Modèle de capacité de l’ingénierie de plateforme
L’ingénierie de plateforme est conçue pour être un parcours. Il est généralement plus efficace de suivre une approche progressive et itérative que de tenter une implémentation immédiate à grande échelle ou de s’appuyer uniquement sur des mandats descendants. La progression incrémentielle, à commencer par les produits minimaux viables (MVP, Minimally Viable Products), permet aux équipes d’affiner leur approche au fil du temps tout en incorporant les commentaires reçus en cours de route.
Le cycle de vie de l’ingénierie de plateforme représente une approche structurée dont le but est de garantir une plateforme fiable, évolutive et en constante amélioration. Ce cycle de vie englobe des phases distinctes, chacune contribuant au succès à long terme de la plateforme.
Un élément essentiel du cycle de vie est le modèle de capacité de l’ingénierie de plateforme, qui fournit un cadre complet pour l’évaluation, la planification et l’implémentation des efforts de l’ingénierie de plateforme. Le modèle décrit les niveaux de maturité, les meilleures pratiques et les capacités critiques requises à chaque phase du cycle de vie afin d’assurer l’alignement avec les objectifs de l’organisation et les besoins des utilisateurs.
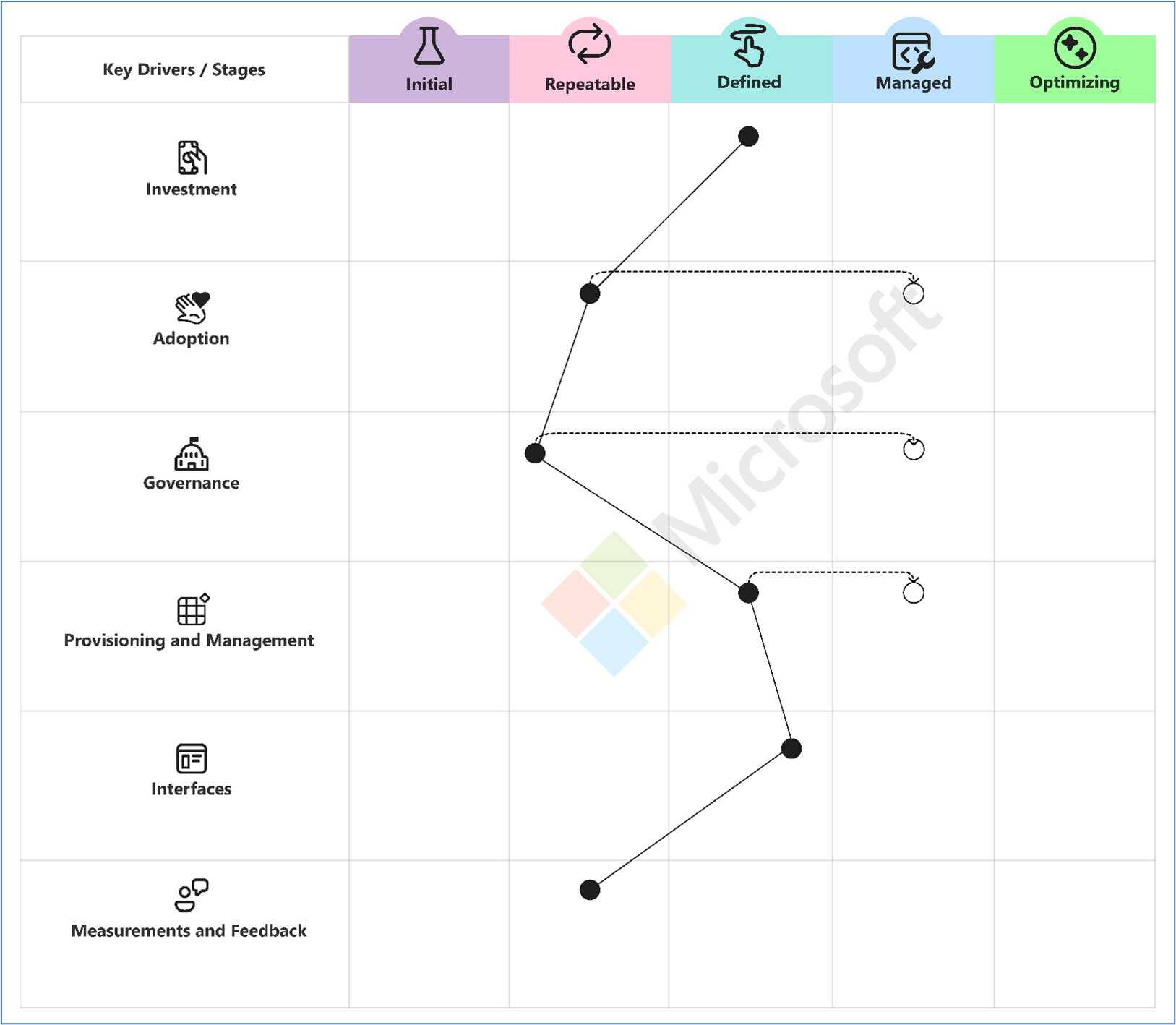
Le modèle décrit la progression des pratiques d’ingénierie de plateforme en cinq phases de maturité : Démarrage, Répétabilité, Définition, Gestion et Optimisation. Dans la phase Démarrage, les organisations ont une structure limitée, avec des processus ad hoc et des investissements minimes dans les capacités de la plateforme. À mesure qu’elles se rapprochent de la phase Répétabilité, des processus de base émergent, mais l’adoption et la gouvernance restent incohérentes. La phase Définition marque l’établissement de normes et de processus clairs, les utilisateurs commençant à adopter de manière intentionnelle des solutions de plateforme. Au cours de la phase Gestion, les plateformes sont activement gouvernées, les ressources sont approvisionnées et gérées efficacement, et les interactions des utilisateurs sont cohérentes grâce à des interfaces normalisées. Enfin, au cours de la phase Optimisation, les plateformes font l’objet d’améliorations continues via des mécanismes de commentaires robustes, des résultats mesurés et des capacités adaptatives en adéquation avec les besoins des utilisateurs et les objectifs de l’organisation.
