Exercice – CREATE EXTERNAL TABLE AS SELECT
Dans cet exercice, vous utilisez CREATE EXTERNAL TABLE AS SELECT (CETAS) pour :
- Exporter une table au format Parquet.
- Déplacez les données froides hors d’une base de données vers le stockage.
- Créez une table externe pour accéder aux données externes exportées.
- Utilisez des vues ou des recherches par caractères génériques comme stratégies de requête.
- Limitez les requêtes à l’aide de l’élimination des dossiers et des informations de métadonnées pour améliorer les performances.
Conditions préalables
- Instance SQL Server 2025 avec une connectivité Internet et le service de requête PolyBase pour les données externes installées et activées comme pour les exercices précédents.
- L’exemple de base de données AdventureWorks2022 restauré sur votre serveur à utiliser pour des exemples de données.
- Un compte stockage Azure avec un conteneur de stockage Blob nommé
datacréé. Pour créer le stockage, consultez Démarrage rapide : Charger, télécharger et répertorier des objets blob avec le portail Azure. - Le rôle RBAC Azure Contributeur aux données blob du stockage attribué dans Azure. Pour plus d’informations, consultez Affecter un rôle Azure pour accéder aux données de blob.
- Un jeton SAS de conteneur blob créé avec les autorisations READ, WRITE, LIST et CREATE à utiliser pour CETAS. Pour créer le jeton SAP, consultez Créer des jetons de signature d’accès partagé (SAP) pour vos conteneurs de stockage.
Utiliser CETAS pour exporter une table au format Parquet
Imaginez que vous travaillez avec une équipe d’analytique métier qui souhaite exporter des données antérieures à 2012 d’une table SQL Server vers un conteneur Stockage Blob Azure. Ils souhaitent exécuter leurs requêtes de rapport sur ces données exportées plutôt que d’interroger directement SQL Server.
Activez CETAS sur l’instance SQL Server.
EXEC SP_CONFIGURE @CONFIGNAME = 'ALLOW POLYBASE EXPORT', @CONFIGVALUE = 1;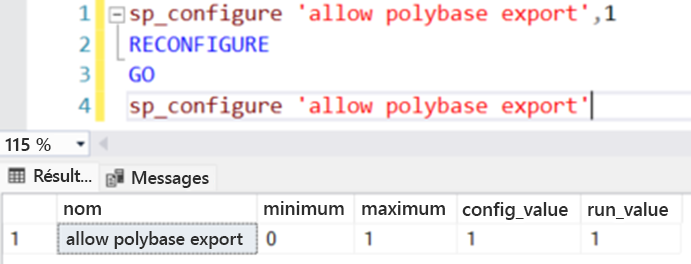
Exécutez la requête d’exploration de données suivante pour comprendre les données que vous souhaitez exporter. Dans ce cas, vous recherchez des données de 2012 ou antérieures. Vous souhaitez exporter toutes les données de 2011 et 2012.
-- RECORDS BY YEARS SELECT COUNT(*) AS QTY, DATEPART(YYYY, [DUEDATE]) AS [YEAR] FROM [PURCHASING].[PURCHASEORDERDETAIL] GROUP BY DATEPART(YYYY, [DUEDATE]) ORDER BY [YEAR]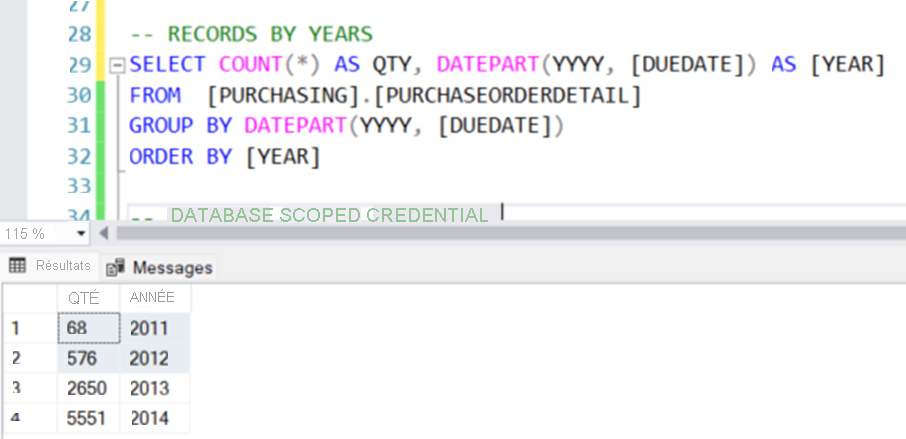
Créez une clé principale de base de données pour la base de données, comme dans les exercices précédents.
