Explorer Microsoft Dataverse
Microsoft Dataverse est une solution basée sur le cloud qui structure facilement diverses données et une logique métier pour prendre en charge des applications et des processus interconnectés de manière sécurisée et conforme. Géré et tenu à jour par Microsoft, Dataverse est disponible dans le monde entier, mais déployé par zone géographique pour se conformer à la résidence de vos données. Il n’est pas conçu pour une utilisation autonome sur vos serveurs. Vous aurez donc besoin d’une connexion Internet pour y accéder et l’utiliser.
Dataverse est différent des bases de données traditionnelles, car il s’agit bien plus que de simples tables. Il intègre la sécurité, la logique, les données et le stockage dans un point central. Il est conçu pour être votre entrepôt de données central pour les données métier, et vous l’utilisez peut-être même déjà. En coulisses, il alimente de nombreuses solutions Microsoft Dynamics 365, comme Field Service, les insights client, le service clientèle et les ventes. Il est également disponible dans le cadre des applications Power Apps et Power Automate avec la connectivité native intégrée. Les fonctionnalités AI Builder et Portails de Microsoft Power Platform utilisent également Dataverse.
Vous trouverez ci-dessous une visualisation qui réunit les nombreuses offres de Microsoft Dataverse.
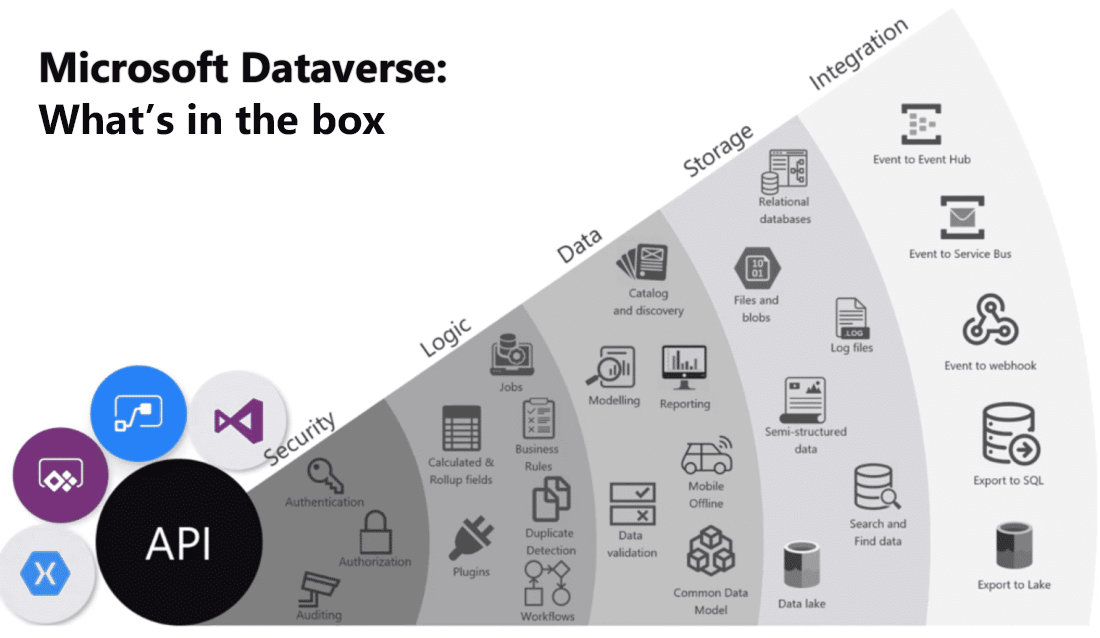
Vous trouverez ci-dessous une brève explication de chaque catégorie de fonctionnalités.
Sécurité : Dataverse gère l’authentification avec Azure Active Directory (Azure AD) pour permettre l’accès conditionnel et l’authentification multi-facteur. Il prend en charge l’autorisation jusqu’au niveau des lignes et des colonnes, et fournit des fonctionnalités d’audit enrichies.
Logique : Dataverse vous permet d’appliquer facilement la logique métier au niveau des données. Quelle que soit la façon dont un utilisateur interagit avec les données, les mêmes règles s’appliquent. Ces règles peuvent être liées à la détection des doublons, aux règles métier, aux workflows, etc.
