Explorer les fonctionnalités Hyperscale
Le niveau de service Hyperscale dans Azure SQL Database est un niveau de service du modèle d’achat vCore idéal pour les charges de travail d’entreprise. Il s’agit d’un stockage hautement évolutif et d’un niveau de performance de calcul qui utilise Azure pour effectuer un scale-out du stockage et des ressources de calcul d’une instance Azure SQL Database bien au-delà des limites disponibles des niveaux de service Usage général et Critique pour l’entreprise. Il découple le moteur de traitement de requêtes à partir de composants de stockage à long terme, ce qui permet une mise à l’échelle fluide des ressources de calcul et de stockage.
Hyperscale simplifie la conception d’applications et d’infrastructures et permet aux développeurs de se concentrer sur les besoins métier, plutôt que sur la gestion des ressources d’une base de données.
Azure SQL Database était auparavant limité à 4 To de stockage par base de données. Toutefois, le niveau de service Hyperscale permet désormais aux bases de données de dépasser 100 To. Hyperscale utilise une mise à l’échelle horizontale pour ajouter des nœuds de calcul à mesure que les données s’accroissent. Bien que le coût soit similaire à une instance Azure SQL Database normale, il existe un coût de stockage supplémentaire par téraoctet.
Comprendre les avantages
Le niveau de service Hyperscale élimine de nombreuses limites pratiques généralement rencontrées dans les bases de données cloud. Contrairement à la plupart des autres bases de données contraintes par les ressources d’un seul nœud, les bases de données Hyperscale n’ont pas ces restrictions. Grâce à son architecture de stockage flexible, le stockage augmente en fonction des besoins et il n’existe aucune taille maximale prédéfinie. Vous payez uniquement la capacité que vous utilisez. Pour les charges de travail intensives en lecture, Hyperscale offre un scale-out rapide en approvisionnant d’autres réplicas pour décharger les opérations de lecture.
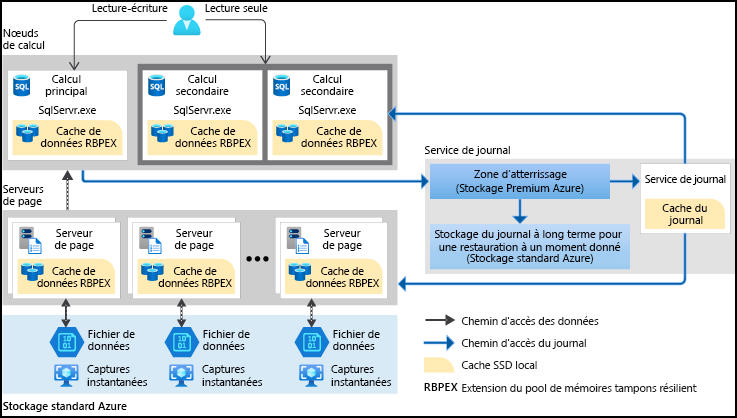
Par ailleurs, le temps nécessaire pour créer des sauvegardes de bases de données ou pour effectuer un scale-up ou un scale-down ne dépend plus du volume de données de la base de données. Les bases de données Hyperscale peuvent être sauvegardées instantanément. Vous pouvez également effectuer le scale-up ou scale-down d’une base de données de plusieurs dizaines de téraoctets en quelques minutes. Cette fonctionnalité vous évite d’être limité par vos choix de configuration initiaux. Hyperscale fournit également des restaurations rapides de bases de données qui s’effectuent en quelques minutes au lieu de quelques heures ou jours.
Hyperscale offre une scalabilité rapide en fonction de la demande de votre charge de travail.
| Fonctionnalité | Descriptif | Avantage | Cas d’usage |
|---|---|---|---|
| Augmenter/Diminuer l'échelle | Vous pouvez augmenter la taille de calcul principale en termes de ressources, comme le processeur et la mémoire, puis la réduire en un temps constant. Étant donné que le stockage est partagé, le scale-up et le scale-down ne sont pas liés au volume de données de la base de données. | Veillez à une flexibilité et à une efficacité dans la gestion des ressources. | Idéal pour les applications avec des charges de travail variables qui nécessitent plusieurs niveaux de puissance de calcul. |
| Effectuer un scale-in/scale-out | Vous pouvez également approvisionner un ou plusieurs réplicas de calcul pour gérer vos requêtes de lecture. Ces réplicas de calcul supplémentaires servent de réplicas en lecture seule pour décharger la charge de travail de lecture à partir du calcul principal. En outre, ces réplicas agissent comme serveurs de secours, prêts à prendre le contrôle en cas de défaillance du calcul principal. | Permet d’améliorer les performances et la fiabilité en déchargeant des charges de travail de lecture et en fournissant des fonctionnalités de basculement. | Adapté aux applications intensives en lecture qui nécessitent une haute disponibilité et des basculements rapides. |
Optimiser les performances
Le niveau de service Hyperscale est conçu pour les clients avec de grandes bases de données SQL Server locales qui souhaitent moderniser leurs applications en passant au cloud. Il est également idéal pour les clients, utilisant déjà Azure SQL Database, qui veulent augmenter de manière significative le potentiel d’expansion de leur base de données. De plus, Hyperscale est excellent pour ceux qui recherchent une haute performance et une scalabilité élevée
Outre les fonctionnalités rapides de mise à l’échelle, Hyperscale offre les fonctionnalités de performances suivantes.
