Extraire des informations à partir de documents
Tip
Pour plus d’informations, consultez l’onglet Texte et images !
Les processus métier actuels dépendent fortement des données contenues dans des documents tels que des formulaires, des reçus et des factures. Le traitement manuel peut introduire des retards et des erreurs, ce qui rend l’automatisation de l’extraction de données plus importante que jamais.
Fonctionnement d’Azure Content Understanding
Azure Content Understanding suit un flux de travail d’extraction piloté par modèle dans lequel le contenu non structuré est ingéré, analysé et retourné en tant que données structurées.
Ingérer du contenu : vous envoyez du contenu à Azure Content Understanding.
Analyse basée sur l’IA : le service utilise une combinaison de : reconnaissance optique de caractères (OCR), reconnaissance vocale, compréhension du langage naturel et modèles IA modales pour analyser le contenu.
Sortie structurée : le service retourne des résultats structurés (par exemple, au format JSON) qui correspondent à votre modèle, rendant les données faciles à stocker, rechercher ou intégrer dans des systèmes en aval.
Note
JSON (JavaScript Object Notation) est un format de données textuel utilisé pour stocker et échanger des données structurées entre les systèmes. Il est facile pour les humains de lire et d’écrire, et facile pour que les machines analysent et génèrent.
Comprendre les schémas
OCR (reconnaissance optique de caractères) permet à un ordinateur de « lire » du texte à partir d’images, telles que des documents numérisés, des photos de reçus ou des images de pages imprimées, et de transformer ce texte en texte numérique modifiable et pouvant faire l’objet d’une recherche. L’OCR de base permet de reconnaître le texte imprimé, se concentre sur l’extraction de texte et ne comprend pas la signification, le contexte ou les relations entre les mots.
Les fonctionnalités d’analyse des documents d’Azure Content Understanding vont au-delà de l’extraction de texte basée sur OCR simple pour inclure l’extraction basée sur le schéma des champs et leurs valeurs. L’approche basée sur le schéma est ce qui différencie Azure Content Understanding des services ocr ou de transcription de base.
Un schéma décrit les informations que vous souhaitez extraire et la façon dont ces informations doivent être structurées. Lorsque vous définissez un schéma, vous spécifiez des champs à extraire. Un schéma répertorie les champs ou entités spécifiques dont vous vous souciez.
Par exemple, supposons que vous définissez un schéma qui inclut les champs courants généralement trouvés dans une facture, par exemple :
- Nom de fournisseur
- Numéro de facture
- Date de facture
- Nom du client
- Adresse personnalisée
- Articles : les articles commandés, chacun incluant :
- Description de l’article
- Prix unitaire
- Quantité ordonnée
- Total pour l’article
- Sous-total de la facture
- Taxe
- Frais d’expédition
- Total de la facture
Supposons maintenant que vous devez extraire ces informations de la facture suivante :
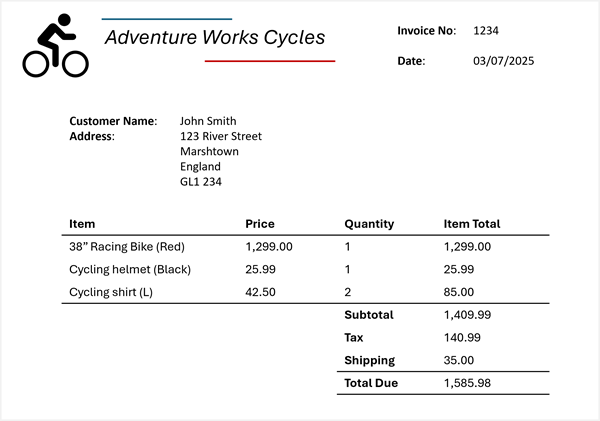
Azure Content Understanding peut appliquer le schéma de facture à votre facture et identifier les champs correspondants, même lorsqu’ils sont étiquetés avec différents noms (ou non étiquetés du tout). L’analyse résultante produit un résultat semblable à ceci :

Le schéma définit également la structure de champ. Les schémas prennent en charge les champs structurés et imbriqués, pas seulement le texte plat. Par exemple:
-
Itemsest une collection - Chaque élément a
description, ,unit pricequantityetline total
L’identification des champs structurés permet à Azure Content Understanding de comprendre les relations entre les valeurs, ce que l’OCR seul ne peut pas faire.
