Explorer les options de haute disponibilité du serveur de fichiers Windows Server
Les services de fichiers représentent l’un des principaux types de charges de travail Windows Server. Leur disponibilité est bien souvent essentielle au bon déroulement des opérations de l’entreprise. Windows Server offre différentes méthodes pour garantir cette disponibilité.
Options de haute disponibilité du serveur de fichiers Windows
Pour implémenter des services de fichiers résilients sur Windows Server, vous pouvez utiliser la haute disponibilité inhérente aux rôles de clustering de basculement. Vous pouvez également assurer une résilience en répliquant le contenu des volumes hébergeant des partages de fichiers à l’aide d’un réplica de stockage.
Options de clustering de basculement du serveur de fichiers Windows Server
Vous pouvez déployer et configurer un serveur de fichiers en cluster à l’aide d’une des méthodes suivantes :
- Serveur de fichiers à usage général. Il s’agit du rôle de serveur de fichiers traditionnel, qui est déjà disponible depuis l’introduction du clustering de basculement dans le système d’exploitation Windows Server. Du point de vue de la disponibilité et de l’évolutivité, le rôle en cluster fonctionne en mode actif/passif, ce qui signifie qu’à un moment donné, les partages de fichiers correspondants (que l’on appelle simplement « partages de fichiers en cluster ») sont disponibles sur l’un des nœuds du cluster. Si ce nœud échoue, un autre nœud prend possession du rôle et de ses ressources, ce qui permet de maintenir la disponibilité des dossiers partagés. Les clients y accèdent cependant toujours via un nœud unique. Ce type d’implémentation de serveur de fichiers convient aux scénarios de travailleurs de l’information. Ce terme représente des scénarios d’entreprise standard, où les utilisateurs s’appuient sur des partages de fichiers pour stocker leurs dossiers de base, leurs profils d’itinérance et les données partagées avec leur service (y compris documents, feuilles de calcul et autres types de données non structurées ou semi-structurées).
- SOFS pour données d’application. Ce type de serveur de fichiers en cluster est destiné aux données d’application serveur, par exemple les fichiers de machine virtuelle Microsoft Hyper-V ou les fichiers de base de données SQL Server. Il offre un niveau supérieur de fiabilité, de disponibilité, de facilité de gestion et de performances, avec un rôle en cluster fonctionnant en mode actif/actif. Autrement dit, tous les partages de fichiers (que l’on appelle dans ce cas de figure « partages de fichiers scale-out » sont disponibles simultanément sur l’ensemble des nœuds du cluster. Cette approche est idéale lors du déploiement d’Hyper-V sur SMB (Server Message Block) ou de Microsoft SQL Server sur SMB.
Réplica de stockage
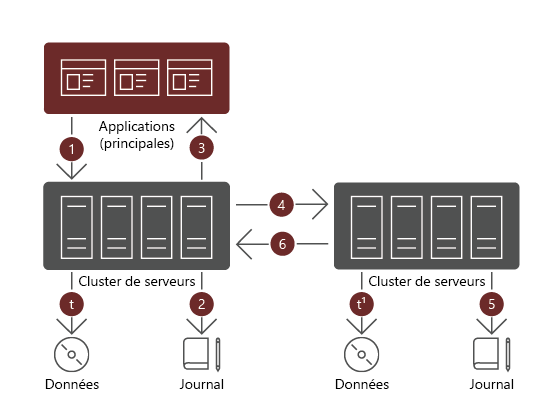
Le réplica de stockage est une technologie Windows Server qui permet une réplication unidirectionnelle et indépendante du stockage entre des volumes de stockage résidant sur des serveurs autonomes ou entre des serveurs en cluster, à des fins de haute disponibilité ou de récupération d’urgence. Selon la latence du réseau et la distance entre les serveurs, vous pouvez optez pour une réplication synchrone ou asynchrone. Avec le réplica de stockage, seul le volume source est accessible pendant les opérations normales de l’entreprise. En cas de défaillance, vous pouvez basculer vers le volume cible et le mettre en ligne.
Le réplica de stockage prend en charge trois scénarios :
- Serveur à serveur.
- Cluster à cluster.
- Cluster étendu.
Les scénarios de clustering vous permettent d’implémenter un serveur de fichiers pour une utilisation générale ou pour une application SOFS. Dans le cas d’une réplication serveur à serveur, le réplica de stockage fournit la résilience pour les partages de fichiers traditionnels et autonomes.
Réplication synchrone et asynchrone
Le réplica de stockage prend en charge deux types de réplication :
- La réplication synchrone réplique les volumes entre les sites à proximité les uns des autres. La réplication est cohérente en cas d’incident, ce qui garantit l’absence de perte de données au niveau du système de fichiers au cours d’un basculement.
- La réplication asynchrone permet la réplication sur des distances plus longues dans les cas où la latence réseau aller-retour dépasse 5 millisecondes (ms). Cependant, elle est sujette à des pertes de données. L’étendue de la perte de données dépend du décalage de la réplication entre les volumes source et cible.
Lors de l’utilisation d’une réplication synchrone, des données doivent être écrites correctement sur les deux volumes. Si ce n’est pas le cas, la charge de travail qui lance l’opération d’écriture doit retenter la même opération. Dans le cas d’une réplication synchrone, les données écrites sur les deux volumes sont identiques.

Utilisez la réplication synchrone lorsque vous devez impérativement éviter de perdre des données. La réplication synchrone nécessite une faible latence du réseau pour réduire le délai d’attente de l’accusé de réception de l’écriture distante. Cette exigence limite la distance entre les serveurs ou les clusters qui hébergent chaque volume.
Lors de l’utilisation d’une réplication asynchrone, une fois qu’une écriture de données est effectuée sur le volume principal, la charge de travail qui lance l’opération d’écriture reçoit une confirmation et peut poursuivre une autre opération d’E/S. Les écritures de données correspondantes interviennent ensuite sur le volume secondaire, sans affecter le volume principal.