Décrire la normalisation
La normalisation d’une base de données est un processus de conception utilisé pour organiser un ensemble déterminé de données en tables et en colonnes dans une base de données. Chaque table doit contenir des données relatives à un « élément » spécifique et ne comporter que des données prenant en charge ce même « élément » inclus dans la table. La finalité de ce processus est de réduire les données en double contenues dans votre base de données, afin de réduire la détérioration des performances des insertions et des mises à jour de base de données. Par exemple, le changement d’adresse d’un client est beaucoup plus facile à implémenter si l’adresse du client n’est stockée que dans la table Clients. Les formes les plus courantes de normalisation sont la première, deuxième et troisième forme normale, qui sont décrites ci-dessous.
Première forme normale
La première forme normale présente les spécifications suivantes :
- Créer une table distincte pour chaque ensemble de données associées
- Éliminer les groupes répétitifs dans les tables individuelles
- Identifier chaque ensemble de données associées avec une clé primaire
Dans ce modèle, vous ne devez pas utiliser plusieurs colonnes dans une table unique pour stocker des données similaires. Par exemple, si le produit peut être de différentes couleurs, vous ne devez pas utiliser plusieurs colonnes sur une seule ligne contenant les différentes valeurs de couleur. La première table, ci-dessous (ProduitsCouleurs), n’est pas dans la première forme normale, car des valeurs sont répétées pour la couleur. Pour les produits d’une seule couleur, c’est un gaspillage d’espace. Et que se passerait-il si un produit était proposé en plus de trois couleurs ? Plutôt que de devoir définir un nombre maximal de couleurs, nous pouvons recréer la table, comme illustré dans la deuxième table, ProduitCouleur. Nous devons également répondre à une exigence pour la première forme normale, celle de l’existence d’une clé unique pour la table, qui est une colonne (ou des colonnes) dont la valeur identifie de façon unique la ligne. Aucune des colonnes de la seconde table n’est unique, mais ensemble, la combinaison de IDProduit et de Couleur est unique. Lorsque plusieurs colonnes sont nécessaires, nous sommes alors en présence d’une clé composite.
| IDProduit | Couleur1 | Couleur2 | Couleur3 |
|---|---|---|---|
| 1 | Rouge | Vert | Yellow |
| 2 | Yellow | ||
| 3 | Bleu | Rouge | |
| 4 | Blue | ||
| 5 | Rouge |
| IDProduit | Couleur |
|---|---|
| 1 | Rouge |
| 1 | Vert |
| 1 | Yellow |
| 2 | Yellow |
| 3 | Blue |
| 3 | Rouge |
| 4 | Blue |
| 5 | Rouge |
La troisième table, ProduitInfo, est dans la première forme normale, car chaque ligne fait référence à un produit particulier ; il n’y a pas de groupe répétitif et la colonne IDProduit peut être utilisée comme clé primaire.
| IDProduit | ProductName | Price | PaysProduction | AbrévPays |
|---|---|---|---|---|
| 1 | Widget | 15,95 | États-Unis | US |
| 2 | Foop | 41,95 | Royaume-Uni | Royaume-Uni |
| 3 | Glombit | 49,95 | Royaume-Uni | Royaume-Uni |
| 4 | Sorfin | 99,99 | République des Philippines | RepPhil |
| 5 | Stem Bolt | 29,95 | États-Unis | US |
Deuxième forme normale
La deuxième forme normale présente la spécification suivante, en plus de celles qui sont demandées par la première forme normale :
- Si la table est dotée d’une clé composite, tous les attributs doivent dépendre de la clé complète, et pas seulement d’une partie de celle-ci.
La deuxième forme normale concerne uniquement les tables dotées de clés composites, comme dans la deuxième table ci-dessus, la table ProduitCouleur. Prenons le cas où la table ProduitCouleur inclut également le prix du produit. Cette table présente une clé composite sur IDProduit et Couleur, car il n’est possible d’identifier une ligne de manière unique qu’au moyen des valeurs des deux colonnes. Si le prix d’un produit ne change pas avec la couleur, les données peuvent s’afficher, comme illustré dans la table suivante :
| IDProduit | Couleur | Price |
|---|---|---|
| 1 | Rouge | 15,95 |
| 1 | Vert | 15,95 |
| 1 | Yellow | 15,95 |
| 2 | Yellow | 41,95 |
| 3 | Blue | 49,95 |
| 3 | Rouge | 49,95 |
| 4 | Blue | 99,95 |
| 5 | Rouge | 29,95 |
La table ci-dessus n’est pas dans la deuxième forme normale. La valeur du prix dépend de IDProduit, mais pas de la Couleur. Il y a trois lignes pour IDProduit 1, le prix de ce produit est donc répété trois fois. Le problème de la violation de la deuxième forme normale apparaît si nous devons mettre à jour le prix, car nous devons veiller à l’actualiser partout. Si nous mettions à jour le prix sur la première ligne, mais pas sur la deuxième ni la troisième ligne, nous expérimenterions un événement appelé « anomalie de mise à jour ». Après la mise à jour, nous ne pourrions plus indiquer le prix réel pour IDProduit 1. La solution consiste à déplacer la colonne Prix dans une table qui contient IDProduit comme clé de colonne unique, car c’est la seule colonne dont le prix dépend. Par exemple, nous pourrions utiliser la Table 3 pour stocker le prix.