Données : Dataverse vous permet de mettre en forme vos données, ce qui vous permet de découvrir, de modéliser, de valider et de rendre compte de vos données. Ce contrôle garantit que vos données ont l’aspect souhaité, quelle que soit la manière dont elles sont utilisées.
Stockage : Dataverse stocke vos données physiques dans le Cloud Azure. Ce stockage informatique évite d’avoir à se préoccuper de l’emplacement de vos données ou de la façon dont elles sont mises à l’échelle. Ces préoccupations sont toutes gérées pour vous.
Intégration : Dataverse se connecte de différentes manières pour répondre aux besoins de votre entreprise. Les API, les webhooks, les événements et les exportations de données vous donnent la flexibilité nécessaire pour obtenir et extraire des données.
Comme vous pouvez le voir, Microsoft Dataverse est une solution cloud très puissante pour le stockage et l’utilisation de vos données métier. Dans les sections suivantes, examinez Microsoft Dataverse avec le filtre du stockage de données pour Microsoft Power Platform, où commencez votre parcours. Gardez à l’esprit d’autres fonctionnalités enrichies abordées ci-dessus. Vous pouvez explorer plus en détail au fur et à mesure que votre utilisation augmente.
Pour commencer, Microsoft Dataverse vous permet de créer une ou plusieurs instances basées sur le cloud d’une base de données standardisée. La base de données comprend des tables et des colonnes prédéfinies qui stockent des données généralement présentes dans presque toutes les organisations et entreprises. Vous pouvez personnaliser et étendre les données stockées en ajoutant de nouvelles colonnes ou tables. La facilité de configuration d’une base de données Microsoft Dataverse et d’un modèle de données standardisé dans celle-ci simplifie votre capacité à concentrer vos efforts sur la génération de solutions sans vous soucier de l’infrastructure, du stockage et de l’intégration des données. Avec vos données stockées dans Microsoft Dataverse, il existe plusieurs façons différentes d’y accéder. Vous pouvez utiliser les données en mode natif avec des outils tels que Power Apps ou Power Automate. N’importe quelle solution métier peut se connecter à Dataverse à l’aide des API de connecteurs. Grâce à la puissance de fonctionnalités comme la sécurité basée sur les rôles et les règles d’entreprise, vous pouvez être confiants quant à la sécurité de vos données, quel que soit le mode d’accès.
Extensibilité
Une base de données Dataverse prend en charge des jeux de données volumineux et des modèles de données complexes. Les tables peuvent contenir des millions d’éléments et vous pouvez étendre le stockage dans chaque instance d’une base de données Microsoft Dataverse jusqu’à 4 téraoctets. La quantité de données disponibles dans votre instance de Microsoft Dataverse est fonction du nombre et du type de licences qui lui sont associées. Le stockage de données est regroupé entre tous les utilisateurs sous licence. Vous pouvez donc allouer le stockage en fonction des besoins pour chaque solution que vous créez. Vous pouvez acheter un stockage incrémentiel si vous avez besoin de plus de stockage que ce qui est proposé au sein d’une licence standard.
Structure et avantages de Microsoft Dataverse
La structure d’une base de données Microsoft Dataverse est basée sur les définitions et le schéma spécifiés dans le modèle Common Data Model. L’utilisation du Common Data Model comme élément principal d’une base de données Microsoft Dataverse simplifie l’intégration de toutes les solutions utilisant un schéma Common Data Model. Cela est dû au fait que Common Data Model est l’élément principal d’une base de données Microsoft Dataverse et utilise un schéma Common Data Model. Les tables standard de la solution sont identiques. Vous pouvez tirer parti d’un écosystème riche de solutions créé par les fournisseurs à l’aide du Common Data Model. Mieux encore, il n’existe pratiquement aucune limite à l’extension d’une base de données Microsoft Dataverse.
Identifier les tables, les colonnes et les relations
Une table est une structure logique contenant des lignes et des colonnes qui représentent un ensemble de données. Dans la capture d’écran, vous voyez la table de compte standard et divers éléments qui peuvent être gérés dans le cadre de celle-ci.
