Gérer les similitudes entre les environnements à l’aide de modèles de pipeline
Quand vous déployez vos changements dans plusieurs environnements, les étapes impliquées dans le déploiement sur chaque environnement sont similaires ou identiques. Dans cette unité, vous allez apprendre à utiliser des modèles de pipeline pour éviter les répétitions et pour permettre la réutilisation de votre code de pipeline.
Déploiement sur plusieurs environnements
Après avoir parlé à vos collègues de l’équipe de site web, vous décidez d’utiliser le pipeline suivant pour le site web de votre entreprise de jouets :
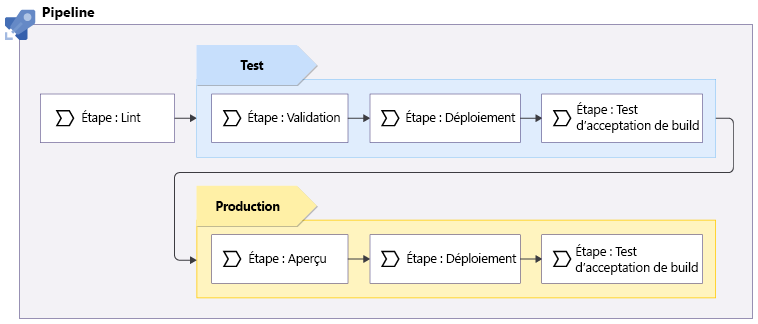
Le pipeline exécute le linter Bicep pour vérifier que le code Bicep est valide et respecte les bonnes pratiques.
La vérification lint se déroule sur le code Bicep sans qu’il soit nécessaire de se connecter à Azure, de sorte que le nombre d’environnements sur lesquels vous effectuez le déploiement n’a pas d’importance. La vérification s’exécute une seule fois.
Le pipeline est déployé dans l’environnement de test. Cette phase requiert les actions suivantes :
- Exécution de la validation préalable d’Azure Resource Manager.
- Déploiement du code Bicep.
- Exécution de certains tests par rapport à votre environnement de test.
Si une partie quelconque du pipeline échoue, le pipeline entier s’arrête pour vous permettre d’examiner et de résoudre le problème. En revanche, si tout fonctionne correctement, votre pipeline poursuit son déploiement dans votre environnement de production :
- Le pipeline exécute un index de préversion, qui exécute l’opération de simulation sur votre environnement de production pour répertorier les modifications qui seront apportées à vos ressources Azure de production. La phase de préversion valide également votre déploiement et vous n’avez donc pas besoin d’exécuter une phase de validation distincte pour votre environnement de production.
- Le pipeline s’interrompt pour la validation manuelle.
- Si l’approbation est reçue, le pipeline exécute les tests de détection de fumée et de déploiement par rapport à votre environnement de production.
Certaines de ces phases sont répétées entre vos environnements de test et de production, tandis que d’autres sont exécutées uniquement pour des environnements spécifiques :
| Étape | Environnements |
|---|---|
| Lint | Ni l’un, ni l’autre : le linting ne fonctionne pas sur un environnement |
| Valider | Test uniquement |
| Préversion | Production uniquement |
| Déployer | Les deux environnements |
| Test d’acceptation de build | Les deux environnements |
Lorsque vous devez répéter des étapes dans votre pipeline, vous pouvez essayer de copier et coller vos définitions d’étape. Toutefois, il est préférable d’éviter cette pratique. Il est facile de faire des erreurs subtiles lorsque vous dupliquez le code de votre pipeline, et des éléments peuvent aisément se désynchroniser. À l’avenir, lorsque vous devez apporter une modification aux étapes, vous devez vous souvenir d’appliquer la modification dans plusieurs emplacements.
Modèles de pipeline
Les modèles de pipeline vous permettent de créer des sections réutilisables de définitions de pipeline. Les modèles peuvent définir des étapes, des travaux ou même des phases entières. Vous pouvez utiliser des modèles pour réutiliser plusieurs fois des parties d’un pipeline dans un pipeline unique, voire même dans plusieurs pipelines. Vous pouvez également créer un modèle pour un ensemble de variables que vous souhaitez réutiliser dans plusieurs pipelines.
Un modèle est un simple fichier YAML qui contient votre contenu réutilisable. Un modèle simple pour une définition d’étape peut ressembler à ce qui suit et être enregistré dans un fichier nommé script.yml :
steps:
- script: |
echo Hello world!
Vous pouvez utiliser un modèle dans votre pipeline en utilisant le mot clé template dans l’emplacement où vous définisseriez normalement l’étape individuelle :
jobs:
- job: Job1
pool:
vmImage: 'windows-latest'
steps:
- template: script.yml
- job: Job2
pool:
vmImage: 'ubuntu-latest'
steps:
- template: script.yml
des modèles imbriqués
Vous pouvez également imbriquer des modèles dans d’autres modèles. Supposons que le fichier précédent était nommé jobs.yml et que vous créez un fichier nommé azure-pipelines.yml qui réutilise le modèle de travail dans plusieurs phases de pipeline :
trigger:
branches:
include:
- main
pool:
vmImage: ubuntu-latest
stages:
- stage: Stage1
jobs:
- template: jobs.yml
- stage: Stage2
jobs:
- template: jobs.yml
Lorsque vous imbriquez des modèles ou que vous les réutilisez plusieurs fois dans un pipeline individuel, vous devez veiller à ne pas utiliser accidentellement le même nom pour plusieurs ressources de pipeline. Par exemple, chaque travail au sein d’une phase a besoin de son propre identificateur. Par conséquent, si vous définissez l’identificateur de travail dans un modèle, vous ne pouvez pas le réutiliser plusieurs fois dans la même phase.
