Scénarios d’ingestion de flux
Azure Synapse Analytics offre plusieurs façons d’analyser de grands volumes de données. Deux des approches les plus courantes de l’analytique données à grande échelle sont les suivantes :
- Entrepôts de données : bases de données relationnelles, optimisées pour le stockage distribué et le traitement des requêtes. Les données sont stockées dans des tables et interrogées à l’aide de SQL.
- Lacs de données : stockage de fichiers distribués dans lequel les données sont stockées sous forme de fichiers qui peuvent être traités et interrogés à l’aide de plusieurs runtimes, notamment Apache Spark et SQL.
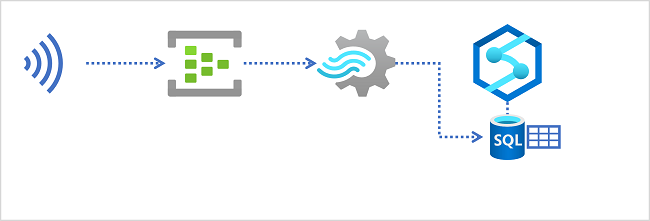
Entrepôts de données dans Azure Synapse Analytics
Azure Synapse Analytics fournit des pools SQL dédiés que vous pouvez utiliser pour implémenter des entrepôts de données relationnelles à l’échelle de l’entreprise. Les pools SQL dédiés sont basés sur une instance de traitement massivement parallèle (MPP) du moteur de base de données relationnelle Microsoft SQL Server dans lequel les données sont stockées et interrogées dans des tables.
Pour ingérer des données en temps réel dans un entrepôt de données relationnelles, votre requête Azure Stream Analytics doit écrire ses résultats dans une sortie qui référence la table dans laquelle vous souhaitez charger les données.
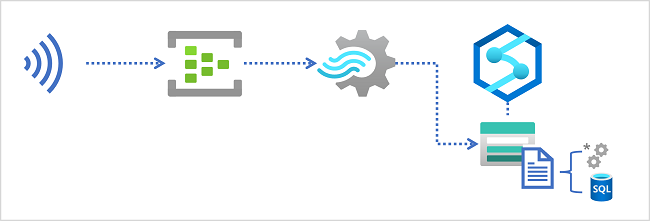
Lacs de données dans Azure Synapse Analytics
Un espace de travail Azure Synapse Analytics comprend généralement au moins un service de stockage utilisé comme lac de données. Le plus souvent, le lac de données est hébergé dans un compte Stockage Azure à l’aide d’un conteneur configuré pour prendre en charge Azure Data Lake Storage Gen2. Les fichiers du lac de données sont organisés hiérarchiquement dans des répertoires (dossiers) et peuvent être stockés dans plusieurs formats de fichiers, notamment du texte délimité (par exemple des valeurs séparées par des virgules, ou CSV), Parquet et JSON.
Lors de l’ingestion de données en temps réel dans un lac de données, votre requête Azure Stream Analytics doit écrire ses résultats dans une sortie qui référence l’emplacement dans le conteneur de stockage Azure Data Lake Gen2 où vous souhaitez enregistrer les fichiers de données. Les ingénieurs, les scientifiques et les analystes de données peuvent ensuite traiter et interroger les fichiers dans le lac de données en exécutant du code dans un pool Apache Spark ou en exécutant des requêtes SQL à l’aide d’un pool SQL serverless.