Choisir une clé de partition
Souvenez-vous que les données des documents JSON sont stockées dans des bases de données Azure Cosmos DB, dans des conteneurs qui sont à leur tour distribués sur des partitions physiques et où les données sont routées vers la partition physique appropriée en fonction de la valeur d’une clé de partition.

La clé de partition est une propriété de document obligatoire qui garantit que des documents dotés de la même valeur de clé de partition seront routés vers une partition physique spécifique et y seront stockés. Une partition physique prend en charge une quantité maximale fixe de stockage et de débit (RU/s). Azure Cosmos DB distribue automatiquement les partitions logiques entre les partitions physiques disponibles, en utilisant à nouveau la valeur de clé de partition pour le faire d’une manière prévisible.
Dans cette unité, vous allez découvrir les partitions logiques et comment éviter les partitions à chaud. Ces informations nous aideront à choisir la clé de partition appropriée aux données client dans notre scénario.
Dans Azure Cosmos DB, vous augmentez le stockage et le débit en ajoutant des partitions physiques pour accéder aux données et les stocker. La taille de stockage maximale d’une partition physique s’élève à 50 Go et le débit maximal à 10 000 RU/s.
Partitions logiques dans Azure Cosmos DB
Une partition logique est une abstraction au-dessus des partitions physiques sous-jacentes. Plusieurs partitions logiques peuvent être stockées dans une même partition physique. Un conteneur peut avoir un nombre illimité de partitions logiques. Les partitions logiques individuelles sont déplacées vers de nouvelles partitions physiques à mesure que leur taille augmente pour garantir une utilisation et une croissance optimales du stockage. Le déplacement de partitions logiques en tant qu’unité garantit que tous les documents qu’elles contiennent résideront sur la même partition physique. La taille maximale d’une partition logique s’élève à 20 Go. L’utilisation d’une clé de partition à haute cardinalité vous permet d’éviter cette limite de 20 Go en répartissant vos données dans un plus grand nombre de partitions logiques. Vous pouvez également utiliser des clés de partition hiérarchiques qui organisent les valeurs de clé de partition dans une hiérarchie pour éviter cette limite. Celles-ci sont traitées dans un autre parcours d’apprentissage.
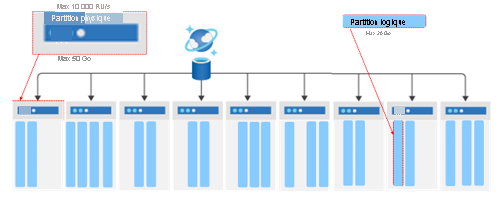
Une clé de partition offre un moyen de router les données d’une partition logique. Il s’agit d’une propriété qui existe au sein de chaque document dans votre conteneur qui route vos données. Un conteneur est une autre abstraction pour toutes les données stockées avec la même clé de partition. La clé de partition est définie quand vous créez un conteneur.
Dans l’exemple suivant, le conteneur a une clé de partition de /username.

Éviter les partitions chaudes
Quand vous modélisez des données pour Azure Cosmos DB, il est essentiel que la clé de partition que vous choisissez engendre une distribution uniforme des données et des requêtes sur les partitions logiques et les partitions physiques, par extension, de votre conteneur. Cela est particulièrement vrai quand les conteneurs croissent et comptent un nombre toujours plus grand de partitions physiques.
Si vous ne testez pas la conception de votre base de données en charge pendant le développement, un mauvais choix éventuel de clé de partition risque de ne pas être détecté avant que l’application soit en production et qu’un volume important de données ait déjà été écrit.
Quand les données ne sont pas partitionnées correctement, cela peut entraîner un problème de partitions à chaud. Les partitions à chaud empêchent la mise à l’échelle de la charge de travail de votre application et peuvent se manifester à la fois sur le stockage et le débit.
Partitions à chaud de stockage
Une partition à chaud sur le stockage se produit quand vous avez une clé de partition qui entraîne des modèles de stockage hautement asymétriques. Par exemple, considérez une application multilocataire qui utilise TenantId comme clé de partition avec six locataires : de A à F. Les locataires B, C, E et F sont très petits, alors que le locataire D comprend un peu plus de données. Cependant, l’Abonné A est massif et atteint rapidement la limite de 20 Go pour sa partition. Dans ce scénario, nous avons besoin de sélectionner une autre clé de partition qui répartira le stockage sur des partitions logiques supplémentaires.

