Activer la résilience des applications avec Azure SQL Database
Les groupes de basculement automatique et géoréplication sont tous deux des mécanismes utilisés dans Azure SQL Database pour améliorer la disponibilité et la récupération d’urgence, mais elles ont quelques différences clés.
Découvrir la géoréplication active
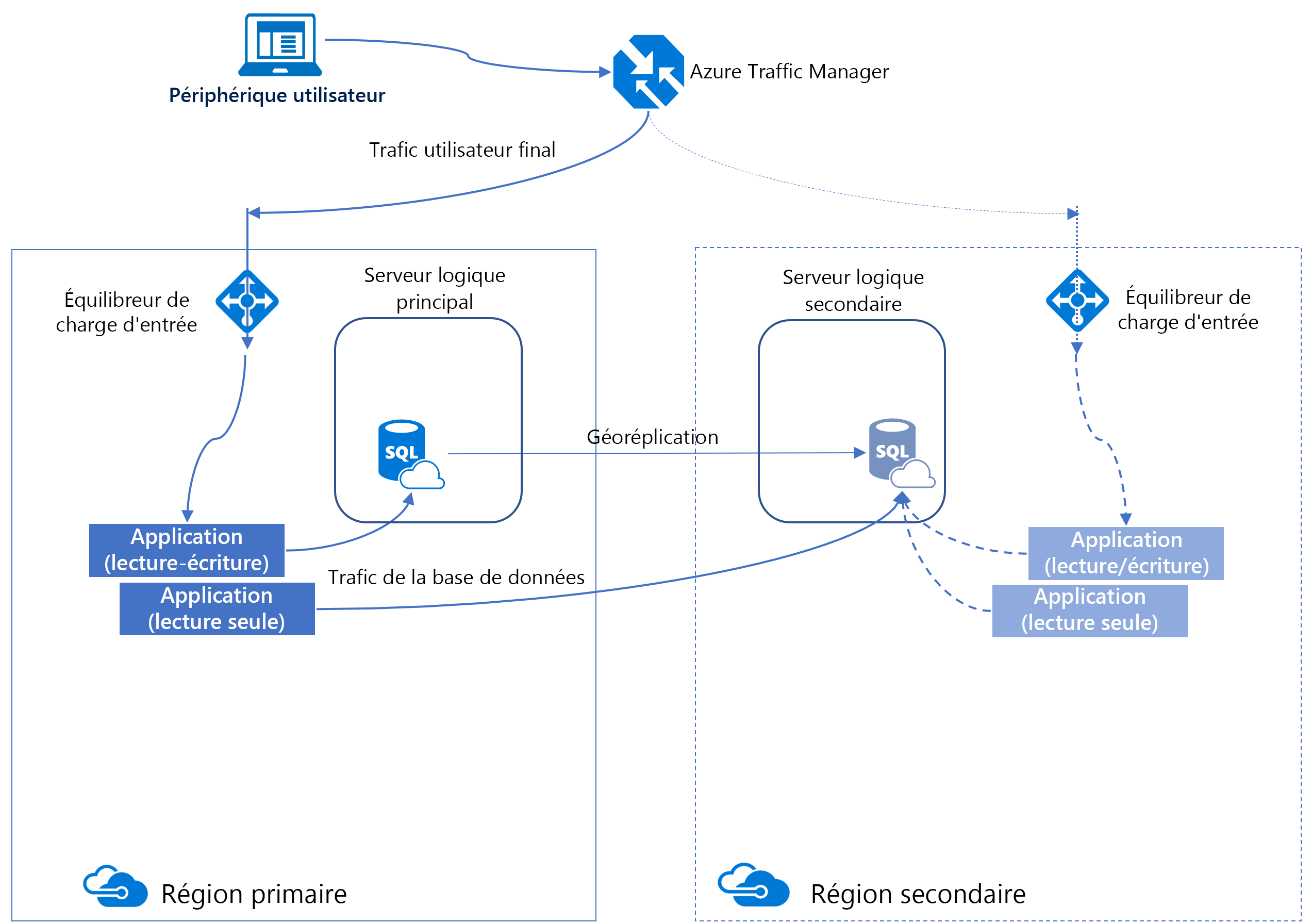
Une méthode pour augmenter la disponibilité d’Azure SQL Database consiste à utiliser la géoréplication. La géoréplication active est conçue comme solution de continuité d’activité qui vous permet de créer des bases de données secondaires accessibles en lecture à partir de bases de données individuelles sur un serveur dans une région identique ou différente. Elle prend en charge jusqu’à quatre réplicas secondaires et elle est configurée par base de données.
En arrière-plan, Azure utilise des groupes de disponibilité pour fournir cette fonctionnalité. Avec la géoréplication active, les clients peuvent basculer programmatiquement ou manuellement des bases de données primaires vers des régions secondaires lors d’un sinistre majeur.