Use AdventureWorks2022 DECLARE @randomWord VARCHAR(64) = NEWID(); DECLARE @createMasterKey NVARCHAR(500) = N' IF NOT EXISTS (SELECT * FROM sys.symmetric_keys WHERE name = ''##MS_DatabaseMasterKey##'') CREATE MASTER KEY ENCRYPTION BY PASSWORD = ' + QUOTENAME(@randomWord, '''') EXEC sp_executesql @createMasterKey; SELECT * FROM sys.symmetric_keys;Créez les informations d’identification délimitées à la base de données et la source de données externe. Remplacez les espaces réservés
<sas_token>et<storageccount>par le compte de stockage et le jeton SAS que vous avez créés dans Azure.-- DATABASE SCOPED CREDENTIAL CREATE DATABASE SCOPED CREDENTIAL blob_storage WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = '<sas_token>'; -- AZURE BLOB STORAGE DATA SOURCE CREATE EXTERNAL DATA SOURCE ABS_Data WITH ( LOCATION = 'abs://<storageaccount>.blob.core.windows.net/data/chapter3' ,CREDENTIAL = blob_storage );Créez le format de fichier externe pour Parquet.
-- PARQUET FILE FORMAT CREATE EXTERNAL FILE FORMAT ffParquet WITH (FORMAT_TYPE = PARQUET);Créez la table externe à l’aide de CETAS. La requête suivante crée une table externe nommée
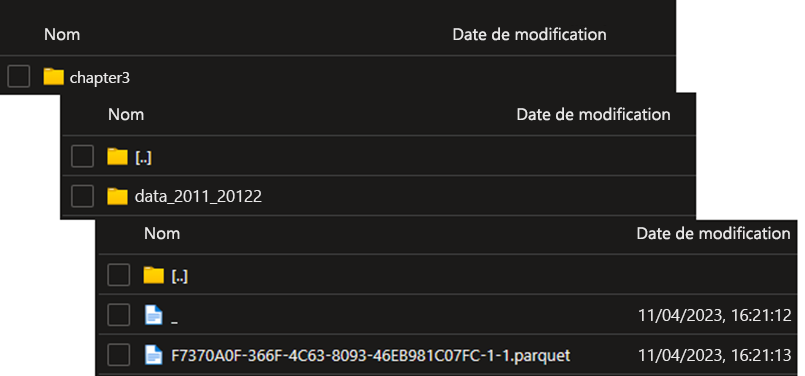
ext_data_2011_2012et exporte toutes les données de 2011 et 2012 vers l’emplacement spécifié par la sourceABS_Datade données.CREATE EXTERNAL TABLE ex_data_2011_2012 WITH( LOCATION = 'data_2011_20122', DATA_SOURCE = ABS_Data, FILE_FORMAT = ffParquet )AS SELECT [PurchaseOrderID] ,[PurchaseOrderDetailID] ,[DueDate] ,[OrderQty] ,[ProductID] ,[UnitPrice] ,[LineTotal] ,[ReceivedQty] ,[RejectedQty] ,[StockedQty] ,[ModifiedDate] FROM [PURCHASING].[PURCHASEORDERDETAIL] WHERE YEAR([DUEDATE]) < 2013 GOVérifiez votre stockage Blob Azure dans le portail Azure. Vous devez voir que la structure suivante a été créée. SQL Server 2025 crée automatiquement le nom de fichier en fonction de la quantité de données qu’il exporte et du format de fichier.