Dans l’exemple de facture, pour chaque champ détecté, vous pouvez extraire des valeurs imbriquées :
- Nom du fournisseur : Adventure Works Cycles
- Numéro de facture : 1234
- Date de facturation : 03/07/2025
- Nom du client : John Smith
- Adresse personnalisée : 123 River Street, Marshtown, Angleterre, GL1 234
-
Éléments :
- Élément 1 :
- Description de l’élément : 38" Racing Bike (Rouge)
- Prix unitaire : 1299,00
- Quantité ordonnée : 1
- Total pour l’article : 1299,00
- Élément 2 :
- Description de l’élément : Casque à vélo (Noir)
- Prix unitaire : 25,99
- Quantité ordonnée : 1
- Total pour l’article : 25,99
- Élément 3 :
- Description de l’élément : Chemise à vélo (L)
- Prix unitaire : 42,50
- Quantité ordonnée : 2
- Total pour l’article : 85,00
- Élément 1 :
- Sous-total de facture : 1409.99
- Taxe : 140,99
- Frais d’expédition : 35.00
- Total de la facture : 1585,98
Azure Content Understanding extrait la signification attendue, pas seulement les étiquettes. Les schémas sont appliqués sémantiquement, ce qui signifie :
- Les champs peuvent être extraits même si les étiquettes diffèrent
- Les champs peuvent être extraits même si des étiquettes sont manquantes
Par exemple, la facture No., Invoice #, ou un numéro non étiqueté peut tous être mappés InvoiceNumber si l’analyseur détermine qu’il représente le même concept.
Comprendre les analyseurs
Un analyseur est une unité dans Azure Content Understanding qui prend en charge l’entrée, applique l’analyse ia et produit des résultats structurés. Les analyseurs appliquent de manière cohérente la même logique d’extraction à tout le contenu entrant. Une fois qu’il est configuré, un analyseur garantit qu’un schéma est réutilisé de manière cohérente pour chaque demande d’analyse. Les analyseurs produisent également des résultats JSON prévisibles. Les résultats structurés facilitent le traitement en aval (stockage, recherche, automatisation).
Azure Content Understanding offre des analyseurs prédéfinis pour les scénarios courants et prend en charge les analyseurs personnalisés adaptés à vos besoins. À un niveau élevé :
- Vous choisissez ou créez un analyseur.
- L’analyseur inclut un schéma définissant des champs et une structure.
- Vous envoyez du contenu à des fins d’analyse
- Le service applique le schéma
- Vous recevez des résultats JSON structurés correspondant au schéma
Utilisation d’Azure Content Understanding dans le portail Foundry
Note
Le portail Foundry dispose d’une interface utilisateur classique et d’une nouvelle interface utilisateur.
Après avoir créé une ressource Microsoft Foundry, vous pouvez utiliser la nouvelle interface du portail Foundry pour tester Azure Content Understanding. Le portail Foundry fournit des exemples de contenu et vous permet de charger votre propre matériel à des fins d’analyse.
Vous pouvez utiliser l’interface visuelle pour sélectionner un document source et extraire les champs d’informations par défaut. Par exemple, lorsque vous essayez Azure Content Understanding sur une image d’un document, le service retourne le texte du document et les informations de disposition de texte.

Les analyseurs d’Azure Content Understanding identifient les valeurs de texte dans les documents et les mappent à des champs spécifiques. Par exemple, pour une facture donnée, le service retourne les champs (par exemple, Adresse du fournisseur) et les données renseignées dans les champs (par exemple, 123 456th Street).

Dans le portail Foundry, vous pouvez également afficher les résultats JSON du traitement.