Afin d’éviter la surcharge de réplication en raison d’une charge de travail d’écriture volumineuse qui peut affecter les performances de réplication, nous vous recommandons de configurer la géoréplication secondaire avec la même taille de calcul et le même niveau de service que la principale.
Vous pouvez configurer manuellement la géoréplication pour Azure SQL Database en accédant à la page de base de données et en sélectionnant Réplicas dans la section Gestion des données .

Une fois le réplica secondaire créé, vous pouvez lancer manuellement un basculement. Les rôles basculent, faisant du réplica secondaire le nouveau principal et l’ancien principal le nouveau secondaire.

La géoréplication est asynchrone, ce qui signifie qu’un retard de certaines données est possible entre la base de données primaire et la base de données secondaire. La chaîne de connexion d’application doit également être mise à jour après un basculement.
Configurer la géoréplication entre abonnements
Dans certains scénarios, vous devrez peut-être configurer un réplica secondaire sur un autre abonnement que celui de la base de données primaire. C’est ici qu’entre en jeu la géoréplication entre abonnements. Cette fonctionnalité vous permet de configurer un réplica secondaire dans un autre abonnement pour vous fournir une flexibilité supérieure et des options de récupération d’urgence améliorées. L’utilisation de la géoréplication entre abonnements vous permet de veiller à ce que vos données soient protégées et accessibles, même si un abonnement rencontre des problèmes. Cette configuration est utile pour les organisations ayant de nombreux abonnements ou pour celles cherchant à implémenter un plan de continuité d’activité robuste.
Pour en savoir plus sur les étapes requises pour configurer une géoréplication entre abonnements, consultez géoréplication entre abonnements.
Activer les groupes de basculement automatique
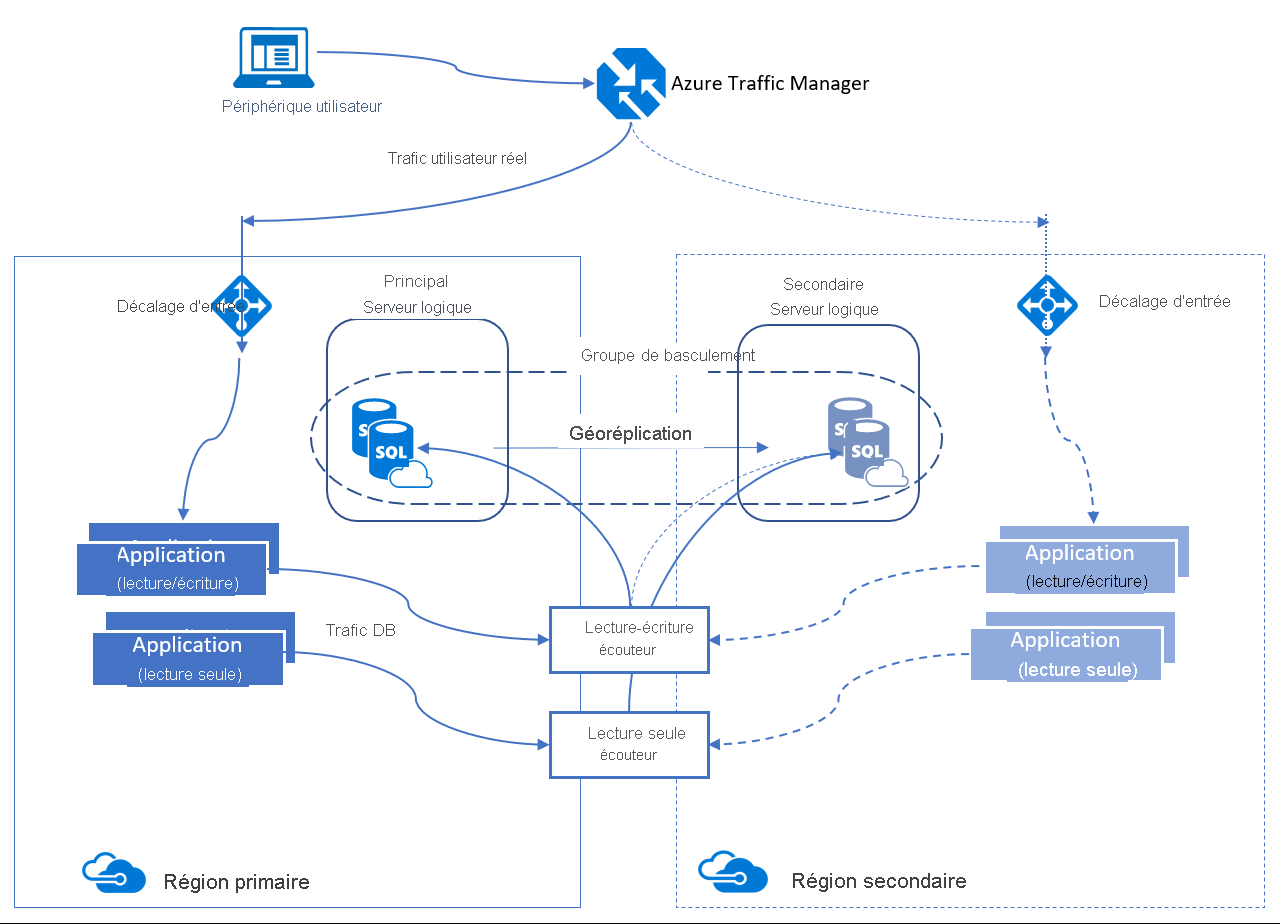
Un groupe de basculement automatique est une fonctionnalité de disponibilité qui peut être utilisée avec Azure SQL Database et Azure SQL Managed Instance. Les groupes de basculement automatique vous permettent de gérer la façon dont les bases de données sont répliquées sur une autre région, ainsi que la façon dont le basculement peut se produire. Le nom affecté au groupe de basculement automatique doit être unique dans le domaine *.database.windows.net.
