Définir l’architecture, les composants et les fonctionnalités de la déduplication des données.
La plupart des organisations et des entreprises, y compris Contoso, doivent gérer le traitement et le stockage d’un volume de données en constante évolution. Bien qu’il existe des solutions qui vous permettent de décharger et d’archiver des données dans le cloud, dans de nombreux cas, il est nécessaire de stocker ces données dans des centres de données locaux. Une gestion efficace du stockage de ces données requiert des outils appropriés. Lorsque vous utilisez Windows Server, vous avez la possibilité d’utiliser la déduplication des données.
Qu’est-ce que la déduplication des données ?
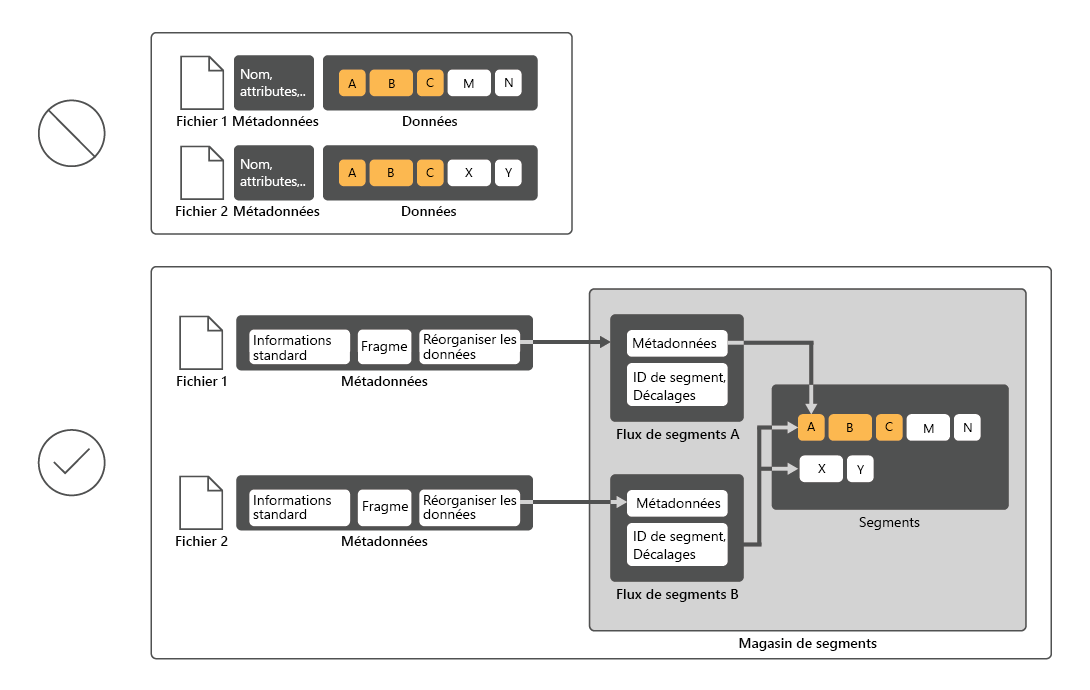
La déduplication des données est un service de rôle de Windows Server qui identifie et supprime les doublons au sein des données sans compromettre l’intégrité des données. Cela permet de stocker davantage de données et d’utiliser moins d’espace disque physique.
Pour réduire l’utilisation du disque, la déduplication des données analyse les fichiers, puis les divise en blocs et conserve une seule copie de chaque bloc. Après la déduplication, les fichiers ne sont plus stockés en tant que flux de données indépendants. Au lieu de cela, Déduplication des données remplace les fichiers par des stubs qui pointent vers les blocs de données qu’elle stocke dans un magasin de blocs commun. Le processus d’accès aux données dédupliquées est transparent pour les utilisateurs et les applications.
Dans de nombreux cas, la duplication des données augmente les performances globales du disque, car plusieurs fichiers peuvent partager un bloc mis en cache en mémoire. De cette façon, il est possible de récupérer des données à partir de ces fichiers en effectuant moins d’opérations de lecture, ce qui compense un faible impact sur les performances lors de la lecture de fichiers dédupliqués. La déduplication des données n’a aucun impact sur les performances des écritures sur le disque, car elle s’applique aux données qui se trouvent déjà sur le disque.
Quels sont les composants de la déduplication des données ?