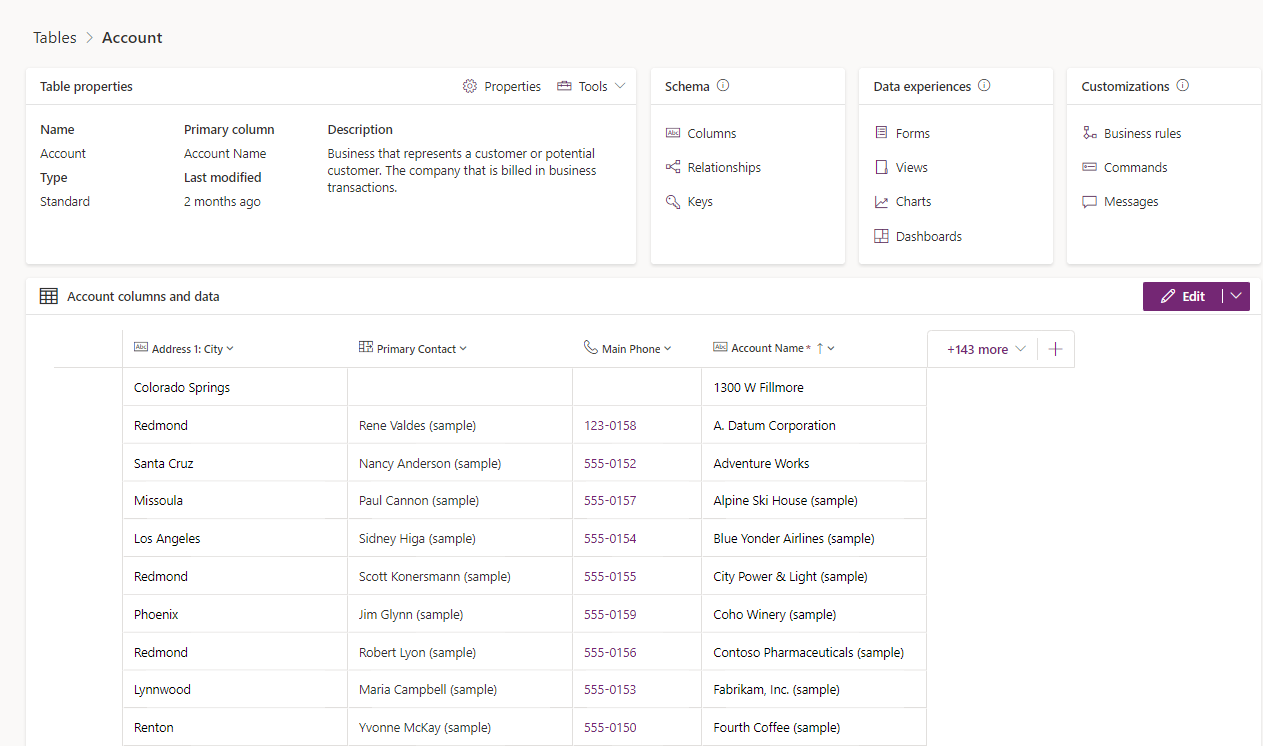
Types de tables
Les trois types de tables sont les suivants :
Standard : plusieurs tables standard, également appelées tables prêtes à l’emploi, sont incluses dans un environnement Dataverse. Citons par exemple les tables de comptes, d’unités métier, de contacts, de tâches et d’utilisateurs. La plupart des tables standard incluses avec Dataverse peuvent être personnalisées.
Managées : il s’agit des tables non personnalisables, importées dans l’environnement dans le cadre d’une solution managée.
Personnalisées : les tables personnalisées sont des tables non managées importées à partir d’une solution non managée ou de nouvelles tables créées directement dans l’environnement Dataverse.
Colonnes
Les colonnes stockent une information discrète au sein d’une ligne dans une table. Vous pouvez les considérer comme une colonne dans Excel. Les colonnes ont des types de données, ce qui signifie que vous pouvez stocker des données d’un certain type dans une colonne qui correspond à ce type de données. Par exemple, si vous disposez d’une solution qui nécessite des dates, telles que la capture de la date d’un événement ou le moment où un événement s’est produit, vous stockez la date dans une colonne de type Date. De même, si vous voulez stocker un nombre, vous stockez le nombre dans une colonne avec le type Nombre.
Le nombre de colonnes dans une table varie de quelques colonnes à 100 ou plus. Dans Microsoft Dataverse, chaque base de données commence par un ensemble standard de tables et chaque table standard possède un ensemble standard de colonnes.