Vous pouvez désormais accéder à la table externe comme une table classique.
SELECT * FROM ex_data_2011_2012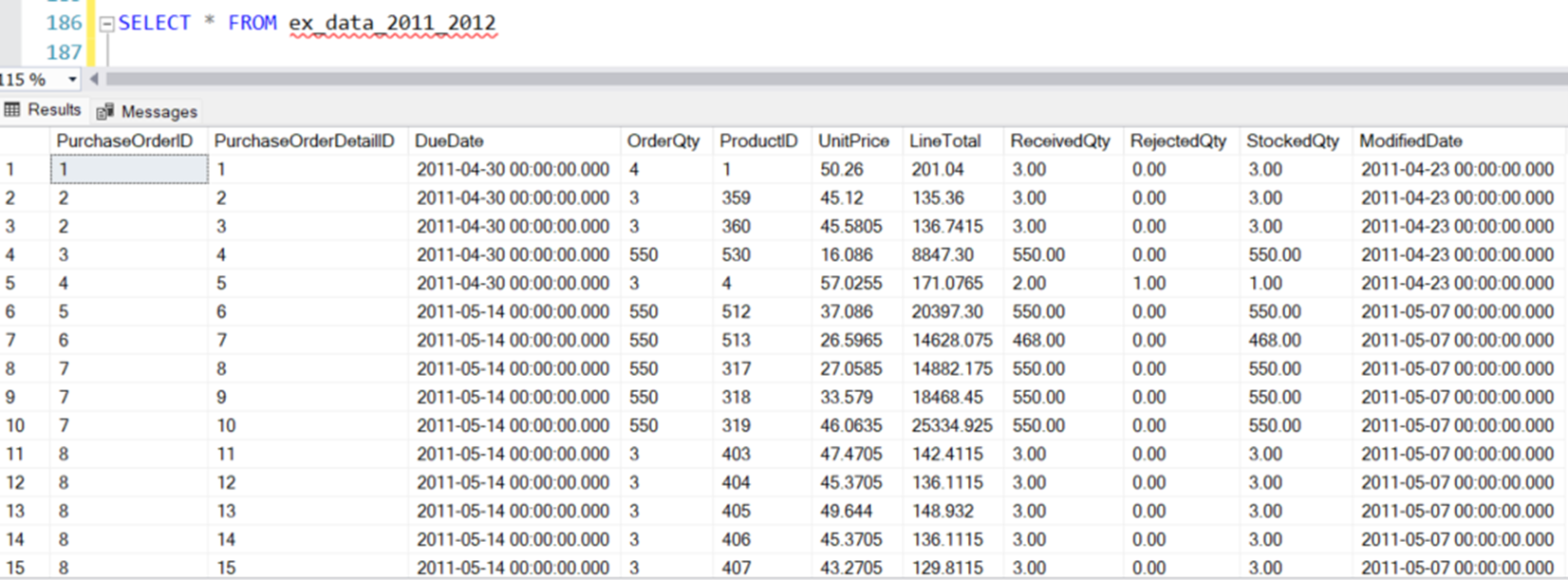
Les données sont désormais exportées vers Parquet et sont facilement accessibles via la table externe. L’équipe d’analyse métier peut interroger la table externe ou diriger leur outil de création de rapports vers le fichier Parquet.
Utiliser CETAS pour déplacer des données froides hors de la base de données
Pour conserver les données gérables, votre entreprise décide de déplacer des données antérieures à 2014 à partir de la base de données SQL Server. Toutefois, toutes les données doivent toujours être accessibles.
