Modéliser de petites entités de recherche
Notre modèle de données comprend deux petites entités de données de référence, ProductCategory et ProductTag. Ces entités sont utilisées comme valeurs de référence et sont liées à d’autres entités via une 1:Many relationship.
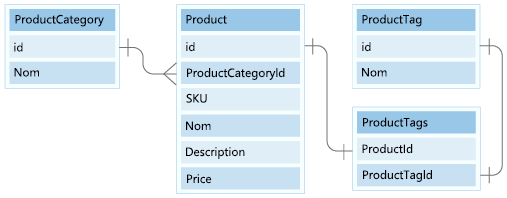
Dans cette unité, nous allons modéliser les entités ProductCategory et ProductTag dans notre modèle de document.
Modéliser les catégories de produits
Premièrement, pour les catégories, nous allons modéliser les données avec leurs colonnes id et name comme seules propriétés, puis les placer dans un nouveau conteneur appelé ProductCategory.
Ensuite, nous avons besoin de choisir une clé de partition. Examinons les opérations que nous avons besoin d’effectuer sur ces données.
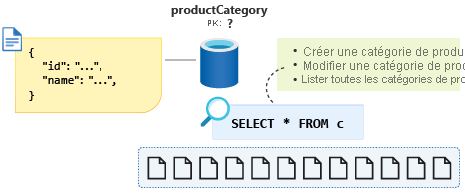
Nous allons créer une catégorie de produit, modifier une catégorie de produit et enfin, lister toutes les catégories de produits. La création et la modification de catégories de produits ne sont pas des opérations souvent exécutées. Notre application d’e-commerce liste souvent toutes les catégories de produits lorsque les clients visitent le site web. La dernière opération est donc celle que nous allons exécuter le plus.
La requête correspondant à cette dernière opération ressemblera à : SELECT * FROM c.
Avec id comme clé de partition sélectionnée, cette requête est désormais inter-partitions, même si nous souhaitons essayer d’optimiser ces opérations exigeantes en lectures et utiliser une seule partition, si possible. Nous savons également que les données de la catégorie de produits n’atteindront jamais 20 Go. Par conséquent, comment ces informations nous aideront à modéliser les données d’une manière qui se traduira par une seule requête de partition lorsque nous listerons toutes les catégories de produits.
Pour ramener de force cette petite quantité de données dans une partition unique, nous pouvons ajouter une propriété de discriminateur d’entité dans notre schéma et l’utiliser comme clé de partition pour ce conteneur. En affectant à cette propriété une valeur constante pour tous les documents de ce type dans le conteneur, nous nous assurons de disposer désormais d’une seule requête de partition. Dans ce cas, nous appellerons la propriété type et lui donnerons la valeur constante category. Notre requête ressemble maintenant à : SELECT * FROM c WHERE c.type = ”category”.

Modéliser des étiquettes de produit
Occupons-nous maintenant de l’entité ProductTag. Cette entité a une fonction quasiment identique à celle de l’entité ProductCategory que nous avons abordée dans la section précédente. Nous allons adopter la même approche ici et modéliser le document pour qu’il contienne les propriétés ID et name, et créer une propriété de discriminateur d’entité appelée type, cette fois avec la valeur constante tag. Créons un conteneur appelé ProductTag et choisissons type comme nouvelle clé de partition.

Certains trouvent que cette technique de modélisation des petites tables de choix est bizarre. Toutefois, en modélisant nos données ainsi, une autre optimisation devient possible, ce que nous allons voir dans le module suivant.