Si le prix d’un produit variait en fonction de sa couleur, la quatrième table serait dans la deuxième forme normale, car le prix dépendrait des deux parties de la clé : l’IDProduit et la Couleur.
Troisième forme normale
La troisième forme normale reflète généralement l’objectif de la majeure partie des bases de données OLTP. La troisième forme normale présente la spécification suivante, en plus de celles demandées par la deuxième forme normale :
- Toutes les colonnes non-clés sont dépendantes de façon non transitive de la clé primaire.
La relation transitive implique qu’une colonne d’une table soit liée à d’autres colonnes, par le biais d’une deuxième colonne. La dépendance signifie qu’une colonne peut dériver sa valeur d’une autre, comme résultat d’une dépendance. Par exemple, votre âge peut être déterminé à partir de votre date de naissance, ce qui rend votre âge dépendant de votre date de naissance. Reportez-vous à la troisième table, ProduitInfo. Cette table adopte la deuxième forme normale, mais pas la troisième. La colonne AbrévPays dépend de la colonne PaysProduction, qui n’est pas la clé. À l’instar de la deuxième forme normale, la violation de la troisième forme normale peut entraîner des anomalies de mise à jour. Nous finirions par obtenir des données incohérentes si nous mettions à jour une ligne de la colonne AbrévPays, mais sans la mettre à jour dans toutes les lignes où cette indication géographique s’est produite. Pour éviter cela, nous pourrions créer une table distincte et stocker les noms des pays/régions avec leur forme abrégée.
Dénormalisation
Bien que la troisième forme normale soit théoriquement souhaitable, elle n’est pas toujours possible pour toutes les données. De plus, une base de données normalisée n’offre pas toujours les meilleures performances. Les données normalisées nécessitent souvent plusieurs opérations de jointure pour que toutes les données nécessaires soient retournées dans une seule requête. Il existe un compromis à trouver entre la normalisation des données lorsque le nombre de jointures nécessaires pour retourner les résultats d’une requête demande une utilisation élevée du processeur, et les données dénormalisées qui exigent moins de jointures et moins de ressource processeur, mais qui ouvrent la possibilité d’anomalies de mise à jour.
Notes
Les données dénormalisées sont différentes des données non normalisées. Pour la dénormalisation, nous commençons par concevoir des tables qui sont normalisées. Nous pouvons ensuite ajouter des colonnes supplémentaires à certaines tables pour réduire le nombre de jointures nécessaires, mais ce faisant, nous sommes conscients de l’existence possible d’anomalies de mise à jour. Nous veillons donc à disposer de déclencheurs ou d’autres types de traitement qui garantiront également la mise à jour de toutes les données dupliquées lorsque nous procéderons à une mise à jour.
Les données dénormalisées peuvent être plus efficaces à interroger, en particulier pour les lourdes charges de travail en lecture, telles qu’un entrepôt de données. Dans ce cas, le fait d’avoir des colonnes supplémentaires peut offrir de meilleurs modèles de requête et/ou des requêtes simplifiées.
Schéma en étoile
Tandis que la normalisation, en grande partie, est destinée aux charges de travail OLTP, les entrepôts de données, eux, possèdent leur propre structure de modélisation, qui est généralement un modèle dénormalisé. Cette conception utilise des tables de faits, qui enregistrent des mesures ou des métriques d’événements particuliers, tels qu’une vente, et les joignent aux tables de dimension, plus petites si l’on considère le nombre de lignes, mais qui peuvent offrir un grand nombre de colonnes pour décrire les données de faits. Parmi les exemples de dimensions, citons inventaire, heure et/ou géographie. Ce modèle de conception est utilisé pour faciliter l’interrogation de la base de données et offrir des gains de performances pour les charges de travail en lecture.