Pour cet exemple, vous exportez les données via CETAS et générez plusieurs tables externes que vous pouvez interroger ultérieurement. Vous pouvez utiliser une vue avec des instructions UNION pour interroger les données, ou créer une table externe unique et utiliser un caractère générique pour effectuer une recherche dans les sous-dossiers des données exportées.
Tout d’abord, clonez la table d’origine, car vous souhaitez simuler l’exportation et la suppression des données, mais ne souhaitez pas nécessairement supprimer la source de données actuelle. Exécutez l'instruction suivante :
-- CLONE TABLE
SELECT * INTO [PURCHASING].[PURCHASEORDERDETAIL_2] FROM [PURCHASING].[PURCHASEORDERDETAIL]
À partir de la première requête d’exploration de données, vous savez qu’il existe 5551 enregistrements de 2014. Tout avant 2014 doit être exporté vers un dossier identifié par année. Les données de 2011 entrent dans un dossier appelé 2011, et ainsi de suite.
Pour créer les tables externes, exécutez les commandes suivantes :
CREATE EXTERNAL TABLE ex_2011 WITH( LOCATION = '2011', DATA_SOURCE = ABS_Data, FILE_FORMAT = ffParquet )AS SELECT [PurchaseOrderID] ,[PurchaseOrderDetailID] ,[DueDate] ,[OrderQty] ,[ProductID] ,[UnitPrice] ,[LineTotal] ,[ReceivedQty] ,[RejectedQty] ,[StockedQty] ,[ModifiedDate] FROM [PURCHASING].[PURCHASEORDERDETAIL_2] WHERE YEAR([DUEDATE]) = 2011;CREATE EXTERNAL TABLE ex_2012 WITH( LOCATION = '2012', DATA_SOURCE = ABS_Data, FILE_FORMAT = ffParquet )AS SELECT [PurchaseOrderID] ,[PurchaseOrderDetailID] ,[DueDate] ,[OrderQty] ,[ProductID] ,[UnitPrice] ,[LineTotal] ,[ReceivedQty] ,[RejectedQty] ,[StockedQty] ,[ModifiedDate] FROM [PURCHASING].[PURCHASEORDERDETAIL_2] WHERE YEAR([DUEDATE]) = 2012;CREATE EXTERNAL TABLE ex_2013 WITH( LOCATION = '2013', DATA_SOURCE = ABS_Data, FILE_FORMAT = ffParquet )AS SELECT [PurchaseOrderID] ,[PurchaseOrderDetailID] ,[DueDate] ,[OrderQty] ,[ProductID] ,[UnitPrice] ,[LineTotal] ,[ReceivedQty] ,[RejectedQty] ,[StockedQty] ,[ModifiedDate] FROM [PURCHASING].[PURCHASEORDERDETAIL_2] WHERE YEAR([DUEDATE]) = 2013;Après avoir exécuté ces commandes, actualisez l’Explorateur d’objets SSMS. Ouvrez ensuite Databases>AdventureWorks2022>Tables>externes pour afficher les tables externes.
