps réel à mesure que de nouveaux événements de données se produisent.
Comprendre le traitement par lots
Dans le traitement par lots, les éléments de données qui viennent d’arriver sont collectés et stockés et le groupe entier est traité en tant que lot. Le moment exact où chaque groupe est traité peut être déterminé de plusieurs façons. Par exemple, vous pouvez traiter les données sur la base d’un intervalle de temps planifié (par exemple, toutes les heures), quand une certaine quantité de données est arrivée ou à la suite d’un autre événement.
Supposons, par exemple, que vous souhaitiez analyser le trafic routier en comptant le nombre de voitures sur un tronçon de route. Le traitement par lots implique que vous réunissiez les voitures dans un parking, puis que vous les comptiez en une seule fois pendant qu’elles sont à l’arrêt.
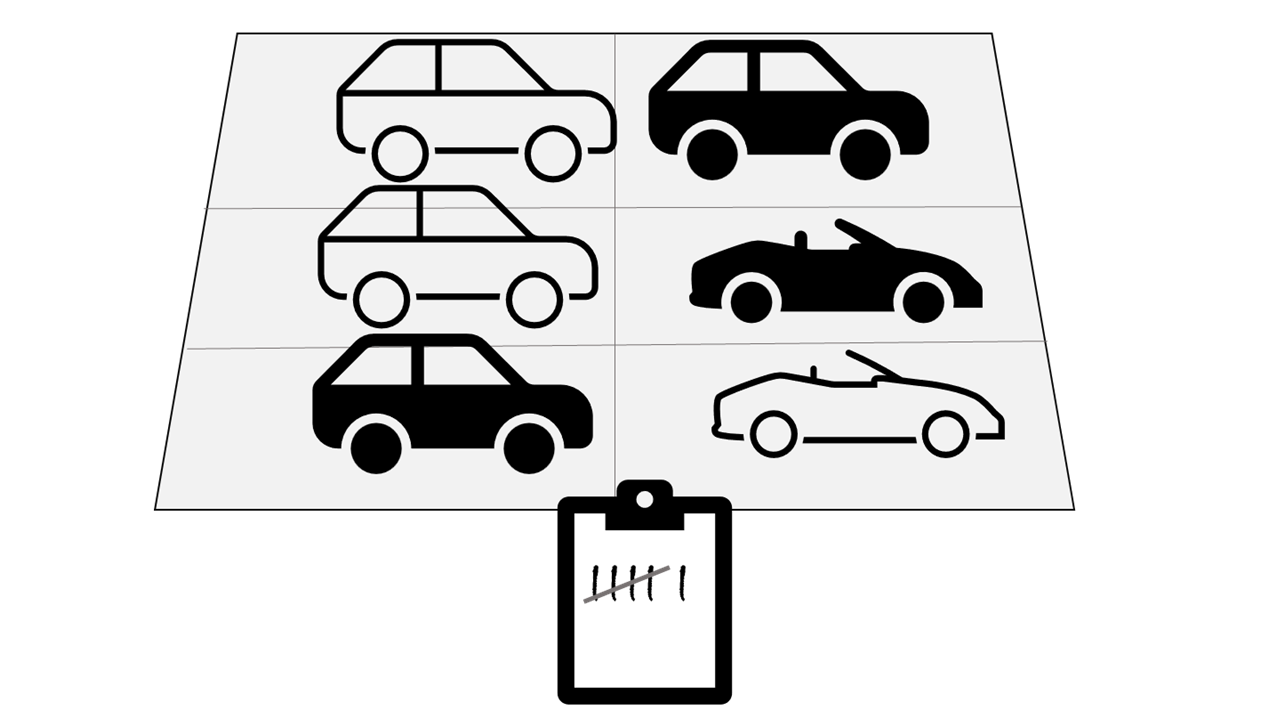
Si la route est occupée, avec un grand nombre de voitures circulant à intervalle régulier, cette approche peut s’avérer irréalisable. En effet, vous n’obtenez aucun résultat tant que vous n’avez pas fait garer un lot de voitures et que vous ne l’avez pas compté.
Un exemple de traitement par lots est la façon dont les sociétés de carte de crédit gèrent la facturation. Le client ne reçoit pas de facture pour chaque achat par carte de crédit, mais une seule facture mensuelle pour tous les achats du mois.
Les avantages du traitement par lots sont les suivants :
- Les gros volumes de données peuvent être traités à un moment qui convient.