Comprendre les relations
Afin de créer une solution efficace et évolutive pour la plupart des solutions que vous concevez, il vous faut répartir les données entre différents conteneurs (tables). Essayer de stocker tous les éléments dans un seul conteneur serait probablement inefficace et difficile à comprendre.
L’exemple suivant illustre ce concept.
Imaginez que vous devez créer un système pour gérer les ordres de vente. Vous avez besoin d’une liste de produits avec le stock disponible, le coût de l’article et le prix de vente. Vous avez également besoin d’une liste principale de clients avec leurs adresses et leurs notations de crédit. Enfin, vous devez également gérer les factures de vente pour stocker les données de facturation. La facture doit comprendre des informations telles que :
Date
Numéro de facture
salesperson
informations sur le client, notamment l’adresse et la cote de solvabilité
un élément de ligne pour chaque élément de la facture
Chaque élément de ligne doit contenir une référence au produit vendu. L’élément de ligne doit également fournir le coût et le prix appropriés pour chaque produit. Enfin, la ligne doit également réduire la quantité disponible en fonction de la quantité vendue dans cet élément de ligne. La création d’une table unique pour prendre en charge les fonctionnalités de l’exemple ci-dessus serait inefficace. Une meilleure façon d’aborder ce scénario métier consiste à créer les quatre tables suivantes :
Clients
Produits
Factures
Éléments de ligne
La création d’une table pour chacun de ces éléments et leur mise en relation entre elles vous permet de générer une solution efficace qui peut mettre à l’échelle, tout en conservant de hautes performances. Le fractionnement des données entre plusieurs tables signifie également que vous n’avez pas à stocker des données répétitives ou à prendre en charge des lignes énormes avec de grandes quantités de données vides. La création de rapports est également plus facile si vous fractionnez les données entre différentes tables.
Les tables qui sont liées les unes aux autres ont une connexion relationnelle. Les relations entre les tables existent sous diverses formes, mais les deux plus courantes sont la relation une-à-plusieurs et la relation plusieurs-à-plusieurs, toutes deux prises en charge par Microsoft Dataverse. Pour en savoir plus sur les différents types de relation, consultez : Relations de table.
Logic métier dans Microsoft Dataverse
De nombreuses organisations ont une logique métier qui a un impact sur la façon dont elles fonctionnent avec les données. Par exemple, une organisation utilisant Dataverse pour stocker des informations client peut vouloir créer un champ tel quel et le champ Numéro d’identification requis. Dans Microsoft Dataverse, vous générez cette logique à l’aide de règles métier. Les règles d’entreprise vous permettent d’appliquer et de maintenir la logique métier au niveau de la couche données au lieu de la couche application. Plus simplement, si vous créez des règles métier dans Microsoft Dataverse, celles-ci sont appliquées, quelle que soit l’endroit où vous interagissez avec les données.
Par exemple, les règles métier peuvent être utilisées dans des applications canevas et dans des applications pilotées par modèle pour définir ou effacer des valeurs dans une ou plusieurs colonnes d’une table. Ils peuvent également être utilisés pour valider des données stockées ou pour afficher des messages d’erreur. Les applications pilotées par modèle peuvent utiliser des règles d’entreprise pour afficher ou masquer des colonnes, activer ou désactiver des colonnes et créer des suggestions en fonction du décisionnel.
Les règles d’entreprise vous offrent un moyen efficace d’appliquer des règles, de définir des valeurs ou de valider des données, quel que soit le format utilisé pour l’entrée de données. Les règles d’entreprise sont également efficaces pour améliorer la précision des données, simplifier le développement de l’application et rationaliser les formulaires présentés aux utilisateurs finaux.
Considérez cet exemple comme une utilisation simple et néanmoins puissante de règles d’entreprise. La règle métier est configurée pour modifier le champ Approbateur VP de la limite de crédit et le rendre obligatoire si la limite de crédit est définie sur une valeur supérieure à $1,000,000. Si la limite de crédit est inférieure à $1,000,000, le champ est facultatif.