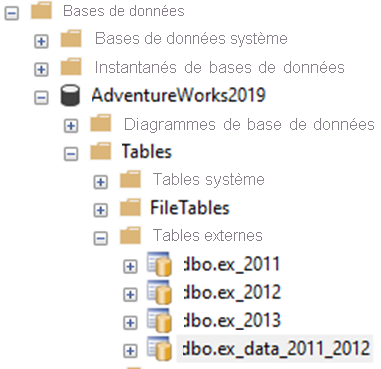
Vérifiez que les dossiers suivants s’affichent dans le conteneur Stockage Azure :
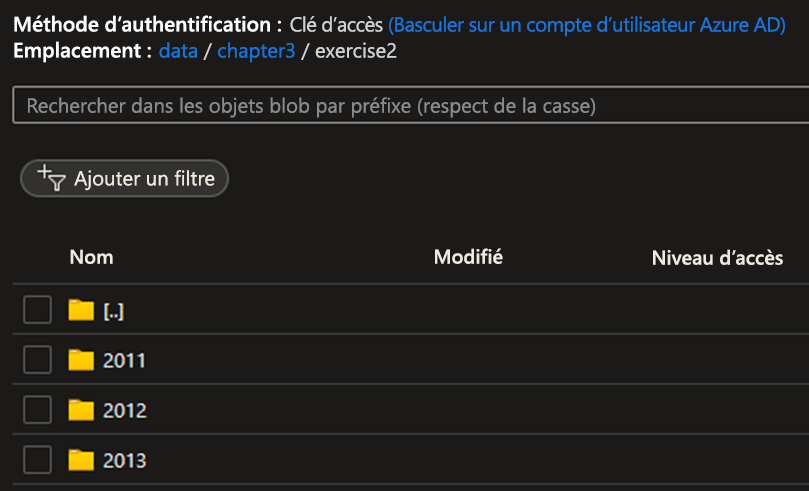
Une fois que les données froides ont été exportées, vous pouvez les supprimer de l'emplacement d'origine de la table.
DELETE FROM [PURCHASING].[PURCHASEORDERDETAIL_2] WHERE YEAR([DUEDATE]) < 2014
Interroger les données qui incluent la table externe
Vous pouvez utiliser une vue ou une recherche générique pour interroger les données externes exportées. Chaque méthode présente des avantages et des inconvénients. La méthode d’affichage est recommandée pour les requêtes répétitives, car elle fonctionne généralement mieux et peut également être combinée avec des tables physiques. La méthode de recherche par caractères génériques est plus flexible et plus facile à utiliser à des fins d’exploration.
Utiliser une vue pour interroger les données
Maintenant que les anciennes données sont exportées et supprimées de la base de données, vous pouvez utiliser T-SQL pour créer une vue qui interroge toutes les tables externes et les données actuelles dans votre base de données.
CREATE VIEW vw_purchaseorderdetail
AS
SELECT * FROM ex_2011
UNION ALL
SELECT * FROM ex_2012
UNION ALL
SELECT * FROM ex_2013
UNION ALL
SELECT * FROM [PURCHASING].[PURCHASEORDERDETAIL_2]
Vous pouvez exécuter la requête d’exploration de données d’origine, cette fois à l’aide de la vue nouvellement créée, pour afficher les mêmes résultats.
SELECT COUNT(*) AS QTY, DATEPART(YYYY, [DUEDATE]) AS [YEAR]
FROM vw_purchaseorderdetail
GROUP BY DATEPART(YYYY, [DUEDATE])
ORDER BY [YEAR]
Utiliser une recherche générique pour interroger les données
Dans l’exemple précédent, nous avons utilisé une vue avec des instructions UNION pour joindre les trois tables externes. Une autre façon d’obtenir les résultats souhaités consiste à utiliser une recherche générique pour analyser la structure de dossiers, y compris les sous-dossiers, pour toutes les données d’un type particulier.
L’exemple T-SQL suivant utilise OPENROWSET pour rechercher dans la ABS_Data source de données, y compris ses sous-dossiers, pour les fichiers Parquet.
SELECT COUNT(*) AS QTY, DATEPART(YYYY, [DUEDATE]) AS [YEAR]
FROM OPENROWSET
(BULK '**'
, FORMAT = 'PARQUET'
, DATA_SOURCE = 'ABS_Data')
AS [cc]
GROUP BY DATEPART(YYYY, [DUEDATE])
ORDER BY [YEAR]
Informations sur l’élimination des dossiers et les métadonnées
Les tables externes et OPENROWSET peuvent utiliser la filepath fonction pour collecter et filtrer des informations en fonction des métadonnées de fichier. La filepath fonction retourne des chemins d’accès complets, des noms de dossiers et des noms de fichiers. Vous pouvez utiliser ces informations pour améliorer les fonctionnalités de recherche de la table externe et des commandes OPENROWSET.
