Grands modèles de langage (LLM) de GitHub Copilot
GitHub Copilot est alimenté par de grands modèles linguistiques (LLM) pour vous aider à écrire du code en toute transparence. Dans cette unité, nous allons nous concentrer sur la compréhension de l’intégration et de l’impact des LLM dans GitHub Copilot. Passons en revue les sujets suivants :
- Qu'est-ce que les LLM ?
- Rôle des LLM dans GitHub Copilot et la création des invites
- Réglage des LLM
- Réglage de LoRA
Qu'est-ce que les LLM ?
Les grands modèles linguistiques sont des modèles d'intelligence artificielle conçus et entraînés pour comprendre, générer et manipuler le langage humain. Ces modèles sont dotés de la capacité de gérer un large éventail de tâches impliquant du texte, grâce à la grande quantité de données de texte sur lesquelles ils sont entraînés. Voici quelques aspects fondamentaux à comprendre sur les LLM :
Volume de données d'entraînement
Les LLM sont exposés à de grandes quantités de texte provenant de sources diverses. Cette exposition leur permet d'avoir une compréhension large du langage, du contexte et des subtilités de diverses formes de communication.
Compréhension contextuelle
Ils excellent dans la génération de texte contextuellement pertinent et cohérent. Leur capacité à comprendre le contexte leur permet de fournir des contributions significatives, qu'il s'agit de terminer des phrases, des paragraphes ou même de générer des documents entiers qui sont contextuellement pertinents.
Intégration du Machine Learning et de l'IA
Les LLM reposent sur le Machine Learning et les principes d'intelligence artificielle. Il s'agit de réseaux neuronaux avec des millions, voire des milliards de paramètres affinés pendant le processus d'entraînement pour comprendre et prédire efficacement le texte.
Polyvalence
Ces modèles ne sont pas limités à un type spécifique de texte ou de langue. Ils peuvent être adaptés et affinés pour effectuer des tâches spécialisées, ce qui les rend hautement polyvalents et applicables dans différents domaines et langues.
Rôle des LLM dans GitHub Copilot et la création d'invites
GitHub Copilot utilise des LLM pour fournir des suggestions de code prenant en charge le contexte. Le LLM considère non seulement le fichier actuel, mais également d'autres fichiers et onglets ouverts dans l'environnement de développement intégré (IDE) pour générer des achèvements de code précis et pertinents. Cette approche dynamique garantit des suggestions personnalisées, améliorant votre productivité.
Réglage des LLM
Le réglage est un processus critique qui nous permet de personnaliser des grands modèles linguistiques (LLM) pré-entraînés pour des tâches ou des domaines spécifiques. Il implique l'entraînement du modèle sur un jeu de données plus petit et spécifique à une tâche, appelé jeu de données cible, tout en utilisant les connaissances et les paramètres obtenus à partir d'un jeu de données pré-entraîné volumineux, appelé modèle source.
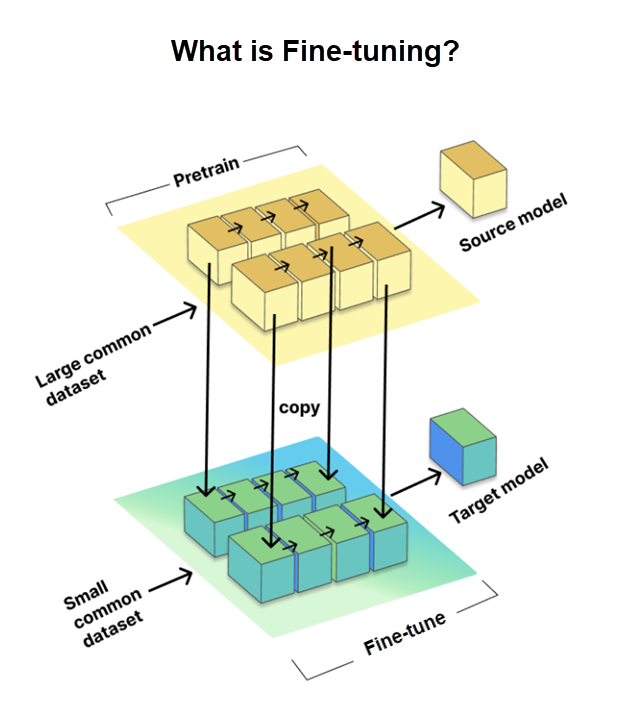
Le réglage est essentiel pour adapter les LLM pour des tâches spécifiques, ce qui améliore leurs performances. Toutefois, GitHub est allé plus loin en utilisant la méthode de réglage précis LoRA, dont nous parlerons plus loin.
Réglage de LoRA
Le réglage complet traditionnel signifie entraîner toutes les parties d'un réseau neuronal, ce qui peut être lent et fortement tributaire des ressources. Mais l’ajustement LoRA (adaptation de bas rang) est un choix judicieux. Il est utilisé pour améliorer l'efficacité des grands modèles linguistiques (LLM) pré-entraînés pour des tâches spécifiques sans avoir à refaire tout l'entraînement.
Voici comment fonctionne LoRA :
- Au lieu de tout changer, LoRA ajoute des parties plus petites qui peuvent être entraînées à chaque couche du modèle pré-entraîné.
- Le modèle d'origine reste le même, ce qui permet de gagner du temps et des ressources.
Qu'y a-t-il de si génial chez LoRA :
- Il bat d'autres méthodes d'adaptation telles que les adaptateurs et le réglage des préfixes.
- C'est comme obtenir de bons résultats avec moins de pièces mobiles.
En termes simples, le réglage de LoRA consiste à travailler plus intelligemment, pas plus dur, à améliorer les LLM pour vos exigences de codage spécifiques lors de l'utilisation de Copilot.