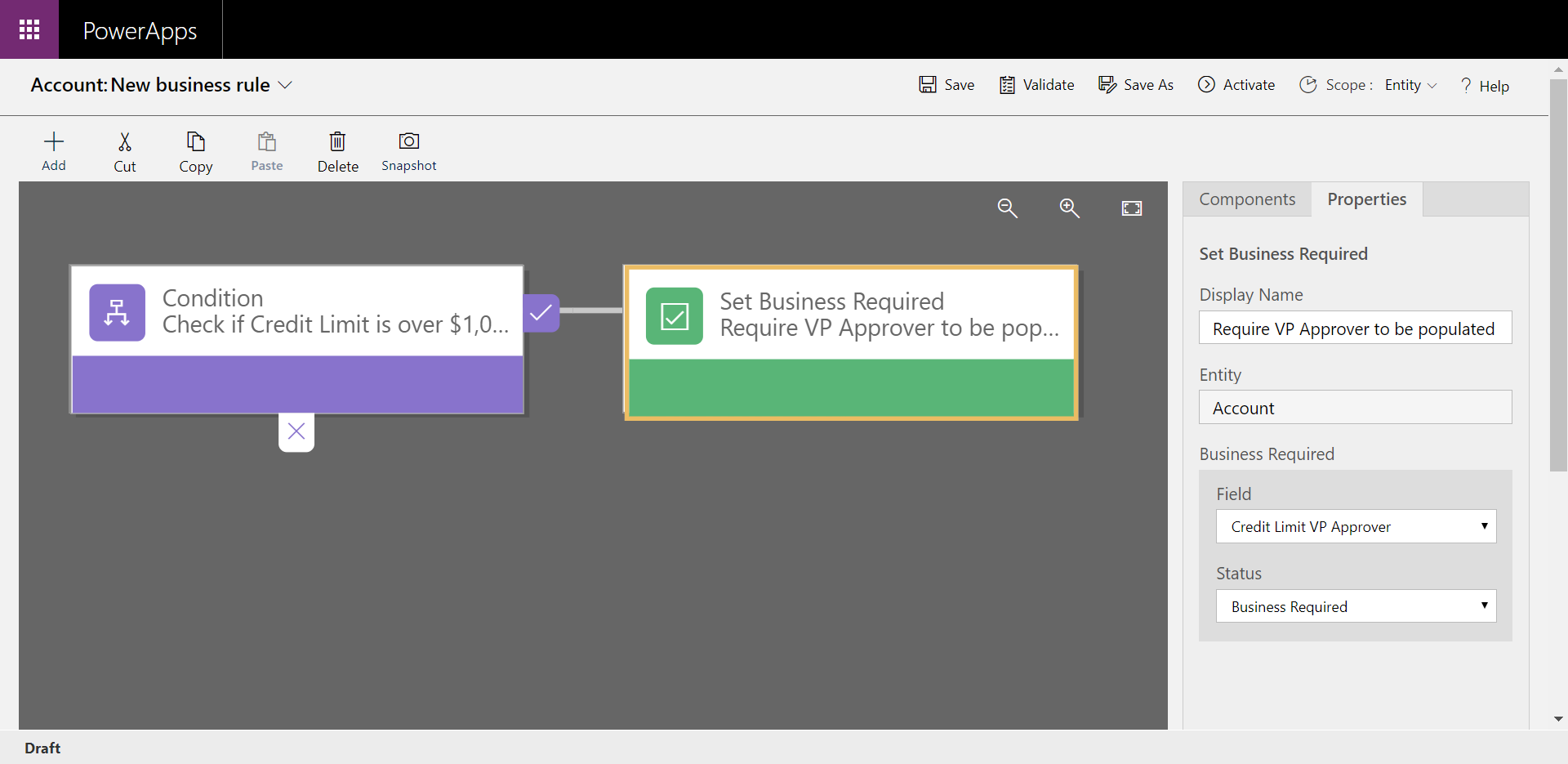
En appliquant cette règle métier au niveau des données plutôt qu’au niveau de l’application, vous contrôlez mieux vos données. Cela garantit que votre logique métier est suivie, que vous y accédiez directement à partir de Power Apps, de Power Automate, ou même au moyen d’une API. La règle est liée aux données, et non à l’application.
Pour en savoir plus sur l’utilisation de règles métier dans Dataverse, consultez : Créer une règle métier pour une table.
Utilisation des dataflows
Les flux de données sont une technologie de préparation des données en libre-service, basée sur le cloud. Les flux de données permettent aux clients d’ingérer, de transformer et de charger des données dans des environnements Microsoft Dataverse, des espaces de travail Power BI ou le compte Azure Data Lake Storage de votre organisation. Les flux de données sont créés à l’aide de Power Query, une expérience de connectivité et de préparation des données, déjà présente dans de nombreux produits Microsoft, dont Excel et Power BI. Les clients peuvent déclencher l’exécution de flux de données à la demande ou automatiquement selon une planification, les données étant toujours actualisées.
