Définir les cas d’usage et l’interopérabilité de la déduplication des données.
Vos économies grâce à la déduplication des données varient en fonction du type de données, de la combinaison de données, de la taille des volumes et des fichiers contenus dans ces volumes. Vous avez la possibilité d’évaluer les économies par volume avant d’activer la déduplication.
Cas d’usage de la déduplication des données
La liste suivante répertorie les scénarios de déduplication classiques et leurs économies d’espace de volume respectives :
| Cas d’usage | Contenu | Espace disque gagné |
|---|---|---|
| Documents utilisateur | Publication ou partage de contenu de groupe, dossiers de base de l’utilisateur et redirection de profil pour accéder aux fichiers hors connexion | 30 à 50 pour cent |
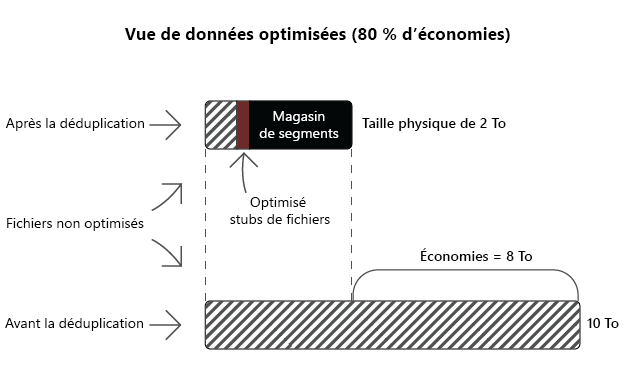
| Partages de déploiement de logiciels | Fichiers binaires logiciels, fichiers CAB, fichiers de symboles, images et mises à jour | 70 à 80 pour cent |
| Bibliothèques de virtualisation | stockage de fichiers de disque dur virtuel (fichiers .vhd et .vhdx) pour l’approvisionnement des hyperviseurs | 80 à 95 pour cent |
| Partage de fichiers général | combinaison de tous les types de données précédemment identifiés | 50 à 60 pour cent |
Cas d’utilisation de la déduplication des données recommandés
En s’appuyant sur les économies potentielles et l’utilisation typique des ressources dans Windows Server, les candidats au déploiement pour la déduplication sont classés comme idéaux, à évaluer ou non idéaux.
- Candidats idéaux à la déduplication :
- Serveurs de redirection de dossiers.
- Dépôt de virtualisation ou bibliothèque d’approvisionnement.
- Partages de déploiement logiciel.
- Volumes de sauvegarde Microsoft SQL Server et Microsoft Exchange Server.
- Fichiers sur les volumes partagés de cluster (CSV) des serveurs de fichiers avec montée en puissance parallèle (SOFS).
- Disques durs virtuels de sauvegarde virtualisée (par exemple, Microsoft System Center Data Protection Manager).
- Disques durs virtuels VDI de l’infrastructure de bureau virtualisé (uniquement VDI personnels).
Important
Dans la plupart des déploiements VDI, une planification spéciale est nécessaire pour prendre en compte les tempêtes de démarrage. Ce terme fait référence à la situation dans laquelle de nombreux utilisateurs essaient de se connecter simultanément à leur infrastructure VDI, généralement au début d’une journée de travail. Une tempête de démarrage impose une charge importante sur le système de stockage VDI et peut entraîner de longs délais pour les utilisateurs de la VDI lors de leur connexion initiale. Vous pouvez réduire l’impact des tempêtes de démarrage en activant la déduplication. De cette façon, les segments lus à partir du magasin de déduplication sur disque lors du démarrage des machines virtuelles sont mis en cache en mémoire. Par conséquent, les lectures suivantes n’ont pas besoin d’un accès fréquent aux segments sur le disque, car ceux-ci sont disponibles dans le cache.
Doit être évalué en fonction du contenu :
- Serveurs métier.
- Fournisseurs de contenu statique.