Le modèle est évalué en fonction de six capacités : Investissement, qui reflète l’allocation des ressources et des financements ; Adoption, qui se concentre sur la découverte et l’utilisation des utilisateurs ; Gouvernance, qui assure l’accessibilité des ressources, le contrôle des coûts et la protection des données/IP ; Approvisionnement et gestion, qui définit la façon dont les ressources sont déployées et maintenues ; Interfaces, qui traite les interactions des utilisateurs avec la plateforme ; et Mesure et commentaires, qui met l’accent sur l’amélioration continue grâce à des métriques de performance et à des insights sur les utilisateurs. Ensemble, ces capacités s’alignent étroitement sur les domaines clés décrits dans le modèle de maturité de l’ingénierie de plateforme de la Cloud Native Computing Foundation et reflètent le niveau de maturité de l’ingénierie de plateforme de l’organisation.
Pour utiliser le modèle de capacité de l’ingénierie de plateforme, évaluez d’abord la position actuelle de votre organisation dans chacun des six domaines de capacité. Vous pouvez effectuer cette évaluation manuellement ou répondre à l’enquête sur le modèle de capacité de l’ingénierie de plateforme. Après avoir identifié vos phases actuelles, définissez des objectifs de croissance futurs et représentez sous forme graphique la progression de votre organisation dans chaque capacité. La progression ne doit pas nécessairement se produire dans toutes les capacités en même temps. Concentrez-vous sur les domaines qui présentent le plus d’intérêt pour votre organisation.
Investissement
À mesure que la capacité Investissement évolue, elle se concentre davantage sur la façon dont le personnel et les fonds sont alloués aux capacités de la plateforme, l’accent étant mis sur le budget et les effectifs, la gestion de l’étendue et la mesure du retour sur investissement (RSI).
- Démarrage (volontariat) : les capacités de la plateforme émergent par nécessité, pilotées par des ingénieurs individuels qui répondent volontairement aux besoins tactiques immédiats. Le budget et les effectifs sont minimes, le travail n’étant généralement pas financé et étant effectué parallèlement aux responsabilités existantes. Les solutions sont étroitement délimitées et ciblent des problèmes spécifiques avec un partage limité des connaissances entre les équipes. Le RSI est mesuré en déterminant l’efficacité avec laquelle les besoins immédiats sont satisfaits et leur impact sur les principaux résultats du projet.