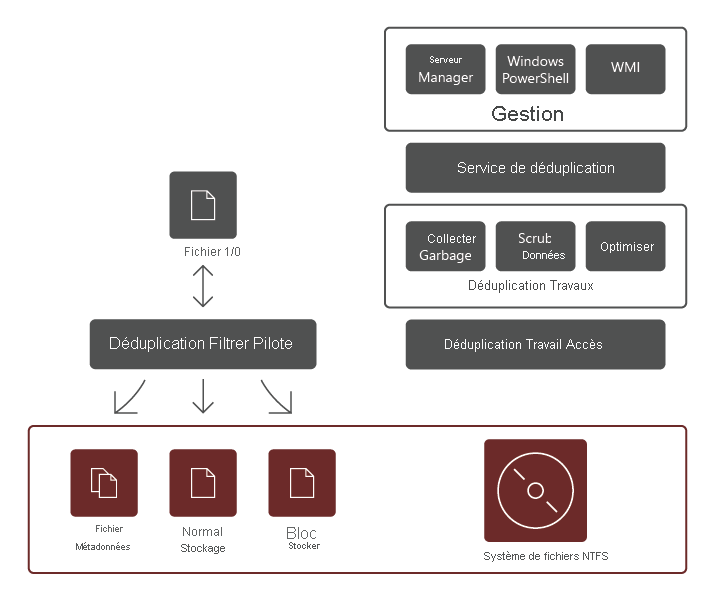
Le service de rôle de déduplication des données comprend les composants suivants :
- Pilote de filtre. Ce composant redirige les demandes de lecture vers les blocs qui font partie du fichier demandé. Chaque volume dispose d’un pilote de filtre.
- Service de déduplication. Ce composant gère les travaux suivants :
- Déduplication et compression. Ces travaux traitent les fichiers en fonction de la stratégie de déduplication des données pour le volume. Après l’optimisation initiale d’un fichier, si le fichier est modifié et qu’il atteint le seuil de stratégie de déduplication des données pour l’optimisation, il est de nouveau optimisé.
- Nettoyage de la mémoire. Ce travail traite les données supprimées ou modifiées sur le volume afin que les blocs de données qui ne sont plus référencés soient nettoyés, ce qui génère de l’espace disque libre. Par défaut, la collecte de déchets se déroule chaque semaine, mais vous pouvez également envisager de la déclencher après avoir supprimé de nombreux fichiers.
- Nettoyage. Ce travail repose sur des fonctionnalités de résilience telles que la validation de la somme de contrôle et la vérification de la cohérence des métadonnées pour identifier et, dans la mesure du possible, résoudre automatiquement les problèmes d’intégrité des données.
Remarque
En raison des fonctionnalités de validation supplémentaires, la déduplication peut détecter et signaler les premiers signes d’altération des données.
- Désoptimisation Ce travail inverse la déduplication sur tous les fichiers optimisés sur le volume. Parmi les scénarios courants d’utilisation de ce type de travail, citons la résolution des problèmes liés aux données dédupliquées ou à la migration de données vers un autre système qui ne prend pas en charge la déduplication des données.
Remarque
Avant de démarrer ce travail, vous devez utiliser l'applet de commande Windows PowerShell Disable-DedupVolume pour désactiver une activité supplémentaire de déduplication des données sur un ou plusieurs volumes.
Remarque
Après la désactivation de la déduplication des données, le volume reste dans l’état dédupliqué, et les données dédupliquées existantes restent accessibles. Toutefois, le serveur arrête d’exécuter des travaux d’optimisation pour le volume et ne déduplique pas les nouvelles données. Ensuite, vous pouvez utiliser le travail d’annulation de l’optimisation pour annuler les données dédupliquées existantes sur un volume. À la fin d'un travail de désoptimisation réussi, toutes les métadonnées de la déduplication des données sont supprimées du volume.
Important
Lors de l’utilisation du travail d’annulation de l’optimisation, assurez-vous que le volume qui héberge ces données dispose de suffisamment d’espace libre, car tous les fichiers dédupliqués reprendront leur taille d’origine.
Étendue de la déduplication des données
La déduplication des données traite toutes les données sur un volume sélectionné, à quelques exceptions près :
- Fichiers qui ne respectent pas la stratégie de déduplication que vous configurez.
- Fichiers dans des dossiers que vous excluez explicitement de l’étendue de la déduplication.
- Fichiers d’état du système.
- Autres flux de données.
- Fichiers chiffrés.
- Fichiers avec attributs étendus.
- Fichiers inférieurs à 32 Ko.
Remarque
À partir de Windows Server 2019, le système ReFS (Resilient File System) prend en charge la déduplication des données pour les volumes pouvant atteindre jusqu’à 64 téraoctets (To) de taille et les fichiers d’une taille maximale de 4 To. Il s’appuie également sur un magasin de blocs de taille variable qui comprend une compression facultative pour optimiser l’économie d’espace disque, tandis que l’architecture de post-traitement à plusieurs threads maintient l’impact sur les performances à un niveau minimal.