Un flux de données stockant les entités résultantes dans un stockage basé sur le cloud, d’autres services peuvent interagir avec les données produites par des flux de données.
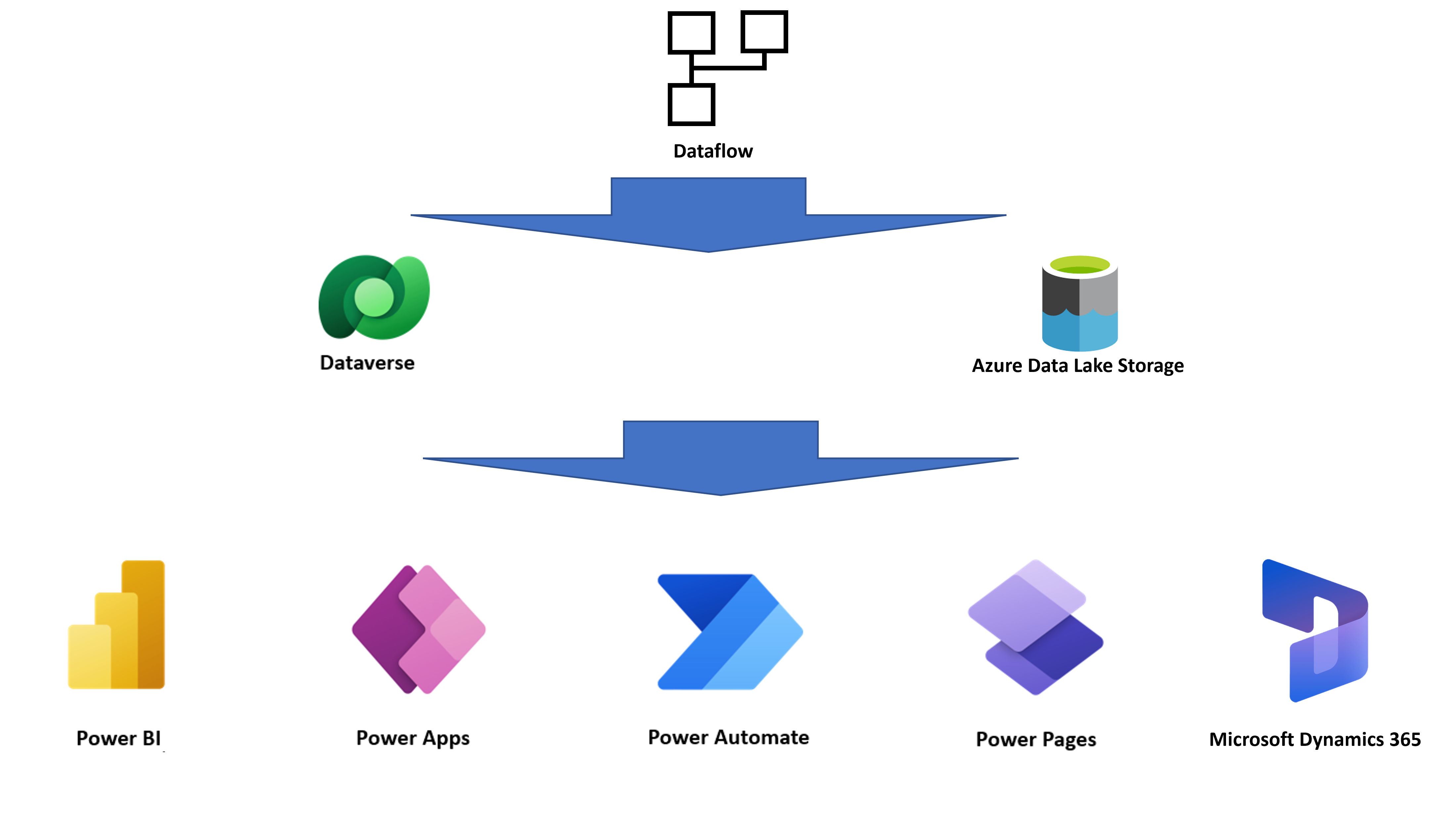
Par exemple, Power BI, Power Apps, Power Automate, Power Virtual Agents et les applications Dynamics 365 peuvent obtenir les données produites par le flux de données en se connectant à Dataverse, à un connecteur de flux de données Power Platform. Ils peuvent également obtenir les données directement par le lac, en fonction de la destination configurée à la création du flux de données.