- Répétabilité (contributions ad hoc) : des équipes dédiées commencent à relever les défis récurrents, tels qu’un approvisionnement incohérent ou des failles de sécurité, mais les efforts restent largement réactifs. Les budgets et les effectifs sont limités aux problèmes transversaux, avec une autonomie limitée dans l’ensemble de l’organisation. La gestion de l’étendue se concentre sur des problèmes spécifiques, sans perspective plus large à l’échelle de la plateforme. Le RSI est mesuré en examinant les améliorations apportées à la résolution de défis clés, notamment la réduction du backlog.
- Définition (opérationnalisation avec une équipe dédiée) : des équipes de plateforme financées de manière centralisée émergent, se concentrant sur l’accélération de la livraison de logiciels et la prise en compte des exigences techniques. La direction commence à encourager la collaboration et à implémenter des pratiques DevOps initiales, mais des défis subsistent pour mesurer la valeur ajoutée des équipes. Le budget et les effectifs sont formalisés pour permettre aux équipes centrales de répondre aux besoins techniques. Les solutions deviennent plus étendues et répondent aux défis courants des équipes, mais l’accent est toujours sur le court terme. Le RSI est mesuré en examinant les gains en termes de vitesse de livraison.
- Gestion (scalabilité, en tant que produit) : un changement culturel se produit, les développeurs étant traités comme des clients et la direction mettant l’accent sur l’empathie et une approche axée sur le produit. Les équipes de plateforme fonctionnent comme des équipes produit, avec des développeurs, des responsables produit et des experts en expérience utilisateur. La gestion de l’étendue, alignée sur les feuilles de route des produits, est examinée en collaboration avec les équipes d’ingénierie pour répondre aux besoins à l’échelle de l’organisation. Le RSI est évalué en examinant l’augmentation de la satisfaction des développeurs, celle-ci reflétant les améliorations apportées en continu et l’alignement sur les besoins des utilisateurs.
- Optimisation (écosystème activé) : l’investissement se concentre sur l’innovation, en maintenant la pertinence de la plateforme avec des contributions encouragées dans l’ensemble de l’organisation. Les équipes de plateforme introduisent des capacités avancées, notamment des améliorations au niveau de la sécurité et des performances, permettant ainsi aux équipes produit de créer sans avoir à dépendre d’un backlog centralisé. Les budgets s’étendent au-delà des équipes centrales, avec des fonds disponibles dans toute l’organisation. La gestion de l’étendue met l’accent sur le partage rapide des connaissances à l’échelle de l’organisation. Le RSI est mesuré sur la base d’améliorations durables apportées à la satisfaction des développeurs.
Adoption
La capacité Adoption se concentre sur la façon dont les utilisateurs découvrent et utilisent vos solutions d’ingénierie de plateforme et leurs offres, ce qui se traduit par la découverte, la sélection et l’utilisation de services, d’outils et de technologies. À mesure que les organisations gagnent en maturité, l’approche en matière d’adoption passe d’une utilisation informelle et sporadique à un modèle plus structuré et participatif dans lequel les utilisateurs s’engagent activement à utiliser la plateforme et contribuent à son évolution. Cette progression reflète la façon dont les pratiques de découverte, de prise de décision et d’utilisation des utilisateurs évoluent au fil du temps, de la découverte informelle initiale à la pleine participation au développement de la plateforme.
- Démarrage (absence de formalité) : l’adoption est incohérente, les équipes améliorant indépendamment les processus sans aucune coordination à l’échelle de l’organisation. Les outils externes sont souvent préférés aux outils internes. Les plateformes sont découvertes de manière informelle, principalement par le bouche-à-oreille ou des rencontres fortuites, les équipes d’ingénierie sélectionnant les services en fonction de leurs besoins spécifiques. Chaque équipe gère ses propres scripts et outils qui sont adaptés à ses exigences uniques.
- Répétabilité (obligation) : l’organisation impose l’utilisation de plateformes partagées, mais les capacités sont limitées aux cas d’utilisation courants, ce qui rend la prise en charge d’exigences inhabituelles difficile. La découverte des utilisateurs repose sur les conseils fournis par l’équipe de la plateforme, souvent par le biais de la documentation ou de directives internes. Les équipes peuvent sélectionner des services mandatés par le biais de discussions informelles avec l’équipe de la plateforme. Bien que des processus soient créés autour des normes de la plateforme, les équipes peuvent ne pas les adopter pleinement ou ne pas être satisfaites des résultats.