Partitions à chaud de débit
Le débit peut être affecté par des partitions à chaud lorsque la plupart ou la totalité des requêtes vont vers la même partition logique.
Il est important de comprendre les modèles d’accès de votre application pour veiller à répartir aussi uniformément que possible les requêtes sur les valeurs de clé de partition. Quand le débit est provisionné pour un conteneur dans Azure Cosmos DB, il est alloué uniformément sur toutes les partitions physiques d’un conteneur.
Par exemple, si vous avez un conteneur avec 30 000 RU/s, cette charge de travail est répartie entre les trois partitions physiques pour les six locataires précédemment mentionnés. Ainsi, chaque partition physique obtient 10 000 RU/s. Si le locataire D consomme l’ensemble de ses 10 000 RU/s, son débit sera limité, car il ne peut pas consommer le débit alloué aux autres partitions. Cela entraîne des performances médiocres pour les locataires C et D, et laisse une capacité de calcul inutilisée dans les autres partitions physiques et les locataires restants. Au final, cette clé de partition génère une conception de base de données dans laquelle la charge de travail d’application ne peut pas être mise à l’échelle.

Quand les données et les requêtes sont réparties uniformément, la taille de la base de données peut augmenter, et ce d’une manière optimale qui permet d’utiliser entièrement le stockage et le débit. Cela permet d’atteindre les meilleures performances possibles et une efficacité optimale. En résumé, la conception de la base de données pourra évoluer.

Considérations relatives aux lectures et écritures
Lorsque vous choisissez une clé de partition, vous devez également déterminer si les données nécessitent beaucoup de lectures ou beaucoup d’écritures. Vous devez chercher à distribuer les demandes exigeantes en écritures avec une clé de partition de haute cardinalité.
Pour les charges de travail nécessitant beaucoup de lectures, vous devez vous assurer que les requêtes sont traitées par une seule partition ou un nombre limité de partitions en incluant une clause WHERE avec un filtre d’égalité sur la clé de partition, ou un opérateur IN sur un sous-ensemble de valeurs de clé de partition, dans vos requêtes.
Pour les scénarios où la charge de travail d’application est exigeante à la fois en écritures et en lectures, il existe une solution. Nous la découvrirons dans le prochain module.
L’illustration suivante montre un conteneur partitionné par nom d’utilisateur. Cette requête n’atteindra qu’une seule partition logique, de sorte que ses performances seront toujours bonnes.

Une requête filtrée sur une autre propriété, comme favoriteColor, s’étendrait sur toutes les partitions incluses dans le conteneur. Ce type de requête est également appelé requête inter-partitions. Une telle requête fonctionne comme prévu quand le conteneur est petit et occupe une seule partition. Toutefois, lorsque le conteneur croît ainsi que le nombre de partitions physiques, cette requête devient plus lente et plus coûteuse, car elle doit vérifier chaque partition pour obtenir des résultats, que la partition physique contienne des données associées à la requête ou non.

Choisir une clé de partition pour les clients
Maintenant que vous comprenez le partitionnement dans Azure Cosmos DB, nous pouvons passer au choix de la clé de partition pour nos données client. Comme nous l’avons vu précédemment, nous effectuons trois opérations concernant les clients : création d’un client, mise à jour d’un client et récupération d’un client. Dans ce cas, nous allons récupérer le client par son ID. Comme cette opération sera appelée le plus souvent, il est judicieux de choisir l’ID du client comme clé de partition pour le conteneur.

Vous pourriez peut-être craindre que le choix de l’ID en tant que clé de partition signifie que nous aurons autant de partitions logiques que de clients, puisque chaque partition logique ne contient qu’un seul document. Des millions de clients impliqueraient des millions de partitions logiques.
Soyez rassuré, cela ne pose aucun problème ! Les partitions logiques sont un concept virtuel et vous pouvez en avoir autant que vous voulez, leur nombre est illimité. Azure Cosmos DB va colocaliser plusieurs partitions logiques sur la même partition physique. À mesure que la taille ou le nombre des partitions logiques augmente, Cosmos DB les déplace vers de nouvelles partitions physiques, selon les besoins.