Inscrire et servir des modèles avec MLflow
L’inscription de modèle permet à MLflow et Azure Databricks de suivre les modèles, ce qui est important pour deux raisons :
- L’inscription d’un modèle vous permet de servir le modèle pour le temps réel, la diffusion en continu ou l’inférence par lot. L’inscription facilite le processus d’utilisation d’un modèle formé, car les scientifiques de données n’ont pas besoin de développer le code de l’application. Le processus de service génère ce wrapper et expose une API REST ou une méthode pour le scoring par lot automatiquement.
- L’inscription d’un modèle vous permet de créer de nouvelles versions de ce modèle au fil du temps, vous permettant de suivre les modifications de modèle et même d’effectuer des comparaisons entre différentes versions historiques des modèles.
Inscription d’un modèle
Lorsque vous exécutez une expérience pour entraîner un modèle, vous pouvez enregistrer le modèle lui-même dans le cadre de l’exécution de l’expérience, comme illustré ici :
with mlflow.start_run():
# code to train model goes here
# log the model itself (and the environment it needs to be used)
unique_model_name = "my_model-" + str(time.time())
mlflow.spark.log_model(spark_model = model,
artifact_path=unique_model_name,
conda_env=mlflow.spark.get_default_conda_env())
Lorsque vous passez en revue l’exécution de l’expérience, y compris les métriques journalisées qui indiquent dans quelle mesure le modèle prédit correctement, le modèle est inclus dans les artefacts d’exécution. Vous pouvez ensuite sélectionner l’option permettant d’inscrire le modèle à l’aide de l’interface utilisateur dans la visionneuse d’expériences.
Si vous souhaitez inscrire le modèle sans examiner les métriques dans l’exécution, vous pouvez également inclure le paramètre registered_model_name dans la méthode log_model ; dans ce cas, le modèle est automatiquement inscrit pendant l’exécution de l’expérience.
with mlflow.start_run():
# code to train model goes here
# log the model itself (and the environment it needs to be used)
unique_model_name = "my_model-" + str(time.time())
mlflow.spark.log_model(spark_model=model,
artifact_path=unique_model_name
conda_env=mlflow.spark.get_default_conda_env(),
registered_model_name="my_model")
Vous pouvez inscrire plusieurs versions d’un modèle, ce qui vous permet de comparer les performances des versions de modèle sur une période donnée avant de déplacer toutes les applications clientes vers la version la plus performante.
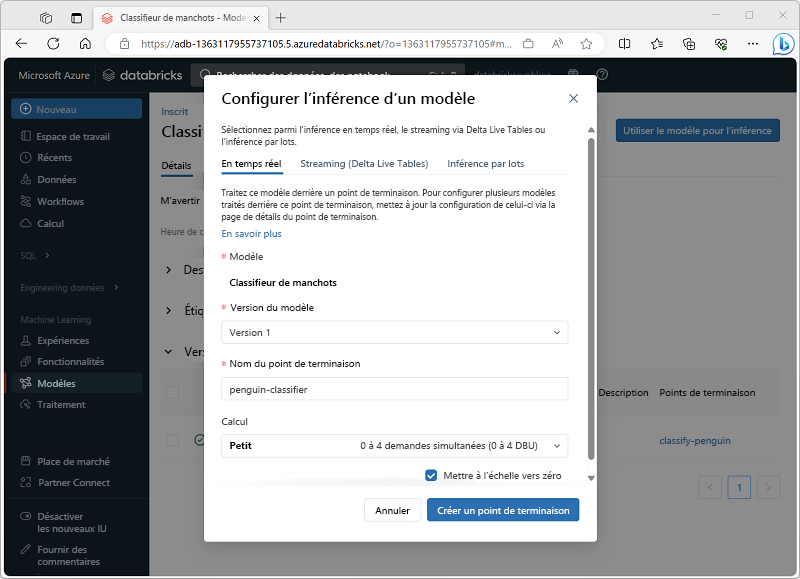
Utilisation d’un modèle pour l’inférence
Le processus d’utilisation d’un modèle pour prédire des étiquettes à partir de nouvelles données de caractéristique est appelé inférence. Vous pouvez utiliser MLflow dans Azure Databricks pour rendre des modèles disponibles pour l’inférence des manières suivantes :
- Héberger le modèle en tant que service en temps réel avec un point de terminaison HTTP sur lequel les applications clientes peuvent effectuer des requêtes REST.
- Utilisez le modèle pour effectuer une inférence de diffusion en continu perpétuelle d’étiquettes sur la base d’une table delta de caractéristiques, en écrivant les résultats dans une table de sortie.
- Utiliser le modèle pour l’inférence par lots basée sur une table delta, en écrivant les résultats de chaque opération de lot dans un dossier spécifique.
Vous pouvez déployer un modèle pour l’inférence à partir de sa page dans la section Modèles du portail Azure Databricks, comme illustré ici :