- Définition (promotion) : les capacités de la plateforme, qui s’alignent sur les besoins des équipes, sont activement promues. L’équipe de la plateforme collabore avec les équipes d’ingénierie pour offrir des services de haute qualité qui réduisent les frais opérationnels. Cependant, certaines équipes peuvent encore présenter un faible RSI en raison de leur dette technique et de leur dépendance à des pratiques obsolètes. Les équipes découvrent les capacités par le biais de directives couvrant les cas d’utilisation classiques, et l’équipe de la plateforme encourage l’utilisation par le biais de la collaboration. Des ambassadeurs d’équipe assurent également la promotion de la plateforme de manière informelle.
- Gestion (pilotage par la valeur) : les équipes produit reconnaissent et choisissent les capacités de la plateforme qui permettent clairement de réduire la charge cognitive et d’offrir des services de haute qualité. Les plateformes sont prises en charge par une documentation complète, des interfaces ergonomiques et une expérience utilisateur en libre-service pour un approvisionnement rapide. Les équipes préfèrent désormais recourir aux plateformes internes plutôt que de créer elles-mêmes des solutions ou de s’en remettre à des fournisseurs externes. La découverte et la prise de décision sont simplifiées, les équipes utilisant des modèles, des forums et la documentation fournie pour prendre pleinement en charge l’adoption de la plateforme.
- Optimisation (participation) : les équipes produit contribuent activement à améliorer les capacités de la plateforme en suggérant de nouvelles fonctionnalités et des correctifs. Des processus sont en place pour permettre aux utilisateurs d’identifier les exigences et de collaborer aux contributions. Les défenseurs et ambassadeurs des développeurs favorisent une communauté interne, étendant ainsi la propriété de la plateforme aux contributeurs. Les ingénieurs de la plateforme travaillent en étroite collaboration avec les équipes produit pour comprendre les besoins et suggérer de nouvelles capacités, ce qui permet aux utilisateurs de soumettre des demandes de tirage (pull requests) et de participer aux révisions.
Gouvernance
À mesure que la fonctionnalité Gouvernance évolue, son objectif est de s’assurer que les utilisateurs ont accès aux ressources et aux capacités dont ils ont besoin, tout en gérant les coûts, les données et la propriété intellectuelle. Cette progression est évaluée en fonction de plusieurs catégories, notamment la définition de stratégies et de cadres, l’implémentation de stratégies, la surveillance et l’atténuation de la conformité ainsi que la gestion des accès. La gouvernance passe de processus manuels et réactifs à un système prédictif intégré qui équilibre le contrôle centralisé et la gestion adaptative en fonction de l’évolution des besoins.
- Démarrage (indépendance) : la gouvernance est manuelle et repose sur un contrôle et un filtrage centralisés, ce qui entrave la scalabilité. Les développeurs et les équipes de sécurité travaillent indépendamment, et répondent de manière réactive aux violations de stratégie. La conformité est maintenue à l’aide de normes minimales, des mesures de sécurité étant souvent ajoutées après coup. Les autorisations d’accès sont accordées en fonction des besoins immédiats, aucun processus normalisé n’étant défini.
- Répétabilité (documentation) : l’organisation commence à documenter et à partager des stratégies, mais celles-ci restent élémentaires et sont appliquées de manière incohérente. Des outils de gouvernance tels que des systèmes de gestion de tickets sont introduits pour gérer les révisions de stratégie, mais le processus reste manuel et lent. Des processus d’audit sont établis, mais ils restent réactifs. Certains rôles et autorisations sont normalisés, mais leur application reste inégale.
- Définition (normalisation) : la gouvernance devient centralisée et normalisée pour améliorer la cohérence et l’efficacité au sein de toutes les équipes. Les stratégies sont documentées et gérées de manière centralisée, avec un certain degré d’automatisation dans le processus d’implémentation. Les normes de gouvernance clés sont respectées grâce à des audits réguliers, et le contrôle d’accès est automatisé avec un système RBAC formel. Toutefois, les équipes de développement ont toujours un contrôle limité sur les changements de stratégie.