Les groupes de basculement automatique offrent une fonctionnalité de type AG via un écouteur, ce qui active les activités lecture/écriture et en lecture seule. Cette fonctionnalité diffère légèrement de la géoréplication active. Il existe deux types d’écouteurs : un pour le trafic en lecture/écriture et l’autre pour le trafic en lecture seule. Pendant un basculement, les mises à jour DNS permettent aux clients de se connecter au nom de l’écouteur sans avoir besoin d’informations supplémentaires. Le serveur de base de données contenant les copies en lecture/écriture est le serveur primaire et le serveur qui en reçoit les transactions est le serveur secondaire.
Les groupes de basculement automatique ont deux stratégies différentes qui peuvent être configurées.
- Géré par le client (recommandé) : les clients peuvent lancer manuellement un basculement lorsqu’ils détectent une panne inattendue affectant une ou plusieurs bases de données dans le groupe de basculement. Vous pouvez effectuer ce basculement manuel en utilisant des outils de ligne de commande comme PowerShell, l’interface Azure CLI ou l’API REST.
- Gérés par Microsoft , ils sont automatiquement lancés par Microsoft lors d’une panne généralisée qui a un impact sur une région primaire. Ce basculement automatique s’applique à tous les groupes de basculement affectés avec leur stratégie de basculement définie sur Géré par Microsoft.
Les basculements non planifiés peuvent entraîner une perte de données s’ils sont forcés et que le serveur secondaire n’est pas entièrement synchronisé avec le principal. La configuration de GracePeriodWithDataLossHours contrôle la durée d’attente d’Azure avant le basculement. La valeur par défaut est d'une heure. Si vous avez un objectif de point de récupération serré et ne pouvez pas vous permettre de perdre beaucoup de données, fixez une valeur plus élevée. Bien qu’Azure attende plus longtemps avant de basculer, cette approche peut engendrer une perte de données inférieure, car le serveur secondaire a plus de temps pour se synchroniser entièrement avec le primaire.
En outre, un groupe de basculement automatique peut inclure une ou plusieurs bases de données, avec la même taille et la même édition sur les serveurs primaire et secondaire. La base de données sur le serveur secondaire est créée automatiquement par le biais d’un processus appelé amorçage, ce qui peut prendre un certain temps en fonction de la taille de la base de données. Il est important de planifier en conséquence et de tenir compte de facteurs tels que la vitesse du réseau.
Choix
La géoréplication est appropriée pour les scénarios où vous avez besoin de plusieurs réplicas accessibles en lecture et où un basculement manuel est acceptable, alors que les groupes de basculement automatique sont parfaits pour les scénarios nécessitant un basculement automatique et une réplication synchrone pour un groupe de bases de données.
Le tableau suivant compare les fonctionnalités de la géoréplication et des groupes de basculement automatique, ainsi que d’autres informations pertinentes.
| Fonctionnalité | Géoréplication | Groupes de basculement automatique |
|---|---|---|
| Nombre de réplicas | Prend en charge jusqu’à quatre réplicas secondaires. | Prend en charge un seul réplica secondaire |
| Niveau de configuration | Configurés par base de données. | Configurés pour un groupe de bases de données |
| Type de réplication | Le terme asynchrone signifie qu’un retard de certaines données est possible entre la base de données primaire et la base de données secondaire | Synchrone, pour veiller à ce que la base de données secondaire soit toujours synchronisée avec la base de données primaire. |
| Basculement | Nécessite un basculement manuel. La chaîne de connexion d’application doit également être mise à jour après un basculement | Permet de prendre en charge les basculements automatique et manuel, sans devoir modifier les chaînes de connexion après un basculement |
| Lisibilité | Permet de fournir des réplicas secondaires accessibles en lecture. | Permet de fournir des bases de données secondaires accessibles en lecture et sert de serveur de secours pour le basculement |
| Cas d'utilisation | Adapté aux scénarios nécessitant plusieurs réplicas accessibles en lecture et un basculement manuel | Idéal pour les scénarios nécessitant un basculement automatique et une réplication synchrone pour un groupe de bases de données |