- Le traitement peut être planifié à un moment où les ordinateurs ou les systèmes seront probablement inactifs, comme pendant la nuit ou les heures creuses.
Les inconvénients du traitement par lots sont les suivants :
- Le délai entre l’ingestion des données et l’obtention des résultats.
- Toutes les données d’entrée d’un traitement par lots doivent être prêtes avant de pouvoir traiter un lot. Cela signifie que les données doivent être vérifiées avec soin. Les problèmes de données, les erreurs et les plantages de programme qui se produisent pendant les traitements par lots entraînent l’arrêt de l’ensemble du processus. Les données d’entrée doivent être soigneusement vérifiées avant que le traitement puisse être réexécuté. Même de petites erreurs de données peuvent empêcher l’exécution d’un programme de traitement par lots.
Comprendre le traitement des flux
Dans le traitement en streaming, chaque nouvel élément de données est traité à son arrivée. Contrairement au traitement par lots, il ne faut pas attendre jusqu’au prochain intervalle. Les données sont traitées comme des éléments individuels en traitement au lieu d’être traitées comme un lot à un moment M. Le traitement des données en flux est bénéfique dans la plupart des scénarios où de nouvelles données dynamiques sont générées en continu.
Par exemple, pour compter les voitures, nous pourrions appliquer une approche de flux, en comptant les voitures en temps réel à mesure qu’elles passent :
Dans cette approche, vous n’avez pas besoin d’attendre que toutes les voitures aient été immobilisées pour commencer à les compter. Vous pouvez regrouper les données sur des intervalles de temps, par exemple, en comptant le nombre de voitures qui passent chaque minute.
Voici des exemples de données de diffusion en continu :
- Une institution financière suit l’évolution de la bourse en temps réel, calcule la valeur à risque et rééquilibre automatiquement les portefeuilles en fonction des mouvements du prix des actions.
- Une société de jeux en ligne collecte les données en temps réel des interactions des joueurs avec les jeux et alimente les données dans sa plateforme de jeux. Elle analyse ensuite les données en temps réel, offre des incentives et des expériences dynamiques pour faire rester ses joueurs.
- Un site web immobilier suit un sous-ensemble des données des appareils mobiles et envoie des recommandations en temps réel de biens à visiter en fonction de leur géolocalisation.
Le traitement en streaming est idéal pour les opérations urgentes qui nécessitent une réponse en temps réel immédiate. Par exemple, un système qui surveille la présence de fumée et de chaleur dans un bâtiment doit déclencher des alarmes et déverrouiller les portes pour permettre aux résidents de sortir immédiatement en cas d’incendie.
Comprendre les différences entre les données en lot et en streaming
En plus de la façon dont le traitement par lots et le traitement en streaming gèrent les données, il existe d’autres différences :
Étendue des données : le traitement par lots peut traiter toutes les données du jeu de données. En règle générale, le traitement en streaming a uniquement accès aux données reçues en dernier ou pendant une fenêtre de temps mobile (par exemple, les 30 dernières secondes).
Taille des données : le traitement par lots convient pour gérer efficacement de gros jeux de données. Le traitement en streaming est destiné à des enregistrements individuels ou à des micro-lots composés de quelques enregistrements.
Performance : la latence est le temps nécessaire pour recevoir et traiter les données. La latence du traitement par lots est généralement de quelques heures. Le traitement en streaming se produit généralement tout de suite, avec une latence de l’ordre de quelques secondes ou millisecondes.
Analyse : en général, vous utilisez le traitement par lots pour une analyse complète. Le traitement en streaming est utilisé pour les fonctions de réponse, les agrégats ou les calculs simples comme les moyennes mobiles.
Combiner le traitement des lots et des flux
De nombreuses solutions d’analyse à grande échelle combinent le traitement par lots et par flux, ce qui permet d’analyser les données historiques et les données en temps réel. Il est courant pour les solutions de traitement par flux de capturer des données en temps réel, de les traiter en les filtrant ou en les agrégeant et de les présenter via des tableaux de bord et des visualisations en temps réel (par exemple, en indiquant le total cumulé des voitures qui sont passées sur une route en une heure). Et ce, en conservant les résultats traités dans un magasin de données pour l’analyse historique avec les données en lots (par exemple, pour activer l’analyse des volumes de trafic au cours de l’année précédente).