SELECT
r.filepath(1) 'folder_name'
,r.filepath() 'full_path'
,r.filepath(2) 'file_name'
FROM OPENROWSET(
BULK '*/*.parquet',
DATA_SOURCE = 'ABS_Data',
FORMAT = 'parquet'
) as [r]
GROUP BY
r.filepath(2),r.filepath(1), r.filepath()
ORDER BY
r.filepath(2)
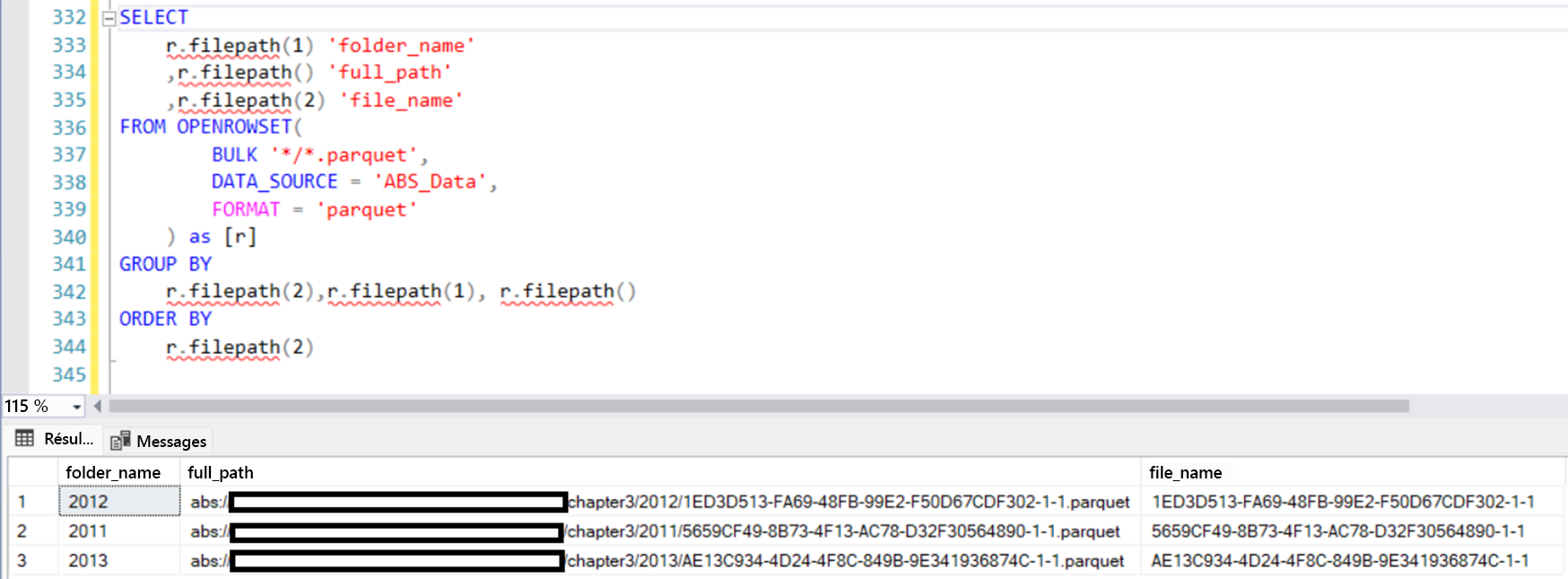
Si vous souhaitez récupérer des données à partir d’un dossier particulier et utiliser toujours les fonctionnalités de la méthode de recherche générique, vous pouvez utiliser la requête suivante :
SELECT *
FROM OPENROWSET(
BULK '*/*.parquet',
DATA_SOURCE = 'ABS_Data',
FORMAT = 'parquet'
) AS r
WHERE
r.filepath(1) IN ('2011')
Les résultats finaux sont identiques, mais en utilisant les métadonnées d’élimination des dossiers, votre requête accède uniquement aux dossiers requis au lieu d’analyser l’intégralité de la source de données, ce qui génère de meilleures performances de requête. Gardez ces informations à l’esprit lorsque vous concevez des architectures de stockage pour mieux utiliser les fonctionnalités PolyBase.