- Serveurs Web.
- HPC (calculs complexes).
Candidats non idéaux à la déduplication :
- Service de mise à jour du serveur Windows (WSUS).
- Volumes de base de données SQL Server et Exchange Server.
Évaluer les économies réalisées avec l’outil d'évaluation de la déduplication
Vous pouvez utiliser l’outil d’évaluation de la déduplication, DDPEval.exe, pour déterminer les économies attendues de la déduplication sur un volume particulier. DDPEval.exe prend en charge l’évaluation des lecteurs locaux et des partages distants mappés ou non.
Conseil
Lorsque la fonctionnalité de déduplication est installée, l’outil DDPEval.exe est automatiquement installé dans le répertoire \Windows\System32\.
Interopérabilité de la déduplication des données
Dans Windows Server, vous devez tenir compte des technologies associées et des problèmes potentiels suivants lors du déploiement de la déduplication des données :
Windows BranchCache
Vous pouvez optimiser l’accès aux données sur le réseau étendu (WAN) en activant BranchCache sur les systèmes d’exploitation clients Windows Server et Windows. Lors de la combinaison des deux technologies, tous les fichiers dédupliqués sont déjà indexés et hachés, ce qui accélère le traitement des requêtes de données provenant d’une filiale. Cela revient à préindexer ou préhacher un serveur prenant en charge BranchCache.
Remarque
BranchCache est une fonctionnalité qui permet de réduire l’utilisation des réseaux étendus (WAN) et d’améliorer la réactivité des applications réseau lors de l’accès au contenu situé dans un bureau central depuis des filiales. Lorsque vous activez BranchCache, une copie du contenu qui est récupérée du serveur Web ou du serveur de fichiers est mise en mémoire cache au niveau de la filiale. Si un autre client de la filiale demande le même contenu, le client peut le télécharger directement à partir du réseau local de la succursale plutôt que d’utiliser à nouveau le réseau étendu pour récupérer le contenu du bureau central.
Clusters de basculement
Les clusters de basculement prennent entièrement en charge la déduplication des données, ce qui signifie que les volumes dédupliqués basculent harmonieusement entre les nœuds du cluster. Toutefois, cela nécessite l’installation de la fonctionnalité de déduplication des données sur chaque nœud du cluster qui participe à un basculement.
Quotas FSRM
Même si vous ne devriez pas créer de quota inconditionnel sur un dossier racine de volume activé pour la déduplication, vous pouvez utiliser le Gestionnaire de ressources du serveur de fichiers (FSRM) pour créer un quota conditionnel dans ce scénario. Lorsque FSRM rencontre un fichier dédupliqué, il identifie la taille logique du fichier pour les calculs de quota. Par conséquent, l’utilisation du quota (y compris les seuils de quota) ne change pas lorsque la déduplication traite un fichier. Toutes les autres fonctionnalités de quota de FSRM, y compris les quotas conditionnels de racine du volume et les quotas dans les sous-dossiers, fonctionnent normalement lors de l’utilisation de la déduplication.
Remarque
FSRM est une suite d’outils qui vous permettent d’identifier, de contrôler et de gérer le type et la quantité de données stockées sur vos serveurs. FSRM vous permet de configurer des quotas inconditionnels ou conditionnels sur des dossiers et des volumes. Un quota inconditionnel empêche les utilisateurs d’enregistrer des fichiers une fois que la limite de quota a été atteinte, tandis qu’un quota conditionnel n’impose pas de limite de quota et génère une notification lorsque les données sur le volume atteignent un seuil.
Réplication DFS
La déduplication des données est compatible avec la réplication de système de fichiers distribués (DFS). L’optimisation ou la désoptimisation d’un fichier ne déclenche pas de réplication car le fichier ne change pas. La réplication DFS utilise la compression différentielle à distance (RPC), pas les blocs du magasin de blocs, pour réaliser des économies de réseau.