Même si l’analyse en temps réel ou la visualisation des données n’est pas nécessaire, les technologies de diffusion en continu sont souvent utilisées pour capturer les données en temps réel et les stocker dans un magasin de données pour un traitement par lots ultérieur (c’est l’équivalent de rediriger toutes les voitures qui voyagent sur une route dans un parking avant de les compter).
Le diagramme suivant montre quelques méthodes permettant de combiner le traitement par lots et par flux dans une architecture d’analyse de données à grande échelle.
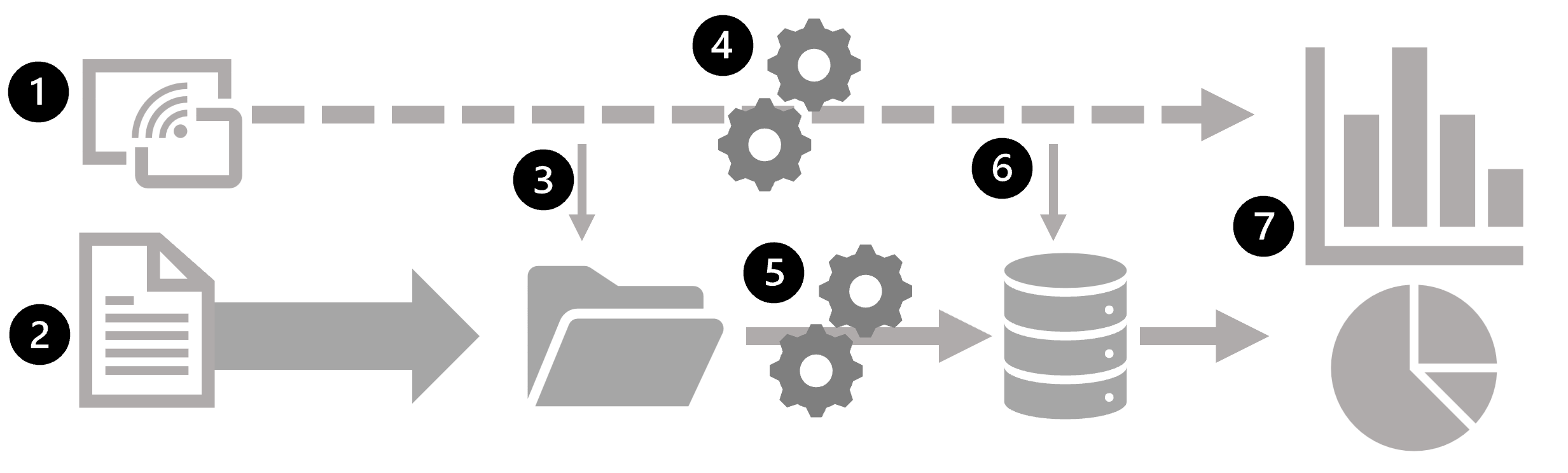
- Les événements de données provenant d’une source de données de diffusion en continu sont capturés en temps réel.
- Les données provenant d’autres sources sont ingérées dans un magasin de données (souvent un lac de données) pour le traitement par lots.
- Si l’analyse en temps réel n’est pas requise, les données de diffusion en continu capturées sont écrites dans le magasin de données pour un traitement par lots ultérieur.
- Lorsque l’analyse en temps réel est requise, une technologie de traitement par flux est utilisée afin de préparer les données de diffusion en continu pour l’analyse ou la visualisation en temps réel. Cela se fait souvent en filtrant ou en agrégeant les données sur des plages temporelles.
- Les données qui ne sont pas diffusées en continu sont régulièrement traitées par lots afin d’être préparées pour l’analyse, et les résultats sont conservés dans un magasin de données analytiques (souvent appelé entrepôt de données) pour l’analyse historique.
- Les résultats du traitement par flux peuvent également devenir persistants dans le magasin de données analytiques pour prendre en charge l’analyse historique.
- Les outils d’analyse et de visualisation sont utilisés pour présenter et explorer les données historiques et en temps réel.
Notes
Les architectures de solution couramment utilisées pour le traitement combiné des données par lots et par flux incluent des architectures lambda et delta. Les détails de ces architectures n’entrent pas dans le cadre de ce cours, mais ils intègrent des technologies pour le traitement des données par lots à grande échelle et le traitement par flux en temps réel afin de créer une solution d’analyse de bout en bout.