- Gestion (intégration) : la sécurité et la conformité sont intégrées en toute transparence aux flux de travail, l’automatisation garantissant que les stratégies sont appliquées de manière cohérente aux systèmes et aux équipes. La surveillance en temps réel et les analyses avancées permettent de détecter les lacunes dans la gouvernance et de les éviter. Les stratégies sont incorporées aux pipelines CI/CD et la gestion des accès est régie par les principes des privilèges minimum avec des révisions automatisées, ce qui garantit une approche plus proactive et mieux intégrée de la gouvernance.
- Optimisation (prévisibilité) : la gouvernance, qui devient dynamique et sensible au contexte, répond aux conditions changeantes et optimise le contrôle d’accès. L’analyse prédictive permet d’identifier les risques avant qu’ils ne se produisent, ce qui permet une atténuation proactive. Les stratégies sont affinées en continu à l’aide d’analyses avancées, et le contrôle d’accès s’ajuste dynamiquement en fonction de facteurs en temps réel comme l’emplacement de l’utilisateur et le temps d’accès, garantissant ainsi la conformité tout en autorisant des flux de travail personnalisés.
Approvisionnement et gestion
La capacité Approvisionnement et gestion met l’accent sur la façon dont les utilisateurs créent, déploient et gèrent des ressources. Le processus passe d’opérations manuelles et cloisonnées à un système adaptatif et automatisé qui équilibre flexibilité et gouvernance, garantissant ainsi que les ressources sont approvisionnées efficacement tout en répondant aux exigences de conformité. Cette progression à travers les phases catégorisées se caractérise par la définition de processus d’approvisionnement, la réponse aux demandes et la gestion de ces demandes ainsi que la surveillance de l’allocation des ressources.
- Démarrage (manuel) : les développeurs configurent manuellement l’infrastructure en fonction des conseils des équipes informatiques ou d’architecture, ce qui entraîne des incohérences et des retards. Sans processus normalisés, les demandes sont examinées manuellement, ce qui augmente le risque d’erreurs. Cette approche devient ingérable à mesure que la demande augmente, les opérations cloisonnées créant des inefficacités.
- Répétabilité (coordination) : l’organisation commence à centraliser les processus d’approvisionnement à l’aide de systèmes de gestion de tickets pour gérer les demandes d’infrastructure. Bien que des approbations manuelles soient toujours requises, certaines erreurs sont réduites, mais des goulots d’étranglement subsistent. Les équipes commencent à utiliser des outils standard pour surveiller les ressources, bien que la vue reste cloisonnée et propre au projet.
- Définition (routes pavées) : les processus d’approvisionnement sont formalisés dans l’organisation à l’aide de l’infrastructure en tant que code (IaC), ce qui permet de normaliser les modèles et les outils. Les demandes sont gérées par le biais de flux de travail structurés, bien que l’équipe de la plateforme puisse avoir du mal à traiter une demande croissante. Des tableaux de bord centralisés permettent de surveiller l’allocation des ressources, offrant ainsi de meilleurs insights sur le niveau de performance.
- Gestion (automatisation) : l’approvisionnement s’automatise et s’intègre aux pipelines CI/CD, ce qui permet de réduire les efforts manuels et de garantir des déploiements cohérents. Les contrôles de gouvernance et de conformité sont incorporés dans les flux de travail. Les capacités en libre-service automatisées permettent aux utilisateurs d’approvisionner des ressources dans le cadre de paramètres contrôlés. La mise à l’échelle est automatisée en fonction des modèles d’utilisation pour optimiser les performances.
- Optimisation (adaptation) : l’approvisionnement devient adaptatif en faisant appel à des systèmes intelligents pour anticiper les besoins en infrastructure en temps réel. Cette approche garantit une allocation efficace des ressources tout en assurant la gouvernance et la conformité. Les systèmes gèrent les demandes de manière proactive, en équilibrant flexibilité et gouvernance, tandis que le niveau de performance et la rentabilité sont optimisés par le biais d’analyses prédictives.
Interfaces
Dans la capacité Interfaces, la principale considération est la façon dont les utilisateurs interagissent avec les services et produits de la plateforme et les consomment. Ses avancées se caractérisent par l’établissement de normes, l’amélioration de l’autonomie des utilisateurs et l’intégration transparente des capacités de la plateforme à des flux de travail existants. L’approche passe de processus incohérents et manuels à un système intégré en libre-service qui améliore l’expérience utilisateur et l’efficacité opérationnelle.
