Caractéristiques et cycle de vie d’un incident
Comme vous l’avez appris dans l’unité précédente, un incident est une perturbation de service qui impacte vos clients et utilisateurs finaux. Les incidents se présentent sous de nombreuses formes, depuis les ralentissements des performances qui agacent les utilisateurs (« la lenteur ») jusqu’aux incidents système qui rendent le service ou site complètement indisponible pendant une période donnée.
Caractéristiques d’un incident
Les incidents sont généralement inattendus et surviennent souvent au plus mauvais moment possible (par exemple, à 2 heures du matin ou alors que vous êtes profondément concentré sur un projet important). C’est la raison pour laquelle les incidents sont généralement redoutés et évités. Certaines personnes en arrivent même à minimiser leur importance. La pression interne est parfois si forte au sein d’une organisation qu’il est tentant de masquer ou de taire une perturbation par crainte des réprimandes.
À tout le moins, les incidents créent du travail non planifié et, puisque vous passez la majeure partie de votre temps à effectuer des tâches planifiées, en sachant pertinemment ce que vous êtes censé faire, vous considérez probablement les incidents comme quelque chose de négatif. Pourtant, il existe une autre façon de les envisager : les incidents sont de vrais « investissements » dans la valeur ajoutée que vous essayez d’apporter aux utilisateurs finaux. Quelle que soit la cause de l’incident ou l’ampleur de son impact, tous les incidents ont une chose en commun : ils peuvent offrir des expériences d’apprentissage précieuses.
Vous devez voir les incidents comme le pouls de vos systèmes. Ils vous en disent plus sur le système que ce que vous en saviez, et c’est une bonne chose. Lorsque vous avez une base solide de supervision et que vous en savez plus sur ce qui se passe dans votre système, cela génère inévitablement plus d’alertes et d’incidents, ainsi que d’opportunités de répondre. À tout le moins, les incidents vous indiquent ce qui se passe et augmentent donc votre sensibilisation opérationnelle. Dans un module précédent sur la supervision, nous avons suggéré qu’il s’agissait d’un précurseur important du travail de fiabilité.
Cycle de vie d’un incident
Si vous voulez élever le statut de votre équipe de réponse aux incidents au niveau des « équipes d’élite/très performantes », vous devez dépasser l’idée qu’une perturbation de service ou un incident s’inscrit dans une chronologie linéaire simple pour l’aborder dans une perspective cyclique.
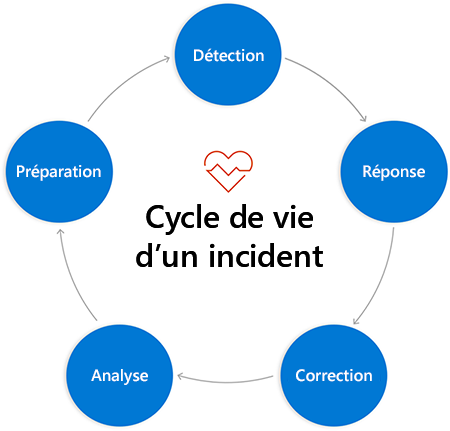
Vous pouvez décomposer le cycle de vie d’un incident en différentes phases qui se suivent logiquement dans un cycle qui se répète en boucle. Chaque fois que vous bouclez ce cycle (et vous allez le faire de nombreuses fois), si votre gestion est correcte, il est possible de revenir au début du cycle avec un meilleur insight sur vos systèmes. Avec une bonne volonté, vous pouvez aussi mieux vous préparer à répondre rapidement et efficacement au prochain incident.
Phases d’un incident
Les phases individuelles du processus de réponse aux incidents sont légèrement différentes selon le modèle que vous utilisez. Pour les besoins de ce module, nous dénombrons cinq phases par lesquelles vous devez passer pour répondre à un incident :
- Détection : Cette phase fait intervenir les connaissances en matière de supervision que vous avez acquises dans un module précédent de ce parcours d’apprentissage. Vos outils de supervision collectent les informations dans les journaux, analysent ces informations en fonction des objectifs orientés client que vous avez configurés et vous envoient des alertes actionnables pour vous informer qu’une intervention humaine est nécessaire.
- Réponse : Cette phase correspond à ce qui se produit une fois que votre équipe et vous avez reçu cette alerte. Nous allons examiner de façon plus approfondie cette phase dans le présent module et nous en dirons beaucoup plus dans un instant.
- Correction : Cette phase correspond au retour à la normale des systèmes. La façon de procéder dépend de la cause de la perturbation de service. Le rétablissement du service et sa mise à la disposition de vos clients est votre plus grande priorité. En revanche, votre travail ne s’arrête pas à la fin de cette phase.
- Analyse : Pour exploiter au mieux les incidents, vous devez en tirer des enseignements. Cette phase correspond au processus de collecte des informations sur ce qui s’est passé et à quel moment pendant l’incident. Elle vous permet aussi de tirer des enseignements en posant les bonnes questions. Pour traiter cette phase, un module entier existe sur ce qu’il est possible d’apprendre d’un échec.
- Préparation : Vous devez intégrer les leçons tirées de la phase d’analyse à votre pratique opérationnelle. S’il existe des éléments d’action susceptibles de permettre d’éviter une panne similaire à l’avenir, ils font également partie de cette phase.
Avant de créer un plan de réponse aux incidents, vous devez comprendre les caractéristiques et la valeur des incidents et vous familiariser avec les phases du cycle de vie d’un incident. L’étape suivante consiste à vérifier que votre stratégie de réponse repose sur des bases solides.