- Les sauvegardes de bases de données sont quasi instantanées, quelle que soit la taille, sans aucun effet sur les ressources de calcul.
- Les restaurations de bases de données s’effectuent en quelques minutes, au lieu de quelques heures ou jours.
- Les performances globales sont améliorées en raison d’un débit de journal des transactions plus élevé et de temps de validation de transactions plus rapides, quels que soient les volumes de données.
Remarque
Pour déployer une base de données Hyperscale dans Azure SQL Database, voir
Déployer une base de données Azure SQL Hyperscale
Pour déployer Azure SQL Database avec le niveau Hyperscale :
Connectez-vous au portail Azure.
Accédez à la page Azure SQL, puis sélectionnez + Créer.
Sélectionnez SQL Database, Base de données unique et le bouton Créer.
Sous l’onglet Informations de base de la page Créer une base de données SQL, sélectionnez l’abonnement, le groupe de ressources et le nom de la base de données souhaités.
Sélectionnez le lien Créer nouveau pour le Serveur, puis fournissez les nouvelles informations de serveur, telles que le nom du serveur, le nom de l’administrateur du serveur et le mot de passe, et la localisation.
Sous Calcul + stockage, sélectionnez le lien Configurer la base de données.
Sélectionnez Hyperscale pour le Niveau de service et Approvisionné pour le Niveau de calcul.
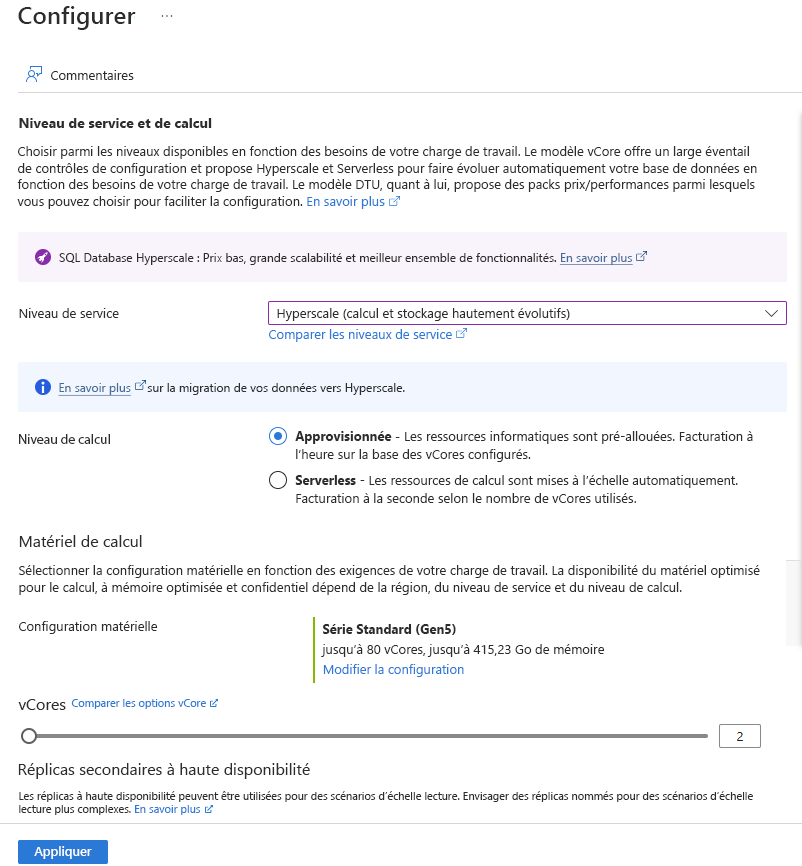
Sous Configuration matérielle, sélectionnez le lien Modifier la configuration. Passez en revue les configurations matérielles disponibles et sélectionnez la configuration la plus appropriée pour votre base de données. Pour cet exemple, nous laissons l’option Série Standard (Gen5) par défaut.
Si vous le souhaitez, ajustez le curseur vCores si vous souhaitez augmenter le nombre de vCores pour votre base de données.
Ajustez le curseur Répliques secondaires à haute disponibilité pour créer une réplique. Sélectionnez Appliquer.
Sélectionnez Suivant : Réseau en bas de la page.
Sous l’onglet Mise en réseau, définissez Ajouter l’adresse IP actuelle du client sur Oui.
Sélectionnez Vérifier + créer, puis Créer.

Remarque
Après la conversion d’une base de données vers Hyperscale, il n’est pas possible de rétablir une instance Azure SQL Database régulière. Pour découvrir plus d’informations sur les limitations d’Hyperscale, consultez limitations connues du niveau de service Hyperscale.
Se connecter à un réplica en lecture seule
Vous pouvez vous connecter à une réplique en lecture seule en définissant l’argument ApplicationIntent de votre chaîne de connexion sur ReadOnly. Les connexions avec l’intention d’application ReadOnly sont automatiquement routées vers l’un des réplicas de calcul en lecture seule.
Server=tcp:<your_server_name>.database.windows.net,1433;Database=<your_database_name>;User ID=<your_username>@<your_server_name>;Password=<your_password>;Encrypt=true;Connection Timeout=30;ApplicationIntent=ReadOnly;