Utiliser Azure Data Lake Storage Gen2 dans les charges de travail d’analytique données
Azure Data Lake Store Gen2 est une technologie permettant plusieurs cas d’usage d’analytique données. Nous allons découvrir quelques types courants de charge de travail analytique et identifier comment Azure Data Lake Storage Gen2 les prend en charge à l’aide d’autres services Azure.
Traitement et analytique du Big Data
Les scénarios de Big Data font généralement référence à des charges de travail analytiques qui impliquent des volumes massifs de données dans une variété de formats devant être traités à une vélocité rapide, ce que l’on appelle les « trois V ». Azure Data Lake Storage Gen 2 fournit un magasin de données distribués évolutif et sécurisé sur lequel les services de Big Data comme Azure Synapse Analytics, Azure Databricks et Azure HDInsight peuvent appliquer des infrastructures de traitement des données comme Apache Spark, Hive et Hadoop. Le caractère distribué du stockage et du calcul de traitement permet d’effectuer des tâches en parallèle, et ainsi d’atteindre des performances et une scalabilité élevées même quand d’énormes quantités de données sont traitées.
Entrepôt de données
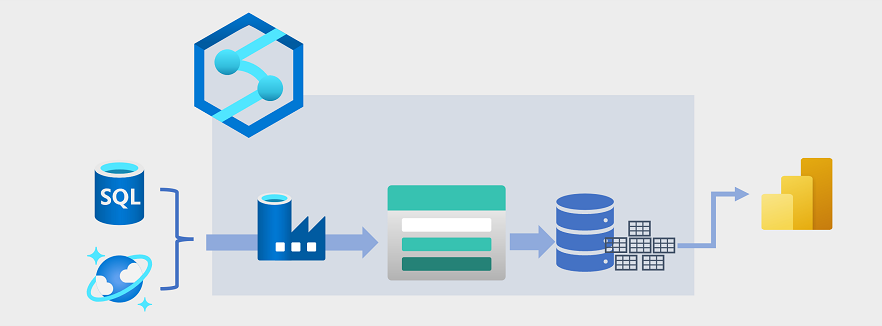
Ces dernières années, l’entreposage des données a évolué pour intégrer de grands volumes de données stockées sous forme de fichiers dans un lac de données avec des tables relationnelles dans un entrepôt de données. Dans une solution d’entreposage des données classique, les données sont extraites de magasins de données opérationnels, comme Azure SQL Database ou Azure Cosmos DB, puis transformées en structures mieux adaptées aux charges de travail analytiques. Les données sont souvent mises en lots dans un lac de données afin de faciliter le traitement distribué, puis elles sont chargées dans un entrepôt de données relationnel. Dans certains cas, l’entrepôt de données utilise des tables externes pour définir une couche de métadonnées relationnelles sur les fichiers du lac de données et créer une architecture hybride de type « data lakehouse » ou « base de données de lac ». L’entrepôt de données peut ensuite prendre en charge les requêtes analytiques pour la création de rapports et la visualisation.
Ce type d’architecture d’entreposage de données peut être implémenté de plusieurs manières. Le diagramme montre une solution dans laquelle Azure Synapse Analytics héberge des pipelines pour effectuer des processus extraction, transformation et chargement (ETL) à l’aide de la technologie Azure Data Factory. Ces processus extraient des données à partir de sources de données opérationnelles et les chargent dans un lac de données hébergé dans un conteneur Azure Data Lake Storage Gen2. Les données sont ensuite traitées et chargées dans un entrepôt de données relationnelles au sein d’un pool SQL dédié Azure Synapse Analytics, où elles peuvent prendre en charge la visualisation des données et la création de rapports à l’aide de Microsoft Power BI.
Analytique données en temps réel
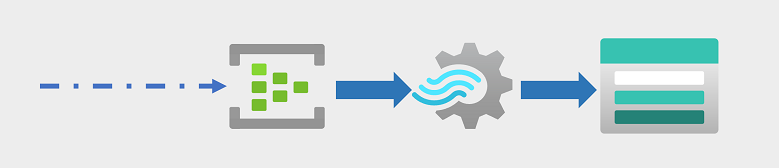
Les entreprises et les autres organisations ont de plus en plus besoin de capturer et d’analyser des flux perpétuels de données, ainsi que d’analyser les données en temps réel (ou en quasi temps réel). Ces flux de données peuvent être générés à partir d’appareils connectés (souvent appelés appareils Internet des objets ou IoT ) ou à partir de données générées par des utilisateurs dans des plateformes de réseaux sociaux ou d’autres applications. Contrairement aux charges de travail de traitement par lots traditionnelles, la diffusion en continu des données nécessite une solution en mesure de capturer et de traiter un flux de données dépendant des événements de données dès qu’ils surviennent.
Les événements de streaming sont souvent capturés dans une file d’attente afin d’être traités. De nombreuses technologies permettent d’effectuer cette tâche, notamment Azure Event Hubs comme illustré dans l’image. À partir de là, les données sont traitées, souvent pour agréger des données sur des fenêtres temporelles (par exemple pour compter le nombre de messages comprenant une étiquette donnée sur les réseaux sociaux toutes les cinq minutes ou pour calculer la lecture moyenne d’un capteur connecté à Internet par minute). Azure Stream Analytics permet de créer des travaux pour interroger et agréger les données des événements dès qu’ils surviennent, ainsi que pour écrire les résultats dans un récepteur de sortie. L’un de ces récepteurs est Azure Data Lake Storage Gen2 qui permet d’analyser et de visualiser les données capturées en temps réel.
Science des données et machine learning

La science des données implique l’analyse statistique de grands volumes de données, souvent à l’aide d’outils comme Apache Spark et de langages de script comme Python. Azure Data Lake Storage Gen 2 fournit un magasin de données cloud hautement évolutif adapté aux volumes de données qui sont nécessaires dans les charges de travail de science des données.
Le Machine Learning est une discipline de la science des données concernant l’apprentissage de modèles prédictifs. L’apprentissage du modèle nécessite des quantités de données considérables, ainsi que la capacité à traiter ces données efficacement. Azure Machine Learning est un service cloud permettant aux scientifiques des données d’exécuter du code Python dans des notebooks à l’aide de ressources de calcul distribuées allouées dynamiquement. Le calcul traite les données dans des conteneurs Azure Data Lake Storage Gen2 pour effectuer l’apprentissage des modèles. Ceux-ci peuvent ensuite être déployés en tant que services web de production pour prendre en charge les charges de travail d’analytique prédictive.