Par exemple, étant donné l’architecture de dossier suivante :
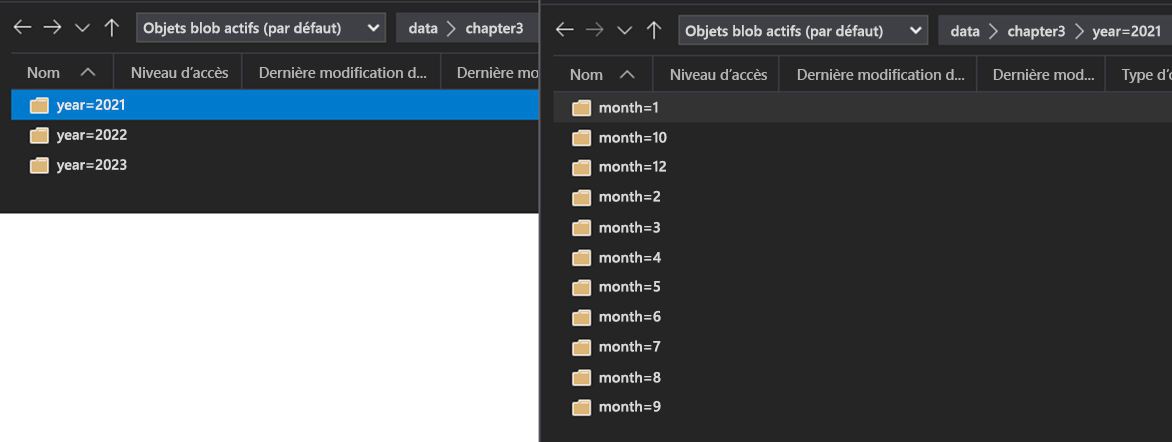
Vous pouvez utiliser la requête suivante :
SELECT *
FROM OPENROWSET(
BULK 'year=*/month=*/*.parquet',
DATA_SOURCE = 'ABS_Data',
FORMAT = 'parquet'
) AS r
WHERE
r.filepath(1) IN ('<year>')
r.filepath(2) IN ('<month>')
Pour cette requête, l’augmentation de la taille de la source de données n’a pas d’importance. SQL Server charge, lit et interroge uniquement les données du dossier sélectionné, en ignorant tous les autres.
Étant donné qu’aucune donnée n’est stockée dans la base de données, l’administrateur de base de données n’a pas besoin de concevoir une stratégie spécifique pour gérer ces données. L’entreprise doit toujours prendre toutes les précautions requises pour conserver les données en toute sécurité, y compris, mais pas uniquement pour les sauvegardes, la disponibilité et les autorisations.
Résumé
Dans cet exercice, vous avez utilisé CETAS pour déplacer des données froides d’une base de données vers stockage Azure et exporter une table en tant que format de fichier Parquet. Vous avez appris à interroger les données externes pour l’exploration et à optimiser les performances.
Vous pouvez utiliser CETAS pour combiner OPENROWSET, tables externes, vues, recherche générique et fonctions filepath. Vous pouvez accéder et exporter des données à partir d’autres bases de données telles que SQL Server, Oracle, Teradata et MongoDB, ou à partir du Stockage Blob Azure, d’Azure Data Lake Storage ou d’un stockage d’objets compatible S3. CETAS peut vous aider à concevoir des solutions performantes, durables et évolutives sur toutes les sources de données prises en charge par PolyBase.