Création d’une application cliente avec Azure Content Understanding
Vous pouvez utiliser l’API Content Understanding pour générer une application cliente légère qui extrait les données par programmation.
Note
Une application cliente est un programme logiciel qui s’exécute sur l’appareil d’un utilisateur et demande des services ou des données à partir d’un autre système, généralement un serveur, sur un réseau. Le client fait partie d’une application avec laquelle les utilisateurs interagissent, tandis que le serveur effectue le travail lourd en arrière-plan. Les applications peuvent demander des données ou des actions d’un service et recevoir une réponse structurée à l’aide d’une API.
Lorsque vous utilisez l’API Content Understanding, vous pouvez choisir un analyseur prédéfini ou créer un analyseur personnalisé. Les analyseurs prédéfinis incluent : prebuilt-invoice, , prebuilt-imageSearchprebuilt-audioSearch, et prebuilt-videoSearch. Lorsque vous envoyez du contenu pour l’analyse à l’analyseur, l’analyse est asynchrone, ce qui signifie que vous obtenez le résultat ultérieurement lorsqu’il est prêt. Étant donné que l’analyse est asynchrone, vous devez interroger l’URL de Operation-Location (ou analyzerResults) jusqu’à ce que le travail réussisse.
Utilisation du Kit de développement logiciel (SDK) Python Azure Content Understanding
Examinons le processus d’utilisation du Kit de développement logiciel (SDK) Python pour analyser une facture à partir d’une URL.
- Installez le Kit de développement logiciel (SDK) Python Azure Content Understanding.
python -m pip install azure-ai-contentunderstanding
Identifiez votre point de terminaison de ressource Foundry et votre clé API ou l’ID Microsoft Entra. Votre point de terminaison ressemble généralement à :
https://<your-resource-name>.services.ai.azure.com/Créez et exécutez le code de l’application cliente. C'
analzyer_idest l’ID de l’analyseur prédéfini. Vous trouverez ici une liste de valeurs d’ID d’analyseur prédéfinies.
import os
from azure.ai.contentunderstanding import ContentUnderstandingClient
from azure.core.credentials import AzureKeyCredential
endpoint = os.environ["FOUNDRY_ENDPOINT"]
key = os.environ["FOUNDRY_KEY"]
client = ContentUnderstandingClient(endpoint=endpoint, credential=AzureKeyCredential(key))
# 1) start analysis with analyzer id + inputs
analyzer_id = "prebuilt-invoice"
inputs = [
{"url": "https://github.com/Azure-Samples/azure-ai-content-understanding-python/raw/refs/heads/main/data/invoice.pdf"}
]
# 2) wait for the Long Running Operation (LRO) to complete
poller = client.begin_analyze(analyzer_id=analyzer_id, inputs=inputs) # starts LRO
result = poller.result() # waits for completion (polling handled by SDK)
# 3) read structured fields + markdown
# The result typically includes extracted "fields" and "markdown" per input content item.
for content in result.contents:
print(content.markdown)
print(content.fields)
La sortie résultante est JSON qui affiche le markdown extrait, les champs, les données dans les champs et le score de confiance. Par exemple:
{
"status": "Succeeded",
"result": {
"analyzerId": "prebuilt-invoice",
"apiVersion": "2025-05-01-preview",
"contents": [
{
"markdown": "# INVOICE\n\nCONTOSO LTD.\n\nContoso Headquarters\n123 456th St\nNew York, NY, 10001\n\nINVOICE: INV-100\n\nINVOICE DATE: 11/15/2019\n\nDUE DATE: 12/15/2019\n\nCUSTOMER NAME: MICROSOFT CORPORATION\n",
"fields": {
"CustomerName": {
"type": "string",
"valueString": "MICROSOFT CORPORATION",
"confidence": 0.95,
},
"InvoiceDate": {
"type": "date",
"valueDate": "2019-11-15",
"confidence": 0.994,
}
}
}
]
}
}
Découvrez ensuite comment utiliser des analyseurs Azure Content Understanding pour extraire des données structurées à partir d’audio et vidéo.