La liste suivante met en évidence certains avantages liés à l’utilisation de flux de données :
Un flux de données dissocie la couche de transformation de données de la couche de modélisation et visualisation dans une solution Power BI.
Le code de transformation de données peut résider dans un emplacement central, un flux de données, plutôt qu’être réparti entre plusieurs artefacts.
Un créateur de flux de données n’a besoin de compétences qu’en Power Query. Dans un environnement avec plusieurs créateurs, le créateur de flux de données peut faire partie d’une équipe qui génère l’ensemble de la solution ou de l’application opérationnelle BI.
Un flux de données est indépendant du produit. Il ne s’agit pas d’un composant uniquement de Power BI ; vous pouvez obtenir ses données dans d’autres outils et services.
Les flux de données tirent parti de Power Query, une puissante expérience graphique de transformation de données en libre-service.
Les flux de données s’exécutent entièrement dans le cloud. Aucune autre infrastructure n’est requise.
Vous disposez de plusieurs options pour commencer à utiliser des flux de données sous couvert de licences pour Power Apps, Power BI et Customer Insights.
Les flux de données peuvent effectuer des transformations avancées, mais ils sont conçus pour des scénarios en libre-service et ne nécessitent aucune connaissance en informatique ou en développement.
Common Data Model
Lorsque vous créez des solutions métier, vous devez souvent intégrer des données dans différentes applications métier de votre organisation. Cette intégration inter-applications peut parfois être difficile. Bien que les données soient semblables, elles ne sont pas nécessairement stockées de la même manière dans différentes applications. Pour le simplifier, plusieurs leaders technologiques ont créé l’initiative Common Data Model. L’objectif est d’avoir une structure commune qui s’applique facilement aux différentes applications. Les organisations peuvent créer et partager leurs propres types de données et leurs propres balises à l’aide du Common Data Model de Microsoft, qui dispose d’un système étendu de métadonnées. Cela permet de capturer de précieuses informations métier qui peuvent être intégrées et enrichies avec des données pour fournir des informations exploitables.
Avec Common Data Model, vous pouvez structurer vos données pour représenter des concepts et des activités couramment utilisés et bien compris. Vous pouvez interroger et analyser ces données, les réutiliser et interagir avec d’autres entreprises et applications utilisant le même format. Les organisations peuvent créer et partager leurs propres types de données et leurs propres balises à l’aide du Common Data Model de Microsoft, qui dispose d’un système étendu de métadonnées.
Au lieu de créer un nouveau modèle de données pour votre application, vous pouvez simplement utiliser les définitions de table disponibles. Common Data Model est utilisé par diverses applications et divers services, notamment Microsoft Dataverse, Dynamics 365, Microsoft Power Platform et Azure. Ce modèle de données partagé garantit l’accès aux mêmes données à tous vos services. Les fonctionnalités de préparation des données dans des flux de données Power BI constituent un bon exemple d’utilisation du Common Data Model. Ces flux de données créent des fichiers de données qui suivent la définition Common Data Model. Ces fichiers de données sont stockés dans Azure Data Lake. Les définitions Common Data Model sont ouvertes et disponibles pour n’importe quel service ou n’importe quelle application souhaitant s’en servir.

Les données décrites à l’aide du Common Data Model peuvent être utilisées avec des services Azure pour créer une solution analytique évolutive. Il peut également s’agir d’une source de données sémantiquement riches pour des applications permettant d’obtenir des informations exploitables, notamment Dynamics 365 Customer Insights. Common Data Model est utilisé pour définir des entités pour des applications Dynamics 365 dans les ventes, les finances, la gestion de la chaîne logistique, tandis que le commerce peut être facilement disponible dans Azure Data Lake.
Microsoft continue d’étendre le Common Data Model en collaboration avec de nombreux partenaires et experts en la matière. En créant des accélérateurs de secteur d’activité, Microsoft permet aux secteurs d’activité suivants de tirer parti du Common Data Model et des plateformes qui le prennent en charge :