Concevoir une stratégie de pipeline et de contrôle de version
Lorsque vous commencez à publier du code Bicep réutilisable, vous utilisez probablement une approche manuelle. Il est facile pour vous de déterminer le fichier Bicep que vous devez publier, et vous avez probablement un processus manuel pour incrémenter le numéro de version.
Lorsque vous automatisez le processus de publication, vous devez réfléchir à la façon d’automatiser ces étapes. Dans cette unité, vous allez apprendre à adopter un système de contrôle de version qui communique les modifications que vous apportez à votre code. Vous découvrirez également comment vous pouvez étendre vos pipelines pour publier uniquement le code attendu.
Numéros de version
Dans les modules de formation Microsoft Learn précédents, vous avez découvert l’importance du contrôle de version pour les specs de modèle et les modules Bicep. Vous pouvez choisir parmi de nombreuses approches de contrôle de version différentes. Dans de nombreuses situations, il est recommandé d’utiliser un système de contrôle de version en plusieurs parties. Un système de contrôle de version en plusieurs parties se compose d’une version majeure, d’une version mineure et d’un numéro de révision, comme dans l’exemple suivant :
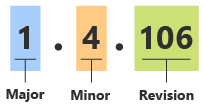
Dans l’exemple précédent, la version principale est 1, la version mineure est 4 et le numéro de révision est 106.
Les modifications apportées aux différentes parties des numéros de version communiquent des informations importantes sur les types de modifications dans le code :
Chaque fois que vous apportez un changement cassant, vous devez incrémenter le numéro de version principale. Par exemple, supposons que vous ajoutez un nouveau paramètre obligatoire ou supprimez un paramètre de votre fichier Bicep. Il s’agit d’exemples de changements cassants, car Bicep exige que les paramètres obligatoires soient spécifiés au moment du déploiement et n’autorise pas la définition de valeurs pour des paramètres inexistants. Par conséquent, vous devez mettre à jour le numéro de version principale.
Chaque fois que vous ajoutez quelque chose de nouveau au code, mais qu’il ne s’agit pas d’un changement cassant, vous devez incrémenter le numéro de version mineure. Par exemple, supposons que vous ajoutez un nouveau paramètre facultatif avec une valeur par défaut. Les paramètres facultatifs ne sont pas des changements cassants. Vous devez donc mettre à jour le numéro de version mineure.
Chaque fois que vous apportez des correctifs de bogues rétrocompatibles ou d’autres modifications qui n’affectent pas le fonctionnement du code, vous devez incrémenter le numéro de révision. Par exemple, supposons que vous refactorisez votre code Bicep pour améliorer l’utilisation des variables et des expressions. Si la refactorisation ne modifie pas du tout le comportement de votre code Bicep, vous mettez à jour le numéro de révision.
Votre pipeline peut également définir automatiquement le numéro de révision. Le numéro de build du pipeline peut être utilisé comme numéro de révision. Cette convention permet de garantir que vos numéros de version sont toujours uniques, même si vous ne mettez pas à jour les autres composants de vos numéros de version.
Par exemple, supposons que vous utilisez un module Bicep précédemment publié avec un numéro de version de 2.0.496. Vous voyez qu’une nouvelle version du module est disponible avec le numéro de version 2.1.502. La seule modification significative est le numéro de version mineure, ce qui indique que vous ne devez pas vous attendre à un changement cassant lorsque vous utilisez la nouvelle version.
Notes
Le contrôle de version sémantique est une structure formalisée du contrôle de version qui est similaire au contrôle de version en plusieurs parties. Le contrôle de version sémantique inclut des composants supplémentaires dans le numéro de version, ainsi que des règles strictes sur le moment où vous devez définir ou réinitialiser chaque composant. Vous trouverez des liens vers des informations supplémentaires sur le contrôle de version sémantique dans le récapitulatif.
Votre équipe doit décider comment définir une modification cassante pour le contrôle de version. Par exemple, supposons que vous générez un module Bicep qui déploie un compte de stockage. Vous mettez maintenant à jour le fichier Bicep pour activer les points de terminaison privés sur votre compte de stockage. Vous ajoutez en même temps une zone DNS privée à votre fichier Bicep.
Dans cet exemple, vous pouvez apporter la modification sans affecter les paramètres ou les sorties du fichier Bicep. De cette façon, il se peut qu’une personne qui déploie le fichier ne remarque pas que quelque chose est différent. Toutefois, cette modification introduit une différence significative dans le comportement de vos ressources. Vous pouvez donc décider de la traiter comme une mise à jour de version majeure.
Vous pouvez également choisir d’utiliser une stratégie de contrôle de version plus simple, comme l’utilisation du numéro de build du pipeline comme numéro de version. Bien que cette approche soit plus facile à implémenter, cela signifie que vous ne pouvez pas communiquer efficacement les différences entre les versions à toute personne qui utilise votre code.
Versions et pipelines
Lorsque vous publiez votre code de manière interactive, par exemple à l’aide d’Azure CLI, vous pensez probablement au numéro de version que vous attribuez à votre module ou spec de modèle lors de sa publication. Toutefois, dans un pipeline de déploiement automatisé, vous devez modifier votre approche pour attribuer des numéros de version. Votre pipeline ne peut pas détecter automatiquement les changements cassants ou vous conseiller lorsque vous devez incrémenter vos numéros de version majeure ou mineure. Prenez soigneusement en compte le contrôle de version avant de publier le module ou la spec de modèle.