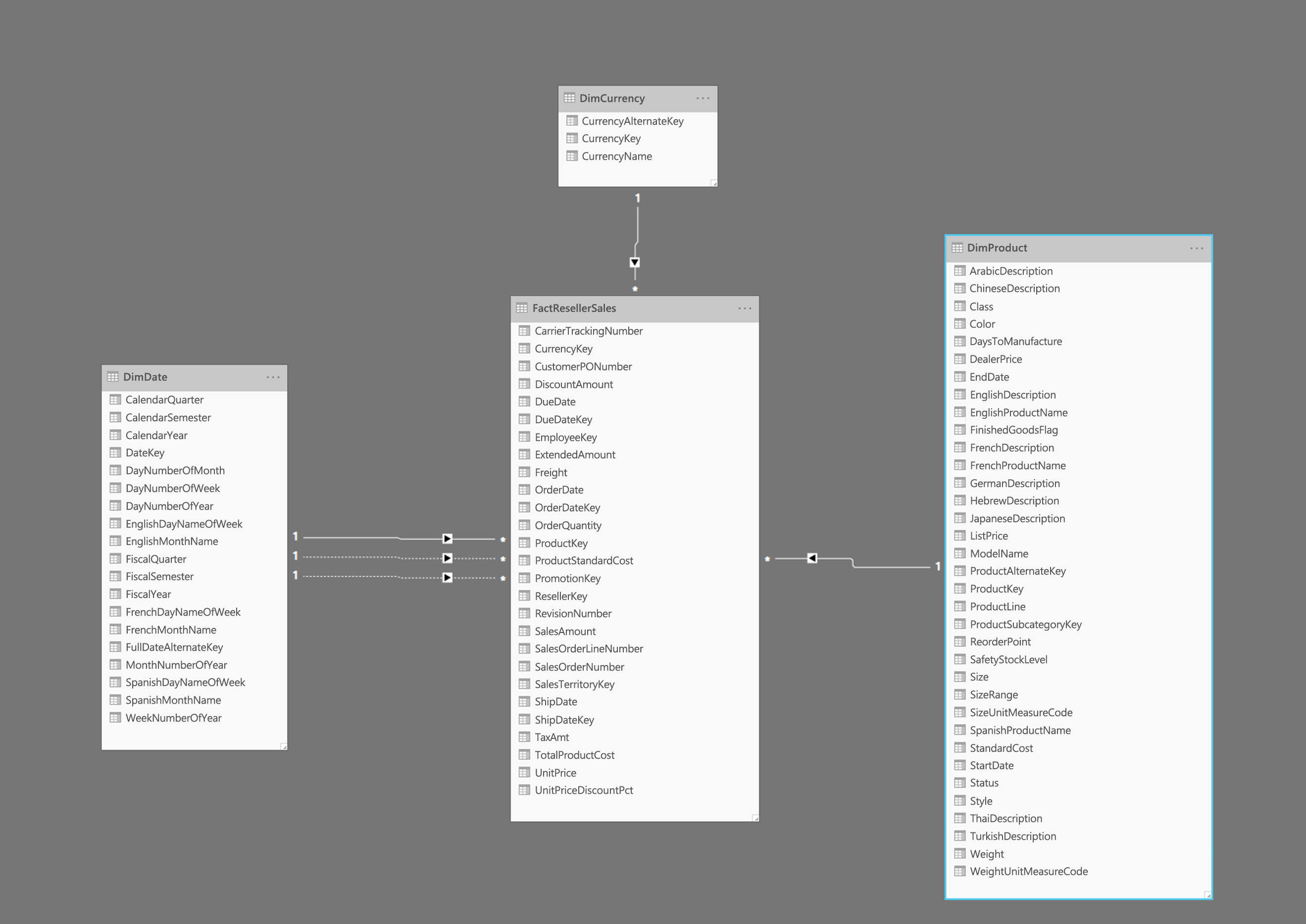
L’image ci-dessus montre un exemple de schéma en étoile, notamment une table de faits FactResellerSales et des dimensions pour la date, la devise et les produits. La table de faits contient des données relatives aux transactions de vente, et les dimensions ne comprennent que les données relatives à un élément spécifique des données de vente. Par exemple, la table FactResellerSales ne contient qu’une colonne ProductKey pour indiquer quel produit a été vendu. Tous les détails se rapportant à chacun des produits sont stockés dans la table DimProduct et sont associés de nouveau à la table de faits avec la colonne ProductKey.
Lié à la conception de schéma en étoile se trouve le schéma en flocon, qui utilise un ensemble de tables plus normalisées pour une entité commerciale propre. L’illustration suivante montre l’exemple d’une dimension unique pour un schéma en flocon. La dimension Produits est normalisée et stockée dans trois tables appelées DimProductCategory, DimProductSubcategory et DimProduct.
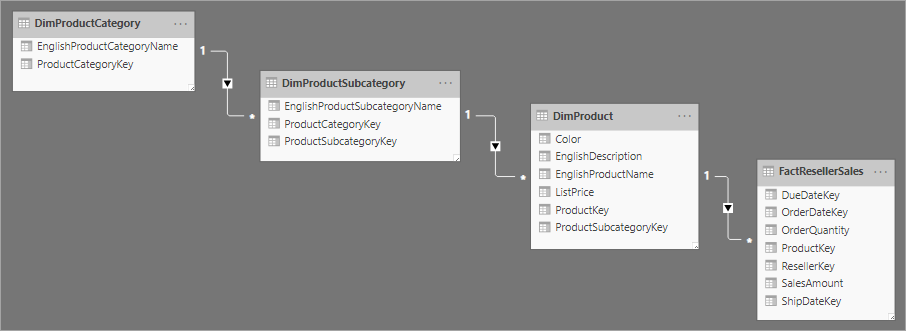
La principale différence entre un schéma en étoile et un schéma en flocon réside dans les dimensions du schéma en flocon qui sont normalisées pour réduire la redondance, ce qui permet d’économiser de l’espace de stockage. En revanche, vos requêtes nécessitent davantage de jointures, ce qui peut augmenter votre complexité et amoindrir les performances.