- Démarrage (processus personnalisés) : les utilisateurs interagissent avec la plateforme via divers processus personnalisés incohérents qui répondent aux besoins immédiats, mais qui manquent de normalisation. Les ingénieurs configurent indépendamment des environnements en consultant leurs collègues ou en s’appuyant sur leurs pratiques personnelles, puis sélectionnent des outils et des processus pour diagnostiquer le comportement des applications sans aucune directive établie. Le partage des connaissances est informel et les services d’approvisionnement nécessitent souvent un support approfondi des fournisseurs en raison du manque de processus formalisés, limitant ainsi la scalabilité et l’efficacité.
- Répétabilité (normes locales) : les ingénieurs et les équipes commencent à définir de manière informelle des normes pour améliorer le partage des connaissances, bien que la cohérence reste un défi en raison de la dépendance à l’engagement individuel. Certaines équipes peuvent utiliser la documentation ou des conteneurs pour définir leurs processus d’installation, mais ces pratiques divergent au fil du temps et nécessitent des efforts de rapprochement. Le diagnostic du comportement des applications devient plus normalisé au sein des équipes, avec une certaine dépendance vis-à-vis des équipes DevOps ou informatiques pour accéder aux ressources déployées. Bien que des normes locales émergent, elles restent peu définies et incohérentes entre les équipes.
- Définition (outils standard) : les interfaces deviennent plus cohérentes, avec l’introduction d’outils normalisés et de pratiques documentées. Les équipes centrales gèrent les modèles et la documentation, avec ce que l’on appelle des « routes pavées » ou des « voies dorées » qui encadrent la façon dont les capacités doivent être approvisionnées et observées. Ces outils et processus répondent aux besoins organisationnels généraux, même si l’assistance d’experts est encore souvent nécessaire. Les équipes peuvent modifier les modèles, mais les modifications ne sont pas toujours intégrées de manière centralisée, ce qui peut entraîner des inefficacités dans le maintien de la cohérence. Le diagnostic du comportement des applications suit des pratiques normalisées pour accéder aux ressources déployées et les analyser, offrant ainsi plus de cohérence entre les équipes.
- Gestion (solutions en libre-service) : la plateforme offre une plus grande autonomie aux utilisateurs en leur fournissant des solutions en libre-service avec une assistance minimale du chargé de maintenance. Les utilisateurs ont accès à des interfaces cohérentes et simples d’utilisation qui leur permettent de découvrir et de modifier des modèles, créant ainsi un environnement centré sur l’utilisateur qui améliore la convivialité. Les outils de diagnostic du comportement des applications et d’observation des ressources sont mis à disposition à la demande via la plateforme. De cette façon, les utilisateurs disposent des ressources dont ils ont besoin sans une forte dépendance vis-à-vis des équipes externes. Le partage des connaissances est facilité par la découverte et la modification de modèles, ce qui augmente la valeur des capacités de la plateforme.
- Optimisation (services intégrés) : les capacités de la plateforme sont intégrées en toute transparence aux outils et processus déjà utilisés par les équipes, comme l’interface CLI ou les environnements IDE. La plateforme s’inscrit donc naturellement dans le cadre des flux de travail des utilisateurs. Certaines capacités sont automatiquement approvisionnées en fonction des besoins des utilisateurs, et la plateforme fournit des blocs de construction flexibles pour les cas d’utilisation de niveau supérieur qui peuvent nécessiter une personnalisation plus approfondie. Les équipes de la plateforme évaluent en permanence les capacités les plus efficaces, guidant les investissements futurs pour optimiser les offres de la plateforme. La plateforme configure automatiquement l’observabilité pour les applications déployées, offrant ainsi un accès en temps réel aux données de diagnostic et simplifiant le processus de surveillance et de gestion du comportement des applications.
Mesures et commentaires
La capacité Mesures et commentaires implique la collecte, l’analyse et l’incorporation de mesures et de commentaires pour évaluer le succès des pratiques d’ingénierie de plateforme. Sa maturité est reflétée par le passage de méthodes ad hoc et informelles à une culture proactive et pilotée par les données où les commentaires et les insights sont intégrés aux processus d’amélioration continue, guidant les décisions stratégiques et le développement de la plateforme.