Une approche consiste à stocker un fichier de métadonnées avec votre code Bicep, comme illustré dans le diagramme suivant :
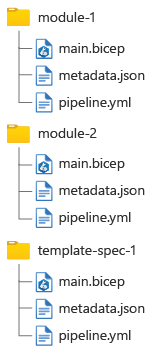
Chaque fois que vous mettez à jour votre code Bicep, vous mettez à jour les informations de version dans le fichier de métadonnées correspondant. Vérifiez que vous identifiez correctement les changements cassants et non cassants afin de pouvoir incrémenter correctement les numéros de version.
Conseil
Si votre équipe passe en revue votre code Bicep à l’aide de demandes de tirage, demandez aux réviseurs de vérifier si les modifications apportées à votre code nécessitent la modification de vos numéros de version majeure ou mineure.
Vous verrez comment utiliser un fichier de métadonnées dans l’exercice suivant.
Combien de pipelines ?
Il est courant de créer une collection de modules et de specs de modèle. Souvent, il est judicieux de conserver ce code dans le même dépôt Git.
En utilisant des filtres de chemin d’accès dans Azure Pipelines, vous pouvez créer des pipelines distincts pour chaque module ou spec de modèle au sein de votre dépôt. Cette approche vous permet d’éviter de publier une nouvelle version de chaque fichier Bicep dans le dépôt chaque fois que vous modifiez un fichier. Vous pouvez utiliser des modèles de pipeline pour définir les étapes de votre pipeline dans un fichier centralisé, ce qui permet d’avoir un pipeline léger pour chaque module ou spec de modèle.
Par exemple, supposons que vous disposez d’une structure de fichiers similaire à celle illustrée précédemment. Vous pouvez configurer trois pipelines distincts, un pour chaque fichier Bicep. Sélectionnez chaque onglet pour afficher la définition de pipeline correspondante et son filtre de chemin d’accès :
trigger:
batch: true
branches:
include:
- main
paths:
include:
- 'module-1/**'
stages:
- template: pipeline-templates/publish-module.yml
parameters:
path: 'module-1/main.bicep'
Supposons que vous modifiez uniquement le fichier module-2/main.bicep. Seul le pipeline pour le module 2 s’exécute. Toutefois, si vous modifiez plusieurs fichiers dans la même validation, chacun des pipelines appropriés est déclenché.
Notes
L’approche de création d’un pipeline pour chacun de vos fichiers Bicep réutilisables est simple et flexible. Mais cela peut devenir fastidieux lorsque vous avez un grand nombre de fichiers Bicep, ou si vous ne souhaitez pas conserver des pipelines distincts pour chaque module et spec de modèle.
Vous pouvez également écrire des scripts dans votre pipeline pour rechercher le code modifié et publier uniquement ces fichiers. Il s’agit d’une approche plus complexe qui dépasse le cadre de ce module Microsoft Learn.
Environnements pour le code Bicep réutilisable
Lorsque vous effectuez un déploiement sur Azure à l’aide de Bicep, il est courant d’utiliser plusieurs environnements pour vous aider à valider et tester votre code avant sa publication dans un environnement de production. Dans les modules de formation Microsoft Learn précédents, vous avez appris à utiliser plusieurs environnements à partir d’un pipeline de déploiement.
Certaines organisations appliquent les mêmes principes aux modules Bicep et aux specs de modèle. Par exemple, vous pouvez tout d’abord publier de nouvelles versions de vos modules dans un registre hors production afin que les utilisateurs de chaque module puissent essayer les nouvelles versions. Ensuite, après qu’ils se déconnectent des modifications, vous pouvez publier les modules dans le registre de production de votre organisation.
Comme les déploiements classiques, vous pouvez utiliser des travaux et des modèles de pipeline pour définir la séquence de déploiement dans vos environnements. Dans ce module Microsoft Learn, nous publions dans un seul environnement pour simplifier le pipeline.
Lorsque vous consommez des modules à partir d’un registre ou utilisez une spec de modèle comme module Bicep, vous pouvez utiliser des alias. Au lieu de spécifier le nom du registre ou l’emplacement de la spec de modèle à chaque fois que vous définissez un module, vous utilisez son alias.
En utilisant des alias, vous pouvez faciliter le fonctionnement de votre processus de déploiement dans plusieurs environnements. Par exemple, lorsque vous définissez un module, vous pouvez utiliser un alias au lieu d’un nom de registre. Ensuite, vous pouvez concevoir un pipeline de déploiement pour configurer l’alias à mapper à :
- Un registre de modules de développement lorsque vous effectuez un déploiement dans un environnement de bac à sable.
- Un registre de production lorsque vous effectuez un déploiement sur d’autres environnements.
Notes
Les alias ne s’appliquent pas lorsque vous publiez. Ils fonctionnent uniquement lorsque vous utilisez des specs de modèle ou des modules dans un fichier Bicep.