Lorsque vous travaillez avec des ensembles complexes de pipelines de déploiement, il peut être utile de créer un dépôt Git dédié pour vos modèles de pipeline partagés. Ensuite, vous pouvez réutiliser le même dépôt dans plusieurs pipelines, même s’ils sont destinés à des projets différents. Nous proposons un lien vers des informations supplémentaires dans le résumé.
Paramètres de modèle de pipeline
Les paramètres de modèle de pipeline facilitent la réutilisation de vos fichiers de modèle, car vous pouvez autoriser de petites différences dans vos modèles chaque fois que vous les utilisez.
Lorsque vous créez un modèle de pipeline, vous pouvez indiquer ses paramètres en haut du fichier :
parameters:
- name: environmentType
type: string
default: 'Test'
- name: serviceConnectionName
type: string
Vous pouvez définir autant de paramètres que nécessaire. Mais, comme avec les paramètres Bicep, essayez d’éviter un emploi excessif des paramètres de modèle de pipeline. Vous devez faciliter la réutilisation de votre modèle par une autre personne sans qu’elle ait besoin de spécifier un trop grand nombre de paramètres.
Chaque paramètre de modèle de pipeline a trois propriétés :
- Le nom du paramètre, que vous utilisez pour faire référence au paramètre dans vos fichiers de modèle.
- Le type du paramètre. Les paramètres prennent en charge plusieurs types de données différents, y compris les chaînes, les nombres et les booléens. Vous pouvez également définir des modèles plus complexes qui acceptent des objets structurés.
- La valeur par défaut du paramètre, qui est facultative. Si vous ne spécifiez pas de valeur par défaut, une valeur doit être fournie quand le modèle de pipeline est utilisé.
Dans l’exemple, le pipeline définit un paramètre de chaîne nommé environmentType, qui a la valeur par défaut de Test et un paramètre obligatoire nommé serviceConnectionName.
Dans votre modèle de pipeline, vous utilisez une syntaxe spéciale pour faire référence à la valeur du paramètre. Utilisez la macro ${{parameters.YOUR_PARAMETER_NAME}}, comme dans cet exemple :
steps:
- script: |
echo Hello ${{parameters.environmentType}}!
Vous transmettez la valeur des paramètres à un modèle de pipeline à l’aide du mot clé parameters, comme dans cet exemple :
steps:
- template: script.yml
parameters:
environmentType: Test
- template: script.yml
parameters:
environmentType: Production
Vous pouvez également utiliser des paramètres lorsque vous affectez des identificateurs à vos travaux et phases dans des modèles de pipeline. Cette technique est utile lorsque vous devez réutiliser le même modèle plusieurs fois dans votre pipeline, comme suit :
parameters:
- name: environmentType
type: string
default: 'Test'
jobs:
- job: Job1-${{parameters.environmentType}}
pool:
vmImage: 'windows-latest'
steps:
- template: script.yml
- job: Job2-${{parameters.environmentType}}
pool:
vmImage: 'ubuntu-latest'
steps:
- template: script.yml
Conditions
Vous pouvez utiliser des conditions de pipeline pour spécifier si une étape, un travail ou même une phase doivent s’exécuter en fonction d’une règle que vous spécifiez. Vous pouvez combiner des paramètres de modèle et des conditions de pipeline pour personnaliser votre processus de déploiement dans de nombreuses situations différentes.
Par exemple, imaginez que vous définissez un modèle de pipeline qui exécute des étapes de script. Vous envisagez de réutiliser le modèle pour chacun de vos environnements. Quand vous déployez votre environnement de production, vous voulez exécuter une autre étape. Voici comment y parvenir à l’aide de la macro if et de l’opérateur eq (est égal à) :
parameters:
- name: environmentType
type: string
default: 'Test'
steps:
- script: |
echo Hello ${{parameters.environmentType}}!
- ${{ if eq(parameters.environmentType, 'Production') }}:
- script: |
echo This step only runs for production deployments.
La condition se traduit alors par : si la valeur du paramètre environmentType est égale à Production, exécutez les étapes suivantes.
Conseil
Soyez attentif à l’identification du fichier YAML quand vous utilisez des conditions comme dans l’exemple. Les étapes auxquelles la condition s’applique doivent être mises en retrait d’un niveau supplémentaire.
Vous pouvez également spécifier la propriété condition sur une phase, un travail ou une étape. Voici un exemple qui montre comment vous pouvez utiliser l’opérateur ne (différent de) pour spécifier une condition comme si la valeur du paramètre environmentType est différente de Production, exécutez les étapes suivantes :
- script: |
echo This step only runs for non-production deployments.
condition: ne('${{ parameters.environmentType }}', 'Production')
Bien que les conditions soient un moyen d’ajouter de la flexibilité à votre pipeline, essayez de ne pas en utiliser trop. Elles compliquent votre pipeline et compliquent la compréhension de son flux. S’il existe plusieurs conditions dans votre modèle de pipeline, le modèle peut ne pas être la meilleure solution pour le workflow que vous envisagez d’exécuter et vous devrez peut-être reconcevoir votre pipeline.
De plus, envisagez d’utiliser des commentaires YAML pour expliquer les conditions que vous utilisez et tous les autres aspects de votre pipeline qui peuvent nécessiter plus d’explications. Les commentaires aident à faciliter la compréhension et l’utilisation de votre pipeline à l’avenir. Des exemples de commentaires YAML sont présentés dans les exercices de ce module.