- Démarrage (ad hoc) : au cours de la phase de démarrage, les processus de mesure et de commentaires sont incohérents et fragmentés. Les métriques sont collectées sans alignement clair sur les objectifs de l’organisation, donnant lieu à des données incomplètes et non fiables. Les commentaires sont collectés de manière informelle et souvent anecdotique, avec un engagement minimal des parties prenantes. Les décisions sont donc prises sur la base d’informations limitées, et il est difficile de mesurer le véritable RSI des pratiques d’ingénierie de plateforme. La documentation des commentaires et des résultats est minimale, et les apprentissages sont rarement capturés ou partagés.
- Répétabilité (processus structurés) : des mécanismes de commentaires de base, comme des enquêtes ou des forums, sont établis pour capturer plus systématiquement les expériences des utilisateurs, mais ces processus varient toujours d’une équipe à l’autre. La mesure du succès est souvent axée sur des métriques basées sur l’activité, comme les déploiements ou les chronologies, ce qui donne un aperçu du niveau de performance, mais ne permet pas d’avoir une perspective plus large basée sur les résultats. Les commentaires restent informels et bas en bas, bien qu’ils commencent à influencer la planification. Des efforts sont faits pour impliquer les parties prenantes, mais ils restent limités, et la documentation initiale des processus et des commentaires est créée, mais elle n’est ni exhaustive ni utilisée systématiquement.
- Définition (cohérence) : la collection des commentaires devient plus formalisée et standardisée, ce qui permet d’obtenir des insights plus approfondis sur les besoins des utilisateurs et des métriques clés. Les métriques passent à des mesures basées sur les résultats, comme la productivité des développeurs, mais leur liaison aux performances financières reste un défi. L’analyse des commentaires est systématique, à l’aide de méthodes qualitatives et quantitatives, et des métriques standard comme DORA (DevOps Research and Assessment est un ensemble de métriques mesurant le niveau de performance de la livraison de logiciels, notamment le délai, la fréquence de déploiement, le temps moyen de restauration et le taux d’échec des modifications) ou SPACE (cadre utilisé pour mesurer la productivité des développeurs dans cinq dimensions : satisfaction et bien-être, niveau de performance, activité, communication et collaboration, et efficacité) sont employées. Des sessions d’évaluation régulières avec des équipes interfonctionnelles garantissent un engagement actif avec les parties prenantes. Une documentation complète des processus liés aux commentaires, aux résultats et aux leçons apprises est conservée et partagée entre les équipes.
- Gestion (insights) : au cours de cette phase, les mécanismes de commentaires et les cadres de mesure sont robustes et axés sur les résultats opérationnels stratégiques. Les insights pilotés par les données guident les opérations de la plateforme, et les commentaires sont intégrés aux feuilles de route de la plateforme, favorisant ainsi des améliorations continues. Des analyses avancées sont utilisées pour évaluer l’impact de la plateforme sur les résultats opérationnels, notamment la croissance des revenus, et les commentaires sont mis en corrélation avec des métriques de performance pour identifier les domaines clés d’amélioration stratégique. Les parties prenantes de l’organisation sont profondément impliquées dans le processus d’envoi de commentaires, avec une collaboration structurée pour éviter les silos. Une documentation dynamique en temps réel, accessible à toutes les parties prenantes, reflète les commentaires en cours et les leçons apprises.
- Optimisation (approche proactive) : les processus de formulation de commentaires et de mesure sont étroitement intégrés à la culture de l’organisation, créant ainsi une approche proactive pour anticiper les défis et opportunités futurs et s’y adapter. Une analyse prédictive et des métriques avancées sont utilisées pour prévoir les besoins et les opportunités à venir, ce qui permet à la plateforme d’évoluer en permanence en réponse aux conditions changeantes. Les commentaires sont entièrement intégrés à un cycle d’amélioration continue, et une culture mettant en avant les commentaires est établie à tous les niveaux de l’organisation. La documentation dynamique et en temps réel reflète les commentaires en cours et est mise à jour en continu. Les leçons apprises sont donc partagées et accessibles à toutes les parties prenantes.